1、一些常量的定義
這里針對MIN_TREEIFY_CAPACITY 這個值進行解釋一下。
java8里面,HashMap 的數據結構是數組 + (鏈表或者紅黑樹),每個數組節點下可能會存在鏈表和紅黑樹之間的轉換,當同一個索引下面的節點超過8個時,首先會看當前數組長度,如果大于64,則會發生鏈表向紅黑樹的 轉換,否則不會轉換,而是擴容。
// 默認的初始化長度 16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16// 默認的最大容量 2^30static final int MAXIMUM_CAPACITY = 1 << 30;// 默認的擴容因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 鏈表轉為樹的閾值static final int TREEIFY_THRESHOLD = 8;// 樹轉為鏈表的閾值static final int UNTREEIFY_THRESHOLD = 6;static final int MIN_TREEIFY_CAPACITY = 64;// map已存節點的數量transient int size;// 修改次數 transient int modCount;// 擴容閾值 當size達到這個值的時候,hashmap開始擴容int threshold;// 加載因子 threshold = 容量 * loadFactorfinal float loadFactor;2、構造器
HashMap提供了三個構造器。
// 無參構造器,使用默認加載因子 0.75public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}// 只傳入初始化容量,也會使用默認加載因子 0.75public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}// 同時傳入初始化容量和加載因子 (初始化容量要大于0,且不能超過最大容量)public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;// 初始化的容量先賦值給了threshold 暫存。this.threshold = tableSizeFor(initialCapacity);}注意看,使用帶參構造器 會調用 tableSizeFor(initialCapacity); 這個方法是干嘛的呢?其實就是為了計算初始化容量。HashMap規定,其容量必須是2的N次方
- ?不傳初始化容量,就取默認值16
- 傳了初始化容量,則初始化容量設置為大于等于該數值的 一個最小的2的N次方
- 比如傳入了7,不是2的N次方,那么取比他大的最小的2的N次方,就是8
- 比如傳入了8,剛好是2的N次方,那就取8
- 比如傳入了9,不是2的N次方,那么取比他大的最小的2的N次方,就是16
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}或等于操作?a |= b ,其實就是?a = a | b。
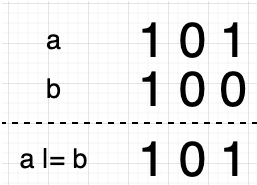
無符號右移操作:a >>> b 就表示將a向右移動b位,左邊空出來的用0補充,右邊的被丟棄

那么?n |= n >>> 1 操作得到的結果就是,最高位和次高位的結果為1;--- > n 的前兩位為1
n |= n >>> 2 操作之后 --- > n的前四位為1
.... 一通操作之后,得到的值是一個低位全是1的值。然后返回的時候+1,得到的值就是一個比n大的2的N次方。而開頭的?int n = cap - 1 是為了解決本身就是2的N次方的場景。
3、插入操作
3.1、插入操作的具體流程
- 插入前首先判斷數組是否為空,如果為空就進行初始化
- 計算key的hash值,然后和數組長度-1 進行 & 運算,獲取在數組中的索引位置
- 當前位置不存在元素,就直接創建新節點放在當前索引位置
- 當前位置元素存在,就走后續的邏輯
- 判斷當前坐標下頭節點的hash值是否和 key的hash相等,如果相等就進行替換(還要判斷一個控參 onlyIfAbsent,這個為false的時候才會替換,最常用的put操作這個值就是false?)
- 如果不相等,判斷當前是鏈表還是紅黑樹
- 如果是鏈表,遍歷鏈表節點,并統計節點個數:
- 如果找到了相同的key,就進行覆蓋操作,
- 如果沒有找到相同key,就將節點添加到鏈表最后面,并判斷是否超過8個節點,如果大于等于8,就要鏈表轉紅黑樹操作。
- 如果是紅黑樹:找到紅黑樹根節點,從根節點開始遍歷:
- 找到相同的key,就進行替換
- 找不到相同的key,就放到相應的位置,然后進行紅黑樹插入平衡調整
- 插入完成之后,判斷當前節點數目是否超過擴容閾值,如果超過,就進行擴容。
public V put(K key, V value) {/*** 首先計算出了key的hash 值*/return putVal(hash(key), key, value, false, true);
}final V putVal ( int hash, K key, V value,boolean onlyIfAbsent, boolean evict){HashMap.Node<K, V>[] tab;HashMap.Node<K, V> p;int n, i;/*** 判斷數組是否為空,為空則進行數組初始化 * ---> tab = resize() 然后獲取數組的長度*/if ((tab = table) == null || (n = tab.length) == 0) {n = (tab = resize()).length;}/*** 計算當前節點要插入數組的索引的位置 ---> (n - 1) & hash* 如果索引處不存在節點,就新創建節點放到索引的位置*/if ((p = tab[i = (n - 1) & hash]) == null) {tab[i] = newNode(hash, key, value, null);}/*** 如果索引處存在節點,走這個邏輯*/else {HashMap.Node<K, V> e;K k;if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {/*** 進入這個分支,說明要插入的節點和頭節點的key相同*/e = p;} else if (p instanceof HashMap.TreeNode) {/*** 說明頭節點是紅黑樹了,要把這個新節點插入到紅黑樹中,涉及到新節點的插入,紅黑樹的平衡調整等*/e = ((HashMap.TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);} else {/*** 說明頭節點是鏈表節點,遍歷鏈表*/for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {/*** 遍歷到最后了,創建新節點插入到尾端* 還要判斷節點是否超過8個,超過了要轉化為紅黑樹*/p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st{treeifyBin(tab, hash);}break;}if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {/*** 找到了相同key的value*/break;}p = e;}}/*** e不為空,說明有key相同的情況,替換成新的value,然后直接返回舊的節點* 因為節點數目不存在變化,因此不需要進行擴容判斷*/if (e != null) { // existing mapping for keyV oldValue = e.value;// onlyIfAbsent的判斷if (!onlyIfAbsent || oldValue == null) {e.value = value;}afterNodeAccess(e);return oldValue;}}++modCount;/*** 如果當前節點超過了擴容閾值,就進行擴容,然后返回null*/if (++size > threshold) {resize();}afterNodeInsertion(evict);return null;
}3.2、 key的hash值是怎么計算的?為什么要這么計算?
- 如果key為空,就直接返回0
- 不為空將 key的hashcode 和 hashcode左移16位進行& 運算
- ----?左移16位主要就是為了將hash的高位也參與到hash計算中,減少hash沖突。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}3.3、resize擴容流程介紹
- 首先會對老數組進行一系列的校驗,大致分為:
- 老數組為空,就設置一下數組長度和擴容閾值,新建數組,然后返回
- 老數組不為空,校驗老數組長度,如果長度超過上限,擴容閾值修改為int最大值,返回
- 否則:容量、擴容閾值變為原來的2倍
- 接著開始遍歷老數組
- 當前坐標下沒有節點,就繼續遍歷
- 當前坐標只有一個節點,計算hash值,然后放到新數組對應位置
- 當前坐標是鏈表,走鏈表邏輯:
- 遍歷鏈表節點,計算??e.hash & oldCap ,這個值如果是0,說明擴容后,在新數組的坐標和老數組一樣,如果為1 ,說明擴容后在新數組的坐標應該是 老數組坐標 + 擴容長度,因此通過計算這個值,可以將鏈表節點分為高位節點和低位節點
- 定義高位和低位兩個鏈表,不斷將鏈表節點放在這兩個新鏈表尾端
- 然后低位鏈表放在新數組的i 坐標位置,高位鏈表放在新數組i+oldcap的位置
- 當前坐標是紅黑樹,走紅黑樹的邏輯
- 因為維護紅黑樹的時候也維護了一個雙向鏈表,因此通過 e.prev e.next就可以遍歷整個樹 (也就是說遍歷鏈表就等于遍歷樹)
- 同樣是將元素分別放在低位鏈表和高位鏈表中,并計算每個鏈表的長度
- 低位鏈表的頭節點放在新數組的i坐標位置,然后維護鏈表的紅黑樹結構(維護前會判斷高位鏈表是否有值,如果為空,說明樹結構沒有被破壞而是直接遷移到新數組中了,這個時候就可以不用重新維護樹結構了)
- 高位鏈表頭節點放在新數組i+oldcap的位置,維護樹結構,同3
注意:jdk1.8中,hashmap的擴容,鏈表節點處理只遍歷了一次,而ConcurrentHashMap中遍歷了兩次。
final HashMap.Node<K, V>[] resize() {HashMap.Node<K, V>[] oldTab = table;// 臨時存儲老的數組長度和老的擴容閾值int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;// 定義新的數組長度和新的擴容閾值int newCap, newThr = 0;// oldCap > 0 說明數組已經初始化了if (oldCap > 0) {// 當前數組長度已經大于等于最大數組長度了,就把擴容閾值設置為int最大值返回,不需要擴容了if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 否則,長度變為原來2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {newThr = oldThr << 1; // double threshold}} else if (oldThr > 0) // initial capacity was placed in threshold{newCap = oldThr;} else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float) newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ? (int) ft : Integer.MAX_VALUE);}// hashmap 初始化的時候,是將數組初始化長度賦值給了threshold,這里開始才是變成擴容閾值。threshold = newThr;// 創建新的數組,并將新數組賦值給tableHashMap.Node<K, V>[] newTab = (HashMap.Node<K, V>[]) new HashMap.Node[newCap];table = newTab;// 老數組不為空,就走擴容邏輯,否則就直接返回新創建的數組了if (oldTab != null) {// 對老數組開始遍歷for (int j = 0; j < oldCap; ++j) {HashMap.Node<K, V> e;// 數組的坐標節點為空說明沒數據,直接遍歷下個坐標if ((e = oldTab[j]) != null) {oldTab[j] = null;// 只有個節點,直接取出該節點,計算hash值,放到新數組中if (e.next == null) {newTab[e.hash & (newCap - 1)] = e;}// 當前是紅黑樹,執行紅黑樹擴容邏輯else if (e instanceof HashMap.TreeNode) {((HashMap.TreeNode<K, V>) e).split(this, newTab, j, oldCap);}// 當前是鏈表,執行鏈表擴容邏輯else { // preserve order// 定義高位鏈表和低位鏈表HashMap.Node<K, V> loHead = null, loTail = null;HashMap.Node<K, V> hiHead = null, hiTail = null;HashMap.Node<K, V> next;// 遍歷鏈表do {next = e.next;// e.hash & oldCap 可以計算出當前節點應該放在高位還是低位if ((e.hash & oldCap) == 0) {// 將遍歷到的節點放在loTail尾部// loHead指向低位節點的頭節點if (loTail == null) {loHead = e;} else {loTail.next = e;}loTail = e;} else {// 將遍歷到的節點放在hiTail尾部// hiHead指向高位節點的頭節點if (hiTail == null) {hiHead = e;} else {hiTail.next = e;}hiTail = e;}} while ((e = next) != null);// 低位鏈表的頭節點放在 新數組的原index中if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 高位鏈表的頭節點放在 新數組的原index + oldCap 中if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}final void split(HashMap<K, V> map, HashMap.Node<K, V>[] tab, int index, int bit) {// ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); 這個this 就是數組中取出來的第一個元素,也就是樹的頭節點HashMap.TreeNode<K, V> b = this;// 設置低位首節點和低位尾節點,高位首節點和高位尾節點HashMap.TreeNode<K, V> loHead = null, loTail = null;HashMap.TreeNode<K, V> hiHead = null, hiTail = null;// 這兩個值用于記錄低位坐標和高位坐標節點的數目int lc = 0, hc = 0;// 從根節點開始,對整個樹進行遍歷,我們介紹了,紅黑樹其實也維護了雙向鏈表,因此通過 e.prev e.next就可以遍歷整個樹for (HashMap.TreeNode<K, V> e = b, next; e != null; e = next) {next = (HashMap.TreeNode<K, V>) e.next;e.next = null;// bit傳入的就是oldCap,也就是舊數組的長度,通過hash & 運算,就可以判斷是放在新數組的低位坐標還是高位坐標if ((e.hash & bit) == 0) {if ((e.prev = loTail) == null) {loHead = e;} else {loTail.next = e;}loTail = e;++lc;} else {if ((e.prev = hiTail) == null) {hiHead = e;} else {hiTail.next = e;}hiTail = e;++hc;}}// 低位坐標處理邏輯if (loHead != null) {// 低位節點數目小于等于6,就轉為鏈表if (lc <= UNTREEIFY_THRESHOLD) {tab[index] = loHead.untreeify(map);}// 否則,還是紅黑樹結構else {// 鏈表頭節點賦值給 tab[index]tab[index] = loHead;if (hiHead != null)// 對低位的鏈表維護紅黑樹結構// 為什么加一個hiHead != null 判斷呢?因為如果原來的元素全部都分到了低位節點,那說明樹結構沒有被破壞,就不需要維護了{loHead.treeify(tab);}}}// 高位和低位的處理一樣if (hiHead != null) {if (hc <= UNTREEIFY_THRESHOLD) {tab[index + bit] = hiHead.untreeify(map);} else {tab[index + bit] = hiHead;if (loHead != null) {hiHead.treeify(tab);}}}
}3.4 鏈表轉紅黑樹
final void treeifyBin(HashMap.Node<K, V>[] tab, int hash) {int n, index;HashMap.Node<K, V> e;// 如果數組為空,或者數組長度小于64,就先嘗試擴容,因為鏈表轉樹的消耗太大了if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) {resize();} // 先拿到當前坐標下的頭節點 ,賦值給 eelse if ((e = tab[index = (n - 1) & hash]) != null) {// 定義頭節點和尾節點HashMap.TreeNode<K, V> hd = null, tl = null;// 遍歷鏈表do {// 將鏈表節點轉化為紅黑樹節點HashMap.TreeNode<K, V> p = replacementTreeNode(e, null);if (tl == null) {// 最開始遍歷的時候,尾節點肯定為空,就把跟節點指向當前節點hd = p;} else {// 雙向鏈表,將前后節點關聯起來p.prev = tl;tl.next = p;}// 當前節點設置為尾節點tl = p;} while ((e = e.next) != null);// 截止到目前,把鏈表中所有的node對象轉變為了紅黑樹節點,單向鏈表變成了雙向鏈表// 把轉換后的雙向鏈表,替換原來位置上的單向鏈表if ((tab[index] = hd) != null) {// 樹化操作hd.treeify(tab);}}
}final void treeify(HashMap.Node<K, V>[] tab) {HashMap.TreeNode<K, V> root = null;// 因為是調用的hd.treeify(tab),因此,這里的this就是雙向鏈表的頭節點,這里先賦值給了臨時變量x// 開始循環這個雙向鏈表了,x就是循環的元素,next就是下一個節點元素for (HashMap.TreeNode<K, V> x = this, next; x != null; x = next) {next = (HashMap.TreeNode<K, V>) x.next;// 當前節點左右孩子都設置為空x.left = x.right = null;if (root == null) {// 第一次進來,根節點肯定是空,將頭節點設置為根節點,染色黑x.parent = null;x.red = false;root = x;} // 第一次以后的循環都走下面的分支了else {// 定義當前節點的key 和 hashK k = x.key;int h = x.hash;Class<?> kc = null;// 開始遍歷樹結構了for (HashMap.TreeNode<K, V> p = root; ; ) {// ph 和 pk 定義當前樹節點的 hash 和 key ,通過hash判斷當前節點要放在樹的左邊還是右邊// dir代表 往樹左邊放還是右邊放int dir, ph;K pk = p.key;if ((ph = p.hash) > h) {dir = -1;} else if (ph < h) {dir = 1;} // hash相等的時候,繼續一系列的判斷,最終得到direlse if ((kc == null && (kc = comparableClassFor(k)) == null)|| (dir = compareComparables(kc, k, pk)) == 0) {dir = tieBreakOrder(k, pk);}HashMap.TreeNode<K, V> xp = p;// dir <= 0 說明是在左側,否則是在右側// 只有保證當前樹節點沒有對應的左孩子或者右孩子的時候,才會將當前節點掛上去,否則繼續循環遍歷樹結構if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0) {xp.left = x;} else {xp.right = x;}// 紅黑樹平衡操作root = balanceInsertion(root, x);// 當前節點已經插入紅黑樹中了,可以跳出當前循環,遍歷鏈表的下一個節點break;}}}}// 把root節點放在當前坐標位置moveRootToFront(tab, root);
}/*** 我們要明確,紅黑樹節點不但維護了樹結構,還維護了雙向鏈表的結構* 這個方法的作用就是:* 1、將樹的根節點,賦值給tab[i]* 2、將這個節點,變成雙向鏈表的頭節點*/
static <K, V> void moveRootToFront(HashMap.Node<K, V>[] tab, HashMap.TreeNode<K, V> root) {int n;if (root != null && tab != null && (n = tab.length) > 0) {// 通過根節點 hash計算在數組中的索引位置int index = (n - 1) & root.hash;// 取到當前索引的第一個節點HashMap.TreeNode<K, V> first = (HashMap.TreeNode<K, V>) tab[index];// 如果root節點和 當前索引位置第一個節點不一樣,就把root節點放在當前坐標位置// 同時要維護雙向鏈表,將root節點變成雙向鏈表的第一個節點。if (root != first) {HashMap.Node<K, V> rn;tab[index] = root;// 將root節點變成雙向鏈表的第一個節點。HashMap.TreeNode<K, V> rp = root.prev;if ((rn = root.next) != null) {((HashMap.TreeNode<K, V>) rn).prev = rp;}if (rp != null) {rp.next = rn;}if (first != null) {first.prev = root;}root.next = first;root.prev = null;}assert checkInvariants(root);}
}4、刪除操作
- 數組沒有初始化,或者對應下標節點為空,說明沒有該元素,直接返回null
- 查找node,(紅黑樹或者鏈表結構)
- 刪除node,(紅黑樹或者鏈表結構) --- 刪除節點的時候即便樹的元素小于等于6也不會轉為鏈表,在代碼里面沒看到,只在擴容的時候會有轉換操作。
/*** 刪除方法,主要介紹以下兩個參數* @param matchValue true:只有值也相同的時候才刪除* @param movable true:刪除后移動節點,樹結構的時候會用到,一般為true*/
final HashMap.Node<K, V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {HashMap.Node<K, V>[] tab;HashMap.Node<K, V> p;int n, index;// 組數沒有初始化,或者對應坐標下面沒有元素,直接返回null了if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {// node記錄要刪除的元素HashMap.Node<K, V> node = null, e;K k;V v;// 找要刪除的元素,賦值給nodeif (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {node = p;} else if ((e = p.next) != null) {if (p instanceof HashMap.TreeNode) {// 從樹中查找節點node = ((HashMap.TreeNode<K, V>) p).getTreeNode(hash, key);} else {// 從鏈表中查找節點 ,鏈表結構時,p是node的前置節點do {if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {// node不為空的時候,刪除節點if (node instanceof HashMap.TreeNode) {((HashMap.TreeNode<K, V>) node).removeTreeNode(this, tab, movable);} else if (node == p) {tab[index] = node.next;} else {p.next = node.next;}// 修改次數加1,size減一,返回刪除的node++modCount;--size;afterNodeRemoval(node);return node;}}return null;
}
![[計算機網絡]---TCP協議](http://pic.xiahunao.cn/[計算機網絡]---TCP協議)

![P1024 [NOIP2001 提高組] 一元三次方程求解](http://pic.xiahunao.cn/P1024 [NOIP2001 提高組] 一元三次方程求解)


)
:程序環境和預處理詳解)



)






)
