目錄
- Python 正則表達式
- Finding Patterns of Text Without Regular Expressions
- Finding Patterns of Text with Regular Expressions
- Creating Regex Objects
- Matching Regex Objects
- Review of Regular Expression Matching
- More Pattern Matching with Regular Expressions
- Grouping with Parentheses
- Matching Multiple Groups with the Pipe
- Optional Matching with the Question Mark
- Matching Zero or More with the Star
- Matching One or More with the Plus
- Matching Specific Repetitions with Braces
- Greedy and Non-greedy Matching
- The findall() Method
- Character Classes
- Making Your Own Character Classes
- The Caret and Dollar Sign Characters
- The Wildcard Character
- Matching Everything with Dot-Star
- Matching Newlines with the Dot Character
- Review of Regex Symbols
- Case-Insensitive Matching
- Substituting Strings with the sub() Method
- Managing Complex Regexes
- Combining re.IGNORECASE, re.DOTALL, and re.VERBOSE
- Project: Phone Number and Email Address Extractor
- Step 1: Create a Regex for Phone Numbers
- Step 2: Create a Regex for Email Addresses
- Step 3: Find All Matches in the Clipboard Text
- Step 4: Join the Matches into a String for the Clipboard
Python 正則表達式

您可能熟悉通過按 CTRL-F 并輸入您要查找的單詞來搜索文本。正則表達式更進一步:它們允許您指定要搜索的文本模式。您可能不知道企業的確切電話號碼,但如果您居住在美國或加拿大,您知道它將是三位數字,后跟連字符,然后是四位數字(以及可選的三位數區號,位于開始)。作為人類,您看到電話號碼時就是這樣知道的:415-555-1234 是電話號碼,但 4,155,551,234 不是。
我們每天還識別各種其他文本模式:電子郵件地址中間有@符號,美國社會安全號碼有九個數字和兩個連字符,網站URL通常有句號和正斜杠,新聞標題使用標題大小寫,社交媒體主題標簽以 # 開頭且不包含空格等。
正則表達式很有用,但很少有非程序員了解它們,盡管大多數現代文本編輯器和文字處理程序(例如 Microsoft Word 或 OpenOffice)都具有可以基于正則表達式進行搜索的查找和查找和替換功能。正則表達式不僅對于軟件用戶而且對于程序員來說都可以節省大量時間。事實上,科技作家科里·多克托羅 (Cory Doctorow) 認為,我們甚至應該在編程之前就學習正則表達式:
知道[正則表達式]意味著用 3 步解決問題和用 3,000 步解決問題之間的區別。當你是一個書呆子時,你會忘記,你通過幾次按鍵就能解決的問題可能需要其他人花費數天的乏味且容易出錯的工作才能完成。
在本章中,您將首先編寫一個程序來查找文本模式而不使用正則表達式,然后了解如何使用正則表達式來使代碼不那么臃腫。我將向您展示與正則表達式的基本匹配,然后繼續介紹一些更強大的功能,例如字符串替換和創建您自己的字符類。最后,在本章末尾,您將編寫一個程序,可以自動從文本塊中提取電話號碼和電子郵件地址。
Finding Patterns of Text Without Regular Expressions
假設您想在字符串中查找美國電話號碼。如果您是美國人,您就知道這種模式:三個數字、一個連字符、三個數字、一個連字符和四個數字。示例如下:415-555-4242。
讓我們使用名為 isPhoneNumber() 的函數來檢查字符串是否與此模式匹配,返回 True 或 False。打開一個新的文件編輯器選項卡并輸入以下代碼;然后將文件另存為 isPhoneNumber.py:
def isPhoneNumber(text):? if len(text) != 12:return Falsefor i in range(0, 3):? if not text[i].isdecimal():return False? if text[3] != '-':return Falsefor i in range(4, 7):? if not text[i].isdecimal():return False? if text[7] != '-':return Falsefor i in range(8, 12):? if not text[i].isdecimal():return False? return True
print('Is 415-555-4242 a phone number?')
print(isPhoneNumber('415-555-4242'))
print('Is Moshi moshi a phone number?')
print(isPhoneNumber('Moshi moshi'))
當這個程序運行時,輸出如下所示:

isPhoneNumber() 函數的代碼會執行多次檢查以查看文本中的字符串是否為有效的電話號碼。如果其中任何檢查失敗,該函數將返回 False。首先,代碼檢查字符串是否正好是 12 個字符 ?。然后它檢查區號(即文本中的前三個字符)是否僅由數字字符 ? 組成。該函數的其余部分檢查字符串是否遵循電話號碼的模式:該號碼必須在區號 ? 之后包含第一個連字符,再添加三個數字字符 ?,然后再添加一個連字符 ?,最后再添加四個數字 ?。如果程序執行成功通過了所有檢查,則返回 True ?。
使用參數“415-555-4242”調用 isPhoneNumber() 將返回 True。使用 ‘Moshi moshi’ 調用 isPhoneNumber() 將返回 False;第一個測試失敗,因為“Moshi moshi”長度不足 12 個字符。
如果您想在較大的字符串中查找電話號碼,則必須添加更多代碼來查找電話號碼模式。將 isPhoneNumber.py 中的最后四個 print() 函數調用替換為以下內容:
message = 'Call me at 415-555-1011 tomorrow. 415-555-9999 is my office.'
for i in range(len(message)):? chunk = message[i:i+12]? if isPhoneNumber(chunk):print('Phone number found: ' + chunk)
print('Done')
當這個程序運行時,輸出將如下所示:
 在
在 for 循環的每次迭代中,消息中的 12 個字符的新塊被分配給變量塊 ?。例如,在第一次迭代中,i 為 0,塊被分配為 message[0:12](即字符串“Call me at 4”)。在下一次迭代中,i 為 1,塊被分配為 message[1:13](字符串“all me at 41”)。換句話說,在 for 循環的每次迭代中, chunk 都采用以下值:

您將塊傳遞給 isPhoneNumber() 以查看它是否與電話號碼模式 ? 匹配,如果是,則打印該塊。
繼續循環message,最終chunk中的12個字符將是一個電話號碼。該循環遍歷整個字符串,測試每個 12 個字符的片段并打印它發現的滿足 isPhoneNumber() 的任何塊。一旦我們瀏覽完消息,我們就會打印 Done。
雖然在此示例中消息中的字符串很短,但它可能有數百萬個字符長,并且程序仍將在不到一秒的時間內運行。使用正則表達式查找電話號碼的類似程序也將在不到一秒的時間內運行,但正則表達式可以更快地編寫這些程序。
Finding Patterns of Text with Regular Expressions
以前的電話號碼查找程序可以工作,但它使用大量代碼來完成一些有限的事情: isPhoneNumber() 函數有 17 行,但只能查找一種模式的電話號碼。電話號碼格式如 415.555.4242 或 (415) 555-4242 怎么樣?如果電話號碼有分機號(例如 415-555-4242 x99)怎么辦? isPhoneNumber() 函數將無法驗證它們。您可以為這些附加模式添加更多代碼,但有一種更簡單的方法。
正則表達式,簡稱正則表達式,是對文本模式的描述。例如,正則表達式中的 \d 代表數字字符,即從 0 到 9 的任何單個數字。正則表達式 \d\d??\d-\d\d\d-\d\d\d\d Python 使用 isPhoneNumber() 函數來匹配與之前的 isPhoneNumber() 函數相同的文本模式:由三個數字、一個連字符、另外三個數字、另一個連字符和四個數字組成的字符串。任何其他字符串都不會與 \d\d??\d-\d\d\d-\d\d\d\d 正則表達式匹配。
但正則表達式可以更加復雜。例如,在模式后添加大括號 ({3}) 中的 3 就像在說“匹配該模式三次”。因此,稍短的正則表達式 \d{3}-\d{3}-\d{4} 也匹配正確的電話號碼格式。
Creating Regex Objects
Python 中的所有正則表達式函數都位于 re 模塊中。在交互式 shell 中輸入以下內容以導入此模塊:
Note
本章中的大多數示例都需要 re 模塊,因此請記住在您編寫的任何腳本的開頭或每次重新啟動 Mu 時導入它。否則,您將收到 NameError: name 're' is not Defined 錯誤消息。
將表示正則表達式的字符串值傳遞給 re.compile() 將返回一個 Regex 模式對象(或簡稱為 Regex 對象)。
要創建與電話號碼模式匹配的 Regex 對象,請在交互式 shell 中輸入以下內容。 (請記住, \d 表示“數字字符”,而 \d\d??\d-\d\d\d-\d\d\d\d 是電話號碼模式的正則表達式。)
>>>phoneNumRegex = re.compile(r’\d\d\d-\d\d\d-\d\d\d\d’)
現在,phoneNumRegex 變量包含一個 Regex 對象。
Matching Regex Objects
Regex 對象的 search() 方法搜索它傳遞的字符串以查找與正則表達式的任何匹配項。如果在字符串中找不到正則表達式模式,則 search() 方法將返回 None。如果找到模式,search() 方法將返回一個 Match 對象,該對象有一個 group() 方法,該方法將從搜索字符串中返回實際匹配的文本。 (我將很快解釋組。)例如,在交互式 shell 中輸入以下內容:

mo 變量名稱只是用于 Match 對象的通用名稱。這個示例乍一看可能很復雜,但它比之前的 isPhoneNumber.py 程序要短得多,并且執行相同的操作。
在這里,我們將所需的模式傳遞給 re.compile() 并將生成的 Regex 對象存儲在 phoneNumRegex 中。然后我們在 phoneNumRegex 上調用search() 并將我們想要在搜索過程中匹配的字符串傳遞給 search()。搜索結果存儲在變量 mo 中。在此示例中,我們知道將在字符串中找到我們的模式,因此我們知道將返回一個 Match 對象。知道 mo 包含 Match 對象而不是空值 None,我們可以在 mo 上調用 group() 以返回匹配項。在 print() 函數調用中寫入 mo.group() 會顯示整個匹配項,415-555-4242。
Review of Regular Expression Matching
雖然在 Python 中使用正則表達式有幾個步驟,但每個步驟都相當簡單。
- 使用 import re 導入正則表達式模塊。
- 使用 re.compile() 函數創建 Regex 對象。 (記住使用原始字符串。)
- 將要搜索的字符串傳遞到 Regex 對象的 search() 方法中。這將返回一個 Match 對象。
- 調用 Match 對象的 group() 方法返回實際匹配文本的字符串。
Note
雖然我鼓勵您將示例代碼輸入交互式 shell,但您還應該使用基于 Web 的正則表達式測試器,它可以準確地向您展示正則表達式如何與您輸入的一段文本匹配。我推薦 https://pythex.org/ 上的測試器。
More Pattern Matching with Regular Expressions
既然您已經了解了使用 Python 創建和查找正則表達式對象的基本步驟,您就可以嘗試它們的一些更強大的模式匹配功能了。
Grouping with Parentheses
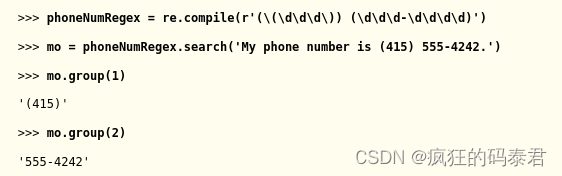
假設您要將區號與電話號碼的其余部分分開。添加括號將在正則表達式中創建組:(\d\d\d)-(\d\d\d-\d\d\d\d)。然后,您可以使用 group() 匹配對象方法從一組中獲取匹配文本。
正則表達式字符串中的第一組括號將是組 1。第二組括號將是組 2。通過將整數 1 或 2 傳遞給 group() 匹配對象方法,您可以抓取匹配文本的不同部分。向 group() 方法傳遞 0 或不傳遞任何內容將返回整個匹配的文本。在交互式 shell 中輸入以下內容:

如果您想一次檢索所有組,請使用 groups() 方法 - 請注意名稱的復數形式。

由于 mo.groups() 返回多個值的元組,因此您可以使用多重賦值技巧將每個值分配給單獨的變量,如前面的 areaCode, mainNumber = mo.groups() 行中所示。
括號在正則表達式中具有特殊含義,但是如果需要匹配文本中的括號該怎么辦?例如,您嘗試匹配的電話號碼可能在括號中設置了區號。在這種情況下,您需要使用反斜杠轉義 ( 和 ) 字符。在交互式 shell 中輸入以下內容:
傳遞給 re.compile() 的原始字符串中的 \( 和 \) 轉義字符將與實際的括號字符匹配。在正則表達式中,以下字符具有特殊含義:
. ^ $ * + ? { } [ ] \ | ( )
. ^ $ * + ? { } [ ] \ | ( )
如果您想將這些字符檢測為文本模式的一部分,則需要使用反斜杠對它們進行轉義:
確保仔細檢查您沒有將轉義括號 ( 和 ) 誤認為是正則表達式中的括號 ( 和 )。如果您收到有關“缺少 )”或“不平衡括號”的錯誤消息,則您可能忘記包含組的未轉義右括號,如下例所示:

該錯誤消息告訴您,r'(\(Parentheses\)' 字符串的索引 0 處有一個左括號,缺少相應的右括號。
Matching Multiple Groups with the Pipe
| 的 |字符稱為管道。您可以在任何想要匹配多個表達式之一的地方使用它。例如,正則表達式 r'Batman|Tina Fey' 將匹配“Batman”或“Tina Fey”。
當 Batman 和 Tina Fey 同時出現在搜索字符串中時,第一次出現的匹配文本將作為 Match 對象返回。在交互式 shell 中輸入以下內容:

您還可以使用管道來匹配多種模式之一作為正則表達式的一部分。例如,假設您想要匹配任何字符串“Batman”、“Batmobile”、“Batcopter”和“Batbat”。由于所有這些字符串都以 Bat 開頭,因此如果您只能指定該前綴一次,那就太好了。這可以通過括號來完成。在交互式 shell 中輸入以下內容:

方法調用 mo.group() 返回完整匹配的文本“Batmobile”,而 mo.group(1) 僅返回第一個括號組“mobile”內匹配文本的部分。通過使用管道字符和分組括號,您可以指定您希望正則表達式匹配的幾種替代模式。
如果需要匹配實際的管道字符,請使用反斜杠對其進行轉義,例如 \|。
Optional Matching with the Question Mark
有時,您只想選擇性地匹配某個模式。也就是說,無論該文本是否存在,正則表達式都應該找到匹配項。 ?字符將其前面的組標記為模式的可選部分。例如,在交互式 shell 中輸入以下內容:

(wo)? 正則表達式的一部分表示模式 wo 是可選組。正則表達式將匹配其中包含零個實例或一個 wo 實例的文本。這就是正則表達式同時匹配“Batwoman”和“Batman”的原因。
使用前面的電話號碼示例,您可以使正則表達式查找包含或不包含區號的電話號碼。在交互式 shell 中輸入以下內容:

你能想到的嗎?意思是“匹配此問號之前的組中的零個或一個。”
如果需要匹配實際的問號字符,請使用\?進行轉義。
Matching Zero or More with the Star
*(稱為星號或星號)表示“匹配零個或多個”——星號之前的組可以在文本中出現任意多次。它可以完全不存在或一遍又一遍地重復。讓我們再看一下蝙蝠俠的例子。

對于“Batman”,正則表達式的(wo)*部分與字符串中 wo 的零個實例匹配;對于“Batwoman”,(wo)* 匹配 wo 的一個實例;對于“Batwowowowoman”,(wo)* 匹配wo的四個實例。
如果需要匹配實際的星號字符,請在正則表達式中的星號前面加上反斜杠 \*。
Matching One or More with the Plus
* 表示“匹配零個或多個”,+(或加號)表示“匹配一個或多個”。與星號不同,星號不要求其組出現在匹配的字符串中,加號前面的組必須至少出現一次。它不是可選的。在交互式shell中輸入以下內容,并將其與上一節中的星號正則表達式進行比較:

正則表達式 Bat(wo)+man 不會匹配字符串“The Adventures of Batman”,因為加號至少需要一個 wo。
如果需要匹配實際的加號字符,請在加號前面加上反斜杠以將其轉義:\+。]
Matching Specific Repetitions with Braces
如果您想要重復某個組特定次數,請在正則表達式中的該組后面加上大括號中的數字。例如,正則表達式 (Ha){3} 將匹配字符串“HaHaHa”,但不會匹配“HaHa”,因為后者只有兩次(Ha)組重復。
您可以通過在大括號之間寫入最小值、逗號和最大值來指定范圍,而不是一個數字。例如,正則表達式 (Ha){3,5} 將匹配“HaHaHa”、“HaHaHaHa”和“HaHaHaHaHa”。
您還可以省略大括號中的第一個或第二個數字,以使最小值或最大值不受限制。例如,(Ha){3,} 將匹配 (Ha) 組的三個或多個實例,而 (Ha){,5} 將匹配零到五個實例。大括號可以幫助縮短正則表達式。這兩個正則表達式匹配相同的模式:

這兩個正則表達式也匹配相同的模式:
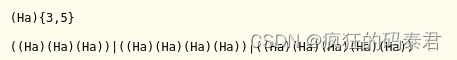
在交互式 shell 中輸入以下內容:

此處,(Ha){3} 匹配“HaHaHa”,但不匹配“Ha”。由于它與“Ha”不匹配,search() 返回 None。
Greedy and Non-greedy Matching
由于 (Ha){3,5} 可以匹配字符串 'HaHaHaHaHa' 中的三個、四個或五個Ha實例,因此您可能想知道為什么上一個大括號示例中Match對象對 group() 的調用返回'HaHaHaHaHa'而不是更短的可能性。畢竟,“HaHaHa”和“HaHaHaHa”也是正則表達式(Ha){3,5}的有效匹配。
Python 的正則表達式默認是貪婪的,這意味著在不明確的情況下它們將匹配盡可能長的字符串。大括號的非貪婪(也稱為惰性)版本與可能的最短字符串匹配,右大括號后跟一個問號。
在交互式shell中輸入以下內容,并注意搜索同一字符串的大括號的貪婪和非貪婪形式之間的區別:

請注意,問號在正則表達式中可以有兩種含義:聲明非貪婪匹配或標記可選組。這些含義完全無關。
The findall() Method
除了search()方法之外,Regex 對象還有 findall() 方法。search()將返回搜索字符串中第一個匹配文本的 Match 對象,而findall()方法將返回搜索字符串中每個匹配的字符串。要查看 search() 如何僅在匹配文本的第一個實例上返回 Match 對象,請在交互式 shell 中輸入以下內容:
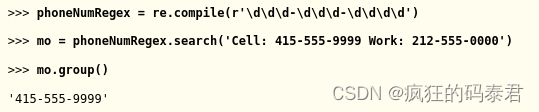
另一方面,只要正則表達式中沒有組,findall() 就不會返回 Match 對象,而是返回字符串列表。列表中的每個字符串都是與正則表達式匹配的搜索文本的一部分。在交互式 shell 中輸入以下內容:

如果正則表達式中有組,則 findall() 將返回元組列表。每個元組代表一個找到的匹配項,其項是正則表達式中每個組的匹配字符串。要查看 findall() 的實際效果,請在交互式shell中輸入以下內容(請注意,正在編譯的正則表達式現在包含括號中的組):

要總結 findall() 方法返回的內容,請記住以下幾點:
- 當在沒有組的正則表達式上調用時,例如
\d\d??\d-\d\d\d-\d\d\d\d,方法findall()返回字符串匹配列表,例如[' 415-555-9999','212-555-0000']。 - 當調用具有組的正則表達式時,例如
(\d\d\d)-(\d\d\d)-(\d\d\d\d),方法findall()返回元組列表字符串(每組一個字符串),例如[('415', '555', '9999'), ('212', '555', '0000')]。
Character Classes
在前面的電話號碼正則表達式示例中,您了解到 \d 可以代表任何數字。也就是說,\d 是正則表達式(0|1|2|3|4|5|6|7|8|9)的簡寫。這樣的簡寫字符類有很多,如表 7-1 所示。
| Shorthand character class | Represents |
|---|---|
| \d | 0 到 9 之間的任何數字。 |
| \D | 任何非 0 到 9 數字的字符。 |
| \w | 任何字母、數字或下劃線字符。 (將此視為匹配“單詞”字符。) |
| \W | 任何非字母、數字或下劃線字符的字符。 |
| \s | 任何空格、制表符或換行符。 (將此視為匹配“空格”字符。) |
| \S | 除空格、制表符或換行符之外的任何字符。 |
字符類非常適合縮短正則表達式。字符類[0-5]將只匹配數字0到5;這比輸入 (0|1|2|3|4|5) 要短得多。請注意,雖然\d匹配數字,\w 匹配數字、字母和下劃線,但不存在僅匹配字母的速記字符類。 (盡管您可以使用[a-zA-Z]字符類,如下所述。)
例如,在交互式 shell 中輸入以下內容:

正則表達式 \d+\s\w+ 將匹配包含一個或多個數字 (\d+)、后跟一個空格字符 (\s)、后跟一個或多個字母/數字/下劃線字符 (\w+) 的文本。 findall() 方法返回列表中正則表達式模式的所有匹配字符串。
Making Your Own Character Classes
有時您想要匹配一組字符,但簡寫字符類(\d、\w、\s 等)太寬泛。您可以使用方括號定義自己的字符類。例如,字符類[aeiouAEIOU]將匹配任何元音,包括小寫和大寫。在交互式 shell 中輸入以下內容:

您還可以使用連字符包含字母或數字范圍。例如,字符類[a-zA-Z0-9]將匹配所有小寫字母、大寫字母和數字。
請注意,方括號內的正常正則表達式符號不會被如此解釋。這意味著您不需要使用前面的反斜杠轉義.、*、? 或 ()字符。例如,字符類 [0-5.] 將匹配數字 0 到 5 和句點。不需要寫成[0-5\.]。
通過在字符類的左括號后面放置插入符號 (^),可以創建負字符類。負字符類將匹配所有不屬于該字符類的字符。例如,在交互式shell中輸入以下內容:

現在,我們不是匹配每個元音,而是匹配每個非元音的字符。
The Caret and Dollar Sign Characters
您還可以在正則表達式的開頭使用插入符號 (^) 來指示匹配必須出現在搜索文本的開頭。同樣,您可以在正則表達式末尾放置一個美元符號 ($),以指示字符串必須以此正則表達式模式結尾。您可以一起使用 ^ 和 $ 來指示整個字符串必須與正則表達式匹配 - 也就是說,僅在字符串的某些子集上進行匹配是不夠的。
例如,r'^Hello' 正則表達式字符串匹配以'Hello'開頭的字符串。在交互式shell中輸入以下內容:

r'\d$' 正則表達式字符串匹配以 0 到 9 之間的數字字符結尾的字符串。在交互式 shell 中輸入以下內容:

r'^\d+$' 正則表達式字符串匹配以一個或多個數字字符開頭和結尾的字符串。在交互式shell中輸入以下內容:

前面的交互式 shell 示例中的最后兩個search()調用演示了如果使用^和 $,整個字符串必須如何與正則表達式匹配。
我總是混淆這兩個符號的含義,因此我使用助記符“Carrots costdollar”來提醒自己插入符號在前,美元符號在后。
The Wildcard Character
. 正則表達式中的(或點)字符稱為通配符,將匹配除換行符之外的任何字符。例如,在交互式shell中輸入以下內容:

請記住,點字符僅匹配一個字符,這就是為什么上一示例中的文本flat匹配僅匹配lat的原因。要匹配實際的點,請使用反斜杠轉義點:\..
Matching Everything with Dot-Star
有時您會想要匹配所有內容。例如,假設您想要匹配字符串“First Name:”,后跟任何和所有文本,然后是“Last Name:”,最后再跟任何內容。您可以使用點星號 (.*) 來代表“任何內容”。請記住,點字符表示“除換行符之外的任何單個字符”,星號字符表示“零個或多個前面的字符”。

點星使用貪婪模式:它將始終嘗試匹配盡可能多的文本。要以非貪婪方式匹配任何和所有文本,請使用點、星號和問號 (.*?)。與大括號一樣,問號告訴Python以非貪婪的方式進行匹配。
在交互式shell中輸入以下內容,查看貪婪版本和非貪婪版本之間的區別:

這兩個正則表達式大致翻譯為“匹配左尖括號,后跟任何內容,然后是右尖括號。”但是字符串 '<Toserve man> fordinner.>' 的右尖括號有兩個可能的匹配項。在正則表達式的非貪婪版本中,Python 匹配最短的可能字符串:“<Toserve man>”。在貪婪版本中,Python 匹配盡可能長的字符串:“<Toserve man> fordinner.>”。
Matching Newlines with the Dot Character
點星將匹配除換行符之外的所有內容。通過將 re.DOTALL 作為第二個參數傳遞給 re.compile(),可以使點字符匹配所有字符,包括換行符。
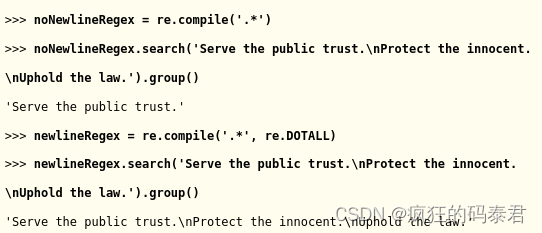
正則表達式noNewlineRegex沒有將re.DOTALL傳遞給創建它的 re.compile() 調用,它只會匹配第一個換行符之前的所有內容,而 newlineRegex 確實將 re.DOTALL 傳遞給 re.compile( ),匹配一切。這就是 newlineRegex.search() 調用匹配完整字符串(包括換行符)的原因。
Review of Regex Symbols

Case-Insensitive Matching
通常,正則表達式將文本與您指定的確切大小寫進行匹配。例如,以下正則表達式匹配完全不同的字符串:
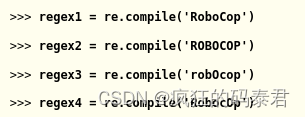
但有時您只關心匹配字母,而不關心它們是大寫還是小寫。要使正則表達式不區分大小寫,可以將 re.IGNORECASE 或 re.I 作為第二個參數傳遞給 re.compile()。在交互式shell中輸入以下內容:

Substituting Strings with the sub() Method
正則表達式不僅可以查找文本模式,還可以用新文本代替這些模式。 Regex 對象的 sub() 方法傳遞兩個參數。第一個參數是一個字符串,用于替換任何匹配項。第二個是正則表達式的字符串。 sub() 方法返回應用了替換的字符串。
例如,在交互式 shell 中輸入以下內容:

有時您可能需要使用匹配的文本本身作為替換的一部分。在 sub() 的第一個參數中,您可以鍵入 \1、\2、\3 等,表示“在替換中輸入組 1、2、3 等的文本”。
例如,假設您想通過僅顯示秘密特工姓名的第一個字母來審查他們的姓名。為此,您可以使用正則表達式代理 (\w)\w* 并將r'\1****'作為第一個參數傳遞給 sub()。該字符串中的\1將被第 1 組(即正則表達式的(\w)組)匹配的任何文本替換。

Managing Complex Regexes
如果您需要匹配的文本模式很簡單,則正則表達式就可以了。但匹配復雜的文本模式可能需要長而復雜的正則表達式。您可以通過告訴 re.compile() 函數忽略正則表達式字符串內的空格和注釋來緩解這種情況。這種“詳細模式”可以通過將變量re.VERBOSE作為第二個參數傳遞給re.compile()來啟用。
現在,而不是像這樣難以閱讀的正則表達式:

您可以使用如下注釋將正則表達式分散在多行中:

請注意前面的示例如何使用三引號語法 (‘’') 創建多行字符串,以便您可以將正則表達式定義分散到多行中,從而使其更加清晰。
正則表達式字符串內的注釋規則與常規 Python 代碼相同:# 符號及其后面到行尾的所有內容都將被忽略。此外,正則表達式的多行字符串內的額外空格不被視為要匹配的文本模式的一部分。這使您可以組織正則表達式,使其更易于閱讀。
Combining re.IGNORECASE, re.DOTALL, and re.VERBOSE
What if you want to use re.VERBOSE to write comments in your regular expression but also want to use re.IGNORECASE to ignore capitalization? Unfortunately, the re.compile() function takes only a single value as its second argument. You can get around this limitation by combining the re.IGNORECASE, re.DOTALL, and re.VERBOSE variables using the pipe character (|), which in this context is known as the bitwise or operator.
So if you want a regular expression that’s case-insensitive and includes newlines to match the dot character, you would form your re.compile() call like this:

這種語法有點過時,源自 Python 的早期版本。位運算符的詳細信息超出了本書的范圍,但請查看 https://nostarch.com/automatestuff2/ 上的資源以獲取更多信息。您還可以為第二個參數傳遞其他選項;它們并不常見,但您也可以在資源中閱讀有關它們的更多信息。
Project: Phone Number and Email Address Extractor
假設您有一項無聊的任務:在長網頁或文檔中查找每個電話號碼和電子郵件地址。如果您手動滾動頁面,您可能會搜索很長時間。但是,如果您有一個程序可以在剪貼板中的文本中搜索電話號碼和電子郵件地址,則只需按 CTRL-A 選擇所有文本,按 CTRL-C 將其復制到剪貼板,然后運行您的程序。它可以用它找到的電話號碼和電子郵件地址替換剪貼板上的文本。
每當您處理一個新項目時,您都會很想直接開始編寫代碼。但通常情況下,最好退后一步,考慮更大的前景。我建議首先為您的程序需要做什么制定一個高級計劃。現在先不要考慮實際的代碼——您可以稍后再考慮。現在,堅持大綱。
例如,您的電話和電子郵件地址提取器需要執行以下操作:
- 將文本從剪貼板中取出。
- 查找文本中的所有電話號碼和電子郵件地址。
- 將它們粘貼到剪貼板上。
現在您可以開始思考這在代碼中如何工作。該代碼需要執行以下操作:
使用pyperclip模塊復制和粘貼字符串。
- 創建兩個正則表達式,一個用于匹配電話號碼,另一個用于匹配電子郵件地址。
- 查找兩個正則表達式的所有匹配項,而不僅僅是第一個匹配項。
- 將匹配的字符串整齊地格式化為單個字符串以進行粘貼。
- 如果在文本中未找到匹配項,則顯示某種消息。
該列表就像該項目的路線圖。在編寫代碼時,您可以分別關注其中的每個步驟。每個步驟都相當易于管理,并且用您已經知道如何在 Python 中執行的操作來表達。
Step 1: Create a Regex for Phone Numbers
首先,您必須創建正則表達式來搜索電話號碼。創建一個新文件,輸入以下內容,并將其另存為 phoneAndEmail.py:

TODO 注釋只是程序的骨架。當您編寫實際代碼時,它們將被替換。
電話號碼以可選的區號開頭,因此區號組后跟一個問號。由于區號可以僅為三位數字(即 \d{3})或括號內的三位數字(即 (\d{3})),因此您應該使用管道連接這些部分。您可以將正則表達式注釋 # Area code 添加到多行字符串的這一部分,以幫助您記住什么 (\d{3}|(\d{3}))?應該匹配。
電話號碼分隔符可以是空格 (\s)、連字符 (-) 或句點 (.),因此這些部分也應該用管道連接。正則表達式的接下來的幾個部分很簡單:三個數字,后跟另一個分隔符,然后是四個數字。最后一部分是可選的擴展名,由任意數量的空格組成,后跟 ext、x 或 ext.,后跟兩到五位數字。
Note
很容易與包含帶括號 ( ) 和轉義括號 ( ) 的組的正則表達式混淆。如果您收到“缺少 )、未終止的子模式”錯誤消息,請記住仔細檢查您使用的是否正確。
Step 2: Create a Regex for Email Addresses
您還需要一個可以匹配電子郵件地址的正則表達式。使您的程序如下所示:

電子郵件地址 ? 的用戶名部分是一個或多個字符,可以是以下任意一種:小寫和大寫字母、數字、點、下劃線、百分號、加號或連字符。您可以將所有這些放入一個字符類中:[a-zA-Z0-9._%±]。
域名和用戶名由 @ 符號 ? 分隔。域名 ? 的字符類稍微寬松一些,僅包含字母、數字、句點和連字符:[a-zA-Z0-9.-]。最后是“dot-com”部分(技術上稱為頂級域),它實際上可以是任何點。這是兩個到四個字符之間。
電子郵件地址的格式有很多奇怪的規則。此正則表達式不會匹配所有可能的有效電子郵件地址,但它會匹配您遇到的幾乎所有典型電子郵件地址。
Step 3: Find All Matches in the Clipboard Text
現在您已經指定了電話號碼和電子郵件地址的正則表達式,您可以讓 Python 的 re 模塊完成查找剪貼板上所有匹配項的艱苦工作。 pyperclip.paste() 函數將獲取剪貼板上文本的字符串值,findall()正則表達式方法將返回元組列表。
使您的程序如下所示:
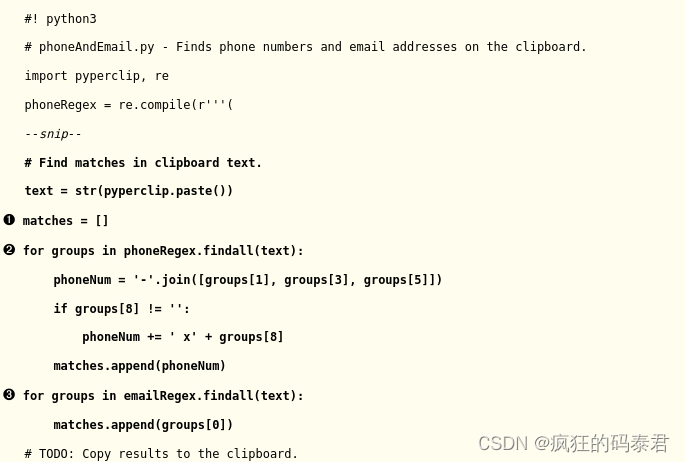
每個匹配項都有一個元組,每個元組包含正則表達式中每個組的字符串。請記住,組 0 匹配整個正則表達式,因此元組索引 0 處的組是您感興趣的組。
正如您在 ? 中看到的,您將把匹配項存儲在名為 matches 的列表變量中。它以一個空列表和幾個 for 循環開始。對于電子郵件地址,您附加每個匹配項的第 0 組 ?。對于匹配的電話號碼,您不想只附加組 0。雖然程序檢測多種格式的電話號碼,但您希望附加的電話號碼采用單一標準格式。 phoneNum 變量包含一個由匹配文本 ? 的第 1、3、5 和 8 組構建的字符串。 (這些組是區號、前三位數字、后四位數字和分機號。)
Step 4: Join the Matches into a String for the Clipboard
現在您已將電子郵件地址和電話號碼作為匹配項中的字符串列表,您希望將它們放在剪貼板上。 pyperclip.copy() 函數僅接受單個字符串值,而不是字符串列表,因此您可以在匹配時調用join()方法。
為了更容易地看到程序正在運行,讓我們將找到的任何匹配項打印到終端。如果沒有找到電話號碼或電子郵件地址,程序應該告訴用戶這一點。
使您的程序如下所示:













及typing庫)
)


)


