文章目錄
- 一、索引概述
- 二、索引結構
- 三、結構 - B-Tree
- 四、結構 - B+Tree
- 五、結構 - Hash
- 六、索引分類
- 七、索引語法
- 1.案例代碼
- 八、SQL性能分析
- 1.查看SQl執行頻率
- 2.慢查詢日志
- 3.PROFILES詳情
- 4.EXPLAIN執行計劃
- 九、 索引使用規則
- 十、SQL 提示
- 十一、覆蓋索引
- 十二、前綴索引
- 十三、單列索引&聯合索引
- 十四、索引設計原則
本篇博客深入詳細地介紹了數據庫索引的概念和重要性。內容包含:索引的概念和目標、索引的優點與缺點。此外,博客還深入解析了三種主要的索引結構:B-Tree、B+Tree和Hash,提供了詳細的結構解析和優化方法,并通過插圖進一步增強了理解。
博客的部分內容專注于對B-Tree和B+Tree的對比,以及MySQL中索引結構的原理和實際應用。對索引結構的一些微妙差異,如MySQL在B+Tree基礎上增加指向相鄰葉子節點的鏈表指針,也進行了深入的探討。
在對索引結構進行詳細解析后,博客介紹了幾種不同類型的索引(包括聚簇索引和非聚簇索引)及其適用場景。接著,博客介紹了索引語法,SQL性能分析以及索引直接和索引建議。
總的來說,這篇博客提供了一份詳盡且全面的索引教程和指南,從基本概念到實踐應用,有很高的參考價值。
一、索引概述
索引是幫助 MySQL 高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查詢算法,這種數據結構就是索引。
優點:
提高數據檢索效率,降低數據庫的IO成本
通過索引列對數據進行排序,降低數據排序的成本,降低CPU的消耗

缺點:
索引列也是要占用空間的
索引大大提高了查詢效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
二、索引結構

三、結構 - B-Tree
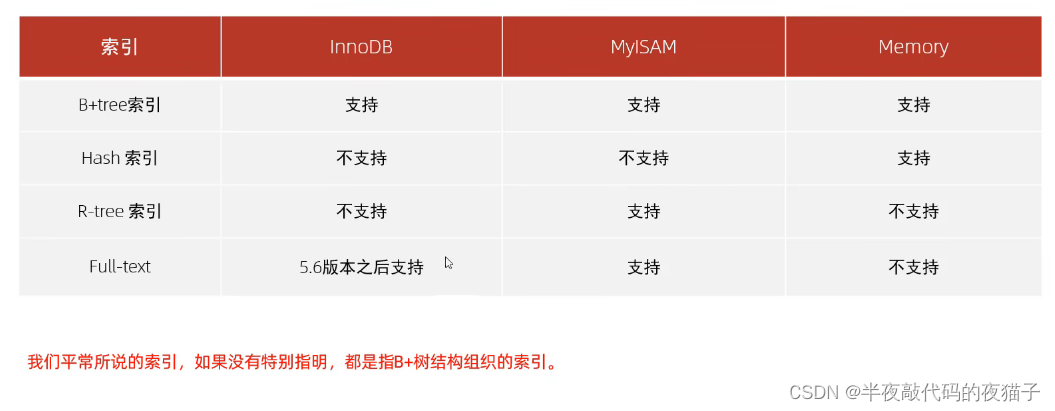
B-Tree (多路平衡查找樹) 以一棵最大度數(max-degree,指一個節點的子節點個數)為5(5階)的 b-tree 為例(每個節點最多存儲4個key,5個指針)
B-Tree結構
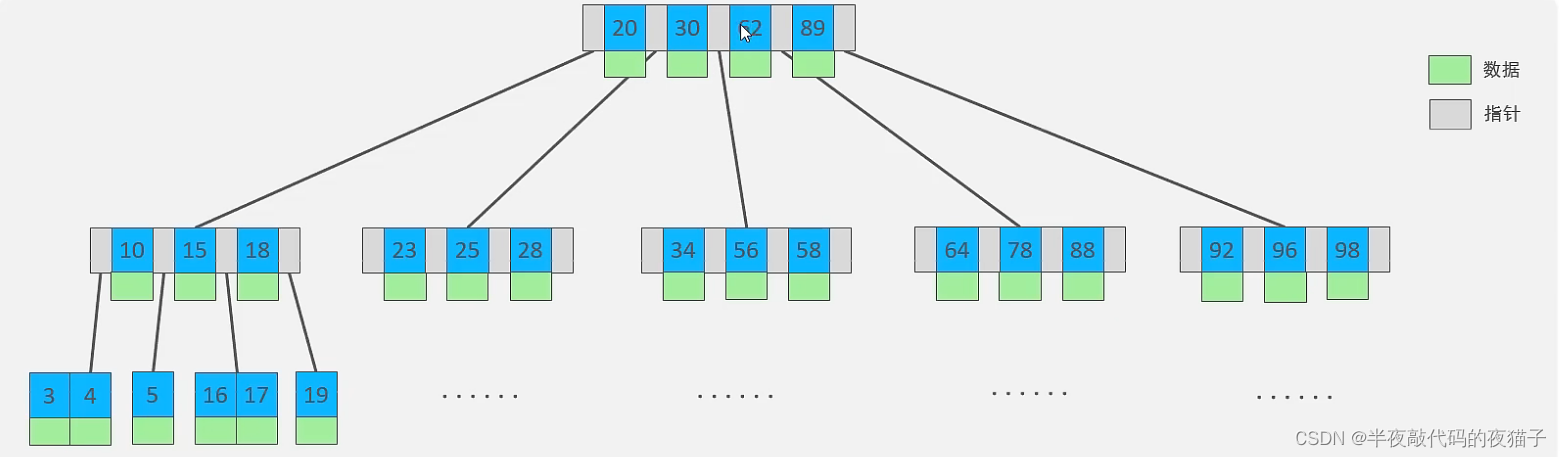
演示地址:https://www.cs.usfca.edu/~galles/visualization/BTree.html
四、結構 - B+Tree
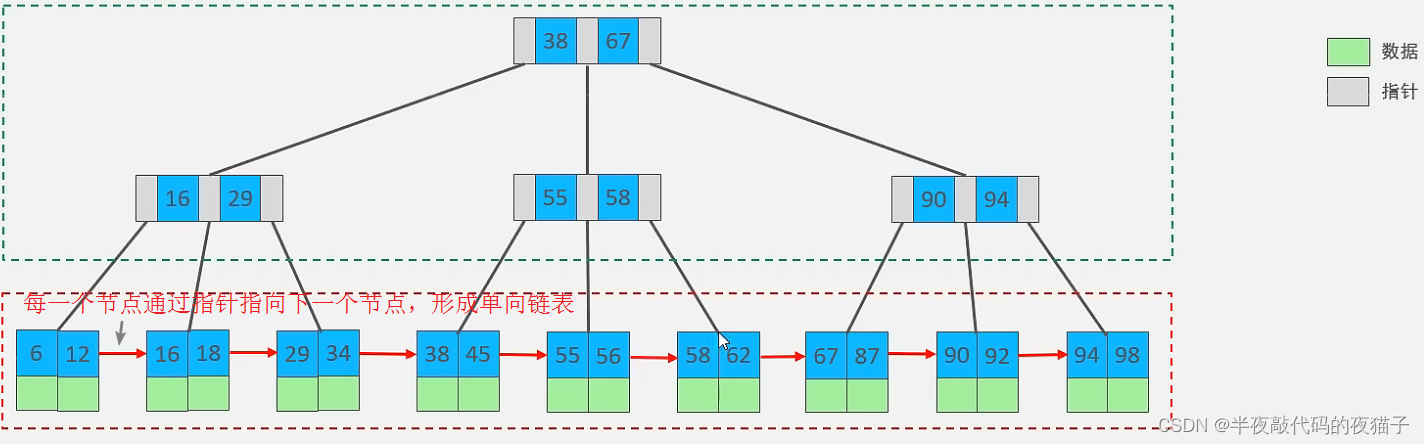
演示地址:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
與 B-Tree 的區別:
所有的數據都會出現在葉子節點,葉子節點形成一個單向鏈表
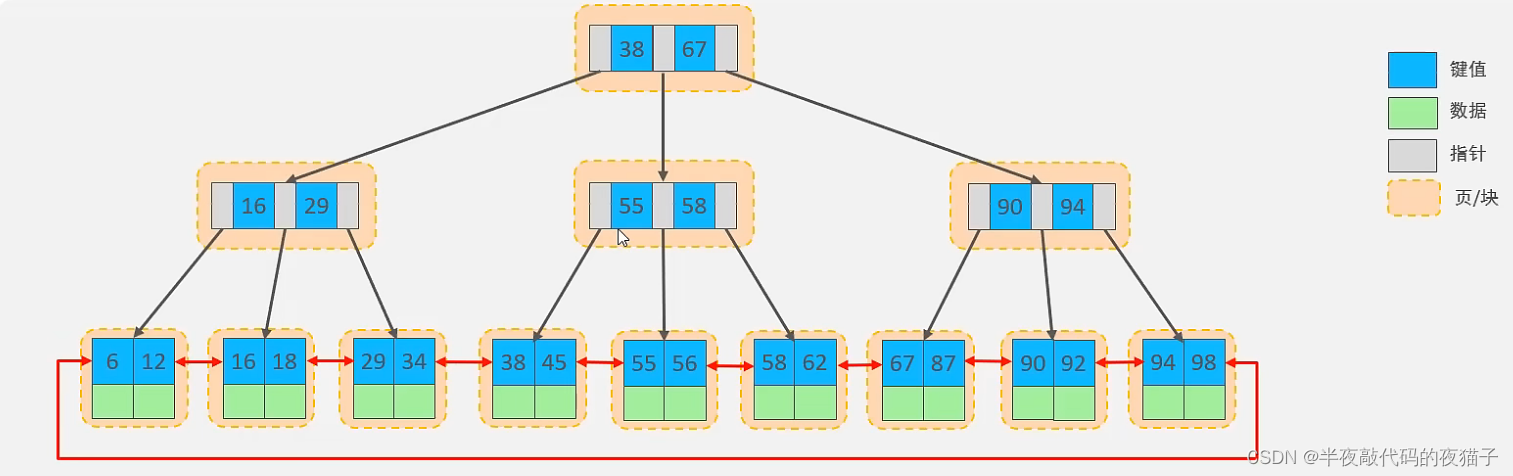
MySQL 索引數據結構對經典的 B+Tree 進行了優化。在原 B+Tree 的基礎上,增加一個指向相鄰葉子節點的鏈表指針,就形成了帶有順序指針的 B+Tree,提高區間訪問的性能。
五、結構 - Hash
哈希索引就是采用一定的hash算法,將鍵值換算成新的hash值,映射到對應的槽位上,然后存儲在hash表中。
如果兩個(或多個)鍵值,映射到一個相同的槽位上,他們就產生了hash沖突(也稱為hash碰撞),可以通過鏈表來解決。

特點:
Hash索引只能用于對等比較(=、in),不支持范圍查詢(betwwn、>、<、…)
無法利用索引完成排序操作
查詢效率高,通常只需要一次檢索就可以了,效率通常要高于 B+Tree 索引
存儲引擎支持:
Memory
InnoDB: 具有自適應hash功能,hash索引是存儲引擎根據 B+Tree 索引在指定條件下自動構建的
面試題
為什么 InnoDB 存儲引擎選擇使用 B+Tree 索引結構?
相對于二叉樹,層級更少,搜索效率高
對于 B-Tree,無論是葉子節點還是非葉子節點,都會保存數據,這樣導致一頁中存儲的鍵值減少,指針也跟著減少,要同樣保存大量數據,只能增加樹的高度,導致性能降低
相對于 Hash 索引,B+Tree 支持范圍匹配及排序操作
六、索引分類
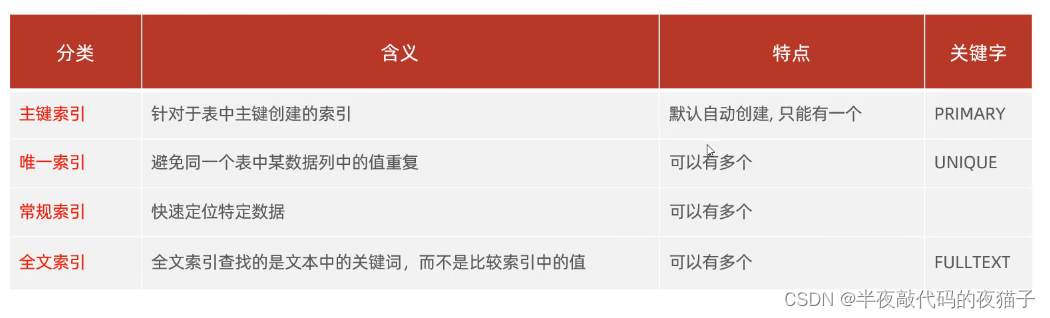

演示圖:
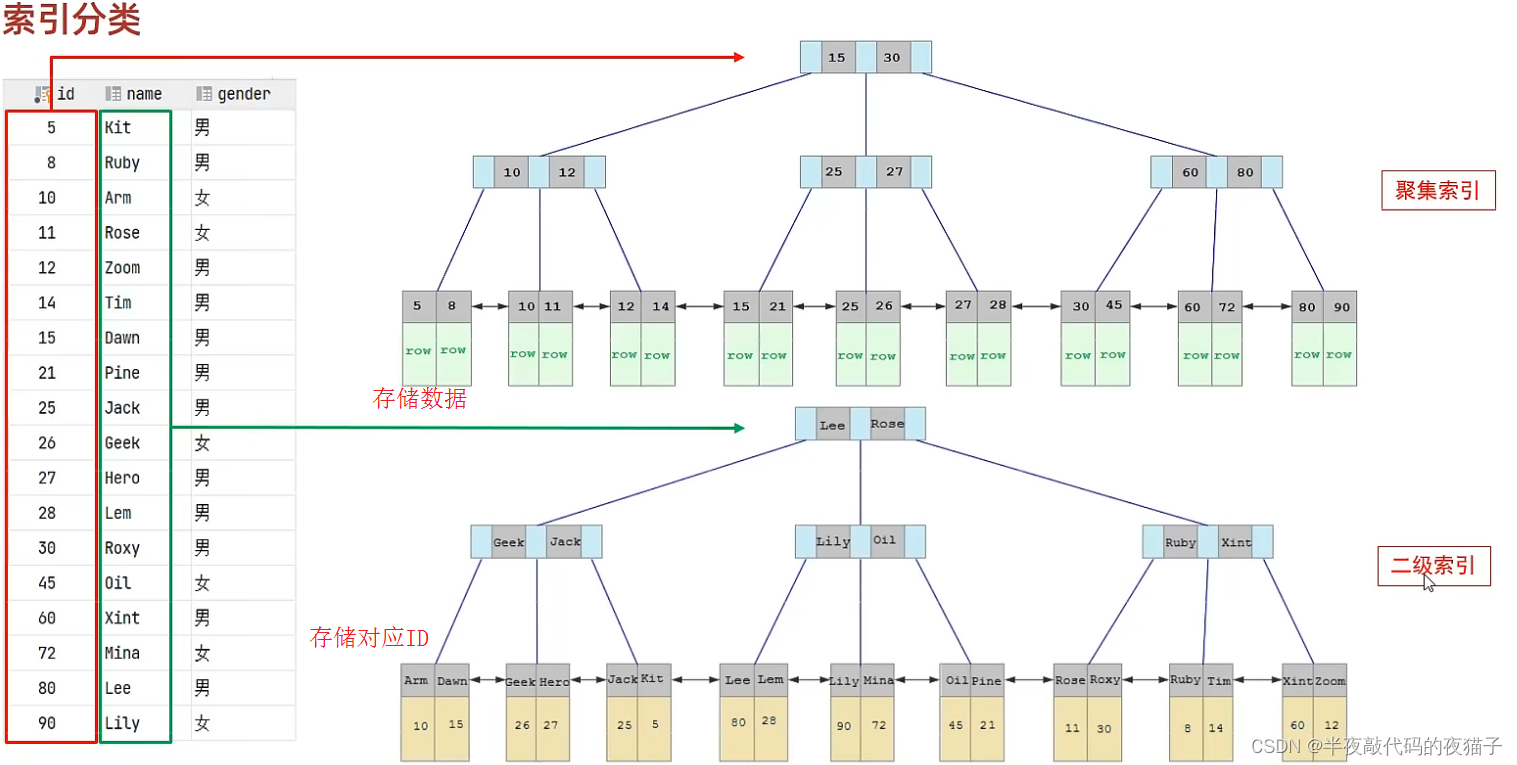
聚集索引選取規則:
如果存在主鍵,主鍵索引就是聚集索引
如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引
如果表沒有主鍵或沒有合適的唯一索引,則 InnoDB 會自動生成一個 rowid 作為隱藏的聚集索引
思考題
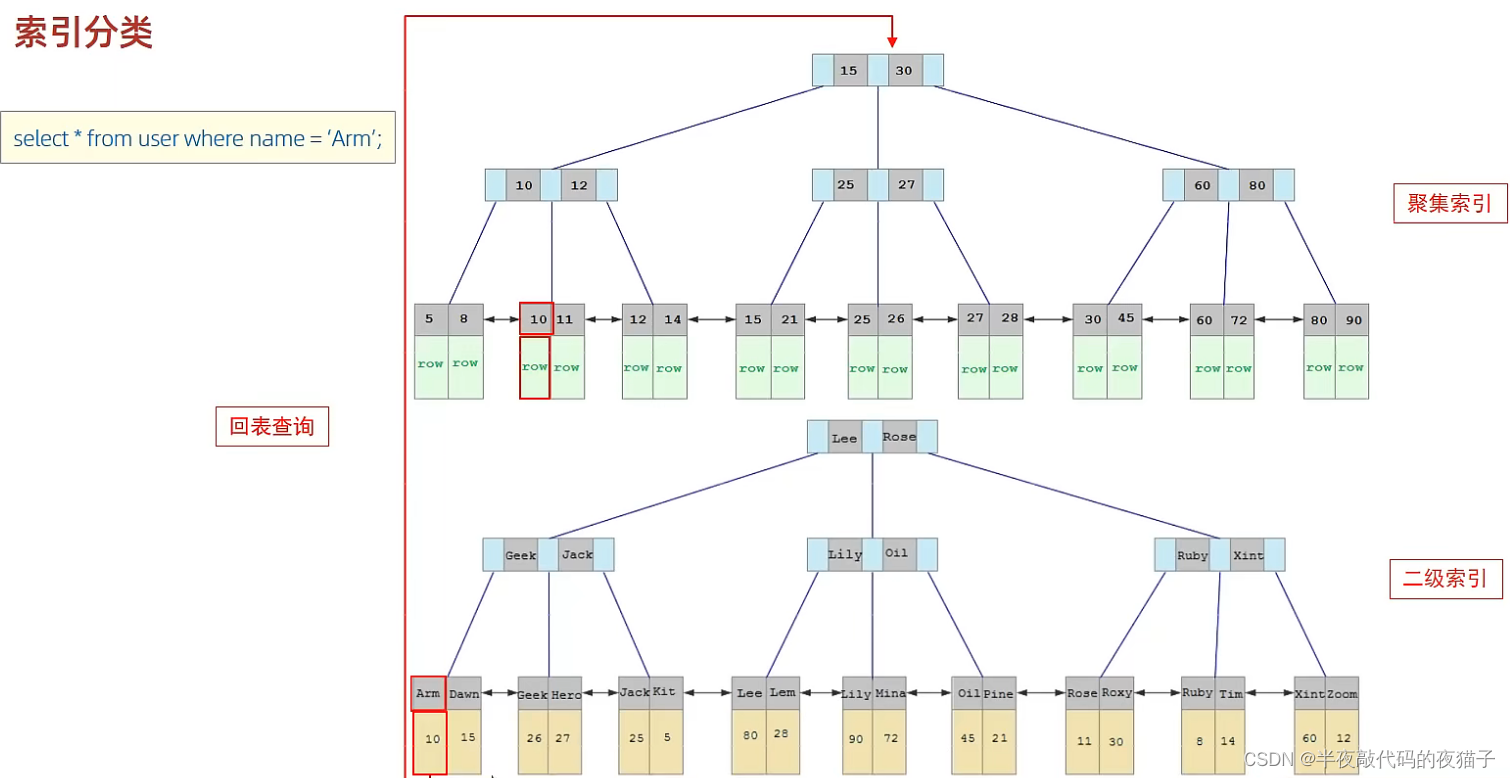
- 以下 SQL 語句,哪個執行效率高?為什么?
select * from user where id = 10;
select * from user where name = ‘Arm’;
– 備注:id為主鍵,name字段創建的有索引
答:第一條語句,因為第二條需要回表查詢,相當于兩個步驟。
- InnoDB 主鍵索引的 B+Tree 高度為多少?
答:假設一行數據大小為1k,一頁中可以存儲16行這樣的數據。InnoDB 的指針占用6個字節的空間,主鍵假設為bigint,占用字節數為8.
可得公式:n * 8 + (n + 1) * 6 = 16 * 1024,其中 8 表示 bigint 占用的字節數,n 表示當前節點存儲的key的數量,(n + 1) 表示指針數量(比key多一個)。算出n約為1170。
如果樹的高度為2,那么他能存儲的數據量大概為:1171 * 16 = 18736;
如果樹的高度為3,那么他能存儲的數據量大概為:1171 * 1171 * 16 = 21939856。
另外,如果有成千上萬的數據,那么就要考慮分表,涉及運維篇知識。
七、索引語法
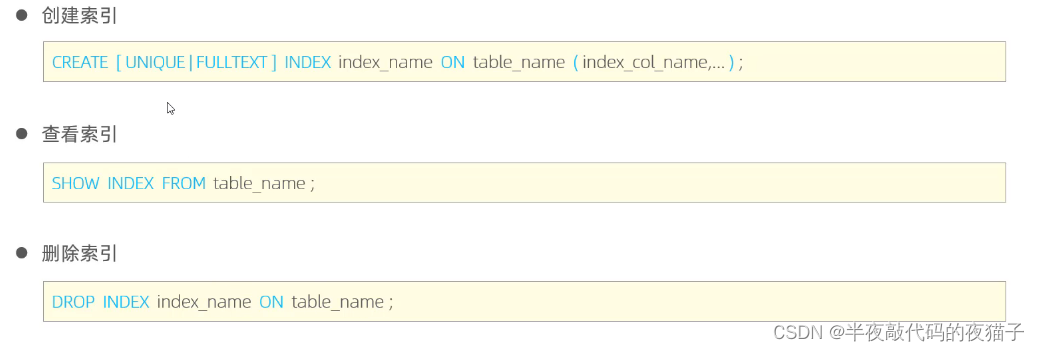
創建索引:
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, …);
如果不加 CREATE 后面不加索引類型參數,則創建的是常規索引
查看索引:
SHOW INDEX FROM table_name;
刪除索引:
DROP INDEX index_name ON table_name;
1.案例代碼

代碼如下(示例):
-- name字段為姓名字段,該字段的值可能會重復,為該字段創建索引
create index idx_user_name on tb_user(name);
-- phone手機號字段的值非空,且唯一,為該字段創建唯一索引
create unique index idx_user_phone on tb_user (phone);
-- 為profession, age, status創建聯合索引
create index idx_user_pro_age_stat on tb_user(profession, age, status);
-- 為email建立合適的索引來提升查詢效率
create index idx_user_email on tb_user(email);
-- 刪除索引
drop index idx_user_email on tb_user;
八、SQL性能分析
1.查看SQl執行頻率
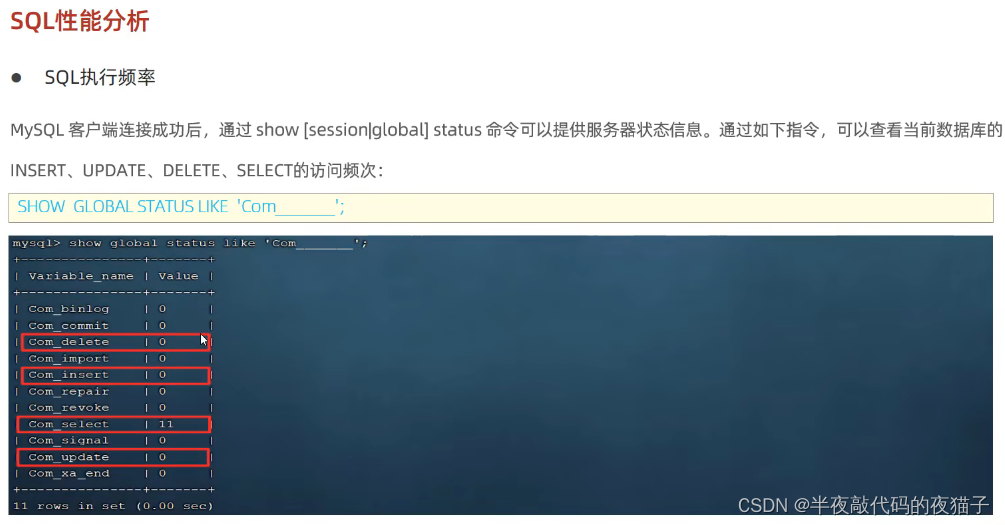
SHOW GLOBAL STATUS LIKE ‘COM_____’
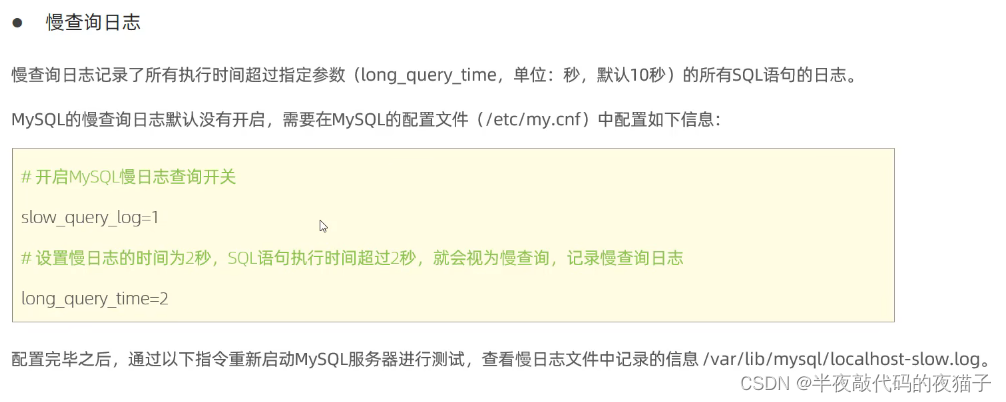
2.慢查詢日志
3.PROFILES詳情
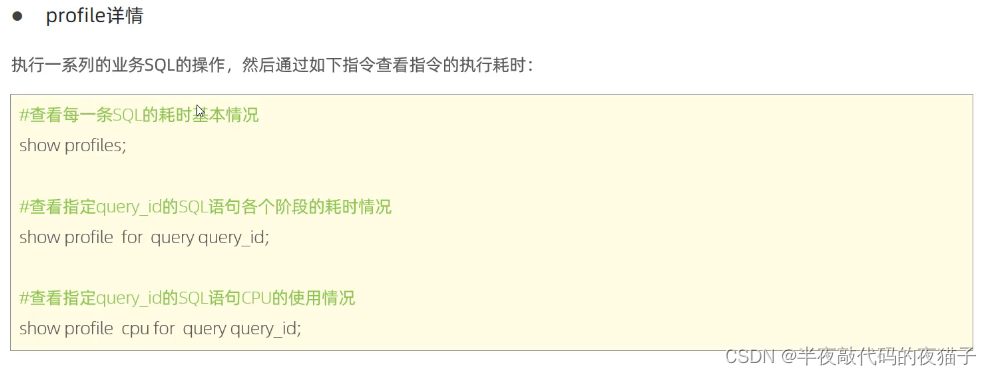
SHOW PROFILES
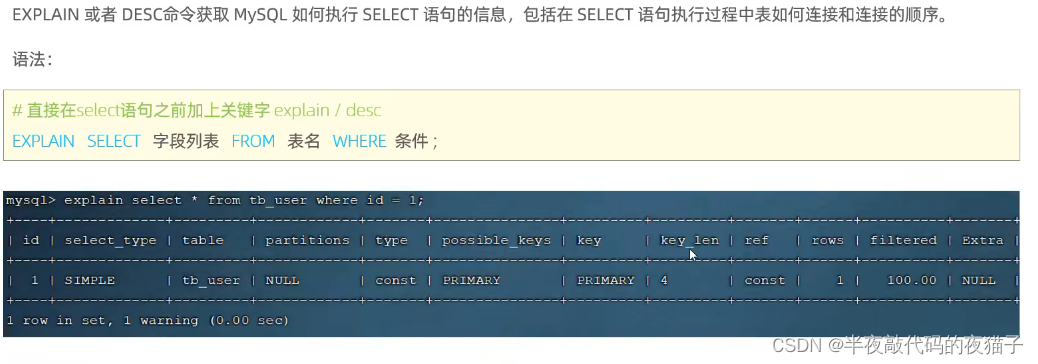
4.EXPLAIN執行計劃


九、 索引使用規則
1.最左前綴法則
如果索引關聯了多列(聯合索引),要遵守最左前綴法則,最左前綴法則指的是查詢從索引的最左列開始,并且不跳過索引中的列。
如果跳躍某一列,索引將部分失效(后面的字段索引失效)。
2.聯合索引中,出現范圍查詢(<, >),范圍查詢右側的列索引失效。可以用>=或者<=來規避索引失效問題。
3.在索引列上進行運算操作,索引將失效。如:explain select * from tb_user where substring(phone, 10, 2) = ‘15’;
4.字符串類型字段使用時,不加引號,索引將失效。如:explain select * from tb_user where phone = 17799990015;,此處phone的值沒有加引號
5.模糊查詢中,如果僅僅是尾部模糊匹配,索引不會是失效;如果是頭部模糊匹配,索引失效。如:explain select * from tb_user where profession like ‘%工程’;,前后都有 % 也會失效。
6.用 or 分割開的條件,如果 or 其中一個條件的列沒有索引,那么涉及的索引都不會被用到。
7.如果 MySQL 評估使用索引比全表更慢,則不使用索引。
十、SQL 提示
是優化數據庫的一個重要手段,簡單來說,就是在SQL語句中加入一些人為的提示來達到優化操作的目的。
例如,使用索引:
explain select * from tb_user use index(idx_user_pro) where profession=“軟件工程”;
不使用哪個索引:
explain select * from tb_user ignore index(idx_user_pro) where profession=“軟件工程”;
必須使用哪個索引:
explain select * from tb_user force index(idx_user_pro) where profession=“軟件工程”;
use 是建議,實際使用哪個索引 MySQL 還會自己權衡運行速度去更改,force就是無論如何都強制使用該索引。
十一、覆蓋索引

盡量使用覆蓋索引(查詢使用了索引,并且需要返回的列,在該索引中已經全部能找到),減少 select *。
explain 中 extra 字段含義:
using index condition:查找使用了索引,但是需要回表查詢數據
using where; using index;:查找使用了索引,但是需要的數據都在索引列中能找到,所以不需要回表查詢
如果在聚集索引中直接能找到對應的行,則直接返回行數據,只需要一次查詢,哪怕是select *;如果在輔助索引中找聚集索引,如select id, name from xxx where name=‘xxx’;,也只需要通過輔助索引(name)查找到對應的id,返回name和name索引對應的id即可,只需要一次查詢;如果是通過輔助索引查找其他字段,則需要回表查詢,如select id, name, gender from xxx where name=‘xxx’;
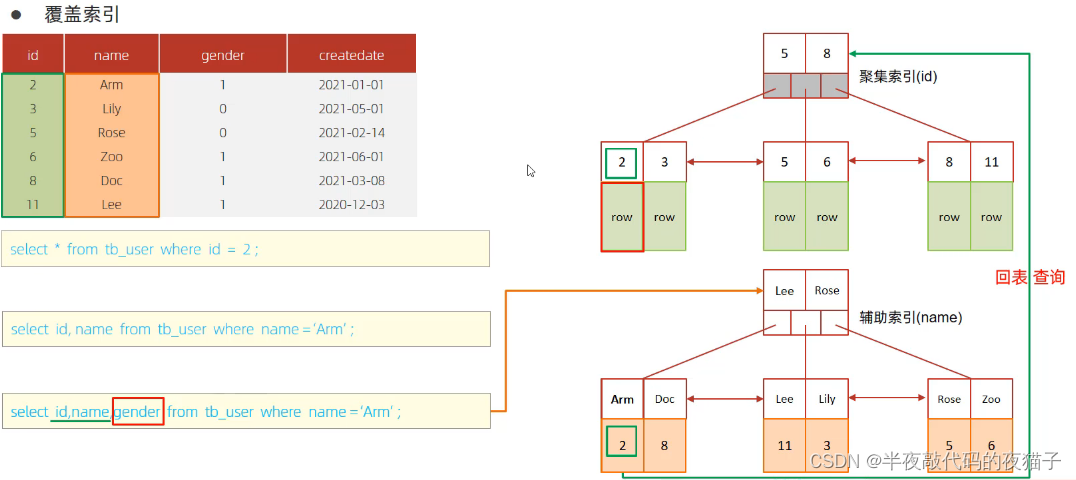
所以盡量不要用select *,容易出現回表查詢,降低效率,除非有聯合索引包含了所有字段
面試題:一張表,有四個字段(id, username, password, status),由于數據量大,需要對以下SQL語句進行優化,該如何進行才是最優方案:
select id, username, password from tb_user where username=‘itcast’;
解:給username和password字段建立聯合索引,則不需要回表查詢,直接覆蓋索引
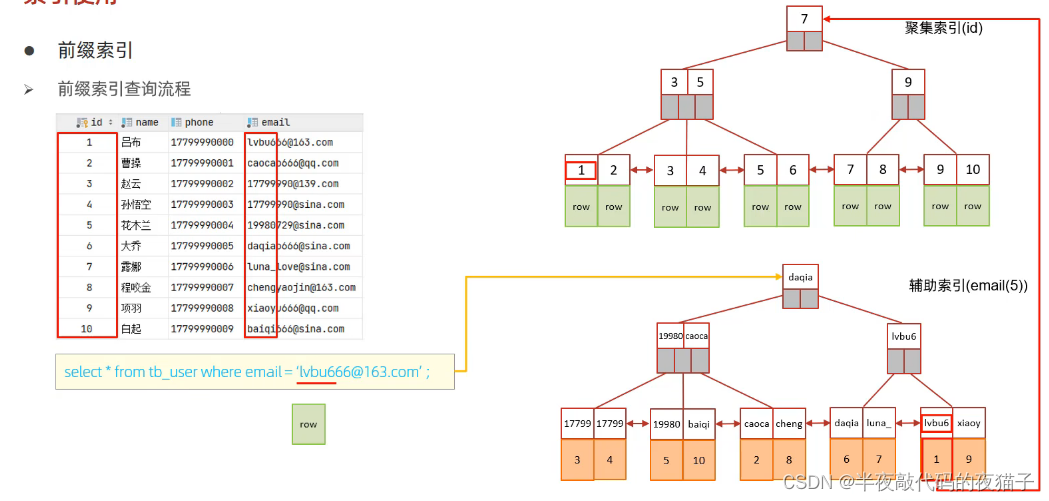
十二、前綴索引
當字段類型為字符串(varchar, text等)時,有時候需要索引很長的字符串,這會讓索引變得很大,查詢時,浪費大量的磁盤IO,影響查詢效率,此時可以只降字符串的一部分前綴,建立索引,這樣可以大大節約索引空間,從而提高索引效率。
語法:create index idx_xxxx on table_name(columnn(n));
前綴長度:可以根據索引的選擇性來決定,而選擇性是指不重復的索引值(基數)和數據表的記錄總數的比值,索引選擇性越高則查詢效率越高,唯一索引的選擇性是1,這是最好的索引選擇性,性能也是最好的。
求選擇性公式:
select count(distinct email) / count() from tb_user;
select count(distinct substring(email, 1, 5)) / count() from tb_user;
show index 里面的sub_part可以看到接取的長度
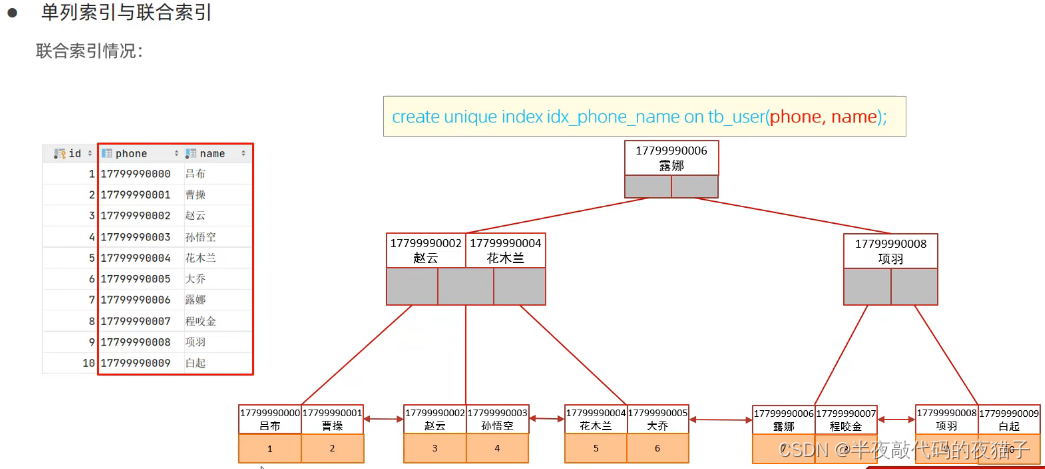
十三、單列索引&聯合索引
單列索引:即一個索引只包含單個列
聯合索引:即一個索引包含了多個列
在業務場景中,如果存在多個查詢條件,考慮針對于查詢字段建立索引時,建議建立聯合索引,而非單列索引。
單列索引情況:
explain select id, phone, name from tb_user where phone = ‘17799990010’ and name = ‘韓信’;
這句只會用到phone索引字段
注意事項
多條件聯合查詢時,MySQL優化器會評估哪個字段的索引效率更高,會選擇該索引完成本次查詢
十四、索引設計原則


)
)




--- 菜單欄功能和Tab頁功能實現)









)

