之前碰到一個線上問題,在接手一個同事的項目后,因為工期比較趕,我還沒來得及了解業務背景和大致實現,只是了解了上線發布的順序和驗證方式就進行了上線,在上線進行金絲雀的時候系統還沒發生什么異常,于是我們進行了全量發布,全量完成后監控顯示有一個接口在間歇性的顯示耗時會比較長,然后我們在觀察是否影響面和判斷是否需要回滾中。另一方面在我們全量發布后大約10分鐘后,其他一個業務線就進行了緊急告警,但是他們沒有上線,在眾多排查手段用了之后,dba排查到我們系統的庫和他們的業務系統庫用的是一個機器,所以告知我們,然后我們就執行了回滾步驟中的關閉業務開關,關閉后雙方業務的監控表明問題消失了。
之后我們就進行解析問題,發現是在某些業務邏輯中操作的一個查詢沒有走索引導致的,然后在下一個窗口進行了重新上線,接口耗時和對方業務的告警都沒有了。但是在上線一段時間后,在夜里2點到5點的時候,該系統仍然會顯示一些實時接口間歇耗時,然后我們看了那段時間的系統運行情況,發現其中一個定時任務會那段時間運行,應該是兩者爭相使用數據庫連接池導致的,最終在測試環境復現,在擴大數據庫連接池后問題消失。
這次情況給我的啟示就是一定要注重了解學會了解清楚怎樣承接一個工程,和在數據庫優化這塊的知識,所以我就進行了一些mysql優化所學的整理,分享給大家。要了解清楚索引的使用情況、連接池情況和數據庫的部署是混合部署還是獨立部署。
關于數據庫的優化,本次是想先講明數據的一些原理,然后再進行一些優化的講解。
一、mysql的原理
(一)mysql體系結構
首先我們來了解下mysql系統是怎樣的,如下圖:
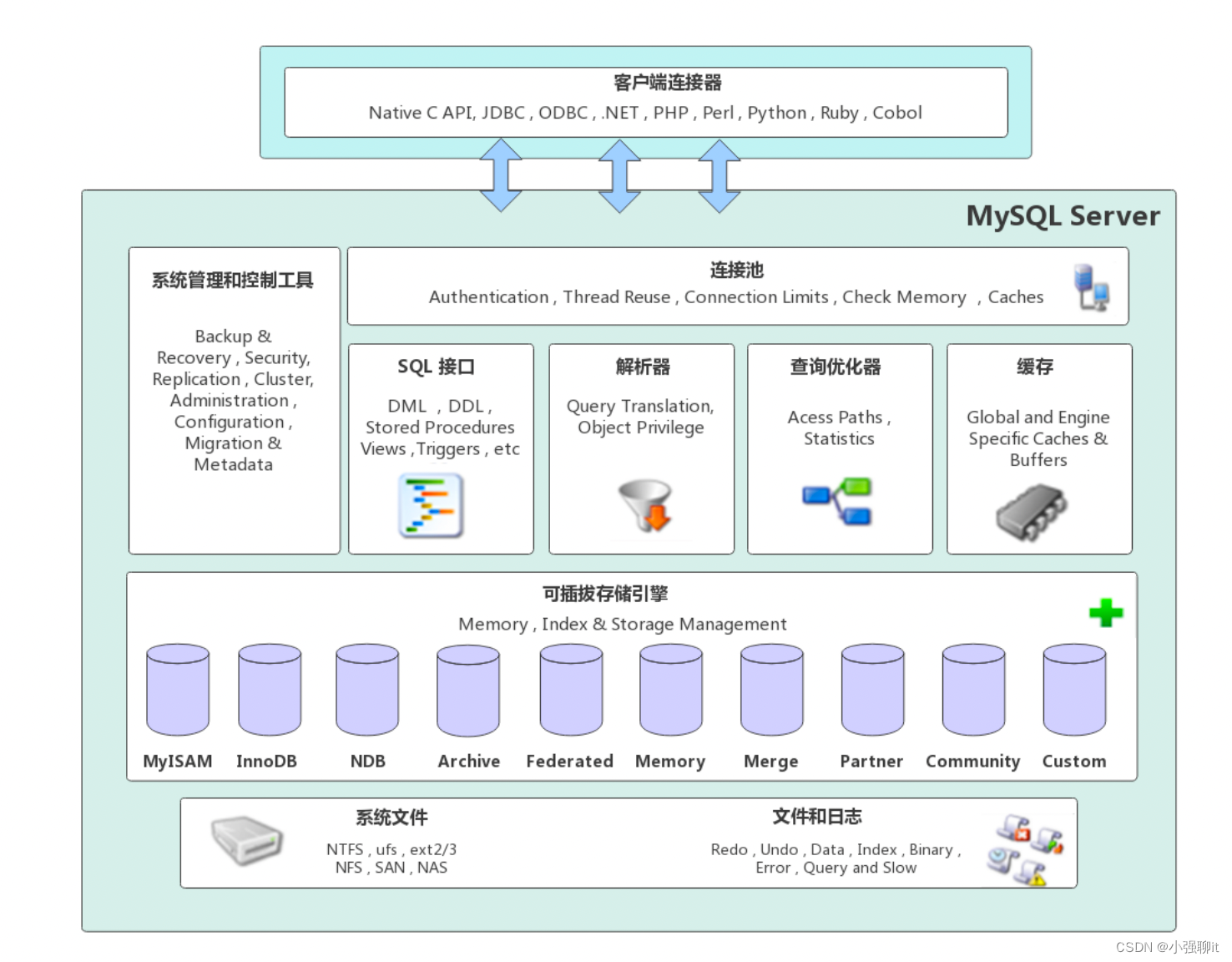
MySQL Server架構自頂向下大致可以分網絡連接層、服務層、存儲引擎層和系統文件層。
1.網絡連接層
客戶端連接器(Client Connectors):提供與MySQL服務器建立的支持。目前幾乎支持所有主流
的服務端編程技術,例如常見的 Java、C、Python、.NET等,它們通過各自API技術與MySQL建立連接。
2.服務層(MySQL Server)
服務層是MySQL Server的核心,主要包含系統管理和控制工具、連接池、SQL接口、解析器、查詢優
化器和緩存六個部分:
(1)連接池(Connection Pool):負責存儲和管理客戶端與數據庫的連接,一個線程負責管理一個
連接。
(2)系統管理和控制工具(Management Services & Utilities):例如備份恢復、安全管理、集群
管理等
(3)SQL接口(SQL Interface):用于接受客戶端發送的各種SQL命令,并且返回用戶需要查詢的結
果。比如DML、DDL、存儲過程、視圖、觸發器等。
(4)解析器(Parser):負責將請求的SQL解析生成一個"解析樹"。然后根據一些MySQL規則進一步
檢查解析樹是否合法。
(5)查詢優化器(Optimizer):當“解析樹”通過解析器語法檢查后,將交由優化器將其轉化成執行計
劃,然后與存儲引擎交互。
select uid,name from user where gender=1;
選取--》投影--》聯接 策略
1)select先根據where語句進行選取,并不是查詢出全部數據再過濾
2)select查詢根據uid和name進行屬性投影,并不是取出所有字段
3)將前面選取和投影聯接起來最終生成查詢結果
(6)緩存(Cache&Buffffer):
緩存機制是由一系列小緩存組成的。比如表緩存,記錄緩存,權限緩
存,引擎緩存等。如果查詢緩存有命中的查詢結果,查詢語句就可以直接去查詢緩存中取數據。
3.存儲引擎層(Pluggable Storage Engines)
存儲引擎負責MySQL中數據的存儲與提取,與底層系統文件進行交互。MySQL存儲引擎是插件式的,
服務器中的查詢執行引擎通過接口與存儲引擎進行通信,接口屏蔽了不同存儲引擎之間的差異 。現在有
很多種存儲引擎,各有各的特點,最常見的是MyISAM和InnoDB。
4.系統文件層(File System)
該層負責將數據庫的數據和日志存儲在文件系統之上,并完成與存儲引擎的交互,是文件的物理存儲
層。主要包含日志文件,數據文件,配置文件,pid 文件,socket 文件等。
(1)配置文件:用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
(2)數據文件:
db.opt 文件:記錄這個庫的默認使用的字符集和校驗規則。
frm 文件:存儲與表相關的元數據(meta)信息,包括表結構的定義信息等,每一張表都會
有一個frm 文件。
MYD 文件:MyISAM 存儲引擎專用,存放 MyISAM 表的數據(data),每一張表都會有一個
.MYD 文件。
MYI 文件:MyISAM 存儲引擎專用,存放 MyISAM 表的索引相關信息,每一張 MyISAM 表對
應一個 .MYI 文件。
ibd文件和 IBDATA 文件:存放 InnoDB 的數據文件(包括索引)。InnoDB 存儲引擎有兩種
表空間方式:獨享表空間和共享表空間。獨享表空間使用 .ibd 文件來存放數據,且每一張
InnoDB 表對應一個 .ibd 文件。共享表空間使用 .ibdata 文件,所有表共同使用一個(或多
個,自行配置).ibdata 文件。
ibdata1 文件:系統表空間數據文件,存儲表元數據、Undo日志等 。
ib_logfifile0、ib_logfifile1 文件:Redo log 日志文件。
(二)?sql執行流程
sql執行的流程一般是這樣的,如下圖:
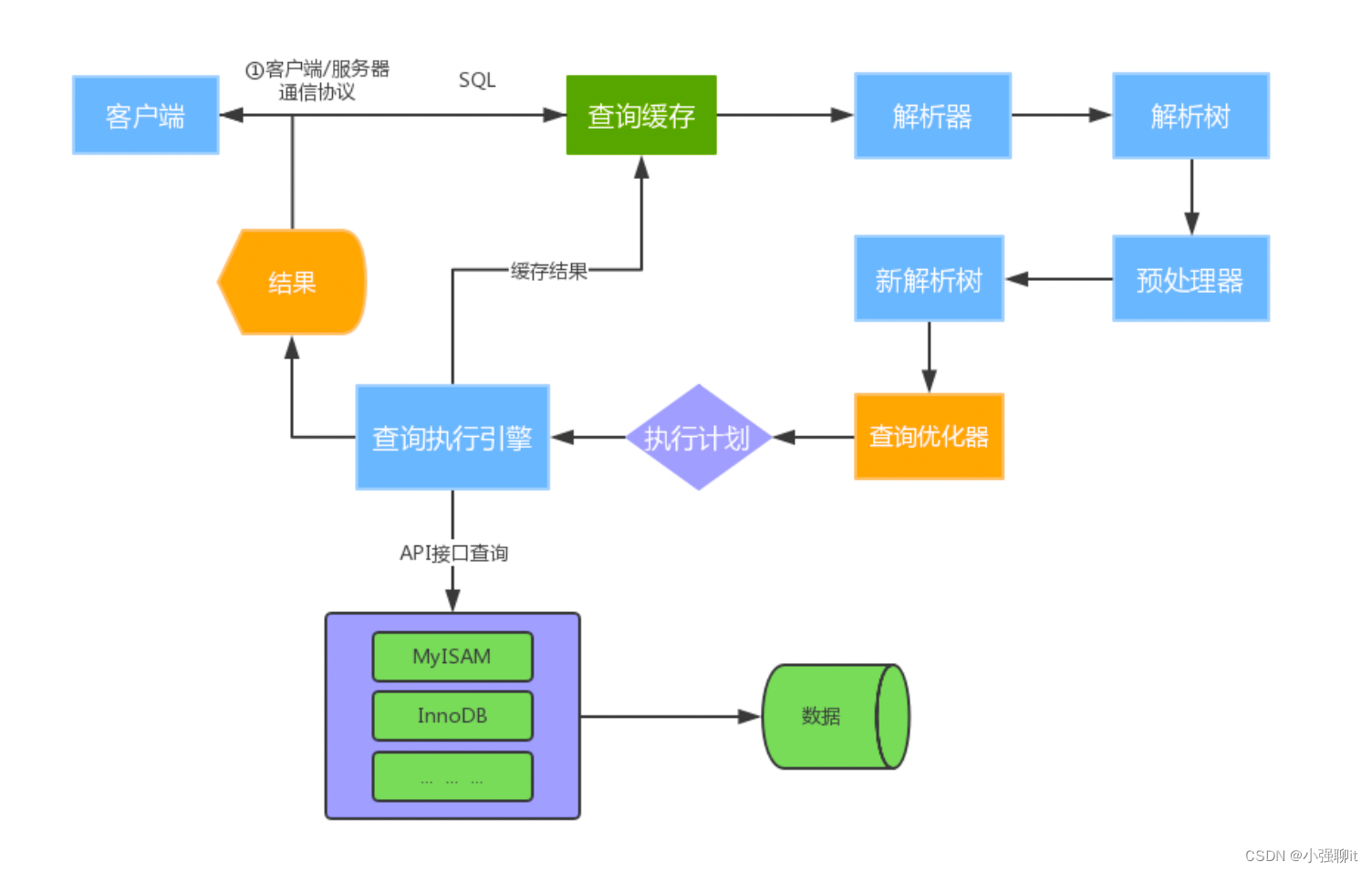
1.建立連接(Connectors&Connection Pool),通過客戶端/服務器通信協議與MySQL建立連接。MySQL 客戶端與服務端的通信方式是 “ 半雙工 ”。
2.查詢緩存(Cache&Buffffer)
這是MySQL的一個可優化查詢的地方,如果開啟了查詢緩存且在
查詢緩存過程中查詢到完全相同的SQL語句,則將查詢結果直接返回給客戶端;如果沒有開啟查詢
緩存或者沒有查詢到完全相同的 SQL 語句則會由解析器進行語法語義解析,并生成“解析樹”。
緩存Select查詢的結果和SQL語句
執行Select查詢時,先查詢緩存,判斷是否存在可用的記錄集,要求是否完全相同(包括參
數值),這樣才會匹配緩存數據命中。
即使開啟查詢緩存,以下SQL也不能緩存
查詢語句使用SQL_NO_CACHE
查詢的結果大于query_cache_limit設置
查詢中有一些不確定的參數,比如now()
show variables like '%query_cache%'; //查看查詢緩存是否啟用,空間大小,限制等
show status like 'Qcache%'; //查看更詳細的緩存參數,可用緩存空間,緩存塊,緩存多少等
3.解析器(Parser)將客戶端發送的SQL進行語法解析,生成"解析樹"。預處理器根據一些MySQL
規則進一步檢查“解析樹”是否合法,例如這里將檢查數據表和數據列是否存在,還會解析名字和別
名,看看它們是否有歧義,最后生成新的“解析樹”。
4.查詢優化器(Optimizer)根據“解析樹”生成最優的執行計劃。MySQL使用很多優化策略生成最
優的執行計劃,可以分為兩類:靜態優化(編譯時優化)、動態優化(運行時優化)。
5.查詢執行引擎負責執行 SQL 語句,此時查詢執行引擎會根據 SQL 語句中表的存儲引擎類型,以
及對應的API接口與底層存儲引擎緩存或者物理文件的交互,得到查詢結果并返回給客戶端。若開
啟用查詢緩存,這時會將SQL 語句和結果完整地保存到查詢緩存(Cache&Buffffer)中,以后若有
相同的 SQL 語句執行則直接返回結果。
如果開啟了查詢緩存,先將查詢結果做緩存操作,返回結果過多,采用增量模式返回
(三)sql語句的中關鍵字執行順序
在編寫一條查詢語句時,習慣性的從頭到尾開始敲出來,應該都是從select?開始吧,但似乎沒太注意它們真正的執行順序;既然要優化,肯定需要得知道一條SQL語句大概的執行流程,結合執行計劃,目的就更加清晰啦;上一張一看就明白的圖:

關鍵字簡述:
- FROM:確定數據來源,即指定表;
- JOIN...ON:確定關聯表和關聯條件;
- WHERE:指定過濾條件,過濾出滿足條件的數據;
- GROUP BY:按指定的字段對過濾后的數據進行分組;
- HAVING:對分組之后的數據指定過濾條件;
- SELECT:查找想要的字段數據;
- DISTINCT:針對查找出來的數據進行去重;
- ORDER BY:對去重后的數據指定字段進行排序;
- LIMIT:對去重后的數據限制獲取到的條數,即分頁;
(四)?mysql使用到的硬件
mysql使用硬件主要的工作內容如下:
CPU及內存:緩存數據訪問、比較、排序、事務檢測、SQL解析、函數或邏輯運算;
網絡:結果數據傳輸、SQL請求、遠程數據庫訪問(dblink);
硬盤:數據訪問、數據寫入、日志記錄、大數據量排序、大表連接。
下面我們看下硬件資源的CPU、內存、硬盤、網卡的性能指標。
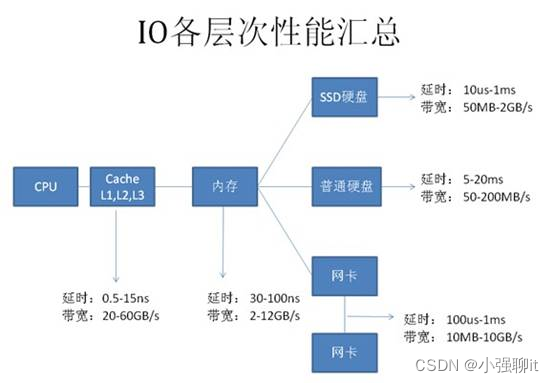
從圖上可以看到基本上每種設備都有兩個指標:
延時(響應時間):表示硬件的突發處理能力;
帶寬(吞吐量):代表硬件持續處理能力。
從上圖可以看出,計算機系統硬件性能從高到代依次為:
CPU——Cache(L1-L2-L3)——內存——SSD硬盤——網絡——硬盤
(五)存儲引擎
存儲數據時,影響存儲速度的主要是索引、唯一性校驗、一次存儲的數據條數等。存儲數據的優化,不同的存儲引擎優化手段不一樣,在MySQL中常用的存儲引擎有,MyISAM和InnoDB,下面來簡單介紹下:
| MyISAM | InnoDB | |
| 物理文件構成區別 | MyISAM表是獨立于操作系統的,每當我們建立一個MyISAM引擎的表時,就會在本地磁盤上建立三個文件,分別是 “.frm”表元數據定義 “.MYD”數據存儲 “.MYI”存儲索引 | Innodb的所有數據保存在一個單獨的表空間里面,而這個表空間可以由很多個文件組成,一個表可以跨多個文件存在。基于磁盤的資源是InnoDB表空間數據文件和它的日志文件,InnoDB 表的大小只受限于操作系統文件的大小,一般為?2GB |
| 事務處理 | MyISAM并不支持事務這樣的高級數據庫特性,但MyISAM類型的表強調的是執行性能。 | InnoDB提供對事務的支持、外鍵約束。 |
| 鎖 | MyISAM存儲引擎只支持表鎖,鎖的粒度較粗。 | 提供行鎖,不過需要注意的是,如果在執行一個SQL語句時MySQL不能確定要掃描的范圍,InnoDB表同樣會鎖全表,例如update table set num=1 ?where name like “%aaa%” |
| 索引的結構 | MyISAM引擎使用B+Tree作為索引結構。MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然后以data域的值為地址,讀取相應數據記錄。 | InnoDB引擎用的也是B+Tree作為索引結構。在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。 |
| DB的CRUD操作 | MyISAM比較適合執行大量查詢的操作,在篩選大量數據時候非常迅速是其的特點。 | 執行大量的insert或update,出于性能方面的考慮,應該使用InnoDB表。 |
| 場景 | ?MyISAM管理非事務表,它提供高速存儲和檢索,以及全文搜索能力,適合需要執行大量的SELECT查詢類似數據倉庫這樣查詢頻繁的應用。 | InnoDB用于事務處理應用程序,具有眾多特性,包括ACID事務支持。如果應用中需要執行大量的INSERT或UPDATE操作,則應該使用InnoDB,這樣可以提高多用戶并發操作的性能。 |
如上面表格中“索引的結構”一欄所述,MyISAM存儲引擎使用B+Tree作為索引結構,葉節點的data域存放的是數據記錄的地址。下面是MyISAM中索引的原理圖:
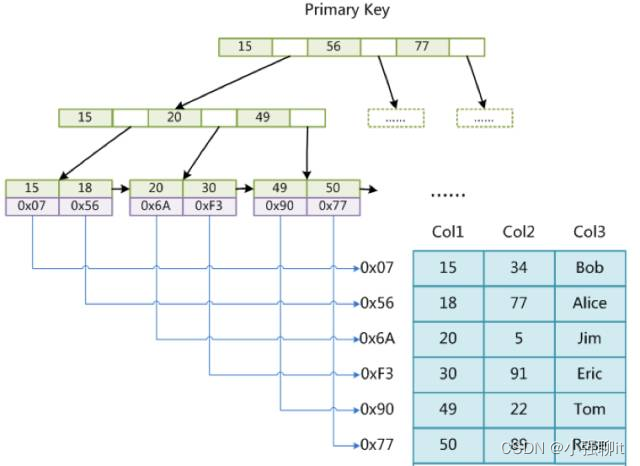
MyISAM中索引檢索的算法先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然后以data域的值為地址,讀取相應數據記錄。這里我們假設這個表僅有三列,分別是Col1、Col2和Col3列。在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重復。假設我們在Col2列上建立一個輔助索引則索引結構如下:

雖然InnoDB也是使用B+Tree作為索引結構,但是具體實現方式與MyISAM截然不同。InnoDB的索引結構如下圖所示:
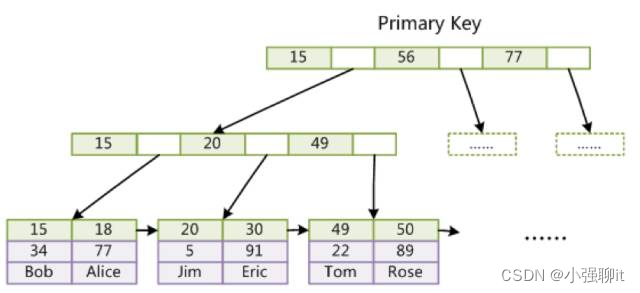
在上面索引結構的具體實現方式上有兩個區別,第一個區別在于InnoDB的數據文件本身就包含了索引部分。而從上文兩種存儲引擎區別的表格中可以知道,MyISAM索引和數據部分是分離的,索引文件僅保存的是數據記錄的地址。而在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。
第二個與MyISAM索引的不同是InnoDB的輔助索引data域存儲相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。例如,下圖為定義在Col3上的一個輔助索引示意圖:
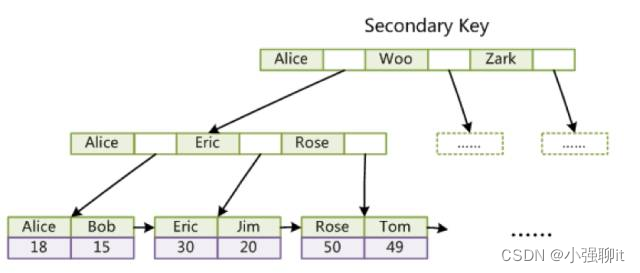
了解InnoDB的索引實現后,就容易明白為什么不應該使用過長的字段作為主鍵,因為所有輔助索引都引用主索引,過長的主索引會令輔助索引變得過大。再比如,用非單調的字段作為主鍵在InnoDB存儲引擎中并不是個好主意,因為InnoDB數據文件本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時數據文件為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增字段作為主鍵則是一個很好的選擇。
了解完上述內容,我們要進行mysql的優化,大致能做的就是:
合理安排資源、調整系統參數使MySQL運行更快、更節省資源。優化方面主要主要包括查詢、表設計、服務器等。最終要達到的效果是減少系統瓶頸,減少資源占用,增加系統的反應速度。

)

)
)




--- 菜單欄功能和Tab頁功能實現)









)