目錄
前言
一、StarRocks在貝殼的應用現狀
1.1 歷史的數據分析架構
1.2 OLAP選型
1.2.1? 離線場景
1.2.2 實時場景
1.2.3 StarRocks 的引入
二、StarRocks 在貝殼的分析實踐
2.1?指標分析
2.2?實時業務
2.3?可視化分析
三、未來規劃
3.1 StarRocks集群的穩定性
3.2?StarRocks 新特性采用
? ? 原文大佬的這篇貝殼找房數倉實踐的文章整體寫的很深入,這里摘抄下來用作學習和知識沉淀。
前言
? ?貝殼找房是國內最大的在線房產交易平臺之一,利用大數據技術進行房源的挖掘和匹配,通過數據分析和挖掘,更準確地了解用戶需求,并為用戶提供個性化的房源推薦和交易服務。
? ? 隨著數據和業務規模的增長,傳統數倉的分析能力面臨很大的挑戰,貝殼需要引入新興的數據湖技術來支撐業務的發展。在指標分析場景、實時業務場景采用StarRocks替換原有的Kylin、Clickhouse 等組件,業務性能上有 5-6 倍性能提升;同時,貝殼也開始推動 StarRocks 替換 Presto 的場景,進一步簡化架構,實現分析層的統一,與 StarRocks 社區共建極速統一的湖倉新范式。
一、StarRocks在貝殼的應用現狀
1.1 歷史的數據分析架構
? 早期為了支持多樣化的分析能力,引入了多種OLAP引擎以支持不同的場景,其中包括:
-
Kylin、Druid:用于高QPS的指標查詢、報表系統等(高并發)
-
Presto、Impala:基于Hive數據分析
-
ClickHouse :用于支撐用戶分析、風控等實時業務
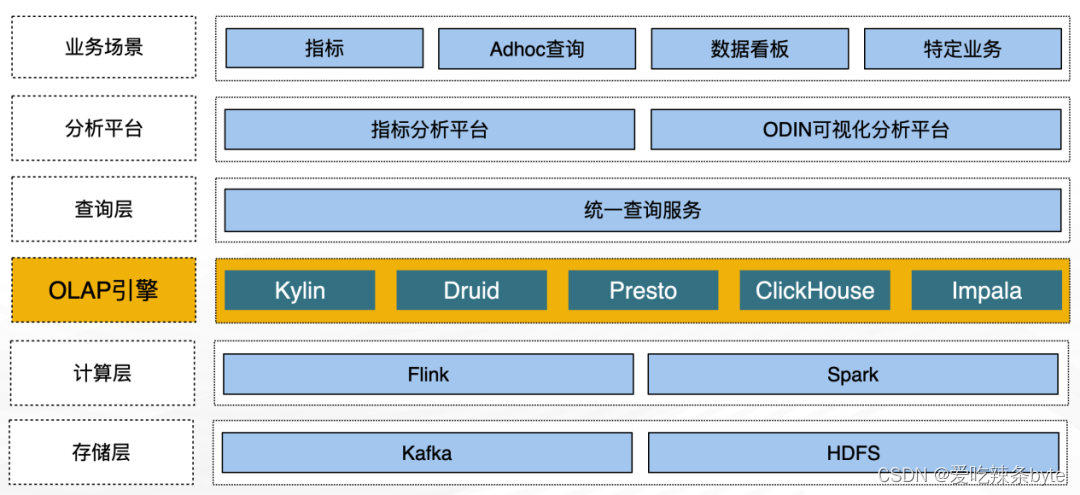
? ? ?隨著使用規模的擴大,維護成本越來越高,在擴展引擎數量的同時,必須要考慮上下游配套產品的兼容性改造,由于每個引擎的特殊性,適配的開發成本也很高,隨著引擎數量的增加和特性迭代,這方面的工作量越來越大。盡管數據開發平臺已經在很大程度上屏蔽了引擎的使用細節,但隨著業務的深入使用,某些場景可能需要使用引擎的高級特性支持。一些業務邏輯需要沉淀到引擎底層,增加了業務模型的開發維護成本。
1.2 OLAP選型
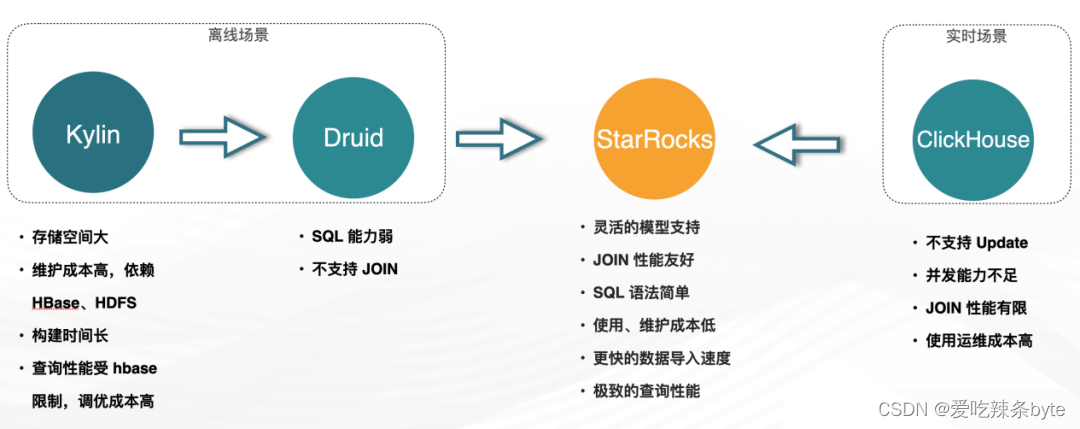
1.2.1? 離線場景
? ?最初使用kylin進行指標分析,Kylin是一種空間換時間的方案,并且依賴于HDFS 和HBase。此外,Kylin在維度計算方面需要較長的構建時間,查詢性能受到HBase的限制,調優成本較高。
Druid的引入雖然解決了以上問題,Druid 的引入雖然解決了以上問題,但Druid本身也存在一些局限性,比如 SQL 能力較弱,不支持JOIN操作。對于數據分析產品來說,如果只能使用寬表,但寬表模型的問題較為顯著,即一旦維度有所變化,其回溯的成本是很高的。
1.2.2 實時場景
? ? ClickHouse 主要是支撐實時分析場景,但在運維成本、更新操作,高并發和Join等場景有諸多限制。
? 從總體來看面臨以下比較嚴重問題:
- 復雜、靈活的業務模型要求
- 高性能的查詢和高穩定性
- 多引擎的高運維成本
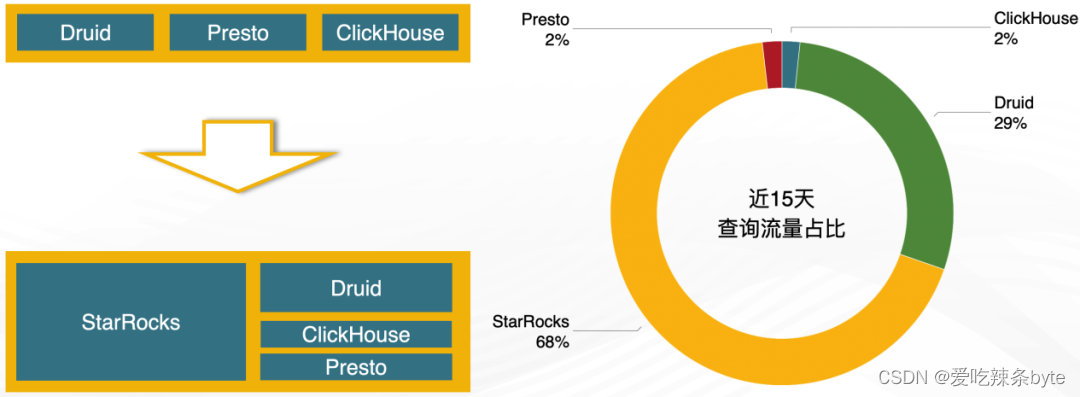
1.2.3 StarRocks 的引入
? ? 帶著這些問題開始調研市場上新興的 OLAP 技術,發現 StarRocks 能夠完全解決以上痛點。2021 年 StarRocks 在貝殼落地,截止 2022 年底,StarRocks 在占據了近 70% 的流量份額。生產環境共有 10 集群在使用,大規模集群 BE節點 40個,小規模集群 BE 節點數 5~10個。
? ?規模:
- 存儲總量80TB
- 日均寫入的數據量12TB,其中離線7TB,實時5TB
- 日均的查詢量是1400萬次
二、StarRocks 在貝殼的分析實踐
? 引入StarRocks最要的目標是解決多引擎的問題,接下來通過 3 個場景來介紹各引擎如何統一到 StarRocks 上。
2.1?指標分析
? ?離線分析場景:Druid To StarRocks
? ?指標開發分為3個階段:
- 數據準備:數據開發人員準備 Hive 表和 StarRocks 表
- 指標開發:基于元數據進行模型和指標開發
- 模型構建:將模型轉換到具體引擎的實現
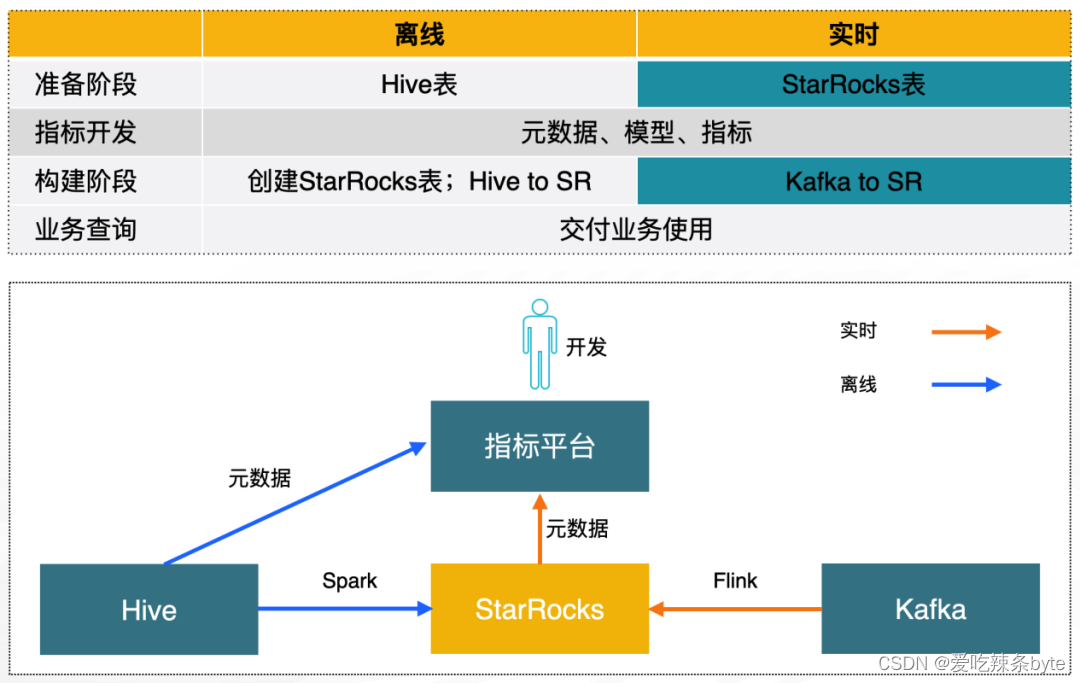
? ?在模型構建階段,使用 Spark任務將Hive數據同步到StarRocks 中,使用Flink同步Kafka中的數據。
? ?在指標分析場景中引入StarRocks,需要關注的主要問題有兩個:
(1)建表:
- ?離線場景:數據來源于Hive,可以進行數據內容探測,根據數據量自動計算分桶數(StarRocks自動分桶策略),根據實踐經驗,慢查詢sql中有很大一部分是模型問題導致(模型表選擇、分區分桶選擇等),智能化建表模式能更好的適配業務。
- 實時場景:雖然可以預估數據規模來生成表模型,但是業務的增長和發展是難以預估的,因此,對事實表通過添加定期巡檢任務進行周期性的檢測,根據歷史數據規模評估表的分區和分桶是否合理,定時向用戶反饋,協助用戶進行模型優化。
(2)數據導入:
- 臨時分區:采用臨時分區來解決導入期間無法查詢的問題
- 預聚合:Spark任務將Hive數據同步到StarRocks的過程中,先在spark階段對數據進行部分計算,以降低導入過程中BE節點的資源消耗,由于大量的導入通常發生在晚上0點至凌晨6點之間,并伴隨著離線導入的高峰期,提前進行聚合可以減輕compaction的壓力。
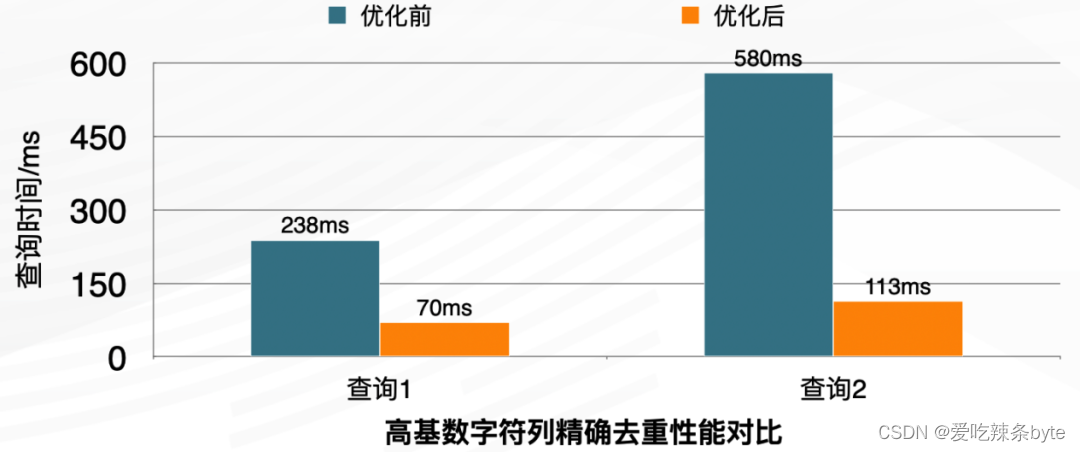
- 高基數的字符列精確去重:需要兼容之前的字符精確去重場景( Kylin、 Druid)使用 Hive 的全局字典來實現去重列編碼。去重計數列使用bitmap類型,查詢性能提高約3到4倍,在高QPS場景下,集群吞吐能力提升明顯。
2.2?實時業務
? 實時分析場景:ClickHouse To StarRocks
?ClickHouse不支持直接的update操作,因此需要通過使用視圖和?argMax()?函數計算最新數據以達到實時更新的目的。對一個復雜的模型而言,需要為每一張表都創建對應的視圖,最終要多張表和視圖才能實現,如圖 7 所示:

? ?ClickHouse 涉及到本地表、分布式表和視圖等不同層級的結構,最頂層的視圖view相當于用戶指標建模時所用的表,從開發角度來看相當復雜:
-
開發門檻較高:數據開發人員需要對 ClickHouse 有較高的掌握程度
-
維護迭代成本高:對于頻繁迭代的業務來說,模型的修改和數據驗證過程會變得比較復雜
-
底表數據量大:底層表存儲了所有變更記錄,在頻繁變更的場景,低表的數據量會變得很大
-
并發場景下Scan高:底層每次執行都需要掃描大量數據,導致集群的I/O壓力較高,讀寫互相影響
-
Join性能有限:在復雜場景下,多張表的關聯查詢性能不及預期
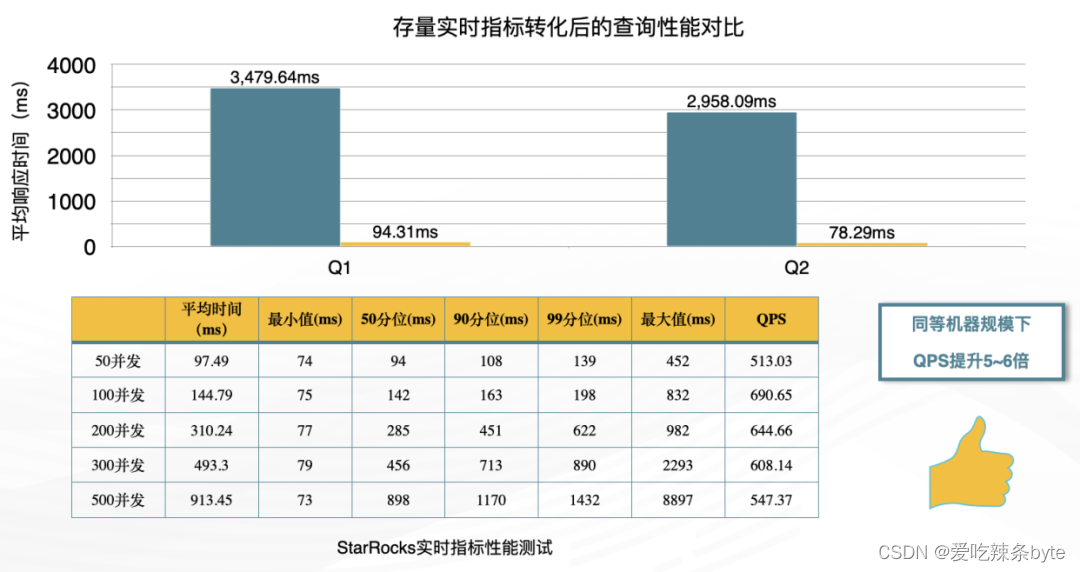
? StarRocks 原生支持update、高性能的Join,高QPS這些特性可以解決以上所有痛點;針對目前ClickHouse中存量的模型,可以通過以下方式平滑遷移到StarRocks:
- 模型:使用 Duplicate 模型對應 ClickHouse 中的MergeTree模型,StarRocks 中與 argMax() 函數對應的有 row_number()
-
查詢:查詢層通過查詢服務直接轉換到StarRocks語法結構
? 下圖是遷移后查詢性能對比結果,平均響應時間大幅下降。通過相同集群規模的并發壓測,QPS提升了5倍以上。
2.3?可視化分析
? ?ad-hoc場景:Presto To StarRocks
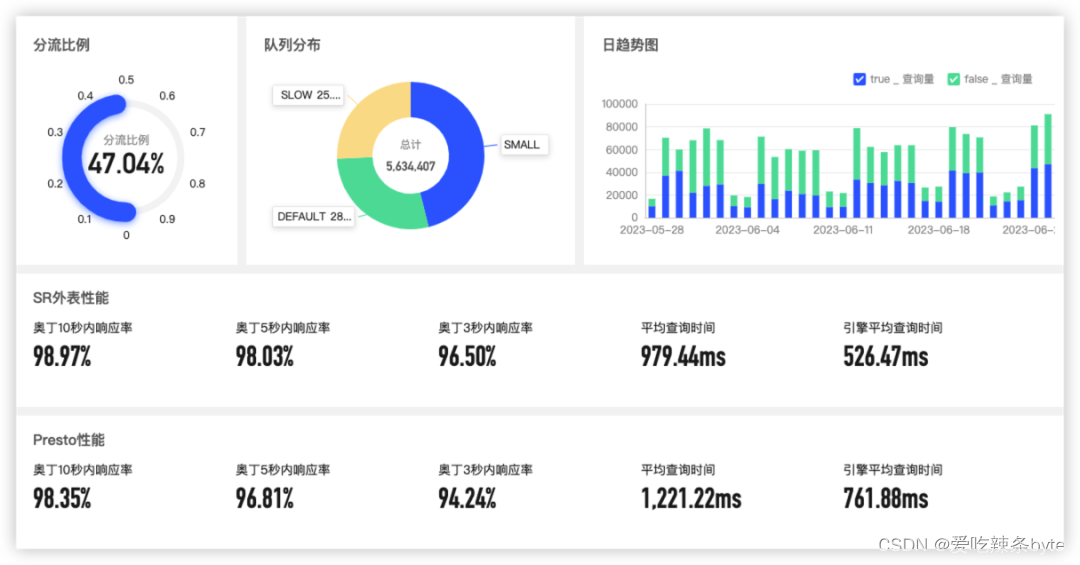
? ?貝殼內部的BI 產品ODIN分析平臺提供了基于Hive的分析能力,底層通過Presto引擎查詢,用戶通過PrestoSql進行建模分析,模型和引擎耦合性非常緊密,無法輕易轉換成到其他引擎的查詢。? ? StarRocks支持了 Hive 外表的功能,相比Presto有 3 倍以上的性能提升,使得 StarRocks 在貝殼有能力統一 OLAP 場景。目前已開始將分流到 StarRocks 做測試驗證,后續隨著 StarRocks Trino/Presto 兼容能力的進一步提升,會繼續提升 StarRocks 的流量占比,實現 StarRocks 在分析層的完全統一。
三、未來規劃
? ?貝殼找房引入 StarRocks已經有兩年時間了,從實踐結果來看,StarRocks能滿足90% 以上的需求場景。引入StarRocks對貝殼整個分析鏈路的建設起到了關鍵性作用,達到了極速統一的目標,并且帶來了顯著的性能收益,極大提升了OLAP分析場景的能力和效率。以下是未來的發展規劃:
3.1 StarRocks集群的穩定性
? ?對大規模集群的運維,需要從以下幾個方面加強穩定性建設:
- 細化監控維度,增加重要指標的監控告警
- 集群上下游鏈路的阻斷控制能力:阻斷能力在穩定性保障中非常重要,監控的目的是更好地發現問題,一旦發現問題,就需要有效的手段來控制降級,比如查詢降級,危險SQL攔截,寫入限制等。
- 多集群數據源的故障恢復自動化:對于一個核心業務,已經建立了雙鏈路保障策略,出現問題時能夠自動切換,不需要人工干預。
3.2?StarRocks 新特性采用
? ?當前我們比較關注 StarRocks 新特性主要是物化視圖、Trino 語法兼容和 LakeHouse 架構。
- 物化視圖在OLAP場景下對查詢的性能提升非常大,目前社區在物化視圖的多表,異步,自動更新等方面已經有了很豐富的功能支持,如何將這些功能結合業務場景,自動探測查詢模式生成對應的物化視圖將是未來的重點工作。
-
從 StarRocks 3.0 版本開始,StarRocks 支持Trino方言,這一點對存量的 Presto模型遷移來說,降低了遷移和使用成本,同時有不錯的查詢性能提升。
- LakeHouse架構是StarRocks3.0 的新架構模式,相比2.0版本的資源隔離能力,全新的存算分離架構支持硬資源隔離,這個特性使得現在的多個小規模集群模式可以統一成大規模集群,進一步降低資源和維護成本;彈性計算能力可以滿足不同業務的使用場景。此外,StarRocks也支持了Apache Hudi、Apache Iceberg 和 Delta Lake 主流數據湖,統一湖倉查詢場景不再是問題。
參考文章:
性能全面飆升!StarRocks 在貝殼找房的極速統一實踐
















)


