示例一:對于簡單類型,比如String
public static void main(String[] args) {List<String> list = new ArrayList< >();list.add("aaa");list.add("bbb");list.add("bbb");list.add("ccc");list.add("abc");list.add("abc");list.add("abd");list.add("cba");list.add("cba");for (String s : list) {System.out.print(s+"\t");}System.out.println("\n-----------------");//方法一:利用Set去重Set<String> set = new HashSet< >();set.addAll(list);for (String s : set) {System.out.print(s+"\t");}System.out.println("\n-----------------");//方法二:利用TreeSet集合特性排序+去重:TreeSet可以將字符串類型的數據按照字典順序進行排序,首字母相同則看第二位List<String> list2 = new ArrayList<>(new TreeSet<>(list));for (String s : list2) {System.out.print(s+"\t");}System.out.println("\n-----------------");//方法三:LinkedHashSet雖然可以去重,但是根據他的特性,他不能對數據進行排序,只能維持原來插入時的秩序List<String> list3 = new ArrayList<>(new LinkedHashSet<>(list));for (String s : list3) {System.out.print(s+"\t");}System.out.println("\n-----------------");//方法四:用list.contains()的方法進行判斷,然后將其添加到新的list當中,元素的順序不發生改變List<String> list4 = new ArrayList<>();for (String item : list) {if (!list4.contains(item)) {list4.add(item);}}for (String s : list4) {System.out.print(s+"\t");}System.out.println("\n-----------------");//方法五:使用Java8特性去重:把list集合->Stream流,然后對流用distinct()去重,再用collect()收集List<String> list5 = list.stream().distinct().collect(Collectors.toList());for (String s : list5) {System.out.print(s+"\t");}System.out.println("\n-----------------");//方法六:使用list自身方法remove():將同一個list用兩層for循環配合.equals()方法,有相同的就用remove()方法剔除掉,然后得到一個沒有重復數據的listfor (int i = 0; i < list.size()-1; i++) {for (int j = list.size()-1; j >i; j--) {if(list.get(i).equals(list.get(j))){list.remove(j);}}}for (String s : list) {System.out.print(s+"\t");}}
結果:

示例二:對于復雜類型,根據指定屬性去重
測試代碼:
public static void main(String[] args) {List<Dept> depts = new ArrayList<>();depts.add(new Dept(10, "ACCOUNTING", "NEWYORK"));depts.add(new Dept(20, "RESEARCH", "DALLAS"));depts.add(new Dept(20, "RESEARCH", "DALLAS"));depts.add(new Dept(30, "SALES", "CHICAGO"));depts.add(new Dept(30, "SALES", "CHICAGO"));depts.add(new Dept(30, "OPERATIONS", "BOSTON"));//方法一:List<Dept> res = depts.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Dept::getDeptno))), ArrayList::new));res.forEach(System.out::println);//方法二:List<Integer> deptnoList = new ArrayList<>();List<Dept> res2 = depts.stream().filter(item -> {boolean flag = !deptnoList.contains(item.getDeptno());deptnoList.add(item.getDeptno());return flag;}).collect(Collectors.toList());res2.forEach(System.out::println);}
結果:
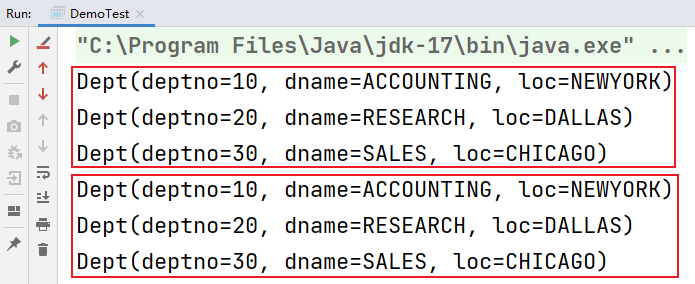
示例三:對于復雜類型,根據指定屬性去重(建議?????)
public class DemoTest {public static void main(String[] args) {List<Dept> depts = new ArrayList<>();depts.add(new Dept(10, "ACCOUNTING", "NEWYORK"));depts.add(new Dept(20, "RESEARCH", "DALLAS"));depts.add(new Dept(20, "RESEARCH", "DALLAS"));depts.add(new Dept(30, "SALES", "CHICAGO"));depts.add(new Dept(30, "SALES", "CHICAGO"));depts.add(new Dept(30, "OPERATIONS", "BOSTON"));//filter參數為true則保留depts.stream().filter(distinctByKey(Dept::getDeptno)).forEach(System.out::println);}private static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {Map<Object,Boolean> seen = new ConcurrentHashMap<>();//putIfAbsent方法添加鍵值對,如果map集合中沒有該key對應的值,則直接添加,并返回null,如果已經存在對應的值,則依舊為原來的值。//如果返回null表示添加數據成功(不重復),不重復(null==null :TRUE)return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;}}
結果:
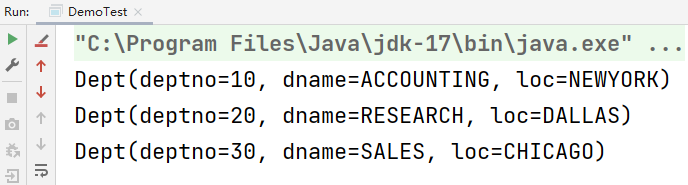
示例四:對于復雜類型,根據指定屬性去重
public static void main(String[] args) {List<Dept> depts = new ArrayList<>();depts.add(new Dept(10, "ACCOUNTING", "NEWYORK"));depts.add(new Dept(20, "RESEARCH", "DALLAS"));depts.add(new Dept(20, "RESEARCH", "DALLAS"));depts.add(new Dept(30, "SALES", "CHICAGO"));depts.add(new Dept(30, "SALES", "CHICAGO"));depts.add(new Dept(30, "OPERATIONS", "BOSTON"));final List<Dept> res = depts.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(Dept::getDeptno))), ArrayList::new));res.forEach(System.out::println);}
結果:
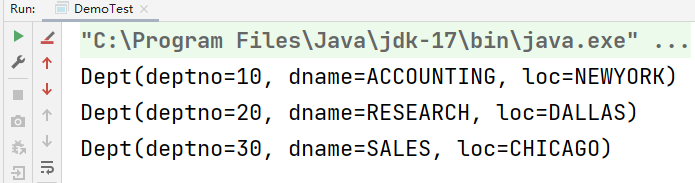
)


處理高光譜及多光譜遙感數據)





)
)
![【PyTorch][chapter 20][李宏毅深度學習]【無監督學習][ GAN]【實戰】](http://pic.xiahunao.cn/【PyTorch][chapter 20][李宏毅深度學習]【無監督學習][ GAN]【實戰】)



)



