
吞一塊大餅,還不如切成小塊吃得香
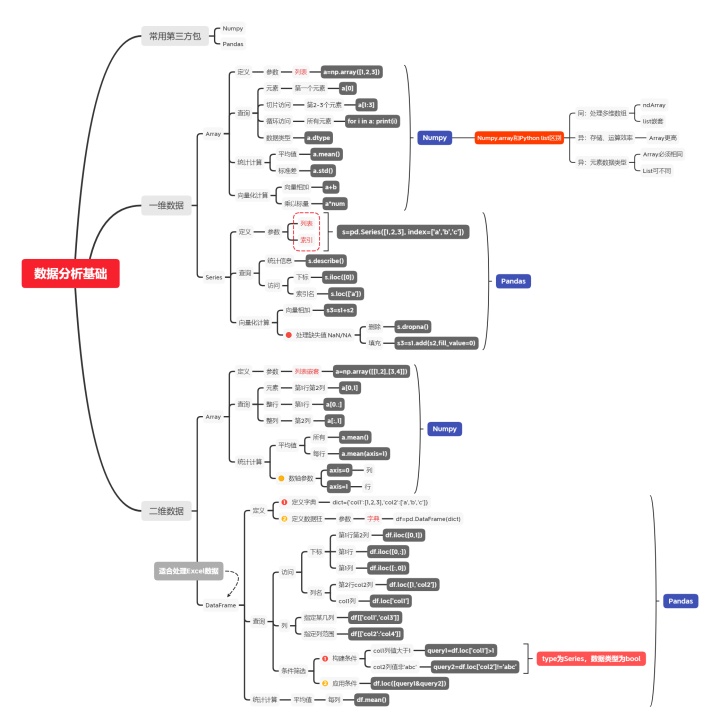
常見的數據集,要么是數列,要么是表格;
因此,數據分析最首要的是,處理一維、二維數據。
主要知識點可參考如圖。
如需要,可點擊以下百度網盤鏈接下載數據分析基礎知識圖PDF:
mindmap2_數據分析基礎.pdf
308.7K
· 百度網盤
數據分析常用第三方包
- Numpy
- Pandas
- Matplotlib
#導入numpy包
import numpy as np
#導入pandas包
import pandas as pd1. 一維數據
- Numpy(Numerical Python): Array
- Pandas: Series
1.1 Numpy-Array
#定義:一維數組array
#參數:一個列表[2,3,4,5]
a = np.array([2,3,4,5])#查詢
a[0]
2#切片訪問:獲取指定序號范圍的元素
#a[1:3]獲取到的是序號從1到3的元素
a[1:3]
array([3, 4])#切片訪問:反序
a[::-1]
array([5, 4, 3, 2])#循環訪問
for i in range(len(a)):print(a[i])
2
3
4
5#循環訪問
for i in a: # 獲取a數組里面的數據,從i=2開始print(a[i-2])
2
3
4
5#循環訪問
for i in a:print(i)
2
3
4
5#查看數據類型
a.dtype
dtype('int32')#統計計算:平均值
a.mean()
3.5#統計計算:標準差
a.std()
1.118033988749895#向量化計算:向量相加
b=np.array([1,2,3])
c=np.array([4,5,6])
b+c
array([5, 7, 9])#向量化計算:乘以標量
d=b*4
d
array([ 4, 8, 12])區別:Numpy數組&Python列表
- 1.處理多維數組
- ndArray
- list嵌套
- 2.存儲、運算效率
- Array > list
- 3.元素數據類型
- Array:必須相同
- List:可不同
1.2 Pandas-Series
#定義:一維數據結構:Series,index為索引
#存放6家公司某一天的股價(單位是美元)
stockS=pd.Series([54.74,190.9,173.14,1050.3,181.86,1139.49],index=['騰訊','阿里巴巴','蘋果','谷歌','Facebook','亞馬遜'])
stockS
#獲取描述統計信息
stockS.describe()
統計信息含義如下
- 數據條數count
- 平均值mean
- 標準差std
- 最小值min下四位數25%
- 中位數50%
- 上四位數75%
- 最大值max
#訪問:iloc屬性用于根據下標獲取值
stockS.iloc[0]
54.74#訪問:loc屬性用于根據索引獲取值
stockS.loc['騰訊']
54.74#向量化運算:向量相加
s1=pd.Series([1,2,3,4],index=['a','b','c','d'])
s2=pd.Series([10,20,30,40],index=['a','b','e','f'])
s3=s1+s2
s3
#處理空值的方法
#方法1:刪除
s3.dropna()
#方法2:填充
s3=s1.add(s2,fill_value=0)
s3
2.二維數據
- Numpy: Array
- Pandas: DataFrame
- DataFrame處理表格數據比較方便
2.1 Numpy-Array
#定義二維數組
a=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]
])#訪問:獲取元素
#行號0,列號2
a[0,2]
3#訪問:整行
#獲取第1行
a[0,:]
array([1, 2, 3, 4])#訪問:整列
#獲取第1列
a[:, 0]
array([1, 5, 9])#數軸參數 axis
#axis=0,down,縱向處理
#axis=1,across,橫向處理#所有平均值
print(a.mean())#每行平均值,即每一行取所有列的平均值
print(a.mean(axis=1))#刪除某一列,即列(集)沿著水平的方向依次刪掉
#a.drop(colNames,axis=1)6.5
[ 2.5 6.5 10.5]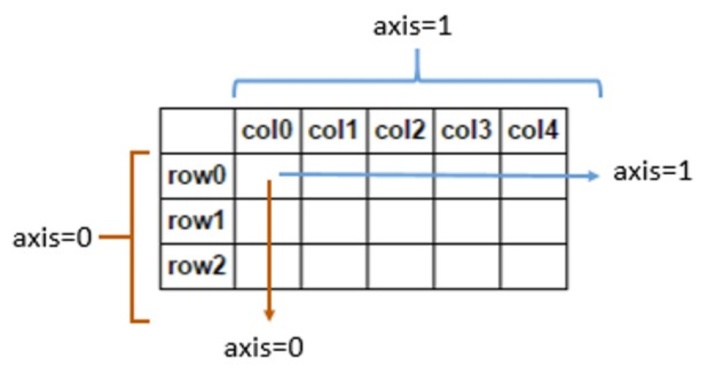
2.2 Pandas-DataFrame
#定義
#第1步:定義一個字典,映射列名與對應列的值
#現Python3的字典對象為有序
salesDict={'購藥時間':['2018-01-01 星期五','2018-01-02 星期六','2018-01-06 星期三'],'社保卡號':['001616528','001616528','0012602828'],'商品編碼':[236701,236701,236701],'商品名稱':['強力VC銀翹片','清熱解毒口服液','感康'],'銷售數量':[6,1,2],'應收金額':[82.8,28,16.8],'實收金額':[69,24.64,15]
}#第2步:定義數據框DataFrame
salesDf=pd.DataFrame(salesDict)
salesDf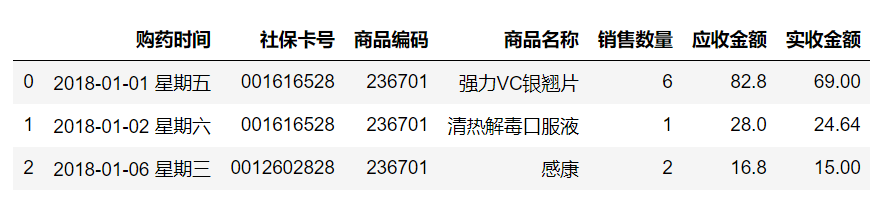
#平均值:是按每列來求平均值
salesDf.mean()
#訪問:iloc屬性用于根據下標獲取值
#查詢第1行第2列的元素
salesDf.iloc[0,1]
'001616528'#獲取第1行,:代表所有列
salesDf.iloc[0,:]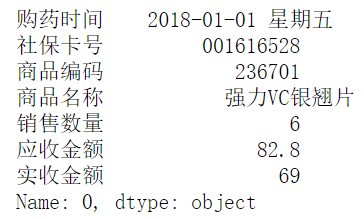
#獲取第1列,:代表所有行
salesDf.iloc[:,0]
#訪問:loc屬性用于根據索引名獲取值
#查詢第1行商品編碼列的元素
salesDf.loc[0,'商品編碼']
236701#獲取“商品名稱”這一列
#salesDf.loc[:,'商品名稱']
salesDf['商品名稱'] #簡單方法
3.查詢操作
3.1 查詢列
#指定列
#通過列表來選擇某幾列的數據
salesDf[['商品名稱','銷售數量']]
#指定連續的列
#通過切片功能,獲取指定范圍的列
salesDf.loc[:,'購藥時間':'銷售數量']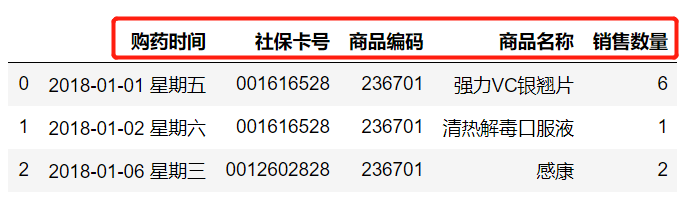
3.2 條件篩選
#第1步:構建查詢條件,對象是Series,數據元素是bool
querySer=salesDf.loc[:,'銷售數量']>1
type(querySer)
pandas.core.series.SeriesquerySer
#第2步:應用查詢條件
#只能指定列
#Error:salesDf.loc[:,querySer]
salesDf.loc[querySer]
salesDf.loc[querySer,'商品編碼':'銷售數量']
#多個條件刪選
querySer1=salesDf.loc[:,'商品名稱']!='感康'
salesDf.loc[querySer1&querySer]
上一章:
Queenie:數據分析1_入門Python?zhuanlan.zhihu.com






讀取內存地址并在C中打印其值)

 - How to use it in a guest)










