編者按:隨著大語言模型技術的快速發展,模型融合成為一種低成本但高性能的模型構建新途徑。本文作者?Maxime Labonne?利用?mergekit?庫探索了四種模型融合方法:SLERP、TIES、DARE和passthrough。通過配置示例和案例分析,作者詳細闡釋了這些算法的原理及實踐操作。
作者的核心觀點是:相比訓練全新模型,融合現有模型可以以更低計算成本獲取類似或更優異的效果。
文章通過模型融合生成了性能優異的?Marcoro14-7B-slerp?。在?Open LLM Leaderboard?和?NousResearch?兩個基準測試上,它都是同參數量模型中的佼佼者。案例驗證了作者主張的模型融合存在的高性價比。當然模型融合也存在一定問題,如訓練數據污染和可能在各種評測排行榜的分數偏高。本文提供了模型融合技術與工程實踐的詳盡指南,對AI實踐者具有重要參考價值。
作者 | Maxime Labonne
編譯?|?岳揚

Image by author
模型融合(Model merging)是一種將兩個或更多個大語言模型(LLM)合并為一個模型的技術。這是一種相對較新的實驗性方法,可以以較低成本(無需?GPU)創建新模型。 令人驚訝的是,這種技術的效果還比較出奇,使用模型融合技術在?Open LLM?Leaderboard[1]上產生了許多最先進的模型。
在本教程中,我們將使用?mergekit?[2]庫來實現這一技術。更具體地說,我們將回顧四種模型融合方法,并提供相關的配置示例。然后,我們將使用?mergekit?創建一個模型:Marcoro14–7B-slerp[3],該模型已成為?Open LLM?Leaderboard(02/01/24)上表現最佳的模型。
相關代碼已上傳至?GitHub[4]?和?Notebook[5]。個人建議使用?LazyMergekit[6]?項目,來輕松運行?mergekit。
特別感謝?mergekit?庫的作者?Charles Goddard[7]?審閱本文。
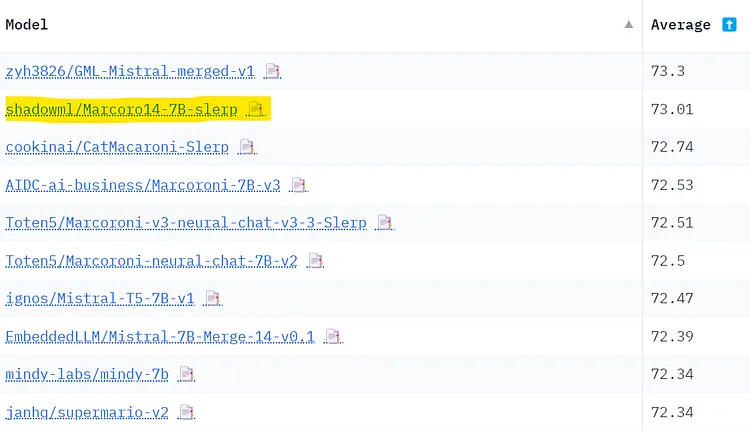
Image by author
01 🤝?融合算法
在本節,我們將重點介紹?mergekit?庫目前實現的四種模型融合方法。請注意,還有其他方法,比如?linear?[8]和?Task Arithmetic?[9]。如果你對模型融合的相關論文感興趣,我推薦閱讀Hugging Face上的這本優秀論文集[10]。
1.1 SLERP
Spherical Linear Interpolation(SLERP)是一種用于在兩個向量之間進行平穩和連貫地插值的方法。這種方法能夠保持恒定的變化速率,并保留向量所在球面空間的幾何特性。
與使用傳統的線性插值方法相比,SLERP?更受青睞的原因有幾個。例如,在高維空間中,線性插值(linear interpolation)可能導致插值向量的大小(幅度)減小(即權重的規模減小)。此外,權重方向的變化往往比大小(幅度)的變化代表的信息更有意義(如特征學習(Feature Learning)和表征(Representation))。
SLERP?是通過以下步驟實現的:
- 對輸入的向量進行歸一化處理,使它們的長度(magnitude)變為單位長度(長度為1)。這一步驟的目的是確保這些向量表示的是方向,而不是大小。
- 使用點積計算這些向量之間的角度。
- 如果這些向量幾乎平行,則默認使用線性插值以提高效率。如果輸入的兩個向量夾角較大,SLERP?將根據插值因子?t?(插值因子?t?是一個介于?0?到?1?之間的值,用于指定插值的程度。t=0?表示完全使用第一個向量,t=1?表示完全使用第二個向量,而在?0?到?1?之間的值表示兩個向量的混合程度。 )和向量之間的夾角計算比例因子(Scale factor)。
- 這些因子用于給原始向量加權,然后求和來獲得插值向量。
SLERP?目前是最流行的模型融合方法,但它僅限于一次合并兩個模型。不過,仍然可以通過分層融合多個模型,就像在?Mistral-7B-Merge-14-v0.1[11]?中所示。
配置示例:
slices:-?sources:-?model:?OpenPipe/mistral-ft-optimized-1218layer_range:?[0,?32]-?model:?mlabonne/NeuralHermes-2.5-Mistral-7Blayer_range:?[0,?32]
merge_method:?slerp
base_model:?OpenPipe/mistral-ft-optimized-1218
parameters:t:-?filter:?self_attnvalue:?[0,?0.5,?0.3,?0.7,?1]-?filter:?mlpvalue:?[1,?0.5,?0.7,?0.3,?0]-?value:?0.5
dtype:?bfloat16
這是一種經典的?SLERP?配置,SLERP?被應用于模型的每一層,以完成整體的模型融合。請注意,我們為插值因子?t?輸入了一系列梯度值(gradient of values)。自注意力層和?MLP?層的參數將使用?OpenPipe/mistral-ft-optimized-1218[12]?和?mlabonne/NeuralHermes-2.5-Mistral-7B[13]?的不同組合。
可以在?Hugging Face Hub?上找到最終訓練完成的模型,位于?mlabonne/NeuralPipe-7B-slerp[14]。
1.2 TIES
TIES-Merging?由?Yadav?等人在這篇論文[15]中引入,TIES-Merging?旨在將多個特定任務模型高效地合并為一個多任務模型。它解決了模型融合中的兩大難題:
- 模型參數的冗余:它能夠識別并消除特定任務模型中的冗余參數。具體做法是在模型微調(fine-tuning)的過程中,關注模型參數發生的變化,對微調過程中發生的變化進行排序,并選擇那些對模型性能影響最顯著的前?k%?的變化,并忽略那些在微調中變化較小或對性能影響較小的部分。
- 模型參數的符號之間存在分歧:當不同模型對同一參數提出相反的調整建議時,就會產生沖突。TIES-Merging?通過創建一個統一的符號向量來解決這些沖突,該向量表示所有模型中變化方向的最顯著方向。
TIES-Merging?分為以下三個步驟:
- Trim(修剪) :只保留一部分最重要的參數(密度參數(density parameter)),并將其余參數重置為零,從而減少特定任務模型中的冗余參數。
- Elect Sign(確定符號) :通過確定模型中哪些方向上的變化(正向或負向)是最為顯著或最主導的,創建一個統一的符號向量,以解決不同模型之間的符號沖突。
- Disjoint Merge:在合并過程中,僅考慮那些與先前創建的統一符號向量一致的參數值,并計算這些值的平均值。在計算平均值時,不考慮原始參數值為零的情況。
與?SLERP?不同,TIES?可以一次性合并多個模型。
配置示例:
models:-?model:?mistralai/Mistral-7B-v0.1#?no parameters necessary for base model-?model:?OpenPipe/mistral-ft-optimized-1218parameters:density:?0.5weight:?0.5-?model:?mlabonne/NeuralHermes-2.5-Mistral-7Bparameters:density:?0.5weight:?0.3
merge_method:?ties
base_model:?mistralai/Mistral-7B-v0.1
parameters:normalize:?true
dtype:?float16
在此配置下,我們使用?Mistral-7B?作為基礎模型來計算?delta?權重。我們融合了兩個模型:mistral-ft-optimized-1218(50%)[12]和?NeuralHermes-2.5-Mistral-7B(30%)[13],并進行了歸一化處理。這里的“density”參數意味著我們只保留了每個模型?50%的參數(另一半來自基礎模型)。
請注意,在配置中權重之和不等于?1,但?normalize:?true?參數會自動在內部將其歸一化。 此配置的靈感來自?OpenHermes-2.5-neural-chat-7b-v3-1-7B[16]?這個模型的作者提供的參數。
你可以在?Hugging Face Hub?上的?mlabonne/NeuralPipe-7B-ties[17]?找到最終訓練完成的模型。
1.3 DARE
DARE[18]?由?Yu?等人(2023?年)提出,使用了與?TIES?類似的方法,但有兩個主要區別:
- Pruning:?DARE?隨機將微調后的權重重置為原始值(基礎模型的權重)。
- Rescaling:?DARE?重新調整權重,以保持模型輸出的期望值大致不變。它將兩個(或更多)模型的重調整后的權重與基礎模型的權重相加,并使用了一個比例因子。
Mergekit?對這種方法的實現有兩種:有?TIES?的確定符號步驟(dare_ties)或沒有?TIES?的確定符號步驟(dare_linear)。
配置示例:
models:- model:?mistralai/Mistral-7B-v0.1#?No parameters necessary for base model- model:?samir-fama/SamirGPT-v1parameters:density: 0.53weight: 0.4- model:?abacusai/Slerp-CM-mist-dpoparameters:density: 0.53weight: 0.3- model:?EmbeddedLLM/Mistral-7B-Merge-14-v0.2parameters:density: 0.53weight: 0.3
merge_method:?dare_ties
base_model:?mistralai/Mistral-7B-v0.1
parameters:int8_mask: true
dtype:?bfloat16
在這個配置示例中,我們使用?dare_ties?合并了基于?Mistral-7B?的三個不同模型。這次,我選擇的權重總和為?1(總和應在?0.9?和?1.1?之間)。density?參數略高于論文中建議的值(<0.5),但看起來它能持續提供更好的結果(參見此討論[19])。
你可以在?Hugging Face Hub?的?mlabonne/Daredevil-7B[20]?上找到它。它也是本文中最好的合并模型,甚至優于?Marcoro14-7B-slerp。
1.4 Passthrough
Passthrough?方法與前幾種方法有很大不同。通過連接來自不同?LLMs?的模型層,這種方法可以生成具有奇怪參數數量的模型(例如,使用兩個?7B?參數模型可以生成?9B?模型)。 這些模型通常被稱為?"Frankenmerges?"或?“Frankenstein?模型”。
這種技術極具實驗性,但能夠成功地創建一些令人印象深刻的模型,比如使用兩個?Llama 2 70B?模型融合而成的?goliath-120b。最近發布的?SOLAR-10.7B-v1.0?也使用了同樣的思想,在他們的論文中這種技術稱為"depth-up scaling"。
配置示例:
slices:-?sources:-?model:?OpenPipe/mistral-ft-optimized-1218layer_range:?[0,?32]-?sources:-?model:?mlabonne/NeuralHermes-2.5-Mistral-7Blayer_range:?[24,?32]
merge_method:?passthrough
dtype:?bfloat16
由此產生的?frankenmerge?模型將包含第一個模型的全部?32?層和第二個模型的?8?個附加層。這將創建一個總共有?40?層和?8.99B?參數的?frankenmerge。此配置的靈感來自于?GML-Mistral-merged-v1[21]。
您可以在?Hugging Face Hub?上的?mlabonne/NeuralPipe-9B-merged?[22]找到最終模型。
02 💻?融合我們自己的模型
在本節中,我們將使用?mergekit?庫加載一個模型融合配置,運行它并將生成的結果模型上傳到?Hugging Face Hub。
首先,我們直接通過源代碼安裝?mergekit,步驟如下:
!git clone https://github.com/cg123/mergekit.git
!cd mergekit?&&?pip install?-q?-e?.
在下面的代碼塊中,我們將以?YAML?格式加載模型融合配置。還在此指定了完成模型融合后模型的名稱,以備將來使用。您可以在此復制/粘貼上一節中的任何配置。
這次,我們將使用兩個不同的模型:?Marcoroni-7B-v3[23]?和?Mistral-7B-Merge-14-v0.1[24]?并用?SLERP?方法進行模型融合。然后將配置保存為?yaml?文件,以便用作模型融合命令的輸入。
import yamlMODEL_NAME?=?"Marcoro14-7B-slerp"
yaml_config?=?"""
slices:-?sources:-?model:?AIDC-ai-business/Marcoroni-7B-v3layer_range:?[0,?32]-?model:?EmbeddedLLM/Mistral-7B-Merge-14-v0.1layer_range:?[0,?32]
merge_method:?slerp
base_model:?AIDC-ai-business/Marcoroni-7B-v3
parameters:t:-?filter:?self_attnvalue:?[0,?0.5,?0.3,?0.7,?1]-?filter:?mlpvalue:?[1,?0.5,?0.7,?0.3,?0]-?value:?0.5
dtype:?bfloat16"""#?Save config as yaml file
with open('config.yaml',?'w',?encoding="utf-8")?as f:f.write(yaml_config)
我們會使用以下參數運行模型融合命令:
- –copy-tokenizer?用于從基礎模型復制分詞器
- –allow-crimes?和?--out-shard-size?可用于將模型劃分為較小的分片(shards),可在內存較小的?CPU?上進行計算
- –lazy-unpickle?用于啟用實驗性的lazy unpickler(譯者注:“lazy unpickler”?指的是一種實驗性的、能夠以一種惰性或延遲加載的方式執行反序列化操作的機制。),以降低內存使用率
此外,某些模型可能還需要?--trust_remote_code?參數(Mistral-7B?不需要)。
該命令將下載模型融合配置中列出的所有模型的權重,并運行所選的模型融合方法(應該需要約?10?分鐘)。
#?Merge models
!mergekit-yaml config.yaml merge?--copy-tokenizer?--allow-crimes?--out-shard-size 1B?--lazy-unpickl
現在,模型已經融合并保存在?merge?目錄中。在上傳之前,我們可以創建一個包含復現該模型融合操作所需信息的?README 文件。以下代碼塊定義了一個?Jinja?模板,并自動將模型融合配置中的數據填入其中。
!pip install?-qU huggingface_hubfrom?huggingface_hub?import?ModelCard,?ModelCardData
from?jinja2?import?Templateusername?= "mlabonne"template_text?= """
---
license:?apache-2.0
tags:
-?merge
-?mergekit
-?lazymergekit
{%-?for model in models?%}
-?{{?model?}}
{%-?endfor?%}
---#?{{?model_name?}}{{?model_name?}}?is a merge of the following models using?[mergekit](https://github.com/cg123/mergekit):{%-?for model in models?%}
*?[{{?model?}}](https://huggingface.co/{{?model?}})
{%-?endfor?%}##?🧩?Configuration```yaml
{{-?yaml_config?-}}
```
"""#?Create a Jinja template object
jinja_template?=?Template(template_text.strip())#?Get list of models from config
data?=?yaml.safe_load(yaml_config)
if "models" in?data:models?= [data["models"][i]["model"] for?i?in range(len(data["models"])) if "parameters" in?data["models"][i]]
elif "parameters" in?data:models?= [data["slices"][0]["sources"][i]["model"] for?i?in range(len(data["slices"][0]["sources"]))]
elif "slices" in?data:models?= [data["slices"][i]["sources"][0]["model"] for?i?in range(len(data["slices"]))]
else:raise?Exception("No models or slices found in yaml config")#?Fill the template
content?=?jinja_template.render(model_name=MODEL_NAME,models=models,yaml_config=yaml_config,username=username,
)#?Save the model card
card?=?ModelCard(content)
card.save('merge/README.md')
現在我們有了?model card?,就可以將整個文件夾推送到?HuggingFace Hub。
from google.colab import userdata
from huggingface_hub import HfApiusername?=?"mlabonne"#?Defined in the secrets tab in Google Colab
api?=?HfApi(token=userdata.get("HF_TOKEN"))api.create_repo(repo_id=f"{username}/{MODEL_NAME}",repo_type="model"
)
api.upload_folder(repo_id=f"{username}/{MODEL_NAME}",folder_path="merge",
)
該模型現在可以在?Hugging Face Hub?上找到,位于?mlabonne/Marcoro14–7B-slerp[25]。在另一個?notebook?中,我們可以使用以下代碼嘗試在免費的?T4 GPU?上運行該模型:
!pip install?-qU transformers acceleratefrom transformers import AutoTokenizer
import transformers
import torchmodel?=?"mlabonne/Marcoro14-7B-slerp"
messages?=?[{"role":?"user",?"content":?"What is a large language model?"}]tokenizer?=?AutoTokenizer.from_pretrained(model)
prompt?=?tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
pipeline?=?transformers.pipeline("text-generation",model=model,torch_dtype=torch.float16,device_map="auto",
)outputs?=?pipeline(prompt,?max_new_tokens=256,?do_sample=True,?temperature=0.7,?top_k=50,?top_p=0.95)
我們向?LLM?提出了"What is a Large Language Model?"這個問題,并獲得了這樣的輸出結果:
A large language model is a type of artificial intelligence?(AI)?system that has been trained on vast amounts of text data.?It’s designed to understand and generate human-like language,?making predictions on what words or phrases might come next in a sentence or document.?These models use complex algorithms and neural network architectures to learn from the data and improve their performance over time.?Some well-known large language models include GPT-3 from OpenAI and BERT from Google.
融合后的模型看起來不錯,但我們需要更全面的評估。對于這種通用型模型,有一些有趣的基準測試:
- Chatbot Arena[26],它通過人類的投票編制?LLMs?排行榜。人們對不同語言模型的表現進行投票,然后使用?Elo?算法對這些模型進行排名。
- MT-bench[26],它使用?GPT-4?作為評判員,對一組多輪問題上的模型回答進行評分。
- NousResearch benchmark suite[27],它匯總了四個基準測試:AGIEval、GPT4ALL、TruthfulQA?和?Bigbench。GPT4ALL?包括了?HellaSwag、OpenBookQA、Winogrande、ARC-Easy、ARC-Challenge、BoolQ?和?PIQA。
- Open LLM Leaderboard[28],它匯總了六個基準測試:ARC、HellaSwag、MMLU、Winogrande、GSM8K?和?TruthfulQA。
不幸的是,我們無法將該模型提交到?Chatbot Arena。不過,可以選擇使用?Open LLM Leaderboard?和?NousResearch?基準測試對其進行評估。
我已經將該模型提交到了?Open LLM Leaderboard[28],它在該排行榜上被評為最佳的?7B?參數模型。以下是具體情況截圖:

Image by author
Open LLM Leaderboard?的問題在于這些基準測試是公開的。這意味著人們可以在測試數據上訓練語言模型,以獲得更好的結果。融合這些最佳的模型,也會污染模型。可以肯定的是,Marcoro14-7B-slerp?受到了污染,而且這次融合中使用的一些模型應該是在這些評估測試集上訓練過的。 如果你想創建最好的模型而非僅僅在排行榜上表現較好的模型,我建議只使用非融合的模型來創建自己的融合模型。
這就是為什么我們不能只依賴于?Open LLM Leaderboard。在?NousResearch?benchmark suite?中,我使用了?🧐?LLM AutoEval?[29]來自動計算評估分數。以下是與表現優秀的?OpenHermes-2.5-Mistral-7B?[30]進行比較的結果:

Image by author
與該模型相比,我們在每項基準測試中都取得了顯著進步。請注意,?NousResearch?benchmark suite?與?Open LLM Leaderboard?共享了一些評估任務:ARC-Challenge,TruthfulQA,HellaSwag和Winogrande。據我所知,Bigbench是唯一完全不同的基準測試(如果情況不是這樣,請隨時去原文鏈接與作者聯系)。然而,在此次模型融合中使用的模型之一仍可能是在Bigbench的評測數據集上訓練過的。
03 總結
在這篇文章中,我們介紹了使用四種不同的方法去融合?LLMs?。詳細說明了?SLERP、TIES、DARE?和?passthrough?的工作原理,并提供了相關的配置示例。最后,我們通過?mergekit?庫使用SLERP方法訓練出了?Marcoro14–7B-slerp?,并將其上傳到?Hugging Face Hub?。我們在兩個基準套件上都獲得了出色的性能:Open LLM Leaderboard(該模型是該榜單性能最佳的?7B?模型)和NousResearch。
Thanks for reading!
END
參考資料
[1]https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
[2]https://github.com/cg123/mergekit
[3]https://huggingface.co/mlabonne/Marcoro14-7B-slerp
[4]https://github.com/mlabonne/llm-course/blob/main/Mergekit.ipynb
[5]https://colab.research.google.com/drive/1_JS7JKJAQozD48-LhYdegcuuZ2ddgXfr?usp=sharing
[6]https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing
[7]https://www.linkedin.com/in/charles-goddard-7b6797b/
[8]https://github.com/cg123/mergekit/tree/1011ef3a84e4c5545473602baf7ef32d535044a9#linear
[9]https://arxiv.org/abs/2212.04089
[10]https://huggingface.co/collections/osanseviero/model-merging-65097893623330a3a51ead66
[11]https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.1
[12]https://huggingface.co/OpenPipe/mistral-ft-optimized-1218
[13]https://huggingface.co/mlabonne/NeuralHermes-2.5-Mistral-7B
[14]https://huggingface.co/mlabonne/NeuralPipe-7B-slerp
[15]https://arxiv.org/abs/2306.01708
[16]https://huggingface.co/Weyaxi/OpenHermes-2.5-neural-chat-7b-v3-1-7B
[17]https://huggingface.co/mlabonne/NeuralPipe-7B-ties
[18]https://arxiv.org/abs/2311.03099
[19]https://github.com/cg123/mergekit/issues/26
[20]https://huggingface.co/mlabonne/Daredevil-7B
[21]https://huggingface.co/zyh3826/GML-Mistral-merged-v1
[22]https://huggingface.co/mlabonne/NeuralPipe-9B-merged
[23]https://huggingface.co/AIDC-ai-business/Marcoroni-7B-v3
[24]https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.1
[25]https://huggingface.co/mlabonne/Marcoro14-7B-slerp
[26]https://chat.lmsys.org/
[27]https://github.com/teknium1/LLM-Benchmark-Logs
[28]https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
[29]https://github.com/mlabonne/llm-autoeval
[30]https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B
原文鏈接:
https://towardsdatascience.com/merge-large-language-models-with-mergekit-2118fb392b54
架構)
















-day05)

)