》》歡迎 點贊,留言,收藏加關注《《
1. 模型構建的步驟:
在構建AI模型時,一般有以下主要步驟:準備數據、數據預處理、劃分數據集、配置模型、訓練模型、評估優化、模型應用,如下圖所示:

【注意】由于MNIST數據集太經典了,很多深度學習書籍在介紹該入門模型案例時,基本上就是直接下載獲取數據,然后就進行模型訓練,最后得出一個準確率出來。但這樣的入門案例學習后,當要拿自己的數據來訓練模型,卻往往不知該如何處理數據、如何訓練、如何應用。在本文,將分兩種情況進行介紹:(1)使用MNIST數據(本案例),(2)使用自己的數據。
2. 庫文件的導入
2.1 使用現成的mnist數據
import tensorflow as tf
# 從tensorflow.examples.tutorials.mnist 導入模塊
# 這是TensorFlow 為了教學MNIST而提前編制的程序
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
mnist = input_data.read_data_sets('/home/anaconda2/桌面/mnist_practice/MNIST_data',one_hot=True)
# MNIST_data指的是存放數據的文件夾路徑,one_hot=True 為采用one_hot的編碼方式編碼標簽
# 從MNIST_data/中讀取MNIST數據,這條語句在數據不存在時,會自動執行下載
2.2 使用自己做的數據
如果是使用自己的數據集,在準備數據時的重要工作是“標注數據”,也就是對數據進行打標簽,主要的標注方式有:
① 整個文件打標簽。例如MNIST數據集,每個圖像只有1個數字,可以從0至9建10個文件夾,里面放相應數字的圖像;也可以定義一個規則對圖像進行命名,如按標簽+序號命名;還可以在數據庫里面創建一張對應表,存儲文件名與標簽之間的關聯關系。如下圖:

② 圈定區域打標簽。例如ImageNet的物體識別數據集,由于每張圖片上有各種物體,這些物體位于不同位置,因此需要圈定某個區域進行標注,目前比較流行的是VOC2007、VOC2012數據格式,這是使用xml文件保存圖片中某個物體的名稱(name)和位置信息(xmin,ymin,xmax,ymax)。
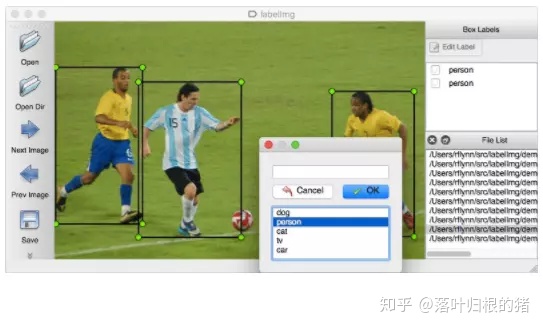
如果圖片很多,一張一張去計算位置信息,然后編寫xml文件,實在是太耗時耗力了。所幸,有一位大神開源了一個數據標注工具labelImg(https://github.com/tzutalin/labelImg),只要在界面上畫框標注,就能自動生成VOC格式的xml文件了,非常方便,如下圖所示:
③ 數據截段打標簽。針對語音識別、文字識別等,有些是將數據截成一段一段的語音或句子,然后在另外的文件中記錄對應的標簽信息。
3. 數據預處理
在準備好基礎數據之后,需要根據模型需要對基礎數據進行相應的預處理。
(1)使用MNIST數據(本案例)
由于MNIST數據集的尺寸統一,只有黑白兩種像素,無須再進行額外的預處理,直接拿來建模型就行。
(2)使用自己的數據
而如果是要訓練自己的數據,根據模型需要一般要進行以下預處理:

a. 統一格式:即統一基礎數據的格式,例如圖像數據集,則全部統一為jpg格式;語音數據集,則全部統一為wav格式;文字數據集,則全部統一為UTF-8的純文本格式等,方便模型的處理;
b. 調整尺寸:根據模型的輸入要求,將樣本數據全部調整為統一尺寸。例如LeNet模型是32x32,AlexNet是224x224,VGG是224x224等;
c. 灰度化:根據模型需要,有些要求輸入灰度圖像,有些要求輸入RGB彩色圖像;
d. 去噪平滑:為提升輸入圖像的質量,對圖像進行去噪平滑處理,可使用中值濾波器、高斯濾波器等進行圖像的去噪處理。如果訓練數據集的圖像質量很好了,則無須作去噪處理;
e. 其它處理:根據模型需要進行直方圖均衡化、二值化、腐蝕、膨脹等相關的處理;
f. 樣本增強:有一種觀點認為神經網絡是靠數據喂出來的,如果能夠增加訓練數據的樣本量,提供海量數據進行訓練,則能夠有效提升算法的質量。常見的樣本增強方式有:水平翻轉圖像、隨機裁剪、平移變換,顏色、光照變換等。
4. 劃分數據集
在訓練模型之前,需要將樣本數據劃分為訓練集、測試集,有些情況下還會劃分為訓練集、測試集、驗證集。
(1)使用MNIST數據
本案例要訓練模型的MNIST數據集,已經提供了訓練集、測試集,代碼如下:
#load data(提取訓練集、測試集)
train_xdata = mnist.train.images #訓練集樣本
validation_xdata = mnist.validation.images #驗證集樣本
test_xdata = mnist.test.images #測試集樣本
#labels(提取標簽數據)
train_labels = mnist.train.labels #訓練集標簽
validation_labels = mnist.validation.labels #驗證集標簽
test_labels = mnist.test.labels #測試集標簽
print(train_xdata.shape,train_labels.shape) #輸出訓練集樣本和標簽的大小
(2)使用自己的數據
如果是要劃分自己的數據集,可使用scikit-learn工具進行劃分,代碼如下:
fromsklearn.cross_validationimporttrain_test_split
# 隨機選取75%的數據作為訓練樣本,其余25%的數據作為測試樣本
# X_data:數據集
# y_labels:數據集對應的標簽X_train,X_test,y_train,y_test=train_test_split(X_data,y_labels,test_size=0.25,random_state=33)
5. 查看數據與可視化樣本
#查看數據,例如訓練集中第一個樣本的內容和標簽
print(train_xdata[0]) #是一個包含784個元素且值在[0,1]之間的向量
print(train_labrels[0])
#可視化樣本,下面是輸出了訓練集中前20個樣本
fig, ax = plt.subplots(nrows=4,ncols=5,sharex='all',sharey='all')
ax = ax.flatten()
for i in range(20):
。。img = train_xdata[i].reshape(28, 28)
。。ax[i].imshow(img,cmap='Greys')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
6. 輸出效果
......................省略省略


)




:MySQL服務安裝實戰)



示例)

![28、清華大學腦機接口實驗組SSVEP數據集:通過視覺觸發BCI[飛一般的趕腳!]](http://pic.xiahunao.cn/28、清華大學腦機接口實驗組SSVEP數據集:通過視覺觸發BCI[飛一般的趕腳!])






