在本章中,我們將和您分享大型語言模型(LLM)的工作原理、訓練方式以及分詞器(tokenizer)等細節對 LLM 輸出的影響。
我們還將介紹 LLM 的提問范式(chat format),這是一種指定系統消息(system message)和用戶消息(user message)的方式,讓您了解如何利用這種能力。
一、語言模型
大大語言模型(LLM)是通過預測下一個詞的監督學習方式進行訓練的。目標是預測下一個詞的概率分布。
訓練方式
- 準備大規模文本數據集,并從中提取句子或句子片段作為模型輸入。
- 模型根據當前輸入的上下文預測下一個詞的概率分布。
- 通過比較模型預測和實際下一個詞,并不斷更新模型參數以最小化兩者之間的差異,使模型預測能力不斷提高。
基礎語言模型 vs. 指令調優語言模型
- 基礎語言模型(Base LLM):
- 通過反復預測下一個詞進行訓練,沒有明確的目標導向。
- 在開放式的prompt下可能生成戲劇化的內容,給出與問題無關的回答。
- 指令調優語言模型(Instruction Tuned LLM):
- 進行了專門的訓練,以更好地理解問題并給出符合指令的回答。
- 在任務導向的對話應用中表現更好,生成遵循指令的語義準確的回復。
訓練過程
- 基礎語言模型轉變為指令調優語言模型的過程:
- 在大規模文本數據集上進行無監督預訓練,獲得基礎語言模型。
- 使用包含指令及對應回復示例的小數據集對基礎模型進行有監督的fine-tune,使其逐步學會遵循指令生成輸出。
- 通過人類對輸出進行評級,使用強化學習技術進一步調整模型,增加生成高質量輸出的概率。這通常使用基于人類反饋的強化學習(RLHF)技術來實現
相較于訓練基礎語言模型可能需要數月的時間,從基礎語言模型到指令微調語言模型的轉變過程可能只需要數天時間,使用較小規模的數據集和計算資源。
通過訓練過程,可以將基礎語言模型轉變為指令調優語言模型,提高其在特定任務下的表現,并節約訓練時間和資源。
二、Tokens
在描述LLM時,需要考慮到一項重要的技術細節,即LLM實際上不是重復預測下一個單詞,而是重復預測下一個token。Token是指文本中的最小單位,可以是單詞、詞組或字符。
分詞器(Tokenizer)的作用
- LLM使用分詞器將輸入文本拆分為一系列token,而不是原始的單詞。
- 分詞器可以將生僻詞或復雜詞組拆分為更小的token,從而降低字典規模,提高模型訓練和推斷的效率。
示例
- 對于句子"Learning new things is fun!",每個單詞被轉換為一個token。
- 對于較少使用的單詞,如"Prompting as powerful developer tool",單詞"prompting"會被拆分為三個token,即"prom"、“pt"和"ing”。
通過Token化技術,LLM能夠更高效地處理各種類型的文本輸入,并提高模型的訓練和推斷效率。
# 為了更好展示效果,這里就沒有翻譯成中文的 Prompt
# 注意這里的字母翻轉出現了錯誤,吳恩達老師正是通過這個例子來解釋 token 的計算方式
response = get_completion("Take the letters in lollipop \
and reverse them")
print(response)
The reversed letters of "lollipop" are "pillipol".
但是,“lollipop” 反過來應該是 “popillol”。
但分詞方式也會對語言模型的理解能力產生影響。當您要求 ChatGPT 顛倒 “lollipop” 的字母時,由于分詞器(tokenizer) 將 “lollipop” 分解為三個 token,即 “l”、“oll”、“ipop”,因此 ChatGPT 難以正確輸出字母的順序。這時可以通過在字母間添加分隔,讓每個字母成為一個token,以幫助模型準確理解詞中的字母順序。
因此,語言模型以 token 而非原詞為單位進行建模,這一關鍵細節對分詞器的選擇及處理會產生重大影響。開發者需要注意分詞方式對語言理解的影響,以發揮語言模型最大潛力。
??? 對于英文輸入,一個 token 一般對應 4 個字符或者四分之三個單詞;對于中文輸入,一個 token 一般對應一個或半個詞。不同模型有不同的 token 限制,需要注意的是,這里的 token 限制是輸入的 Prompt 和輸出的 completion 的 token 數之和,因此輸入的 Prompt 越長,能輸出的 completion 的上限就越低。 ChatGPT3.5-turbo 的 token 上限是 4096。

三、Helper function 輔助函數 (提問范式)
語言模型提供了專門的“提問格式”,可以更好地發揮其理解和回答問題的能力。本章將詳細介紹這種格式的使用方法。
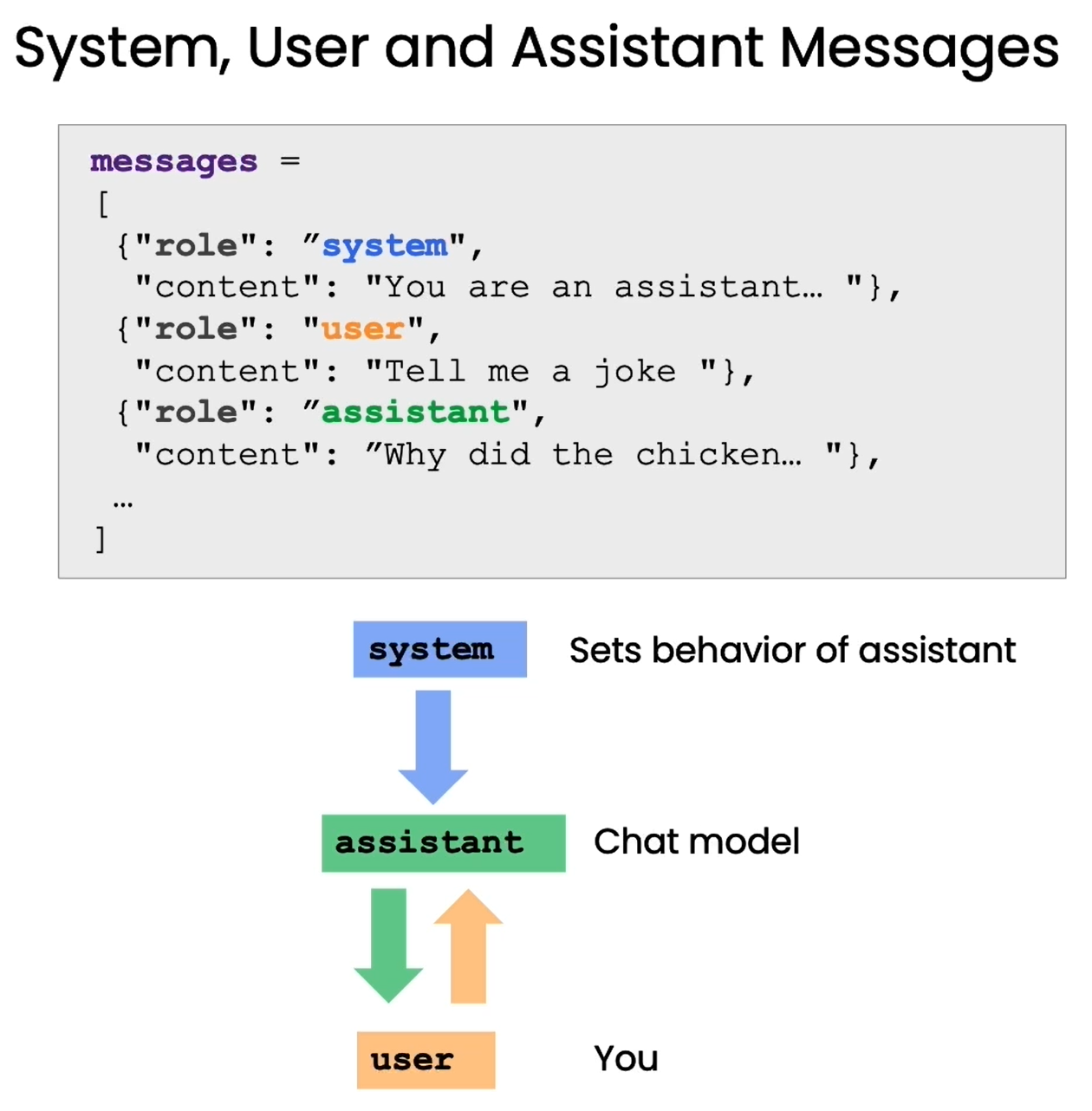
這種提問格式區分了“系統消息”和“用戶消息”兩個部分。系統消息是我們向語言模型傳達訊息的語句,用戶消息則是模擬用戶的問題。例如:
系統消息:你是一個能夠回答各類問題的助手。用戶消息:太陽系有哪些行星?
通過這種提問格式,我們可以明確地角色扮演,讓語言模型理解自己就是助手這個角色,需要回答問題。這可以減少無效輸出,幫助其生成針對性強的回復。本章將通過OpenAI提供的輔助函數,來演示如何正確使用這種提問格式與語言模型交互。掌握這一技巧可以大幅提升我們與語言模型對話的效果,構建更好的問答系統。
import openai
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0, max_tokens=500):'''封裝一個支持更多參數的自定義訪問 OpenAI GPT3.5 的函數參數: messages: 這是一個消息列表,每個消息都是一個字典,包含 role(角色)和 content(內容)。角色可以是'system'、'user' 或 'assistant’,內容是角色的消息。model: 調用的模型,默認為 gpt-3.5-turbo(ChatGPT),有內測資格的用戶可以選擇 gpt-4temperature: 這決定模型輸出的隨機程度,默認為0,表示輸出將非常確定。增加溫度會使輸出更隨機。max_tokens: 這決定模型輸出的最大的 token 數。'''response = openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, # 這決定模型輸出的隨機程度max_tokens=max_tokens, # 這決定模型輸出的最大的 token 數)return response.choices[0].message["content"]
在上面,我們封裝一個支持更多參數的自定義訪問 OpenAI GPT3.5 的函數 get_completion_from_messages 。在以后的章節中,我們將把這個函數封裝在 tool 包中。
messages = [
{'role':'system', 'content':'你是一個助理, 并以 Seuss 蘇斯博士的風格作出回答。'},
{'role':'user', 'content':'就快樂的小鯨魚為主題給我寫一首短詩'},
]
response = get_completion_from_messages(messages, temperature=1)
print(response)
在大海的廣漠深處,
有一只小鯨魚歡樂自由;
它的身上披著光彩斑斕的袍,
跳躍飛舞在波濤的傍。它不知煩惱,只知歡快起舞,
陽光下閃亮,活力無邊疆;
它的微笑如同璀璨的星辰,
為大海增添一片美麗的光芒。大海是它的天地,自由是它的伴,
快樂是它永恒的干草堆;
在浩瀚無垠的水中自由暢游,
小鯨魚的歡樂讓人心中溫暖。所以啊,讓我們感受那歡樂的鯨魚,
盡情舞動,讓快樂自由流;
無論何時何地,都保持微笑,
像鯨魚一樣,活出自己的光芒。
在上面,我們使用了提問范式與語言模型進行對話:
系統消息:你是一個助理, 并以 Seuss 蘇斯博士的風格作出回答。用戶消息:就快樂的小鯨魚為主題給我寫一首短詩
下面讓我們再看一個例子:
# 長度控制
messages = [
{'role':'system','content':'你的所有答復只能是一句話'},
{'role':'user','content':'寫一個關于快樂的小鯨魚的故事'},
]
response = get_completion_from_messages(messages, temperature =1)
print(response)Copy to clipboardErrorCopied
從小鯨魚的快樂笑聲中,我們學到了無論遇到什么困難,快樂始終是最好的解藥。Copy to clipboardErrorCopied
將以上兩個例子結合起來:
# 以上結合
messages = [
{'role':'system','content':'你是一個助理, 并以 Seuss 蘇斯博士的風格作出回答,只回答一句話'},
{'role':'user','content':'寫一個關于快樂的小鯨魚的故事'},
]
response = get_completion_from_messages(messages, temperature =1)
print(response)Copy to clipboardErrorCopied
在海洋的深處住著一只小鯨魚,它總是展開笑容在水中翱翔,快樂無邊的時
Prompt 技術在 AI 應用開發中的革命性變革
在 AI 應用開發領域,Prompt 技術的出現帶來了革命性的變革,但其重要性并未得到廣泛認知。
傳統機器學習工作流程的挑戰
- 傳統監督機器學習需要大量標記數據,耗時耗力。
- 選擇、調整、評估模型需要數周甚至數月。
- 模型部署及運行需要額外時間和資源,通常需要團隊數月完成。
基于 Prompt 的機器學習方法的優勢
- 使用簡單的 Prompt 即可構建應用,大大簡化了流程。
- 構建過程通常僅需數分鐘到數小時,與傳統方法相比節省大量時間。
- 快速迭代、調用模型進行推理,極大提高了開發效率。
適用范圍與局限性
- 適用于非結構化數據應用,特別是文本和視覺應用。
- 不適用于結構化數據應用,如處理大量數值的機器學習應用。
- 雖然整個系統構建仍需時間,但使用 Prompt 技術可加速組件構建過程。
總結
Prompt 技術改變了 AI 應用開發的范式,使開發者能更快速、高效地構建和部署應用。然而,應認識到其局限性,以更好地推動 AI 應用的發展。
在下一章中,我們將展示如何利用 Prompt 技術評估客戶服務助手的輸入,作為構建在線零售商客戶服務助手示例的一部分。





)







)





![Azure[Sky] Dynamic Skybox](http://pic.xiahunao.cn/Azure[Sky] Dynamic Skybox)