目錄:目錄
看本文章之前,需要學習卷積神經網絡基礎,可參考? sheng的學習筆記-卷積神經網絡-CSDN博客
目錄
LeNet-5
架構圖
層級解析
1、輸入層(Input layer)
2、卷積層C1(Convolutional layer C1)
3、采樣/池化層S2(Subsampling layer S2)
4、卷積層C3(Convolutional layer C3)
5、采樣/池化層S4(Subsampling layer S4)
6、全連接層C5(Fully connected layer C5)
7、全連接層F6(Fully connected layer F6)
8、輸出層(Output layer)
AlexNet
架構圖
AlexNet 模型的特點
1)使用 ReLU 激活函數
2)數據擴充(Data augmentation)
3)重疊池化 (Overlapping Pooling)
4)局部歸一化(Local Response Normalization,簡稱 LRN)
5)Dropout
6)?多 GPU 訓練
詳細的逐層解析
1、第一層(卷積層)
2、第二層(卷積層)
3、第三層(卷積層)
4、第四層(卷積層)
5、第五層(卷積層)
6、第六層(全連接層)
7、第七層(全連接層)
8、第八層(全連接層)
總結圖
?VGG-16
架構圖
參考文章:
卷積神經網絡常用的架構:一個或多個卷積層后面跟著一個池化層,然后又是若干個卷積層再接一個池化層,然后是全連接層,最后是輸出,這種排列方式很常用。
LeNet-5
LeNet-5是一個經典的深度卷積神經網絡,由Yann LeCun在1998年提出,旨在解決手寫數字識別問題,被認為是卷積神經網絡的開創性工作之一。該網絡是第一個被廣泛應用于數字圖像識別的神經網絡之一,也是深度學習領域的里程碑之一。
架構圖
LeNet-5的基本結構包括7層網絡結構(不含輸入層),其中包括2個卷積層、2個降采樣層(池化層)、2個全連接層和輸出層。

- ?從左往右看,隨著網絡越來越深,圖像的高度和寬度在縮小,從最初的32×32縮小到28×28,再到14×14、10×10,最后只有5×5。與此同時,隨著網絡層次的加深,通道數量一直在增加,從1增加到6個,再到16個。這種架構,可以支持的入參 數量,沒有那么多,對于高清圖像的處理沒那么好
- LeNet-5的論文是在1998年撰寫的,當時人們并不使用padding,或者總是使用valid卷積(不填充,padding為0),這就是為什么每進行一次卷積,圖像的高度和寬度都會縮小
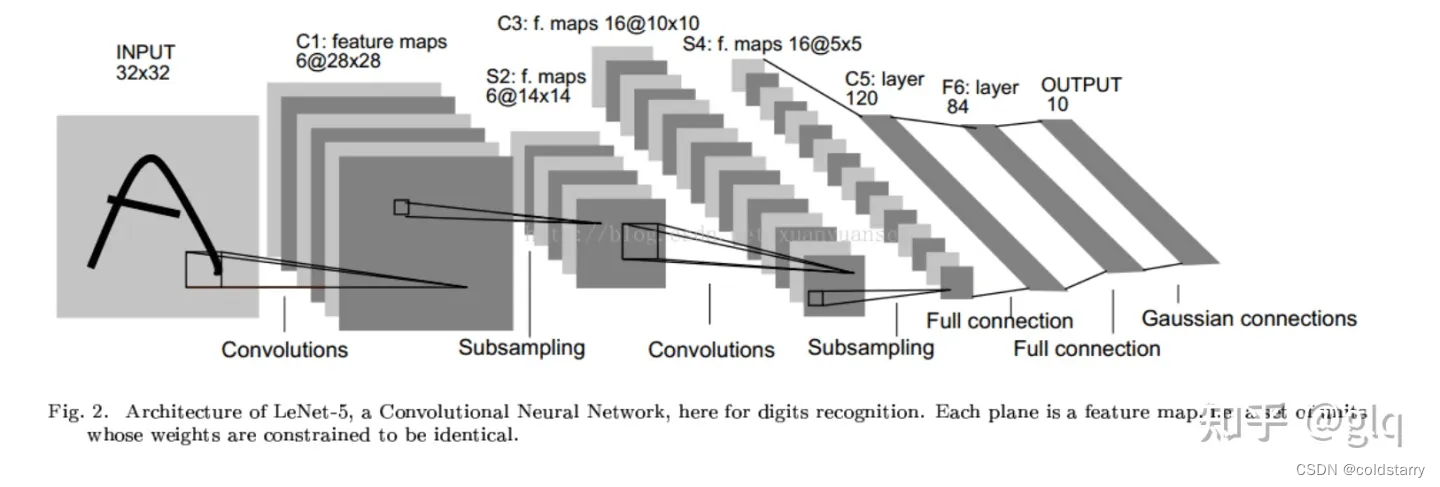
層級解析
1、輸入層(Input layer)
輸入層接收大小為?32×32?的手寫數字圖像,其中包括灰度值(0-255)。在實際應用中,我們通常會對輸入圖像進行預處理,例如對像素值進行歸一化,以加快訓練速度和提高模型的準確性。
2、卷積層C1(Convolutional layer C1)
卷積層C1包括6個卷積核,每個卷積核的大小為?5×5?,步長為1,填充為0。因此,每個卷積核會產生一個大小為?28×28?的特征圖(輸出通道數為6)。
3、采樣/池化層S2(Subsampling layer S2)
采樣層S2采用最大池化(max-pooling)操作,每個窗口的大小為?2×2?,步長為2。因此,每個池化操作會從4個相鄰的特征圖中選擇最大值,產生一個大小為?14×14?的特征圖(輸出通道數為6)。這樣可以減少特征圖的大小,提高計算效率,并且對于輕微的位置變化可以保持一定的不變性。
4、卷積層C3(Convolutional layer C3)
卷積層C3包括16個卷積核,每個卷積核的大小為?5×5?,步長為1,填充為0。因此,每個卷積核會產生一個大小為?10×10?的特征圖(輸出通道數為16)。
5、采樣/池化層S4(Subsampling layer S4)
采樣層S4采用最大池化操作,每個窗口的大小為?2×2?,步長為2。因此,每個池化操作會從4個相鄰的特征圖中選擇最大值,產生一個大小為?5×5?的特征圖(輸出通道數為16)。
6、全連接層C5(Fully connected layer C5)
C5將每個大小為?5×5?的特征圖拉成一個長度為400的向量,并通過一個帶有120個神經元的全連接層進行連接。120是由LeNet-5的設計者根據實驗得到的最佳值。
7、全連接層F6(Fully connected layer F6)
全連接層F6將120個神經元連接到84個神經元。
8、輸出層(Output layer)
輸出層由10個神經元組成,每個神經元對應0-9中的一個數字,并輸出最終的分類結果。在訓練過程中,使用交叉熵損失函數計算輸出層的誤差,并通過反向傳播算法更新卷積核和全連接層的權重參數。
AlexNet
2012 年,Alex Krizhevsky、Ilya Sutskever 在多倫多大學 Geoff Hinton 的實驗室設計出了一個深層的卷積神經網絡 AlexNet,奪得了 2012 年 ImageNet LSVRC 的冠軍,且準確率遠超第二名(top5 錯誤率為 15.3%,第二名為 26.2%),引起了很大的轟動。AlexNet 可以說是具有歷史意義的一個網絡結構,在此之前,深度學習已經沉寂了很長時間,自 2012 年 AlexNet 誕生之后,后面的 ImageNet 冠軍都是用卷積神經網絡(CNN)來做的,并且層次越來越深,使得 CNN 成為在圖像識別分類的核心算法模型,帶來了深度學習的大爆發。
架構圖
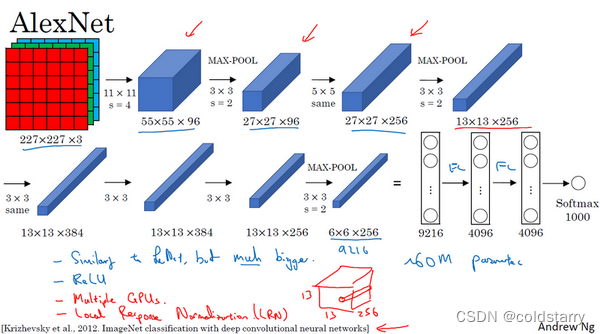
AlexNet首先用一張227×227×3的圖片作為輸入,實際上原文中使用的圖像是224×224×3,但是如果你嘗試去推導一下,你會發現227×227這個尺寸更好一些。
- 第一層我們使用96個11×11的過濾器,步幅為4,由于步幅是4,因此尺寸縮小到55×55,縮小了4倍左右。
- 然后用一個3×3的過濾器構建最大池化層,f=3,步幅s為2,卷積層尺寸縮小為27×27×96。
- 接著再執行一個5×5的卷積,padding之后,輸出是27×27×276。
- 然后再次進行最大池化,尺寸縮小到13×13。
- 再執行一次same卷積,相同的padding,得到的結果是13×13×384,384個過濾器。
- 再做一次same卷積。
- 再做一次同樣的操作,
- 最后再進行一次最大池化,尺寸縮小到6×6×256。6×6×256等于9216,將其展開為9216個單元
- 然后是一些全連接層。
- 最后使用softmax函數輸出識別的結果,看它究竟是1000個可能的對象中的哪一個。
實際上,這種神經網絡與LeNet有很多相似之處,不過AlexNet要大得多。LeNet或LeNet-5大約有6萬個參數,而AlexNet包含約6000萬個參數。當用于訓練圖像和數據集時,AlexNet能夠處理非常相似的基本構造模塊,這些模塊往往包含著大量的隱藏單元或數據。
AlexNet網絡結構看起來相對復雜,包含大量超參數,這些數字(55×55×96、27×27×96、27×27×256……)都是Alex Krizhevsky及其合著者不得不給出的。
AlexNet 模型的特點
AlexNet 之所以能夠成功,跟這個模型設計的特點有關,主要有:
- 使用了非線性激活函數:ReLU
- 防止過擬合的方法:Dropout,數據擴充(Data augmentation)
- 其他:多 GPU 實現,LRN 歸一化層的使用
1)使用 ReLU 激活函數
傳統的神經網絡普遍使用 Sigmoid 或者 tanh 等非線性函數作為激勵函數,然而它們容易出現梯度彌散或梯度飽和的情況。以 Sigmoid 函數為例,當輸入的值非常大或者非常小的時候,這些神經元的梯度接近于 0(梯度飽和現象),如果輸入的初始值很大的話,梯度在反向傳播時因為需要乘上一個 Sigmoid 導數,會造成梯度越來越小,導致網絡變的很難學習。
在 AlexNet 中,使用了 ReLU (Rectified Linear Units)激勵函數,該函數的公式為:f (x)=max (0,x),當輸入信號 < 0 時,輸出都是 0,當輸入信號 > 0 時,輸出等于輸入,如下圖所示:
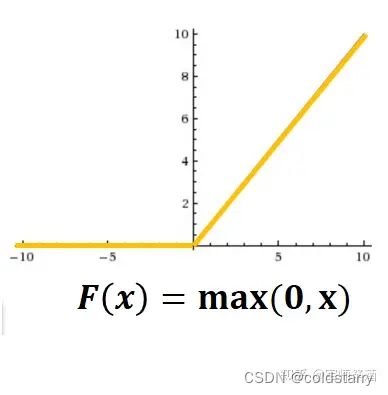
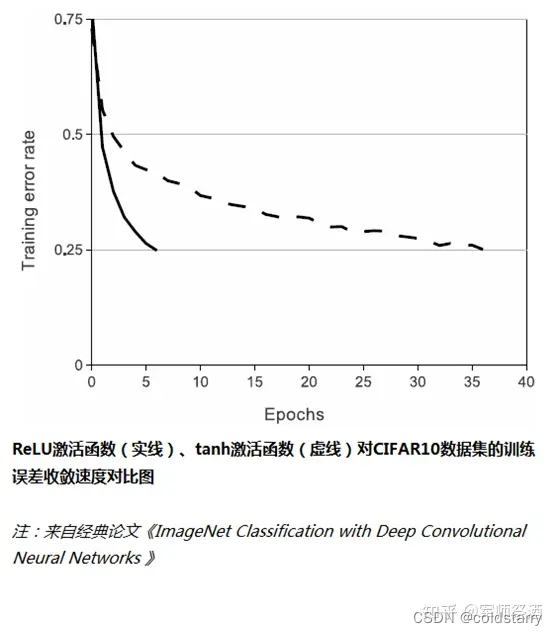
使用 ReLU 替代 Sigmoid/tanh,由于 ReLU 是線性的,且導數始終為 1,計算量大大減少,收斂速度會比 Sigmoid/tanh 快很多,如下圖所示:
2)數據擴充(Data augmentation)
有一種觀點認為神經網絡是靠數據喂出來的,如果能夠增加訓練數據,提供海量數據進行訓練,則能夠有效提升算法的準確率,因為這樣可以避免過擬合,從而可以進一步增大、加深網絡結構。而當訓練數據有限時,可以通過一些變換從已有的訓練數據集中生成一些新的數據,以快速地擴充訓練數據。
其中,最簡單、通用的圖像數據變形的方式:水平翻轉圖像,從原始圖像中隨機裁剪、平移變換,顏色、光照變換,如下圖所示:

AlexNet 在訓練時,在數據擴充(data augmentation)這樣處理:
(1)隨機裁剪,對 256×256 的圖片進行隨機裁剪到 224×224,然后進行水平翻轉,相當于將樣本數量增加了((256-224)^2)×2=2048 倍;
(2)測試的時候,對左上、右上、左下、右下、中間分別做了 5 次裁剪,然后翻轉,共 10 個裁剪,之后對結果求平均。作者說,如果不做隨機裁剪,大網絡基本上都過擬合;
(3)對 RGB 空間做 PCA(主成分分析),然后對主成分做一個(0, 0.1)的高斯擾動,也就是對顏色、光照作變換,結果使錯誤率又下降了 1%。
3)重疊池化 (Overlapping Pooling)
一般的池化(Pooling)是不重疊的,池化區域的窗口大小與步長相同,如下圖所示:
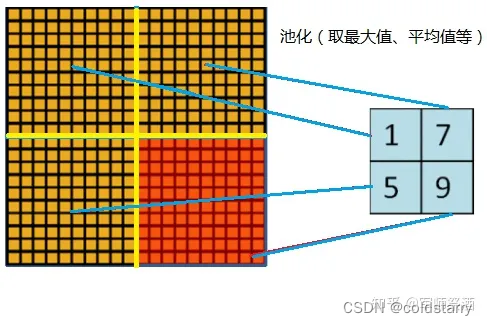
在 AlexNet 中使用的池化(Pooling)卻是可重疊的,也就是說,在池化的時候,每次移動的步長小于池化的窗口長度。AlexNet 池化的大小為 3×3 的正方形,每次池化移動步長為 2,這樣就會出現重疊。重疊池化可以避免過擬合,這個策略貢獻了 0.3% 的 Top-5 錯誤率。
此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果
4)局部歸一化(Local Response Normalization,簡稱 LRN)
局部響應歸一層的基本思路是,假如這是網絡的一塊,比如是13×13×256,LRN要做的就是選取一個位置,比如說這樣一個位置,從這個位置穿過整個通道,能得到256個數字,并進行歸一化。進行局部響應歸一化的動機是,對于這張13×13的圖像中的每個位置來說,我們可能并不需要太多的高激活神經元

5)Dropout
引入 Dropout 主要是為了防止過擬合。在神經網絡中 Dropout 通過修改神經網絡本身結構來實現,對于某一層的神經元,通過定義的概率將神經元置為 0,這個神經元就不參與前向和后向傳播,就如同在網絡中被刪除了一樣,同時保持輸入層與輸出層神經元的個數不變,然后按照神經網絡的學習方法進行參數更新。在下一次迭代中,又重新隨機刪除一些神經元(置為 0),直至訓練結束。
其主要的思想是,隨機減少中間層節點,減少每個節點對最終結果的影響,從而防止過擬合

6)?多 GPU 訓練
AlexNet 當時使用了 GTX580 的 GPU 進行訓練,由于單個 GTX 580 GPU 只有 3GB 內存,這限制了在其上訓練的網絡的最大規模,因此他們在每個 GPU 中放置一半核(或神經元),將網絡分布在兩個 GPU 上進行并行計算,大大加快了 AlexNet 的訓練速度。
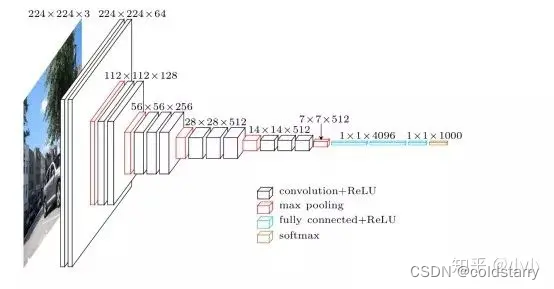
詳細的逐層解析
下圖是 AlexNet 的網絡結構圖:
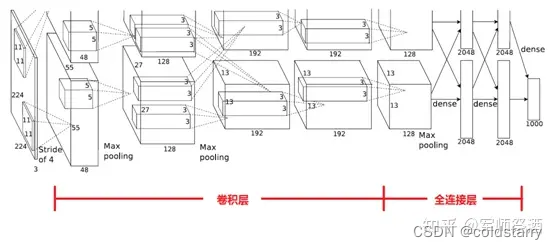
AlexNet 網絡結構共有 8 層,前面 5 層是卷積層,后面 3 層是全連接層,最后一個全連接層的輸出傳遞給一個 1000 路的 softmax 層,對應 1000 個類標簽的分布。
由于 AlexNet 采用了兩個 GPU 進行訓練,因此,該網絡結構圖由上下兩部分組成,一個 GPU 運行圖上方的層,另一個運行圖下方的層,兩個 GPU 只在特定的層通信。例如第二、四、五層卷積層的核只和同一個 GPU 上的前一層的核特征圖相連,第三層卷積層和第二層所有的核特征圖相連接,全連接層中的神經元和前一層中的所有神經元相連接。
下面逐層解析 AlexNet 結構:
1、第一層(卷積層)
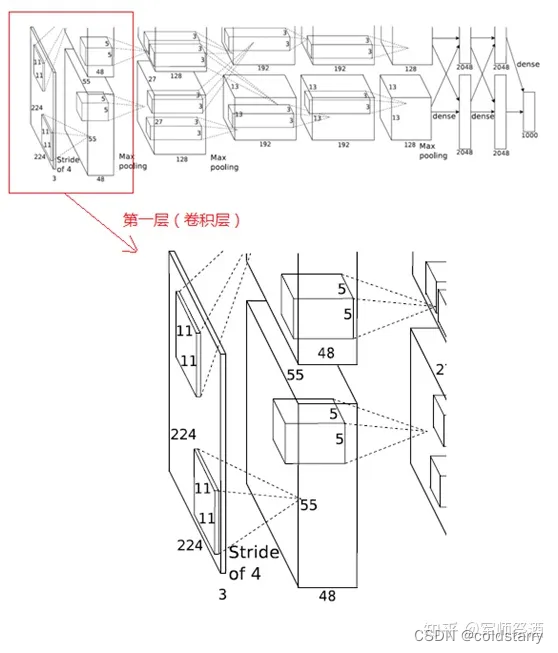
該層的處理流程為:卷積 -->ReLU--> 池化 --> 歸一化,流程圖如下:
(1)卷積
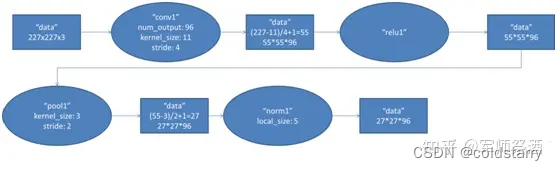
輸入的原始圖像大小為 224×224×3(RGB 圖像),在訓練時會經過預處理變為 227×227×3。在本層使用 96 個 11×11×3 的卷積核進行卷積計算,生成新的像素。由于采用了兩個 GPU 并行運算,因此,網絡結構圖中上下兩部分分別承擔了 48 個卷積核的運算。
卷積核沿圖像按一定的步長往 x 軸方向、y 軸方向移動計算卷積,然后生成新的特征圖,其大小為:floor ((img_size - filter_size)/stride) +1 = new_feture_size,其中 floor 表示向下取整,img_size 為圖像大小,filter_size 為核大小,stride 為步長,new_feture_size 為卷積后的特征圖大小,這個公式表示圖像尺寸減去卷積核尺寸除以步長,再加上被減去的核大小像素對應生成的一個像素,結果就是卷積后特征圖的大小。
AlexNet 中本層的卷積移動步長是 4 個像素,卷積核經移動計算后生成的特征圖大小為 (227-11)/4+1=55,即 55×55。
(2)ReLU
卷積后的 55×55 像素層經過 ReLU 單元的處理,生成激活像素層,尺寸仍為 2 組 55×55×48 的像素層數據。
(3)池化
RuLU 后的像素層再經過池化運算,池化運算的尺寸為 3×3,步長為 2,則池化后圖像的尺寸為 (55-3)/2+1=27,即池化后像素的規模為 27×27×96
(4)歸一化
池化后的像素層再進行歸一化處理,歸一化運算的尺寸為 5×5,歸一化后的像素規模不變,仍為 27×27×96,這 96 層像素層被分為兩組,每組 48 個像素層,分別在一個獨立的 GPU 上進行運算。
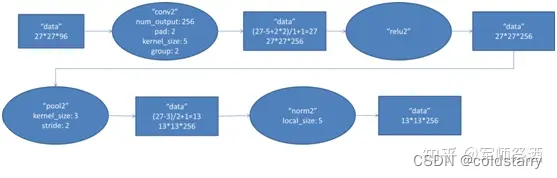
2、第二層(卷積層)
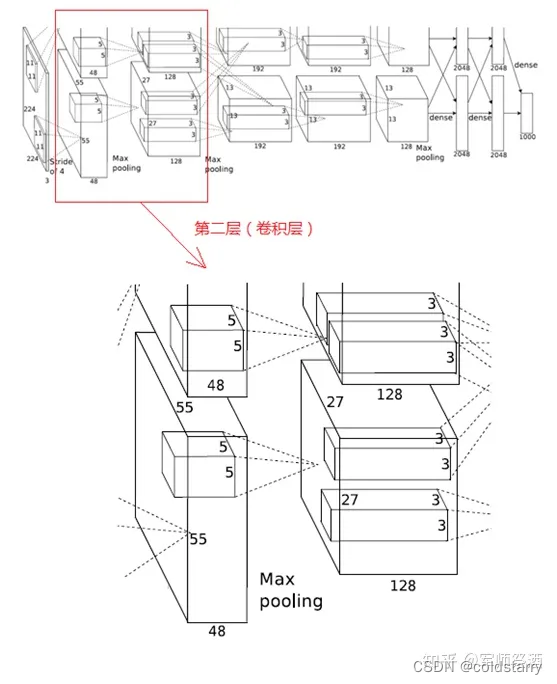
該層與第一層類似,處理流程為:卷積 -->ReLU--> 池化 --> 歸一化,流程圖如下:
(1)卷積
第二層的輸入數據為第一層輸出的 27×27×96 的像素層(被分成兩組 27×27×48 的像素層放在兩個不同 GPU 中進行運算),為方便后續處理,在這里每幅像素層的上下左右邊緣都被填充了 2 個像素(填充 0),即圖像的大小變為 (27+2+2) ×(27+2+2)。第二層的卷積核大小為 5×5,移動步長為 1 個像素,跟第一層第(1)點的計算公式一樣,經卷積核計算后的像素層大小變為 (27+2+2-5)/1+1=27,即卷積后大小為 27×27。
本層使用了 256 個 5×5×48 的卷積核,同樣也是被分成兩組,每組為 128 個,分給兩個 GPU 進行卷積運算,結果生成兩組 27×27×128 個卷積后的像素層。
(2)ReLU
這些像素層經過 ReLU 單元的處理,生成激活像素層,尺寸仍為兩組 27×27×128 的像素層。
(3)池化
再經過池化運算的處理,池化運算的尺寸為 3×3,步長為 2,池化后圖像的尺寸為 (57-3)/2+1=13,即池化后像素的規模為 2 組 13×13×128 的像素層
(4)歸一化
然后再經歸一化處理,歸一化運算的尺度為 5×5,歸一化后的像素層的規模為 2 組 13×13×128 的像素層,分別由 2 個 GPU 進行運算。
3、第三層(卷積層)
?
第三層的處理流程為:卷積 -->ReLU

(1)卷積
第三層輸入數據為第二層輸出的 2 組 13×13×128 的像素層,為便于后續處理,每幅像素層的上下左右邊緣都填充 1 個像素,填充后變為 (13+1+1)×(13+1+1)×128,分布在兩個 GPU 中進行運算。
這一層中每個 GPU 都有 192 個卷積核,每個卷積核的尺寸是 3×3×256。因此,每個 GPU 中的卷積核都能對 2 組 13×13×128 的像素層的所有數據進行卷積運算。如該層的結構圖所示,兩個 GPU 有通過交叉的虛線連接,也就是說每個 GPU 要處理來自前一層的所有 GPU 的輸入。
本層卷積的步長是 1 個像素,經過卷積運算后的尺寸為 (13+1+1-3)/1+1=13,即每個 GPU 中共 13×13×192 個卷積核,2 個 GPU 中共有 13×13×384 個卷積后的像素層。
(2)ReLU
卷積后的像素層經過 ReLU 單元的處理,生成激活像素層,尺寸仍為 2 組 13×13×192 的像素層,分配給兩組 GPU 處理。
4、第四層(卷積層)

與第三層類似,第四層的處理流程為:卷積 -->ReLU
(1)卷積
第四層輸入數據為第三層輸出的 2 組 13×13×192 的像素層,類似于第三層,為便于后續處理,每幅像素層的上下左右邊緣都填充 1 個像素,填充后的尺寸變為 (13+1+1)×(13+1+1)×192,分布在兩個 GPU 中進行運算。
這一層中每個 GPU 都有 192 個卷積核,每個卷積核的尺寸是 3×3×192(與第三層不同,第四層的 GPU 之間沒有虛線連接,也即 GPU 之間沒有通信)。卷積的移動步長是 1 個像素,經卷積運算后的尺寸為 (13+1+1-3)/1+1=13,每個 GPU 中有 13×13×192 個卷積核,2 個 GPU 卷積后生成 13×13×384 的像素層。
(2)ReLU
卷積后的像素層經過 ReLU 單元處理,生成激活像素層,尺寸仍為 2 組 13×13×192 像素層,分配給兩個 GPU 處理。
5、第五層(卷積層)

第五層的處理流程為:卷積 -->ReLU--> 池化
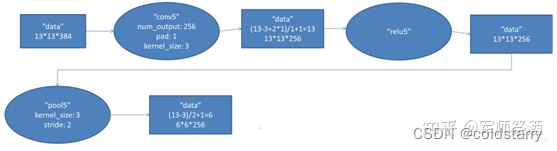
(1)卷積
第五層輸入數據為第四層輸出的 2 組 13×13×192 的像素層,為便于后續處理,每幅像素層的上下左右邊緣都填充 1 個像素,填充后的尺寸變為 (13+1+1)×(13+1+1) ,2 組像素層數據被送至 2 個不同的 GPU 中進行運算。
這一層中每個 GPU 都有 128 個卷積核,每個卷積核的尺寸是 3×3×192,卷積的步長是 1 個像素,經卷積后的尺寸為 (13+1+1-3)/1+1=13,每個 GPU 中有 13×13×128 個卷積核,2 個 GPU 卷積后生成 13×13×256 的像素層。
(2)ReLU
卷積后的像素層經過 ReLU 單元處理,生成激活像素層,尺寸仍為 2 組 13×13×128 像素層,由兩個 GPU 分別處理。
(3)池化
2 組 13×13×128 像素層分別在 2 個不同 GPU 中進行池化運算處理,池化運算的尺寸為 3×3,步長為 2,池化后圖像的尺寸為 (13-3)/2+1=6,即池化后像素的規模為兩組 6×6×128 的像素層數據,共有 6×6×256 的像素層數據。
6、第六層(全連接層)

第六層的處理流程為:卷積(全連接)-->ReLU-->Dropout

(1)卷積(全連接)
第六層輸入數據是第五層的輸出,尺寸為 6×6×256。本層共有 4096 個卷積核,每個卷積核的尺寸為 6×6×256,由于卷積核的尺寸剛好與待處理特征圖(輸入)的尺寸相同,即卷積核中的每個系數只與特征圖(輸入)尺寸的一個像素值相乘,一一對應,因此,該層被稱為全連接層。由于卷積核與特征圖的尺寸相同,卷積運算后只有一個值,因此,卷積后的像素層尺寸為 4096×1×1,即有 4096 個神經元。
(2)ReLU
這 4096 個運算結果通過 ReLU 激活函數生成 4096 個值。
(3)Dropout
然后再通過 Dropout 運算,輸出 4096 個結果值。
7、第七層(全連接層)
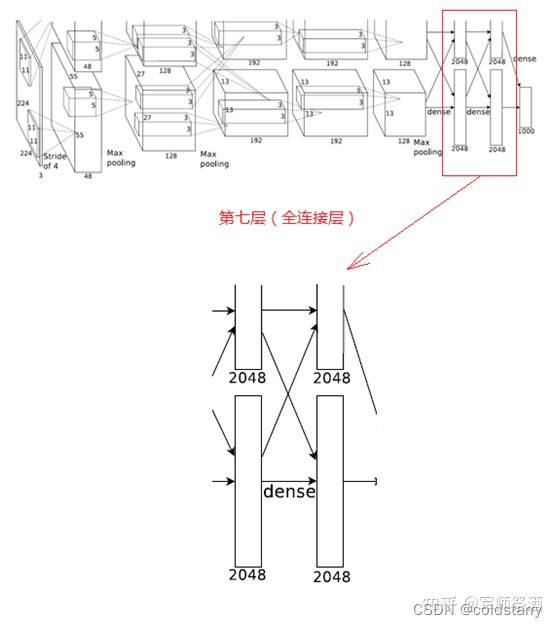
第七層的處理流程為:全連接 -->ReLU-->Dropout
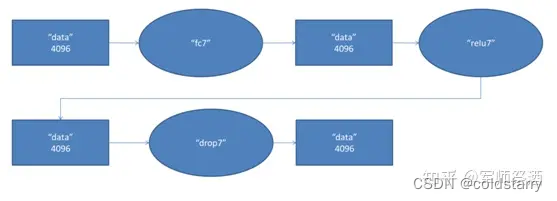
第六層輸出的 4096 個數據與第七層的 4096 個神經元進行全連接,然后經 ReLU 進行處理后生成 4096 個數據,再經過 Dropout 處理后輸出 4096 個數據。
8、第八層(全連接層)

第八層的處理流程為:全連接

第七層輸出的 4096 個數據與第八層的 1000 個神經元進行全連接,經過訓練后輸出 1000 個 float 型的值,這就是預測結果。
總結圖


?VGG-16
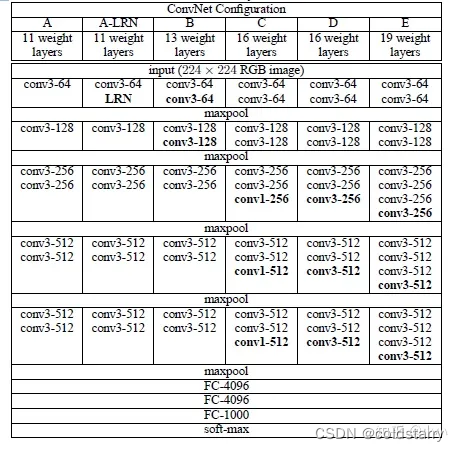
VGGNet 是由牛津大學視覺幾何小組(Visual Geometry Group, VGG)提出的一種深層卷積網絡結構,他們以 7.32% 的錯誤率贏得了 2014 年 ILSVRC 分類任務的亞軍(冠軍由 GoogLeNet 以 6.65% 的錯誤率奪得)和 25.32% 的錯誤率奪得定位任務(Localization)的第一名(GoogLeNet 錯誤率為 26.44%)。VGG可以看成是加深版本的AlexNet. 都是conv layer + FC layer。
論文地址:https://arxiv.org/pdf/1409.1556.pdf
VGG-16的這個數字16,就是指在這個網絡中包含16個卷積層和全連接層(conv+fc的總層數是16,是不包括max pool的層數)。
總共包含約1.38億個參數,但VGG-16的結構并不復雜,而且這種網絡結構很規整,整個網絡都使用卷積核尺寸為 3×3 和最大池化尺寸 2×2,都是幾個卷積層后面跟著可以壓縮圖像大小的池化層,池化層縮小圖像的高度和寬度。同時,卷積層的過濾器數量變化存在一定的規律,由64翻倍變成128,再到256和512。每一步都進行翻倍,或者說在每一組卷積層進行過濾器翻倍操作,正是設計此種網絡結構的另一個簡單原則。這種相對一致的網絡結構對研究者很有吸引力,而它的主要缺點是需要訓練的特征數量非常巨大。?
架構圖

VGG-16網絡沒有那么多超參數,這是一種只需要專注于構建卷積層的簡單網絡。
- 假設這個小圖是我們的輸入圖像,尺寸是224×224×3
- 進行第一個卷積:用64個3×3的過濾器對輸入圖像進行卷積,輸出結果是224×224×64,因為使用了same卷積,通道數量也一樣,
- 接著還有一層224×224×64,得到這樣2個厚度為64的卷積層,意味著我們用64個過濾器進行了兩次卷積

- 接下來創建一個池化層,池化層將輸入圖像進行壓縮,從224×224×64縮小到112×112×64。
- 然后又是若干個卷積層,使用128個過濾器,以及一些same卷積,縮小到112×112×128
- 然后進行池化,可以推導出池化后的結果是這樣(56×56×128)。
- 接著再用256個相同的過濾器進行三次卷積操作,
- 再池化,得到28×28×256
- 再卷積三次,使用512個過濾器,得到28×28×512
- 再池化,得到14×14×512。如此進行幾輪操作后,將最后得到的7×7×512的特征圖進行全連接操作,得到4096個單元,然后進行softmax激活,輸出從1000個對象中識別的結果。
參考文章:
吳恩達的深度學習-卷積神經網絡,第四周
AlexNet - 知乎
卷積神經網絡之VGG - 知乎
 - CMD 指令詳解)

字段去重,并且選擇B(Ingter)字段最大的值)



掛載硬盤/數據盤詳細操作和開機自動掛載的兩種方式)


之同態濾波)



)




)
