一、分類模型簡介
本篇將介紹分類模型。對于二分類模型,我們將介紹邏輯回歸(logistic regression)和Fisher線性判別分析兩種分類算法;對于多分類模型,我們將簡單介紹SPSS中的多分類線性判別分析和多分類邏輯回歸。
分類模型,顧名思義將數據分類。如有一堆蘋果和橙子,有它們的重量,大小,顏色等數據,將它們根據數據分為兩類,之后如果給出數據,可以進行一定的判斷,這個只有數據的是蘋果還是橙子。
二、適用賽題
預測類
- 由已知數據處理分類得到模型
- 對后來的數據進行預測
三、模型流程
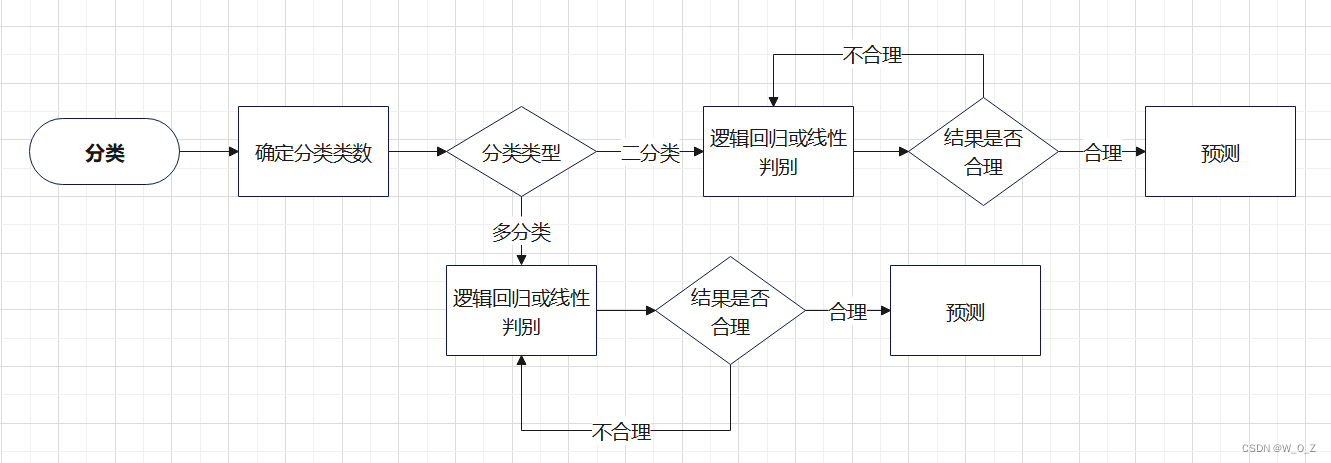
四、流程分析
本篇中的邏輯回歸和Fisher線性判別不做證明,且邏輯回歸和Fisher線性判別推薦使用SPSS軟件進行操作
1.確定分類
分類模型有二分類和多分類兩種,開始先得確定要分多少類。比如上面的蘋果和橙子例子就是二分類;如果水果種類再多點,像蘋果、橙子、檸檬和橘子,就是多分類問題。
2.二分類
①邏輯回歸
對于因變量為分類變量的情況,我們可以使用邏輯回歸進行處理。把y看成事件發生的概率,y ≥ 0.5表示發生;y < 0.5表示不發生。比如可以說y ≥ 0.5是蘋果,y < 0.5是橙子。
線性概率模型(Linear Probability Model 簡記LPM)



由于后者有解析表達式(而標準正態分布的cdf沒有),所以計算logistic模型比probit模型更為方便。


②Fisher線性判別分析
LDA(Linear Discriminant Analysis)是一種經典的線性判別方法,又稱Fisher判別分析。該方法思想比較簡單:給定訓練集樣例,設法將樣例投影到一維的直線上,使得同類樣例的投影點盡可能接近和密集,異類投影點盡可能遠離。
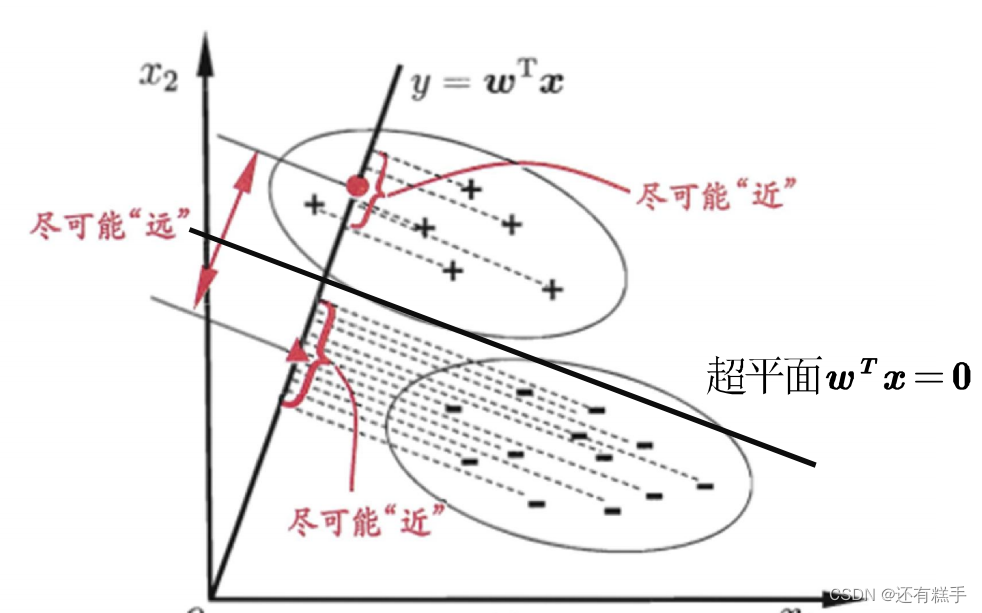
可借助SPSS軟件直接得到結果。
3.多分類
多分類的操作和二分類類似,這里不再贅述。
4.合理性
如果預測結果較差怎么辦?
可在Logistic回歸模型中加入平方項、交互項等。
但在加入平方項之后,雖然預測能力提高了,但有可能會出現過擬合現象。
也就是對于樣本數據的預測非常好,但是對于樣本外的數據的預測效果可能會很差。
所以如何確定合適的模型?
把數據分為訓練組和測試組,用訓練組的數據來估計出模型,再用測試組的數據來進行測試。(訓練組和測試組的比例一般設置為80%和20%)
注意:為了消除偶然性的影響,可以對上述步驟多重復幾次,最終對每個模型求--個平均的準確率,這個步驟稱為交叉驗證。
5.預測
根據給出的數據,計算得到屬于哪個類別的可能性最大。





)













