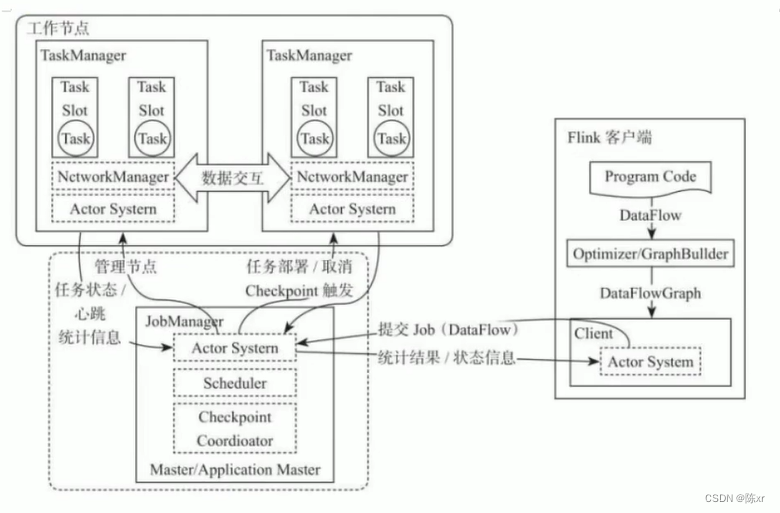
1.Flink原理(角色分工)

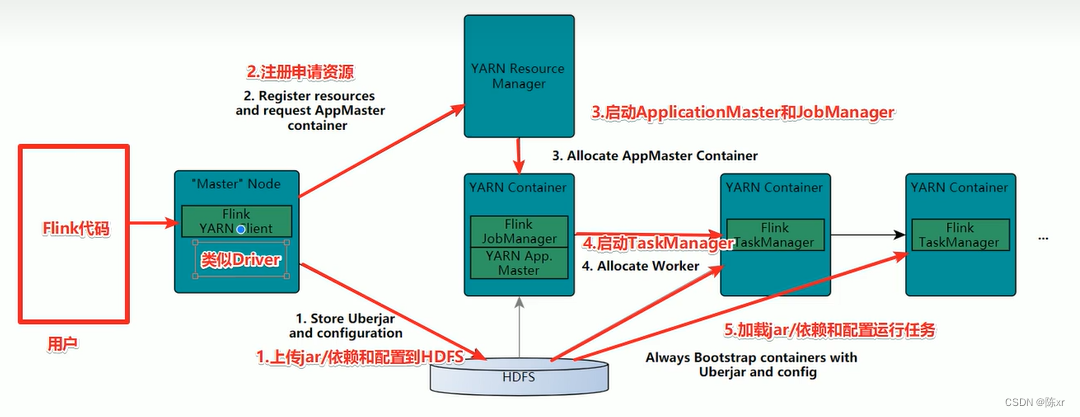
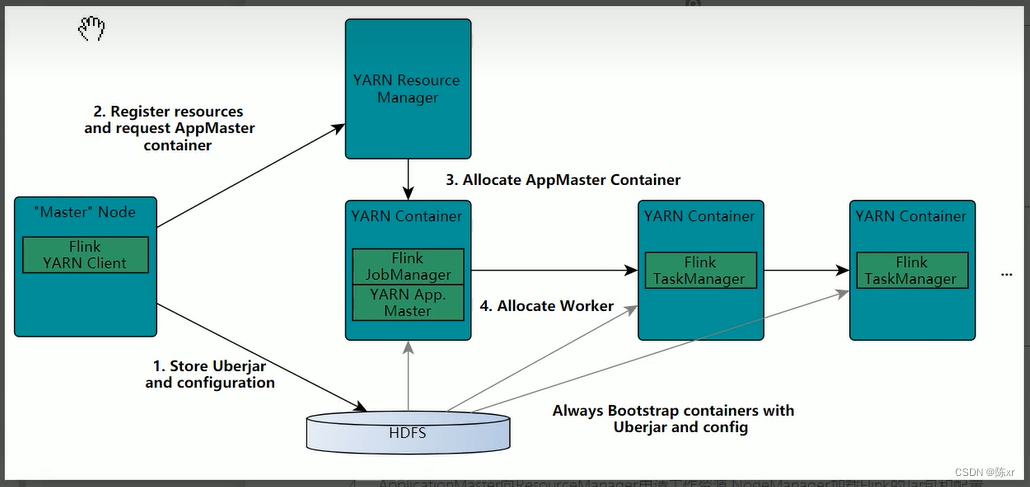
2.Flink執行流程
on yarn版:
3.相關概念
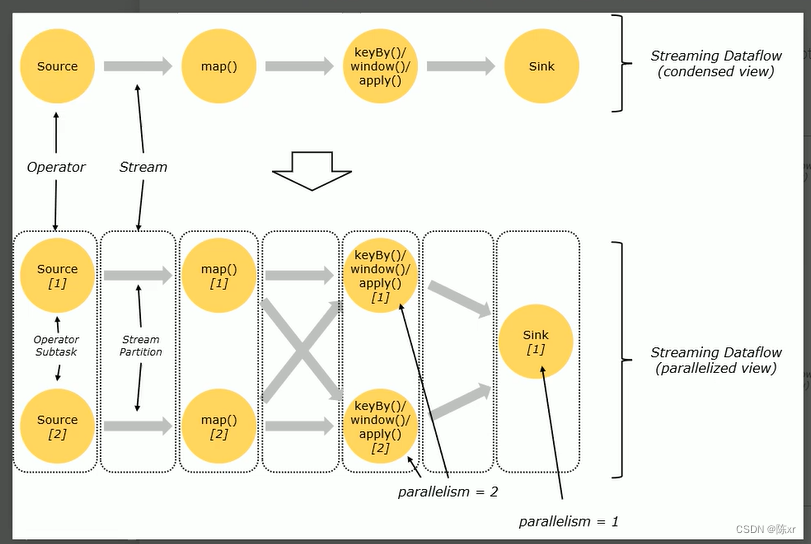
1)DataFlow:Flink程序在執行的時候會被映射成一個數據流模型;
2)Operator:數據流模型中的每一個操作被稱作Operator,Operator分為:Source,Transform,Sink;
3)Partition:數據流模型是分布式和并行的,執行中會形成1-n個分區
4)Subtask:多個分區任務可以并行,每一個都是獨立運行在一個線程中的,也就是一個SubTask子任務;
5)Parallelism:并行度,就是可以同時真正執行的子任務數/分區數。
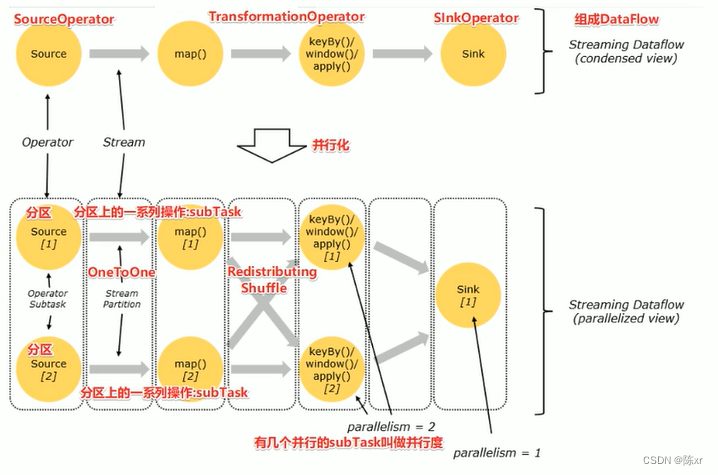
6)Operator傳遞模式
6-1)One to One模式:兩個operator用此模式傳遞的時候,會保持數據的分區數和數據的排序(類似于spark中的窄依賴),多個one to one 的operator可以合并為一個operator chain。
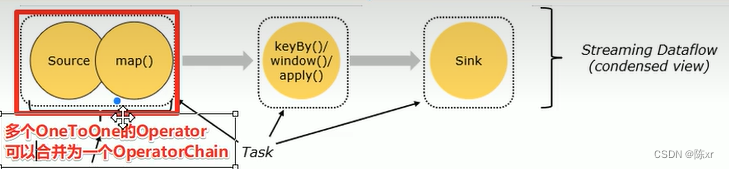
6-2)Redistributing模式:此模式會改變數據的分區數(類似于Spark中的寬依賴)
7)TaskSlot and Slot Sharing
7-1)TaskSlot(任務槽)

每個TaskManager是一個JVM進程,為了控制一個TaskManager(worker)能接收多少task,Flink通過Task slot來進行控制。TaskSlot數量是用來限制一個TaskManager工作進程中可以同時運行多少個工作線程,TaskSlot是一個TaskManager中的最小資源分配單位,一個TaskManager中有多少個TaskSlot就意味著能支持多少并發的Task處理。
7-2)Slot Sharing(槽共享)
前面的Task Slot跑完一些線程任務之后,Task Slot可以給其他線程任務使用,這就是槽共享,這樣的好處是可以避免線程的重復創建和銷毀。
8)ExecutionGraph(Flink執行圖)
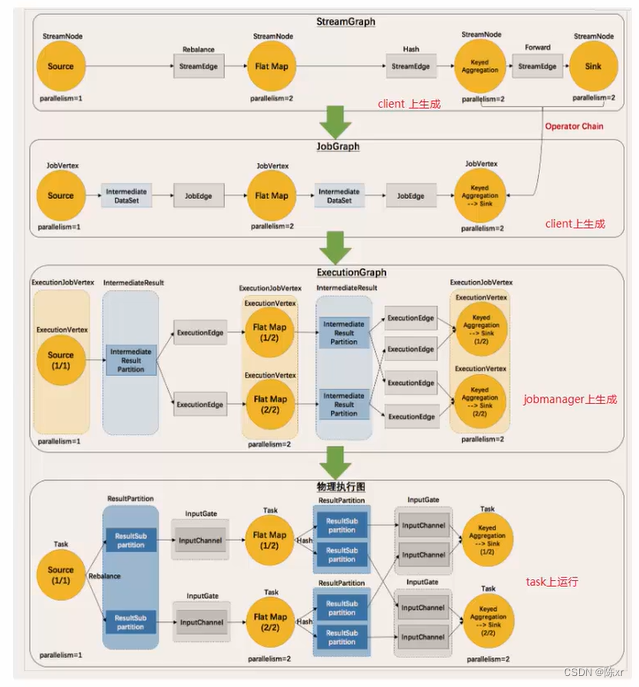
解釋上圖:
(流程化)StreamGraph:最初的程序執行邏輯,也就是算子之間的前后順序 ---- 在Client上生成
(優化合并)JobGraph:將One to One的Operator合并為OperatorChain ---- 在Client上生成
(并行化)ExecutionGraph:將JobGraph根據代碼中設置的并行度和請求的資源進行并行化規劃 ---- 在JobManager上生成
(將任務分配給具體的TaskSlot執行---落實執行線程化)物理執行圖:將ExecutionGraph的并行計劃,落實到具體的TaskManager上,將具體的SubTask落實到具體的TaskSlot內進行運行。
4.Flink流批一體API
前置知識:
{
Flink把流分為:
有邊界的流(bounded Stream):批數據
無邊界的流(unbounded Steam):真正的流數據
流計算和批計算對比:
數據時效性:流式計算實時,批計算非實時,高延遲;
數據特征不同:流式計算的數據一般是動態的,沒有邊界的,而批處理的數據一般則是靜態數據。
應用場景不同:流式計算應用在實時場景,時效性要求比較高的場景,如實時推薦,業務監控等,批處理應用在實時性要求不高,離線計算的場景下,數據分析,離線報表等。
運行方式不同:流式計算的任務持續進行的,批量計算的任務則一次性完成。
}
4-1)Source(數據從哪來)
File-based基于文件:
env.readTextFile(本地/HDFS文件/文件夾);Socket-based基于Socket連接:
env.socketTextStream(主機名,端口號);Collection-based基于集合:
env.fromElemnts();
env.fromCollection();
env.generateSequence();
env.fromSequence();Custom自定義:
Flink還提供了數據源接口,我們實現了這些接口就可以實現自定義數據源獲取數據,不同接口有不同的功能,接口如下:
SourceFunction:非并行數據源(并行度=1)
RichSourceFunction:多功能非并行數據源(并行度=1)
ParallelSourceFunction:并行數據源(并行度可以 > 1)
RichParallelSourceFunction:多功能并行數據源(并行度可以 > 1)--- kafka數據源就使用該接口
---------------------------------------------------------------------------------------------------------------------------------
4-2)Transformation(數據做怎樣的操作處理)
Transformation基本操作:
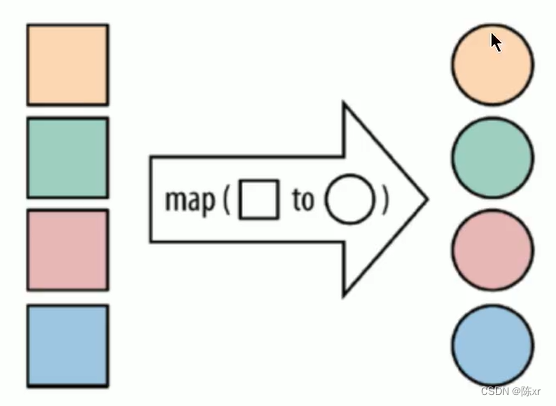
map:j將函數作用在集合中的每一個元素上,并返回作用后的結果。
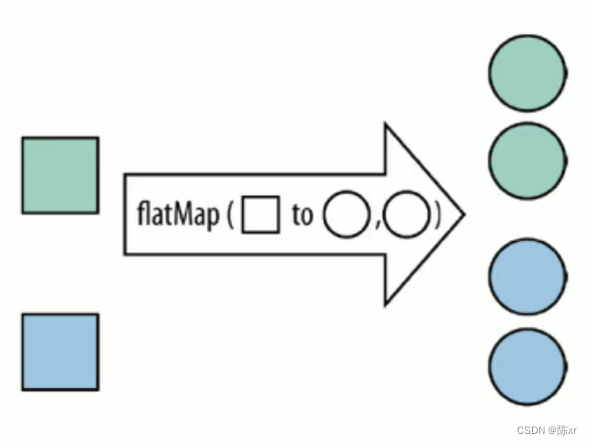
flat Map:將集合中的每個元素變成一個或者多個元素,并返回扁平化之后的結果
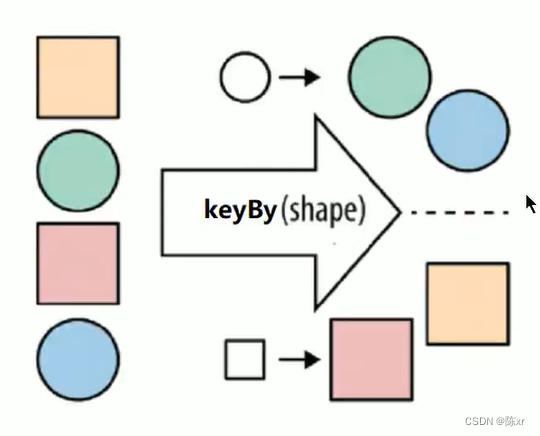
keyBy:按照指定的key來對流中的數據進行分組。注意:流中沒有groupBy,而是keyBy
filter:按照指定的條件對集合中的元素進行過濾,過濾出返回true/符合條件的元素

sum:按照指定的字段對集合中的元素進行求和
reduce:對集合中的元素進行聚合

Transformation合并和拆分:
union:union算子可以合并多個同類型的數據流,并生成同類型的數據流,即可以將多個DataStream[T]合并成為一個新的DataStream[T]。數據按照先進先出FIFO的模式合并。
connect:
和union類似,用來連接兩個數據流,區別在于:connect只可以連接兩個數據流,union可以連接多個;connect所連接的兩個數據流的數據類型可以不一樣,unions所連接的兩個數據流的數據類型必須一樣

split(已廢除),select,side output:
split就是將一個流分成多個流;
select就是獲取分流后對應的數據;
side output:可以使用process方法對流中的數據進行處理,并針對不同的處理結果將數據收集到不同的OuputTag中。
rebalance(重平衡分區):
類似于Spark中的repartition算子,功能更強,可以直接解決數據傾斜(Flink也有數據傾斜的情況,如下圖),在內部使用round robin方法將數據均勻打散。
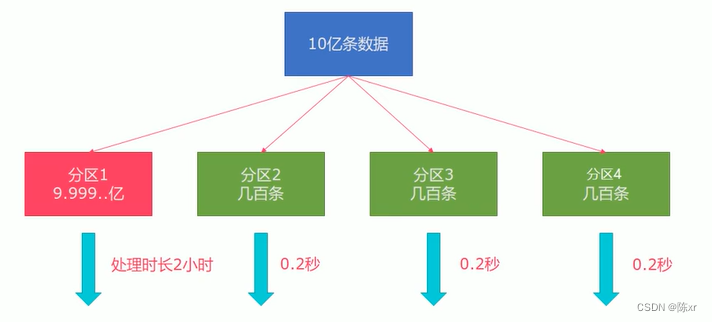
其他分區API:
dataStream.global(); 全部發往第一個Task
dataStream.broadcast(); 廣播
dataStream.forward(); 上下游并發度一樣時一對一發送
dataStream.shuffle(); 隨即均勻分配
dataStream.rebalance(); 輪流分配
dataStream.recale(); 本地輪流分配
dataStream.partitionCustom(); 自定義單播--------------------------------------------------------------------------------------------------------------------------------?
4-3)Sink(數據做怎樣的輸出)
基于控制臺和文件的Sink:
ds.print(); 直接輸出到控制臺
ds.printErr(); 直接輸出到控制臺,用紅色
ds.writeAsText().setParallelism(); 以多少并行度輸出到某個文件路徑?
自定義的Sink。
--------------------------------------------------------------------------------------------------------------------------------
4-4)Connectors(連接外部的工具)
Connectors-JDBC
Flink內已經提供了一些綁定的Connector,例如Kafka source和sink,Es sink等。讀寫Kafka,es,rabiitMQ時可以直接使用相應的connector的API就可以了。
同樣Flink內也提供了專門操作redis的RedisSink。查詢接口文檔使用就行了。
5.Flink高級API
Flink四大基石
Flink流行的原因,就是這四大基石:CheckPoint,State,Time,Window。
a.Flink-Windows操作
使用場景:在流式處理中,數據是源源不斷的,有時候我們需要做一些聚合類的處理。例如,在過去一分鐘內有多少用戶點擊了網頁。此時我們可以定義一個窗口/window,用來收集1分鐘內的數據,并對這個窗口內的數據進行計算。

Flink支持按照
(用的多)時間time:每xx分鐘統計最近xx分鐘的數據
數量count:每xx個數據統計最近xx個數據
兩種類型的窗口形式
按照窗口的形式進行組合有四種窗口:
基于時間的滑動窗口,基于時間的滾動窗口,基于數量的滑動窗口,基于數量的滾動窗口。
---------------------------------------------------------------------------------------------------------------------------------
b.Flink-Time和Watermark
在Flink的流式處理中,會涉及到時間的不同概念
事件時間EventTime:事件真真正正發生/產生的時間(重點關注事件時間)
攝入時間IngestionTime:事件到達Flink的事件
處理時間ProcessingTime:事件真正被處理/計算的時間
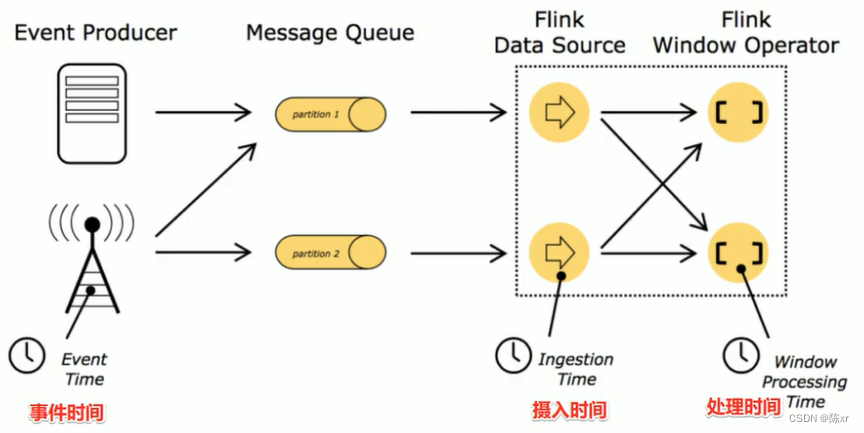
事件時間能夠真正反映/代表事件的本質!所以一般在實際開發中會以事件時間作為計算標準。
總結:
????????實際開發中我們希望基于事件時間來處理數據,但因為數據可能因為網絡延遲等原因,出現了亂序或延遲到達,那么可能處理的結果不是我們想要的甚至出現數據丟失的情況,所以需要一種機制來解決一定程度上的數據亂序或延遲到底的問題!也就是Watermaker水印機制/水位線機制。
什么是Watermark?
就是給數據額外的加的一個時間列,也就是個時間戳。
Watermark = 當前窗口的最大事件事件 - 最大允許的延遲時間或者亂序時間
這樣可以保證Watermaker水位線會一直上升(變大),不會下降。
Watermark的作用:用來觸發窗口計算,通過改變觸發窗口計算的時機,從而在一定程度上解決數據亂序的問題。
---------------------------------------------------------------------------------------------------------------------------------
c.Fink-狀態管理
Flink支持狀態的自動管理。在絕大多數情況下使用Flink提供的自動管理就行了,極少數使用手動的狀態管理。
無狀態計算是什么意思:就是不需要考慮歷史的數據,相同的輸入得到相同的輸出。
有狀態計算(Flink有自動狀態管理了,就少手動去維護狀態管理了吧)就是要考慮歷史的數據,相同而輸入不一定得到相同的輸出。
---------------------------------------------------------------------------------------------------------------------------------
d.Flink-容錯機制
State和CheckPoint的區別:
State:
維護/存儲的是某一個Operator的運行的狀態/歷史值,是維護在內存中!
一般指一個具體的Operator的狀態(operator的狀態表示一些算子在運行的過程中會產生的一些歷史結果如前面的maxBy底層會維護當前的最大值,也就是會維護一個keyedOperator,這個State里面存放就是maxBy這個Operator中的最大值)
CheckPoint:
某一時刻,Flink中所有的Operator的當前State的全局快照,一般存在磁盤上(一般放HDFS上)。
表示了一個Flink Job在一個特定時刻的一份全局狀態快照,即包含了所有Operator的狀態可以理解為Checkpoint是把State數據定時持久化存儲了。
比如KafkaConsumer算子中維護的Offset狀態,當任務重新恢復的時候可以從Checkpoint中獲取。
6.狀態恢復和重啟策略
重啟策略分類:
默認重啟策略:配置了Checkpoint的情況下不做任務配置,默認是無限重啟并自動恢復,可以解決小問題,但是可能會隱藏掉真正的bug。
無重啟策略:使用API配置不重啟即可。
固定延遲重啟策略(開發中使用):調用API,配置固定時間or多少次數重啟
失敗率重啟策略(開發偶爾使用):調用API,可以選擇每個測量階段內最大失敗次數;失敗率測量的時間間隔;兩次連續重啟的時間間隔來重啟。
7.SavePoint(本質就是手動的CheckPoint)
實際開發中,如果要對集群進行停機維護/擴容,這個時候需要執行一次SavePoint,也就是執行一次手動的CheckPoint,那么這樣的話,程序所有的狀態都會被執行快照并保存。當擴容/維護完畢后,可以從上一次的checkpoint的目錄中恢復。
8.Flink Table API 和 SQL(重點)
和Hive,Spark SQL一樣,Flink也選擇用SQL語言來進行業務程序的編寫,為什么?
因為Java,Scala等開發語言難度較高,SQL語言簡單,能迅速上手,因此Flink也是將Flink Table API & SQL作為未來的核心API。
Flink Table API & SQL的特點:
聲明式 --- 用戶只關心做什么,不用關心怎么去做
高性能 --- 支持查詢優化,可以獲取更好的執行性能
流批統一 --- 相同的統計邏輯,既可以支持流模式運行,也可以支持批模式運行
標準穩定 --- 語音遵循SQL標準,不易變動
易理解 --- 語義明確,所見即所得
9.動態表和連續查詢
動態表:就是源源不斷地數據不斷地添加到表的末尾
連續查詢:連續查詢需要借助state狀態管理
10.Spark vs Flink
1)應用場景
Spark主要做離線批處理,對延時要求不高的實時處理(微批)
Flink主要用于實時處理,Flink 1.12支持流批一體
2)API上
Spark:RDD(不推薦)/ DSteam(不推薦)/? DataFrame和DataSet
Flink:DataSet(軟棄用)和DataSteam / Tabel API & SQL
3)核心角色和原理
Spark:

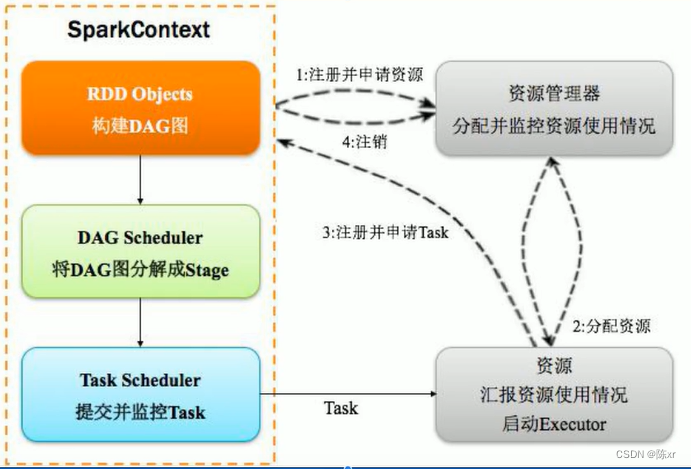
Flink:
4)時間機制
Spark:SparkSteaming只支持處理時間,StructuredSteaming開始支持事件時間
Flink:直接支持事件時間/處理時間/攝入時間
5)容錯機制
Spark:緩存/ 持久化+ checkpoint(應用級別)
Flink:State + CheckPoint(Operator級別,顆粒度更小) + 自動重啟策略 + SavePoint
6)窗口
Spark中支持時間,數量的滑動和滾動窗口,要求windowDuration和SlideDuration必須是batchDuration的倍數
Flink中的窗口機制更加靈活/功能更多,支持基于時間/數量的滑動/滾動 和 會話窗口
Flink保姆級教程,超全五萬字,學習與面試收藏這一篇就夠了_flink 教程-CSDN博客




)







)


)
)

)
