文章目錄
- 1. 寫在前面
- 2. 頁面分析
- 3. 字符知識
- 4. 加密分析
【作者主頁】:吳秋霖
【作者介紹】:Python領域優質創作者、阿里云博客專家、華為云享專家。長期致力于Python與爬蟲領域研究與開發工作!
【作者推薦】:對JS逆向感興趣的朋友可以關注《爬蟲JS逆向實戰》,對分布式爬蟲平臺感興趣的朋友可以關注《分布式爬蟲平臺搭建與開發實戰》
還有未來會持續更新的驗證碼突防、APP逆向、Python領域等一系列文章
1. 寫在前面
??目前市面上有不少的網站使用了字體加密技術,像一些重要的數字內容使用字體加密很常見!從早期的靜態固定字體文件隨著不斷的對抗演進到目前的動態字體文件,從PC端的應用到目前APP頁面的普及使用
本期文字將以紅色小番茄為例,咱們使用OCR識別技術來攻克一下字體加密
2. 頁面分析
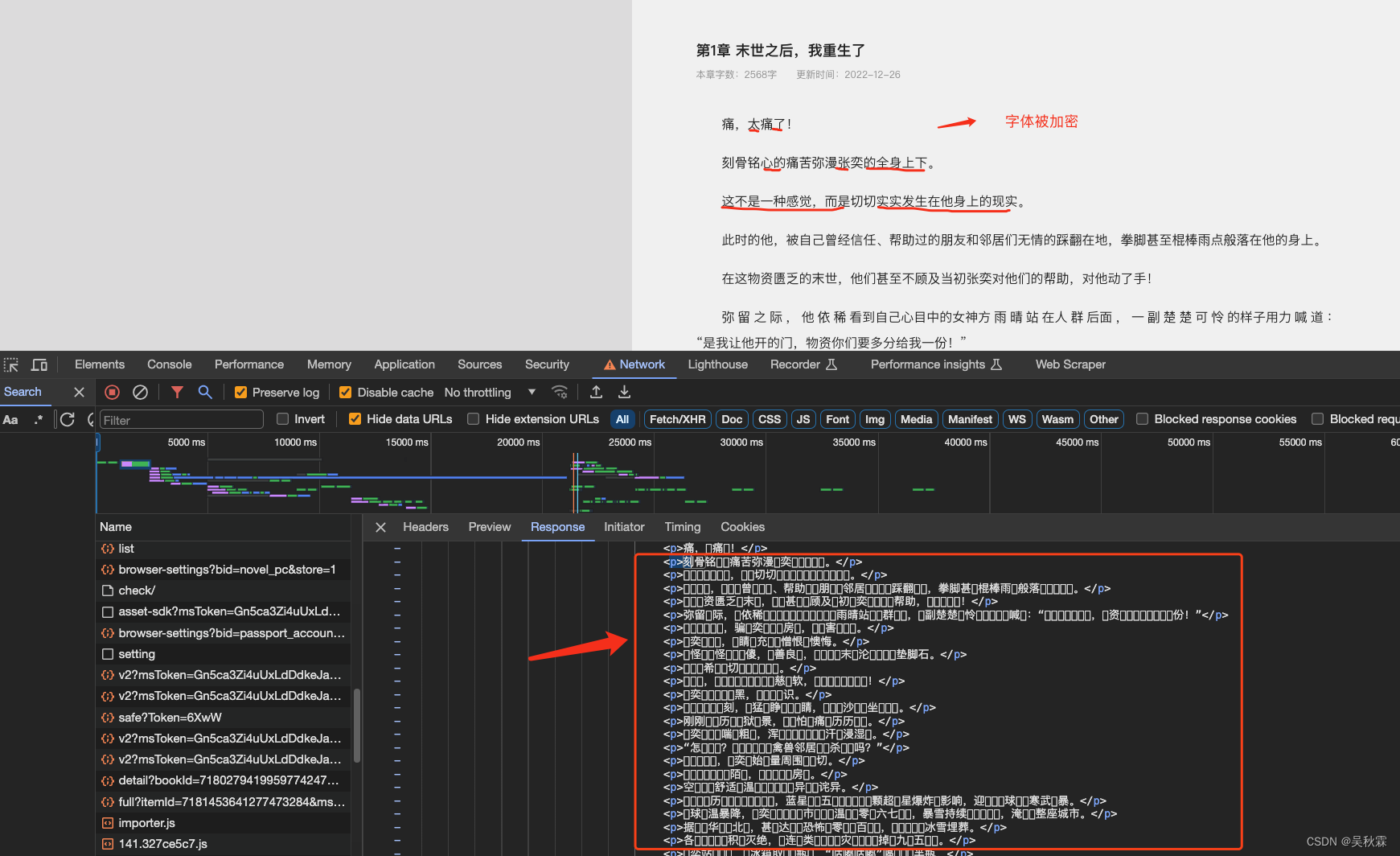
我們打開首先網站分析一下,可以看到響應的HTML內容中網頁顯示的本文內容,均是看起來晦澀難懂的字符,這就是字體加密。如下所示:
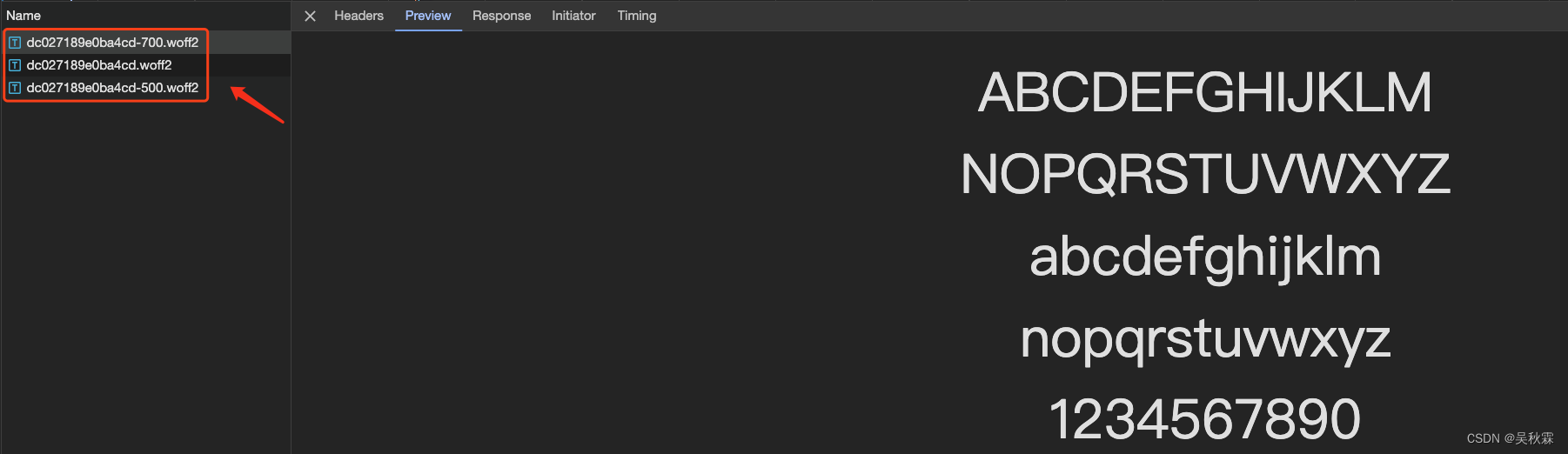
對于Web端的字體加密,我們可能都知道會有相應的woff類型的文件,存儲著自定義的字體,它的作用則是讓網站能夠使用這些自定義的字體來顯示加密的文本內容,如下所示:
3. 字符知識
在真正的內容分析開始之前,我們需要了解的一些知識點。這里不知道的朋友認真學,所有的中文漢字它都自己對應的一串數字碼,也叫做Unicode碼點,這是一種國際化的字符編碼標準!為世界上幾乎所有的字符集提供了一個唯一的標識
它們是一個非負整數,如下作者隨機打印了幾個示例:
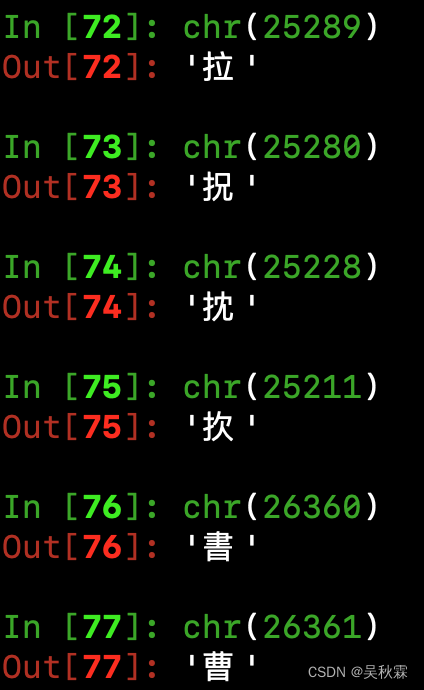
同理我們使用Python的內置函數ord可以查看字符的碼點,chr函數則將碼點轉換為字符
4. 加密分析
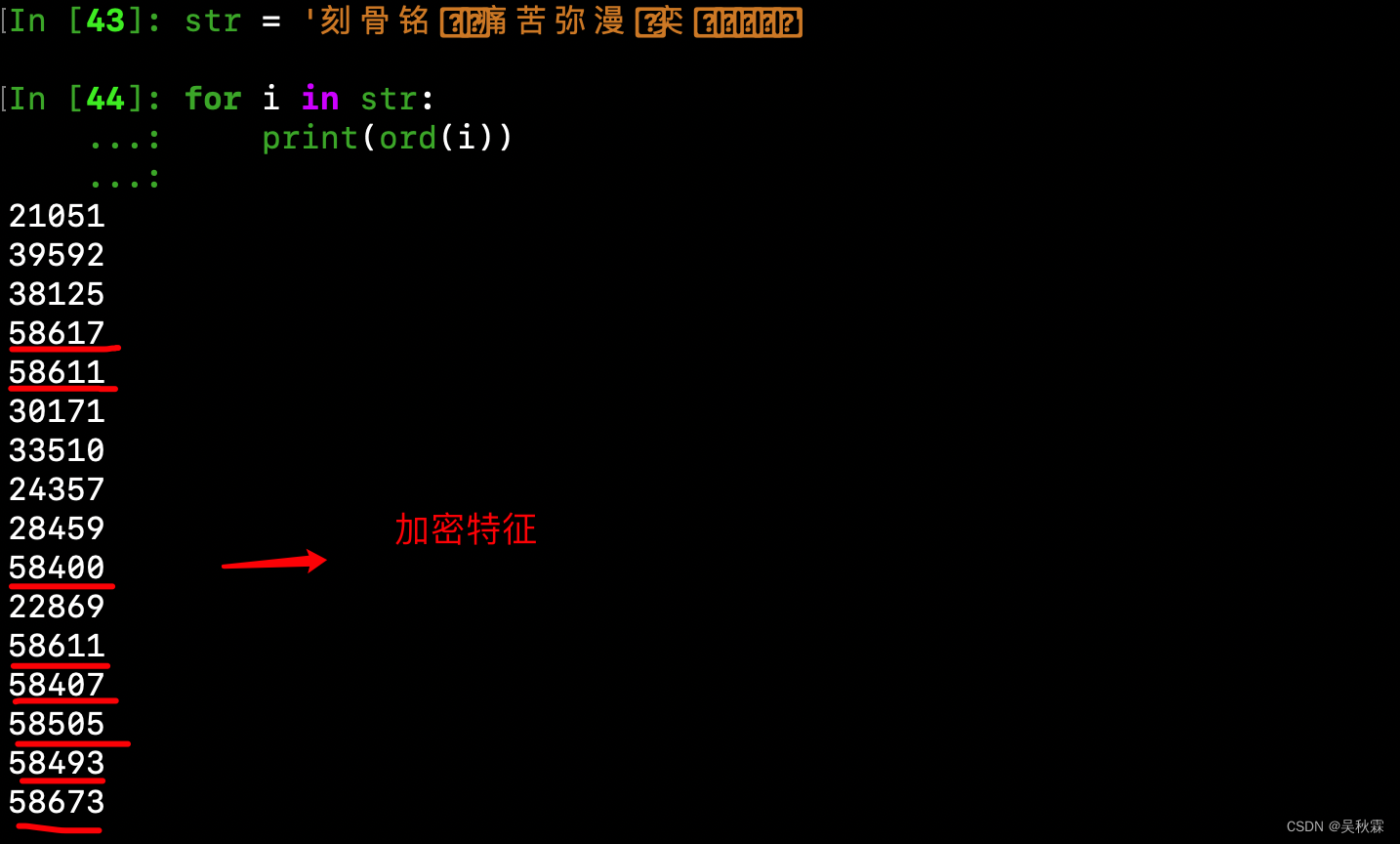
接下來,這里將網頁中加密的文本拿一小段下來簡單的進行一個測試。使用ord打印一下所有字符的碼點,可以看到一個特征!就是每一個被加密的字體對應的碼點都是58…這樣的,如下所示:
這個時候我們則需要將上面提到的woff文件下載下來,并使用fontTools庫來加載字體并解析其結構,代碼如下:
from fontTools.ttLib import TTFonturl = 'https://lf6-awef.bytetos.com/obj/awesome-font/c/dc027189e0ba4cd-700.woff2'response = requests.get(url).content
with TTFont(BytesIO(response)) as font_parse:u_d = font_parse.getBestCmap())
將會得到一個碼點與字體編碼對應的字典,如下所示:
{58344: 'gid58344', 58345: 'gid58345', 58346: 'gid58346', 58347: 'gid58347', 58348: 'gid58348', 58349: 'gid58349', 58350: 'gid58350', 58351: 'gid58351', 58352: 'gid58352'}
接下來,我們需要將gid編碼對應的文字信息拿到,并建立字典。方便我們后續在對文本內容進行還原的時候調用,加密字體編碼如何對應明文數據,代碼實現如下:
unicode_reuslt = []
for key, _ in u_d.items():unicode_reuslt.append(key)
char_list = [chr(ch_unicode) for ch_unicode in unicode_reuslt]
normal_dict, error_dict = font_to_img(char_list, ttf_name)
new_dict = {ord(key): value for key, value in normal_dict.items()}
print(new_dict)
在這里將使用到OCR識別技術,去還原加密字體的文字,這也是當前比較主流的一種方案,代碼實現如下所示:
def font_to_img(code_list, filename, score=0.95):normal_dict = {}ocr = CnOcr()for char_list in code_list:char_code = char_list.encode().decode()img_size = 1024img = Image.new('img', (img_size, img_size), 255)draw = ImageDraw.Draw(img)font = ImageFont.truetype(filename, int(img_size * 0.7))x, y = draw.textsize(char_code, font=font)draw.text(((img_size - x) // 2, (img_size - y) // 2), char_code, font=font, fill=0)img = img.convert("RGB")word = ocr.ocr_for_single_line(np.array(img))normal_dict[char_code] = word["text"]return normal_dict
如上代碼,這里簡單解讀一下!score參數表示OCR對該文本的識別得分,上面代碼中沒有使用的原因是有較小概率的丟失率!這個問題可以找一些更精準的模型來識別
再說說識別文字的流程與原理,上面使用Image來創建了一個白色的背景圖像,然后使用ImageDraw在圖像上繪制出字符,字體大小為圖像大小的70%
然后將圖像轉換為RGB格式,最后使用Ocr對圖像進行單行識別,獲取識別結果以及識別得分,結果如下所示:

接下來,我門需要做的就是對加密的文本內容進行遍歷,對每一個字符進行編碼轉換,得到對對應的碼點!提取碼點為58特征的加密字體,然后從上面字典獲取對應的文字,如下所示:
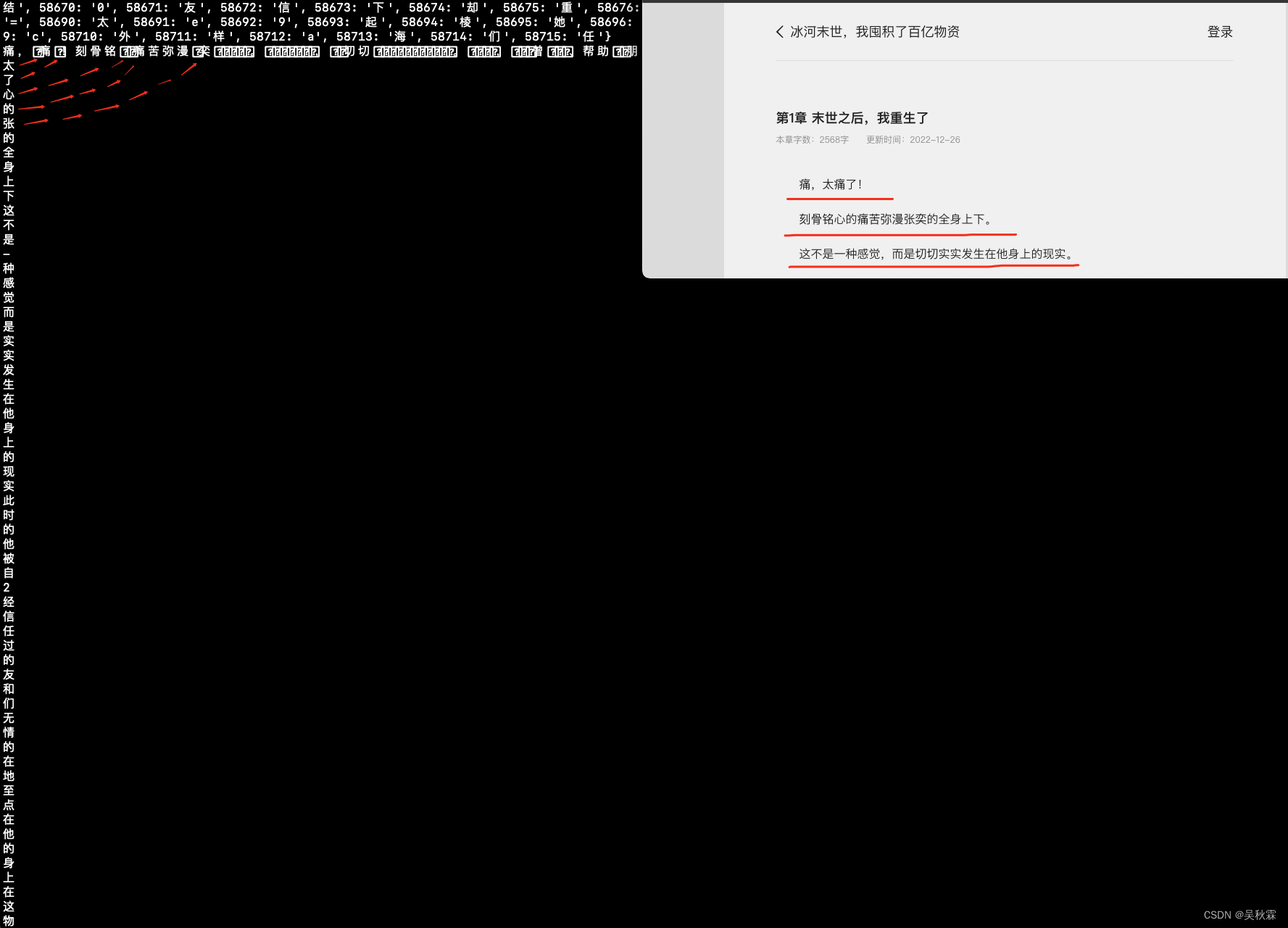
最終我們再通過上述的代碼將加密打散還原出來的加密字體文字,拼接成完整的句子。這里的話我們將所有加密特征與非加密文字內容完成組裝即可,最終內容還原如下所示:
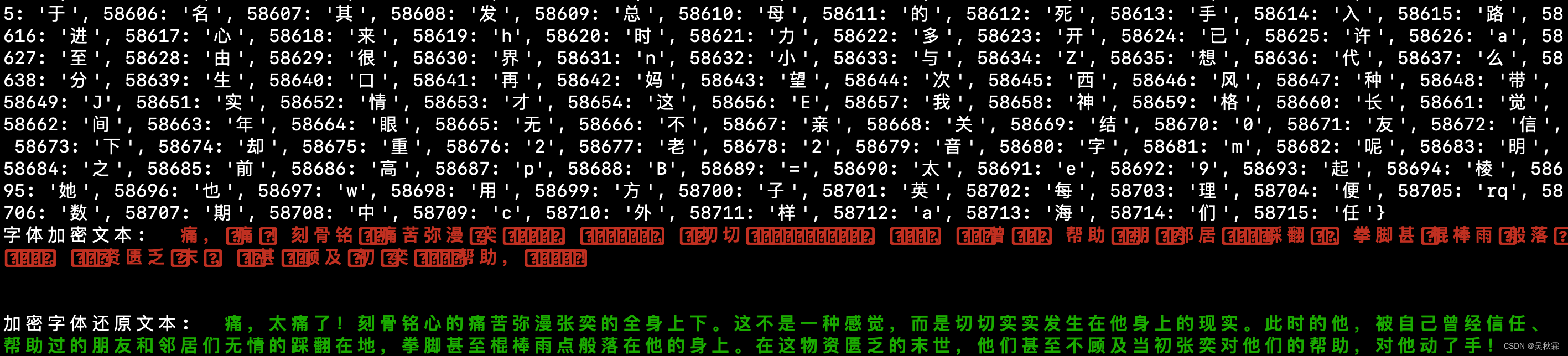
以上是加密字體文字內容還原的全部流程,如需要完整的Python代碼進行測試或學習,可聯系作者獲取!
??好了,到這里又到了跟大家說再見的時候了。創作不易,幫忙點個贊再走吧。你的支持是我創作的動力,希望能帶給大家更多優質的文章


)







)





![Azure[Sky] Dynamic Skybox](http://pic.xiahunao.cn/Azure[Sky] Dynamic Skybox)


