Sora - 探索AI視頻模型的無限可能
隨著人工智能技術的飛速發展,AI視頻模型已成為科技領域的新熱點。而在這個浪潮中,OpenAI推出的首個AI視頻模型Sora,以其卓越的性能和前瞻性的技術,引領著AI視頻領域的創新發展。讓我們將一起探討Sora的技術特點、應用場景以及對未來創作方式的深遠影響。
Sora是text-to-video模型
方向一:技術解析
參考1
- 使用統一的patches格式對訓練數據進行標準化處理,將圖像分割成小塊(patches),然后像語言模型(LLM)中的tokens一樣輸入到Transformer模型中。
- 可能是幾幀十幾幀對應一段文本描述,大力出奇跡?
- 可以擴展到2D和3D,cv大一統?
參考2
Embedding層的作用是將某種格式的輸入數據,轉變為模型可以處理的向量表示,來描述原始數據所包含的信息。
本來想實現一下這個將圖像劃分為patches,貌似成功了~
import einops
import matplotlib.pyplot as plt
from einops import rearrange
import numpy as np
import pandas as pd
import os
from torchvision import transforms
from PIL import Image
import torchimage_path = 'D:/meeee/344.png'
preprocess = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()])image = Image.open(image_path).convert("RGB")
tensor_image = preprocess(image)display(tensor_image)patches = rearrange(tensor_image,'c (h p1) (w p2) -> (h w) c p1 p2',p1=16,p2=16)
patches.shapefigure = plt.figure(figsize=(5,5))
for i in range(patches.size(0)):img = patches[i].permute(1,2,0)figure.add_subplot(14,14,i+1)plt.axis('off')plt.imshow(img)
plt.show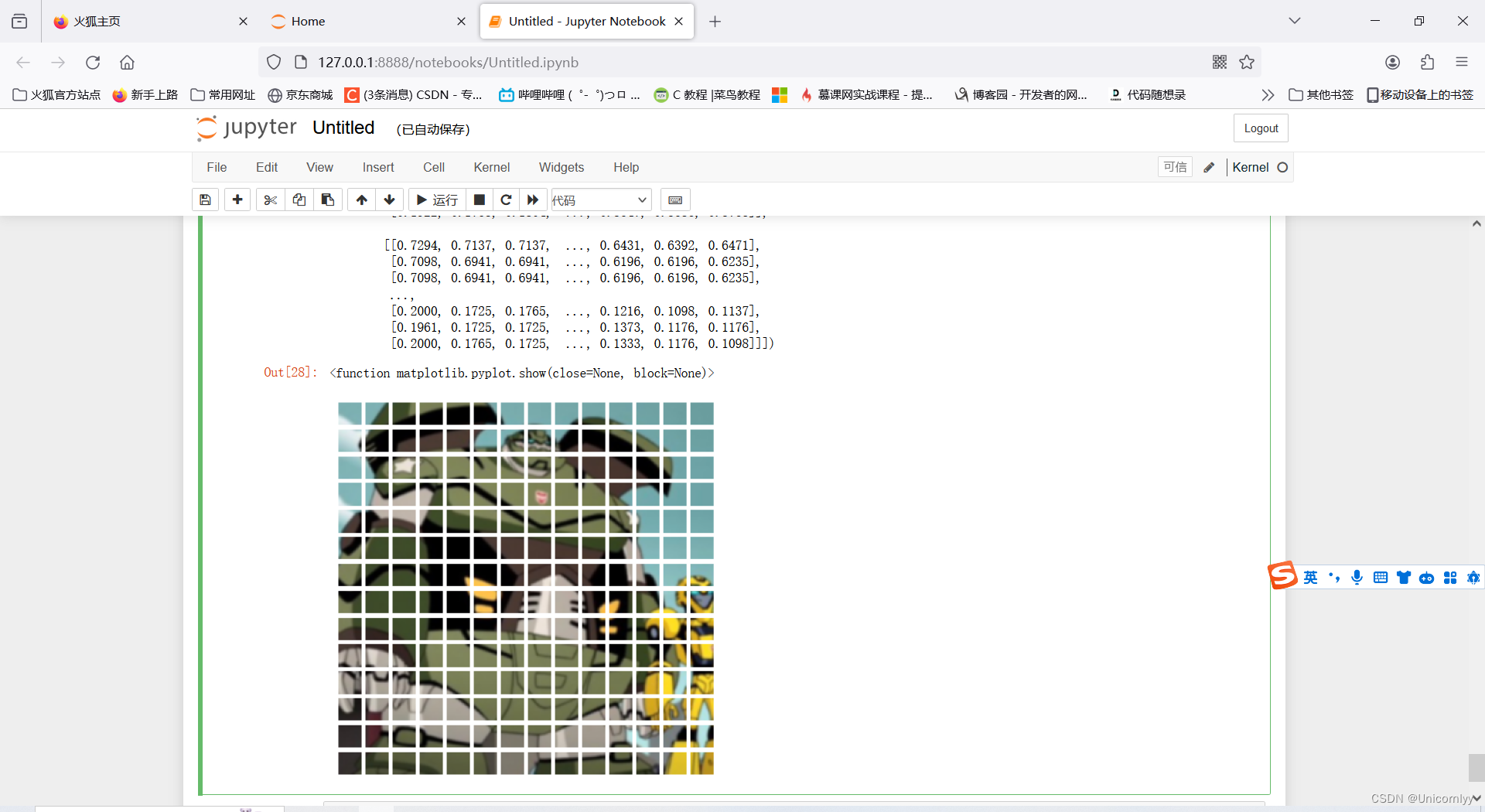
 CLIP模型,圖生文,輸入一張圖輸出對這張圖的描述,屬于多模態,文本-圖片
CLIP模型,圖生文,輸入一張圖輸出對這張圖的描述,屬于多模態,文本-圖片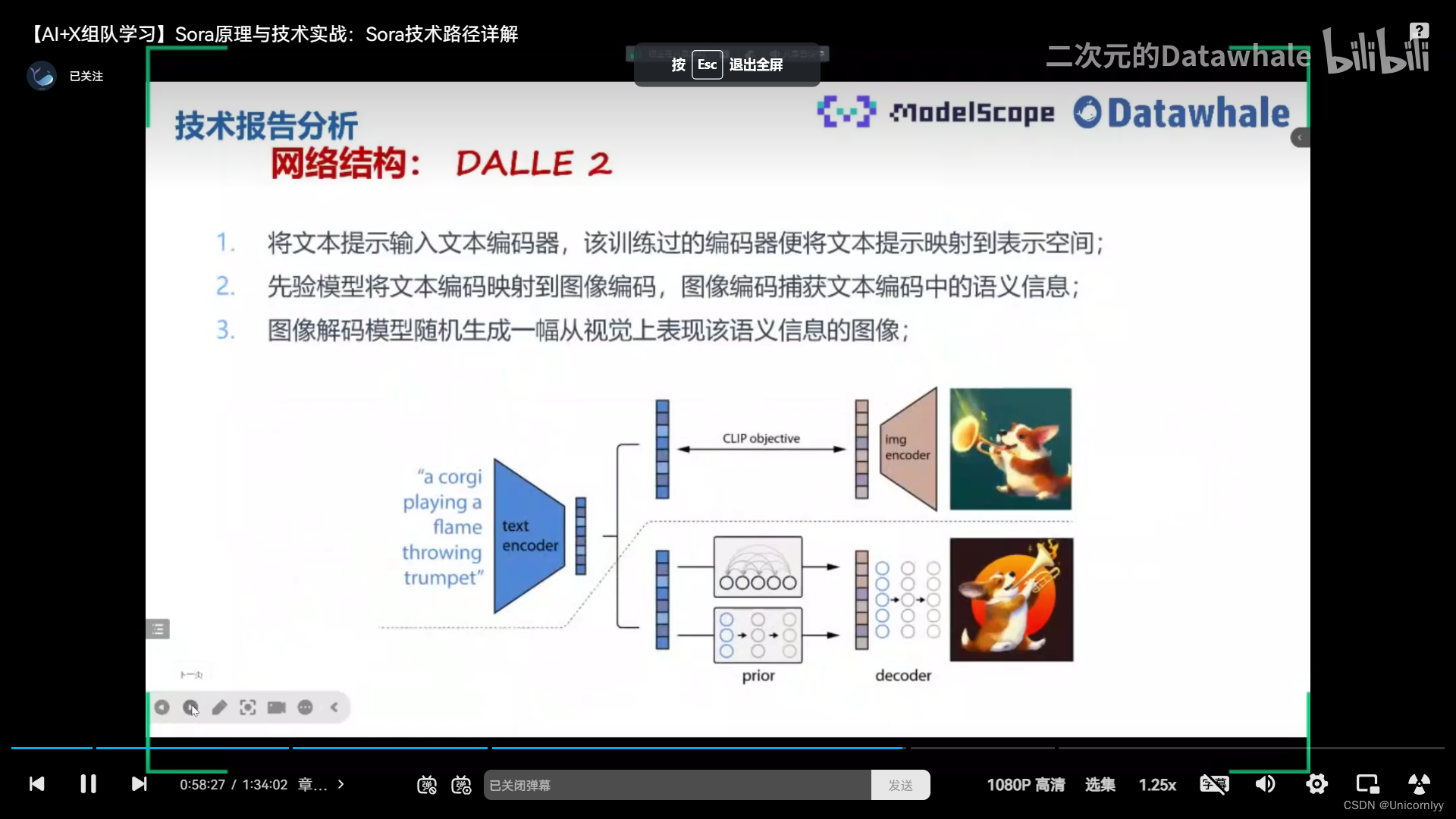
比較認同一位老師說的不要拿錯的東西去為人服務(無人駕駛?)是火上澆油,Sora是仿真是概率模型~
方向三:未來展望
感覺可能影響創作流程,工作流會很大改變?
- 降低技術門檻:
AI視頻模型可以自動處理視頻編輯中的復雜任務,如特效(時間成本,技術含量,金錢成本)、剪輯、調色、音頻處理等,從而降低了專業知識的需求。創作者可以更容易地將想法變為現實,不再受限于技術技能。我覺得對于小說家或者寫劇本的創作者來說,可能是一個福音~
方向五:用戶體驗與互動
期待OpenAI早日能開放sora,非常想體驗體驗~~



![Azure[Sky] Dynamic Skybox](http://pic.xiahunao.cn/Azure[Sky] Dynamic Skybox)















