目錄
摘要
SwinTransformer原理
代碼實現
YOLOv8詳細添加步驟
?ymal文件內容
one_swinTrans
three_swinTrans
啟動命令
完整代碼分享
摘要
Swin Transformer通過引入創新的分層注意力機制展現了其架構的獨特性,該機制通過將注意力區域劃分為塊并在這些塊內執行操作,從而有效降低了計算復雜性。其主要結構呈現分層形式,每個階段包括一組基礎塊,負責捕捉不同層次的特征表示,形成了分層的特征提取過程。采用多尺度的注意力機制使得模型能夠同時關注不同大小的特征,從而提高對圖像中不同尺度信息的感知。在多個圖像分類基準數據集上,Swin Transformer表現出與其他先進模型相媲美甚至更優的性能,且在相對較少的參數和計算成本下取得出色的結果。其模塊化設計使得它在目標檢測和語義分割等其他計算機視覺任務上也具備良好的通用性。
SwinTransformer原理
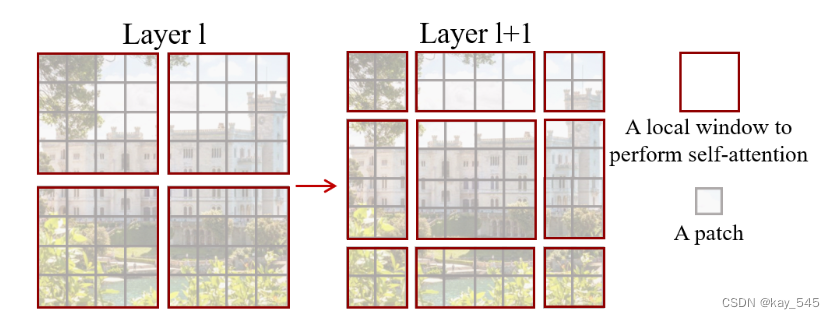
Swin Transformer 的一個關鍵設計元素是連續自注意力層之間窗口分區的移動,如圖所示。移動的窗口橋接了前一層的窗口,提供了它們之間的連接,從而顯著增強了建模能力。這種策略在現實世界的延遲方面也很有效:窗口內的所有查詢補丁共享相同的密鑰,這有利于硬件中的內存訪問。相比之下,早期基于滑動窗口的自注意力方法 由于不同查詢像素的鍵集不同,因此在通用硬件上延遲較低。
下圖概述了 Swin Transformer 架構,其中展示了微型版本 。它首先通過補丁分割模塊(如 ViT)將輸入 RGB 圖像分割成不重疊的補丁。每個補丁都被視為一個“token”,其特征被設置為原始像素 RGB 值的串聯。在我們的實現中,我們使用 4 × 4 的 patch 大小,因此每個 patch 的特征維度為 4 × 4 × 3 = 48。線性嵌入層應用于此原始值特征,將其投影到任意維度(記為C)
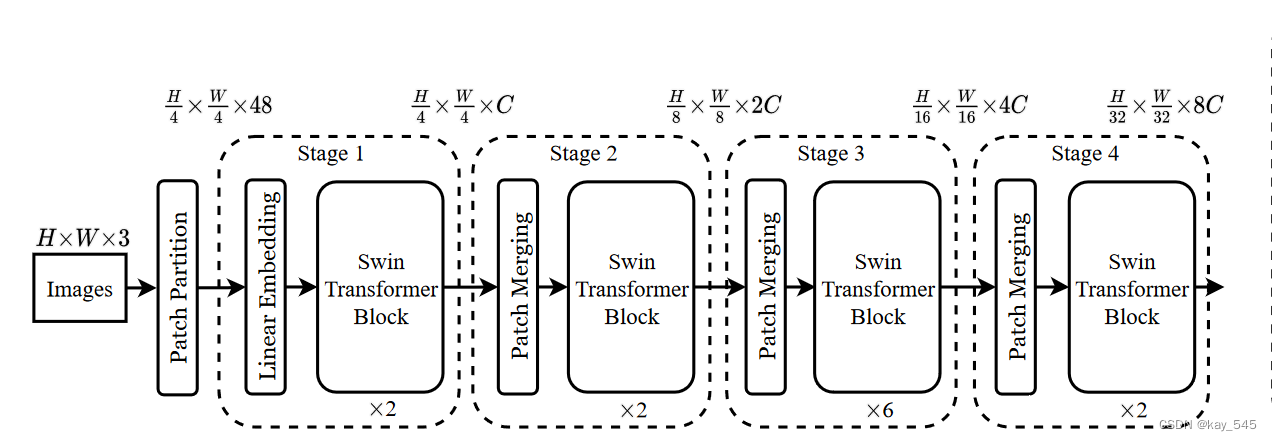
在這些補丁token上應用了幾個經過修改的自注意力計算的 Transformer 塊(Swin Transformer 塊)。 Transformer 塊維護tokens數量 ( H/4 ×W/4 ),與線性嵌入一起被稱為“階段 1”
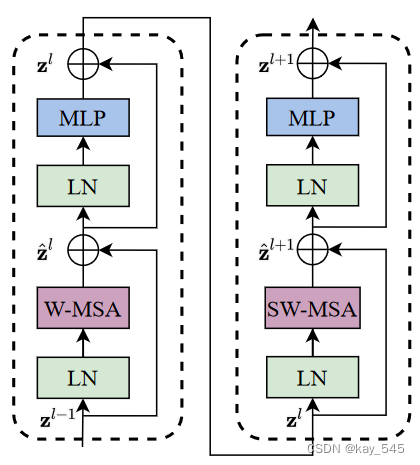
Swin Transformer 是通過將 Transformer 塊中的標準多頭自注意力(MSA)模塊替換為基于移位窗口的模塊而構建的,其他層保持不變。如上圖所示,Swin Transformer 模塊由基于移位窗口的 MSA 模塊組成,后跟中間帶有 GELU 非線性的 2 層 MLP。在每個 MSA 模塊和每個 MLP 之前應用 LayerNorm (LN) 層,并在每個模塊之后應用殘差連接。
代碼實現
class WindowAttention(nn.Module):def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)nn.init.normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)# print(attn.dtype, v.dtype)try:x = (attn @ v).transpose(1, 2).reshape(B_, N, C)except:# print(attn.dtype, v.dtype)x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass SwinTransformer(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(SwinTransformer, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.m(self.cv1(x))y2 = self.cv2(x)return self.cv3(torch.cat((y1, y2), dim=1))class SwinTransformerB(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(Swin_Transformer_B, self).__init__()c_ = int(c2) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1, 1)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):x1 = self.cv1(x)y1 = self.m(x1)y2 = self.cv2(x1)return self.cv3(torch.cat((y1, y2), dim=1))class SwinTransformerC(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(Swin_Transformer_C, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(c_, c_, 1, 1)self.cv4 = Conv(2 * c_, c2, 1, 1)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(torch.cat((y1, y2), dim=1))class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xdef window_partition(x, window_size):B, H, W, C = x.shapeassert H % window_size == 0, 'feature map h and w can not divide by window size'x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass SwinTransformerLayer(nn.Module):def __init__(self, dim, num_heads, window_size=8, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.SiLU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratio# if min(self.input_resolution) <= self.window_size:# # if window size is larger than input resolution, we don't partition windows# self.shift_size = 0# self.window_size = min(self.input_resolution)assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def create_mask(self, H, W):# calculate attention mask for SW-MSAimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))return attn_maskdef forward(self, x):# reshape x[b c h w] to x[b l c]_, _, H_, W_ = x.shapePadding = Falseif min(H_, W_) < self.window_size or H_ % self.window_size != 0 or W_ % self.window_size != 0:Padding = True# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')pad_r = (self.window_size - W_ % self.window_size) % self.window_sizepad_b = (self.window_size - H_ % self.window_size) % self.window_sizex = F.pad(x, (0, pad_r, 0, pad_b))# print('2', x.shape)B, C, H, W = x.shapeL = H * Wx = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c# create mask from init to forwardif self.shift_size > 0:attn_mask = self.create_mask(H, W).to(x.device)else:attn_mask = Noneshortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = x# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xx = x.view(B, H * W, C)# FFNx = shortcut + self.drop_path(x)x = x + self.drop_path(self.mlp(self.norm2(x)))x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h wif Padding:x = x[:, :, :H_, :W_] # reverse paddingreturn xclass SwinTransformerBlock(nn.Module):def __init__(self, c1, c2, num_heads, num_layers, window_size=8):super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)# remove input_resolutionself.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2) for i inrange(num_layers)])def forward(self, x):if self.conv is not None:x = self.conv(x)x = self.blocks(x)return xYOLOv8詳細添加步驟
1. 復制以上代碼在?ultralytics/nn/modules/conv.py 添加
2. 在ultralytics/nn/modules/init.py 注冊SwinTransformer
3. 在ultralytics/nn/task.py 注冊SwinTransformer(兩處注冊)
4. 成功添加SwinTransformer
?ymal文件內容
one_swinTrans
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 6 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, SwinTransformer, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)three_swinTrans
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 6 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, SwinTransformer, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, SwinTransformer, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, SwinTransformer, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
啟動命令
from ultralytics import YOLO# Load a model
# model = YOLO('yolov8s.yaml') # build a new model from YAML
model = YOLO('/ultralytics/cfg/models/v8/yolov8_swinTrans.yaml') # load a pretrained model (recommended for training)
# model = YOLO('yolov8s.yaml').load('yolov8s.pt') # build from YAML and transfer weights# Train the model
if __name__ == '__main__':model.train( )
完整代碼分享
https://download.csdn.net/download/m0_67647321/88890624



——多態)



)



有案例!)
)






)
