搭建類似joinquant、tushare類似的私有數據服務應用,有以下一些點需要注意:
需要說明的是,這里討論的是web api前后端,當然還有其它方案,thrift,grpc等。因為要考慮到一魚兩吃,本文只探討web api。在web api的基礎上,可以提供封裝sdk庫,供前端函數式調用服務或純手動寫restful api 的方式,自己封裝調用函數服務。
一、性能
性能主要取決于后端,前端可以考慮性能更好的語言、多線程和異步。
后端開發上,主要是序列化+壓縮。
1、序列化
需要考慮跨語言的問題。比如,如果后端用python開發,用pickle序列化,前端用julia,用rust調用就會存在反序列化的問題。
如果用json序列化,雖然會通用,但效率卻會比較低下。
阿里的Fury據說是一個跨語言的序列化的庫,沒有試用過。
https://furyio.org
python:
pip install pyfury
 比如python:
比如python:
from typing import Dict
import pyfuryclass SomeClass:f1: "SomeClass"f2: Dict[str, str]f3: Dict[str, str]fury = pyfury.Fury(ref_tracking=True)
fury.register_class(SomeClass, "example.SomeClass")
obj = SomeClass()
obj.f2 = {"k1": "v1", "k2": "v2"}
obj.f1, obj.f3 = obj, obj.f2
data = fury.serialize(obj)
# bytes can be data serialized by other languages.
print(fury.deserialize(data))
這個庫,正好緩解不少跨語言的痛點。但是并不一定可以解決所有語言的痛點,比如,對于R,或C#呢,就不知道是否可以。
當然,還是有其它解決辦法的。比如,可以在這個基礎上進行跨語言ffi封裝,不過技術上會復雜一些。
2、壓縮
不僅需要考慮性能,選擇讀寫高效的庫,而且還要考慮跨語言的問題。
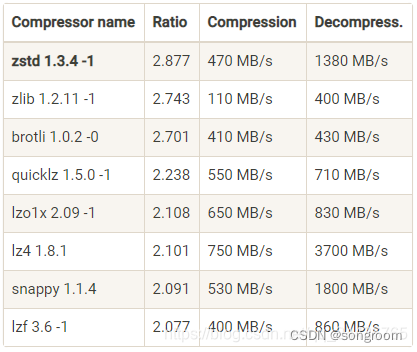
顯然,API是要跨網絡的,對壓縮比,以及壓縮和解壓來綜合考量比較,需要根據場景來選取。有人喜歡zstd,也有人喜歡別的。
3、數據庫還是文件系統
這個具體還是要看場景(并發、性能、硬件條件等),看應用服務的要求,各有優點。
(1)數據庫
是選擇TDengine,還是Clickhouse,還是DolphinDB? 還是采用其它?當然性能(讀/寫還是讀和寫)要求高,一般的數據庫就不需要考慮了(如mysql之類)。
(2)文件系統
是選擇Hdf5?還是Feather,還是Parquet,還有 Jay?Csv文件格式當源數可以考慮,但是當文件服務的一線服務支持,性能太差了。
Parquet壓縮比好,但速度略慢于Feather。hdf5對字符串性能要差,需要進行特別處理。最好還是把最常用的數據格式做個比較,還要看看空間占用情況。
hdf5文件我還碰到過硬盤空間澎脹(空間占用異常暴漲)的事情,這些都需要自已摸索。
4、異步
后端如果采用異步的方式,有利于提升并發的效率。這里異步的框架的深度和廣度,也需要進一步探討。是在網絡IO層,還是包括數據庫的訪問?
就異步而言,異步支持最好的是rust,特別適合做后端。
5、帶寬資源
這個主要看你有多豪了。沒什么說的,上預算。
二、前端的靈活性
1、關于前端服務模式的適用性
可以考慮在前端提供不同的選擇,比如,是python sdk模式(提供安裝包),還是純restful模式(手寫post,get等),以及不同的語言選擇,來指定特定后端的序列化和壓縮庫的選擇,便于前端有更好的適用性和體驗。
這個可以在前端的headers中,或者post的params參數中,可以帶入讓后端判斷的參數即可以。
這個可以通過寫比較詳細的示例,讓大家更易于上手。
2、關于前端服務對后端的約束
前端如果python用戶多,后端用python開發有使用上有一定的優勢。前后端數據格式容易對齊(序列化)和Dataframe等。rust也非常適合,可以通過PYO3提供相應的前端適用服務封裝。包括polars也是rust封裝的,pandas2.x上有很多還趕不上。
)


)
)

)

)



平滑處理與常見函數)


)
和Object.defineProperty使用詳細,Vue2和vue3中雙向數據綁定的原理)


