分布式理論基礎
1、分布式架構有哪些特點,優勢和缺陷
特點:
| 微服務架構的優點 | 微服務架構的缺陷 |
|---|---|
| 自由使用不同技術 | 增加故障排除挑戰 |
| 每一個微服務都側重于單一功能 | 由于遠程調用增加延遲 |
| 支持單個可部署單元 | 增加了配置與其他操作的工作量 |
| 允許經常發布軟件 | 難以保持交易安全 |
| 確保每項服務的安全性 | 難以跨越各種邊界追蹤數據 |
| 多個服務時并行開發和部署的 | 難以在微服務間進行編碼 |
2、分布式系統如何進行無狀態化改造
狀態概念:如果一個數據需要被多個服務共享,才能完成交易,那么這個數據被稱為狀態,反之則稱為無狀態。
阻礙單體架構變為分布式架構的關鍵點在于狀態的處理,對于任何狀態,需要考慮它的分發、處理、存儲。
對于數據的存儲,主要包含這幾類數據:
- 會話數據,主要保存在內存中
- 結構化數據,主要是業務邏輯相關
- 文件圖片數據,比較大,往往通過CDN下發
- 非結構化數據,例如文本,評論等
如果這些數據保存到本地,和業務邏輯耦合在一起,就需要在數據分發時,將同一個用戶的所有數據分到同一個進程,這樣就會影響架構的橫向擴展。
解決方案:
| 問題點 | 處理方案 |
|---|---|
| 會話數據 | 使用統一的外部緩存 如 spring session + redis |
| 結構化數據 | 分布式數據庫 + 讀寫分離 |
| 文件數據 | 分布式共享存儲 如 HDFS + CDN 預加載 |
| 非結構化數據 | 使用統一搜索引擎 如 ES |
3、CAP理論下的注冊中心選擇
常見的注冊中心:zookeeper、eureka、nacos、consul
| zookeeper | eureka | nacos | consul | |
|---|---|---|---|---|
| 一致性 | CP | AP | CP+AP | CP |
| 健康檢查 | Keep Alive | 心跳 | TCP/HTTP/MYSQL/Client Beat | TCP/HTTP/gRPC/Cmd |
| 雪崩保護 | 無 | 有 | 有 | 無 |
| 訪問協議 | TCP | HTTP | HTTP/DNS | HTTP/DNS |
| springcloud集成 | 支持 | 支持 | 支持 | 支持 |
Zookeeper:CP設計,保證一致性,在集群環境下,某個節點失效,則會選舉新的leader,或者半數以上節點不可用,則無法提供服務,因此無法滿足可用性
Eureka:AP設計,不區分主從節點,一個節點掛了,自動切換到其它可用節點,去中心化,保證可用性
結論:
如果要求一致性,則選擇zookeeper/Nacos,如金融行業 CP
如果要求可用性,則Eureka/Nacos,如電商系統 AP
微服務和分布式
分布式系統(Distributed Systems)
本質:通過網絡連接的多臺計算機協同工作,表現為單一系統的技術體系
核心目標:解決單機性能瓶頸,實現高可用、可擴展和容錯
微服務架構
本質:將單體應用拆分未多個獨立部署的小型服務,每個服務實現特定的業務功能
核心特征:
- 單一職責原則
- 獨立部署運行
- 輕量級通信
- 去中心化治理
兩者關系
- 微服務是分布式系統的實現范式:所有微服務架構都是分布式系統
- 分布式系統是更廣泛的概念:包含但不限于微服務(如集群計算、網格計算)
- 關鍵差異
| 維度 | 分布式系統 | 微服務 |
|---|---|---|
| 關注點 | 基礎設施與資源整合 | 業務解耦與敏捷交付 |
| 粒度 | 可變(進程/機器/數據中心) | 業務功能級細粒度 |
| 技術一致性 | 通常同質化 | 允許技術異構 |
| 數據管理 | 可能共享存儲 | 每個服務獨立數據庫 |
冪等性
冪等性是指同一操作的多次執行和單次執行產生相同的效果。
產生冪等性問題的原因主要有:
1.網絡請求重試:網絡波動或超時,客戶端可能會重復發送相同的請求。
2.用戶界面重復提交:用戶在用戶界面上可能會不小心重復點擊按鈕,導致相同的請求被發送多次。
3.消息隊列重試機制:使用消息隊列(如Kafka、RabbitMQ)時,消息可能會被重復消費。
4.數據庫并發操作:數據庫的插入、更新和刪除操作多個事務同時修改同一條記錄,而沒有使用適當的鎖機制或事務隔離級別。
5.外部系統API接口重試:對外提供的API接口可能由于調用方的重試邏輯,導致數據庫操作被重復調用。
冪等性核心實現方案
-
唯一標識(Token機制):
-
數據庫唯一約束
表結構設計唯一約束業務字段
-
樂觀鎖機制(版本號控制)
// 更新庫存示例 public boolean deductStock(Long productId, Integer quantity, Integer version) {String sql = "UPDATE product SET stock = stock - ?, version = version + 1 " +"WHERE id = ? AND version = ?";int rows = jdbcTemplate.update(sql, quantity, productId, version);return rows > 0; } -
分布式鎖
在分布式系統中,使用分布式鎖來保證同一時間只有一個實例處理特定消息或請求
-
狀態機
使用狀態機是判斷業務流程,確保操作只執行一次。
狀態機設計:
- 訂單創建:訂單初始化,狀態為
PENDING(待支付)。 - 支付操作:當訂單狀態為
PENDING時,允許執行支付操作,支付成功后狀態變為PAID(已支付)。 - 重復支付檢查:如果再次嘗試支付一個已經是
PAID狀態的訂單,狀態機將拒絕該操作,保持訂單狀態不變。
- 訂單創建:訂單初始化,狀態為
-
冪等性架構設計
關鍵組件:
- 網關層冪等攔截器:基于請求ID過濾重復請求
- 分布式冪等服務:集中管理冪等Token和狀態
- 業務層冪等處理器:封裝各種冪等策略
- 持久層冪等設計:數據庫唯一約束+樂觀鎖
常見問題解決方案
-
分庫分表下的全局唯一約束
- 使用分布式ID生成器(Snowflake/TinyID)
- 單獨創建全局索引表
- 通過Redis原子操作實現分布式鎖
-
冪等與并發沖突
// Redis Lua腳本保證原子性 String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then " +" return redis.call('del', KEYS[1]) " +"else " +" return 0 " +"end";Long result = redisTemplate.execute(new DefaultRedisScript<>(luaScript, Long.class),Collections.singletonList(key),token); -
長事務中的冪等
- 分段提交:將大事務拆分為多個冪等子任務
- 狀態快照:保存中間狀態支持斷點續執
- 補償事務:為每個操作設計冪等補償
分布式事務
1、本地事務
傳統的事務是通過關系型數據庫來控制事務,這是利用數據庫本身的使用特性來實現的,基于關系型數據庫的事務被稱為本地事務。
事務的的四大特性:ACID
| 事務特性 | 說明 |
|---|---|
| Atomic 原子性 | 構成事務的所有操作要么都執行,要么都不執行 |
| Consistency 一致性 | 事務執行前后,數據庫的整體狀態時不變的 |
| Isolation 隔離性 | 多個事務的執行互不干擾,一個事務不能看到其它事務未提交的中間狀態 |
| Duration 持久性 | 事務一旦提交,數據就會持久化到磁盤,不可回滾 |
2、分布式事務
在分布式系統環境下,一個事務操作會由多個不同網絡節點上的的服務參與,通過網絡遠程協作來完成一個大的事務,保證多個服務節點的數據一致性,這就是分布式事務。
3、數據一致性
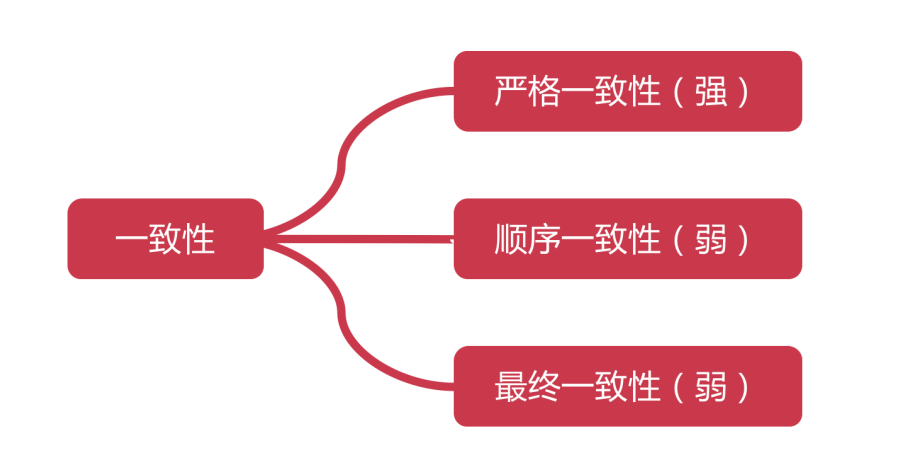
- 嚴格一致性:分布式系統中的某個數據一旦被更新成功后,后續無論從哪個服務節點訪問,都能讀取到最新的數據值。在數據庫集群中,其中某個節點的數據發生了變更,那么需要等待集群內所有節點進行數據同步,同步完成后,才能正常對外提供服務。
- 順序一致性:分布式系統節點變動的數據,與實際操作順序一致,它不像嚴格一致性那樣,要求每次更新都要同步,它只要求數據同步的順序一致即可。
- 最終一致性:分布式系統中所有節點的數據,最終會變得一致,不要求任意時刻任意節點上的數據都是相同的。
4、CAP定理
C 一致性(Consistency):更新操作成功并返回客戶端完成后,所有節點在同一時間的數據完全一致,不能存在中間狀態。
A 可用性(Availibility):系統提供的服務必須一直處于可用狀態,對于用戶的每一個操作請求總能在有限的時間內返回結果。
P 分區容錯性(Partition tolerance):即使分布式系統中的某個功能組件不可用,操作依然可以完成。
在分布式系統里面,一致性、可用性、分區容錯性這三個指標,不可能同時做到,最多只能滿足兩個,而分區容錯性時最基本的要求。在實際應用中,經常會在保證分區容錯性的情況下,然后犧牲部分一致性,不要求強一致性,也就是不一定要等到所有節點的數據狀態都是一樣時才能對外提供服務。可以在程序設計實現里面加一些控制處理,即使出現短暫的數據不一致,也不影響系統的正常使用,這樣就保證了三者基本可以同時滿足。
5、BASE定理
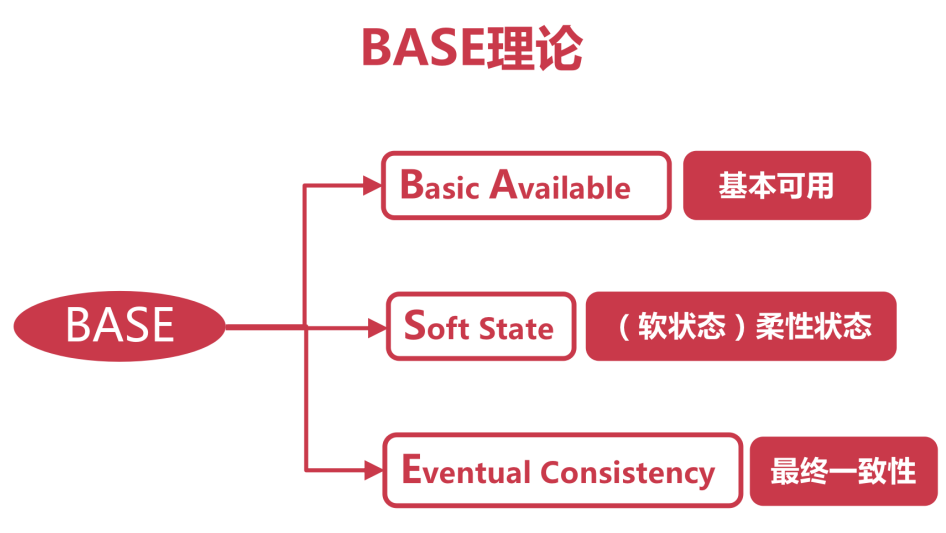
基本可用:允許系統的部分功能不可用或響應時間延長。
軟狀態:允許分布式系統中部分節點存在中間狀態數據,不影響系統的可用性,不要求數據的強一致性。
最終一致性:允許不同節點數據在業務允許的時間范圍內不同,但最終所有節點數據必須保持一致。
6、兩階段(2PC)和三階段(3PC)提交協議
兩階段提交
兩階段提交協議:準備階段(Prepare Phase)和提交階段(Commit Phase)。涉及一個協調者(Coordinator)和多個參與者(Participants)。
階段一:準備階段
- 協調者向所有參與者發送事務內容,詢問是否可以提交事務,然后等待所有參與者的響應。
- 參與者執行事務操作(但不提交),將Undo和Redo信息記錄到事務日志。
- 參與者向協調者返回實務操作的執行結果 Yes或No。
階段二:提交階段
協調者根據所有參與者的反饋決定是否提交事務:
情況1:所有參與者都返回 Yes
- 協調者向所有的參與者發送 Commit 指令
- 參與者收到指令后執行提交操作,并釋放資源
- 參與者向協調者發送Ack消息
- 協調者收到所有參與者的Ack后,完成事務
情況2:有任意一個參與者返回No或超時
- 協調者向所有參與者發送Rollback指令
- 參與者收到指令后通過Undo日志執行回滾操作,并釋放事務資源
- 參與者向協調者發送回滾完成消息
- 協調者收到所有參與者的Ack后,中斷事務
優缺點
優點:
- 原理簡單,實現方便
- 大多數情況下能保證事務的原子性
缺點:
- 同步阻塞問題:在準備階段后,所有的參與者都會阻塞等待協調者的執行,期間占用資源無法釋放。
- 單點故障問題:如果協調者故障,參與者將一直處于阻塞狀態,等待提交/回滾指令
- 數據不一致問題:在階段二,協調者只發送了部分Commit指令就故障,那么部分參與者提交事務,部分未收到指令未提交事務,導致數據不一致
- 保守機制:任意一個參與者失敗就會導致整個事務回滾,沒有容錯機制
三階段提交
三階段提交是對兩階段提交的改進,將兩階段的準備階段一分為二,形成三個階段:詢問階段(CanCommit)、預提交階段(PreCommit)和提交階段(DoCommit)。同時引入超時機制來解決2PC中的阻塞問題。
階段一:詢問階段
- 協調者向所有參與者發送一個包含事務內容的CanCommit請求,詢問是否可以執行事務,然后等待響應。
- 參與者根據自身情況(如是否可以鎖定資源)反饋Yes或No
階段二:預提交階段
協調者根據階段1的反饋決定是否繼續:
**情況1:**所有參與者反饋Yes
- 協調者向所有參與者發送PreCommit請求
- 參與者收到PreCommit后,執行事務操作(寫Undo/Redo日志),但不提交
- 參與者反饋Ack(表示已經準備好)
**情況2:**有參與者反饋No或超時
- 協調者向所有參與者發送中止請求
- 參與者(未收到PreCommit的參與者)中斷事務
階段三:提交階段
協調者根據階段2的反饋結果決定是否提交
**情況1:**協調者收到所有參與者的Ack
- 協調者向所有參與者發送DoCommit請求
- 參與者收到后執行提交,釋放資源,并反饋Ack
- 協調者收到所有Ack后完成事務
**情況2:**有參與者未返回Ack或協調者超時
- 協調者向所有參與者發送中止請求
- 參與者使用Undo日志回滾事務,釋放資源
改進點
- 引入超時機制解決阻塞問題
- 在詢問階段超時,參與者會中止事務
- 在預提交和提交階段,如果參與者超時,則會自動提交事務
- 將2階段的準備階段拆分為兩個階段,詢問階段只做檢查,不鎖定資源,減少資源鎖定時間
優缺點
優點:
- 降低了阻塞范圍:在等待超時后,參與者會自動提交或回滾,不會一直阻塞
- 解決了協調者單點故障問題:在提交階段,若協調者故障,參與者在超時后會自動提交
缺點:
- 在提交階段,如果因為網絡分區導致部分參與者未收到PreCommit請求,超時自動提交了,而部分參與者收到了終止請求,進行了回滾,會導致數據不一致(但概率比2PC低)
- 交互次數增多,實現更復雜
2PC VS 3PC
| 維度 | 2PC | 3PC | 優劣分析 |
|---|---|---|---|
| 階段數量 | 2階段 | 3階段 | 3PC增加網絡交互 |
| 阻塞時間 | 長(含資源鎖定) | 短(僅DoCommit鎖定) | 3PC減少30%阻塞時間 |
| 協調者故障 | 事務永久阻塞 | 超時后自動提交/回滾 | 3PC解決單點故障 |
| 數據一致性 | 強一致 | 最終一致 | 2PC更適合金融場景 |
| 網絡分區容忍 | 弱 | 較強 | 3PC更適合跨地域部署 |
| 實現復雜度 | ★★☆ | ★★★ | 2PC更易實現 |
| 適用場景 | 銀行轉賬 | 電商訂單 | 3PC更適合互聯網應用 |
最佳實踐
-
協議選擇原則:
- 金融系統:2PC + 協調者集群 + 重試機制
- 互聯網應用:3PC + 異步補償 + 冪等設計
-
性能優化關鍵:
// 批量處理優化 public void batchCommit(List<Transaction> transactions) {// 合并網絡請求batchPrepare(transactions);batchCommit(transactions); } -
故障處理四板斧:
- 超時中斷:設置合理超時閾值
- 狀態可查:實現事務狀態查詢接口
- 人工干預:提供管理臺操作入口
- 自動補償:基于日志的自動恢復
-
監控指標體系:
指標 預警閾值 監控手段 事務成功率 <99.9% Prometheus 平均延遲 >200ms Grafana 資源鎖定時間 >1s 日志分析 協調者切換次數 >5次/小時 Zabbix
Seata
Seata核心概念
| 角色 | 作用 |
|---|---|
| TC (Transaction Coordinator) | 事務協調器(獨立部署),負責全局事務的提交/回滾決策,維護全局事務狀態。 |
| TM (Transaction Manager) | 事務管理器(集成在業務服務中),負責開啟/提交/回滾全局事務。 |
| RM (Resource Manager) | 資源管理器(集成在業務服務中),負責管理分支事務(如本地數據庫操作)。 |
Seata 事務模式詳解
1. AT 模式(Auto Transaction) - 最常用
- 原理:基于數據庫快照 + 反向補償 SQL 實現自動補償。
- 工作流程:
- TM 向 TC 注冊全局事務(生成全局唯一
XID)。 - RM 執行業務 SQL 前,Seata 解析 SQL 生成前置快照(
before image)。 - 執行業務 SQL 并提交本地事務。
- 生成后置快照(
after image),將快照和行鎖信息存入undo_log表。 - 全局事務提交:TC 異步刪除所有
undo_log。 - 全局事務回滾:TC 通知 RM 根據
undo_log生成反向 SQL 補償(如update回滾為update還原)。
- TM 向 TC 注冊全局事務(生成全局唯一
- 優點:對業務零侵入(只需加
@GlobalTransactional注解),高性能。 - 缺點:依賴數據庫本地事務(僅支持支持本地 ACID 的數據庫如 MySQL/Oracle)。
2. TCC 模式(Try-Confirm-Cancel)
-
原理:通過人工編碼實現兩階段提交。
- Try:預留資源(如凍結庫存)。
- Confirm:提交資源(實際扣減庫存)。
- Cancel:回滾預留(釋放凍結庫存)。
-
代碼示例:
@TwoPhaseBusinessAction(name = "deductStock", commitMethod = "confirm", rollbackMethod = "cancel") public boolean tryDeductStock(BusinessActionContext context, int productId, int count) {// Try: 檢查并凍結庫存 } public boolean confirm(BusinessActionContext context) {// Confirm: 扣減凍結庫存 } public boolean cancel(BusinessActionContext context) {// Cancel: 解凍庫存 } -
優點:不依賴數據庫事務,支持異構系統。
-
缺點:業務侵入性強,需自行處理空回滾、冪等、懸掛問題。
3. Saga 模式
- 原理:長事務拆分多個子事務,每個子事務提供補償操作,失敗時反向執行補償。
- 適用場景:業務流程長、無需強一致性的場景(如訂單流程包含多個服務)。
- 缺點:需保證補償操作冪等性,可能出現臟寫。
4. XA 模式
- 原理:基于數據庫的 XA 協議實現強一致性(兩階段提交)。
- 優點:數據強一致。
- 缺點:性能低(鎖定資源時間長),需數據庫支持 XA 協議(如 MySQL 5.7+)。
Seata AT 模式核心機制
1. 全局鎖機制
- 防止其他事務修改正在被全局事務操作的數據。
- RM 執行 SQL 前,向 TC 申請行級全局鎖(
table_name + pk)。 - 鎖沖突時,后發起的事務會重試或回滾。
2. undo_log 表設計
CREATE TABLE `undo_log` (`id` BIGINT(20) NOT NULL AUTO_INCREMENT,`branch_id` BIGINT(20) NOT NULL, -- 分支事務ID`xid` VARCHAR(100) NOT NULL, -- 全局事務ID`context` VARCHAR(128) NOT NULL, -- 上下文(如序列化格式)`rollback_info` LONGBLOB NOT NULL, -- 回滾信息(快照)`log_status` INT(11) NOT NULL, -- 狀態(0-正常,1-已回滾)PRIMARY KEY (`id`)
);
3. 事務執行流程
部署與配置
1. TC Server 部署
-
步驟:
# 下載 Seata Server wget https://seata.io/.../seata-server-1.7.0.tar.gz # 修改配置文件 conf/registry.conf(注冊中心) store.mode = "db" # 選擇TC事務狀態存儲方式(db/file/redis) # 啟動 sh bin/seata-server.sh -p 8091
2. 業務服務集成
-
依賴:
<!-- Spring Cloud Alibaba --> <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency> -
配置:
seata:application-id: order-servicetx-service-group: my-tx-group # 事務組名(需與TC配置一致)registry:type: nacos # 注冊中心類型nacos:server-addr: 127.0.0.1:8848config:type: nacos
3. 全局事務注解
@RestController
public class OrderController {@GlobalTransactional // 開啟全局事務public String createOrder() {orderService.create(); // 分支事務1storageService.deduct(); // 分支事務2// 若此處異常,所有分支事務回滾}
}
生產環境關鍵實踐
1. 高可用部署 TC
- 方案:TC 集群化 + 數據庫持久化(
store.mode=db) + 注冊中心(Nacos/Zookeeper)。 - 負載均衡:客戶端通過注冊中心發現多個 TC 實例。
2. 性能優化
- 異步化:全局事務提交時異步刪除
undo_log。 - 合并請求:TC 合并 RM 的心beat和事務消息,減少網絡開銷。
- 線程池調優:調整 TC 的
server.executor線程池大小。
3. 故障處理
- 全局鎖沖突:優化業務邏輯,減少長事務。
- undo_log 堆積:監控清理失敗日志(
log_status=1)。 - TC 宕機恢復:依賴數據庫恢復事務狀態。
4. 監控與告警
- Metrics:集成 Prometheus 收集事務成功率、耗時等指標。
- 日志追蹤:通過 XID 跨服務追蹤事務鏈路。
適用場景對比
| 模式 | 一致性 | 性能 | 業務侵入 | 適用場景 |
|---|---|---|---|---|
| AT | 最終一致 | ???? | 無 | 標準CRUD操作(80%場景) |
| TCC | 強一致 | ??? | 高 | 資金交易、需高一致的業務 |
| Saga | 最終一致 | ???? | 中 | 長流程業務(如訂單+物流+支付) |
| XA | 強一致 | ?? | 低 | 傳統銀行系統、遺留數據庫 |
常見問題解決方案
- 空回滾(TCC模式)
原因:Try未執行,Cancel被調用。
解決:在 Cancel 中檢查 Try 是否執行(通過事務狀態表)。 - 冪等控制
方案:在try/confirm/cancel方法中通過xid + branch_id去重。 - AT模式臟寫
場景:全局事務未提交時,其他本地事務修改了相同數據。
防御:開啟全局鎖(默認開啟),沖突事務會回滾。 - undo_log表清理
腳本:定時刪除已提交事務的日志(DELETE FROM undo_log WHERE log_status = 0)。
總結
- 選型建議:優先使用 AT 模式(簡單高效),復雜業務用 TCC,歷史系統兼容選 XA。
- 核心價值:Seata 通過 TC 統一協調 + 多模式適配,顯著降低分布式事務開發復雜度。
- 注意:分布式事務無法100%保證一致性(如極端宕機),需配合人工對賬兜底。
部署建議:
TC集群 + 數據庫存儲 + Nacos注冊中心 + Prometheus監控
通過@GlobalTransactional注解,5分鐘快速接入分布式事務!
ZooKeeper
Zookeeper 是一個開源的分布式協調服務,由Appache基金維護,核心解決分布式系統中的一致性、狀態同步、配置管理、集群管理等問題。讀請求可以被集群中的任意一臺機器處理,寫請求會同時發給所有的zookeeper機器并且達成一致后,請求才會響應成功。隨著zookeeper集群機器增多,讀請求吞吐量會提高但寫請求的吞吐量會下降。
1、核心定位與特性
| 特性 | 說明 |
|---|---|
| 分布式一致性 | 基于ZAB協議保證集群節點數據強一致性 |
| 樹形數據結構 | 數據模型為層級命名空間(類似文件系統),節點稱為ZNode |
| 監聽機制 | 客戶端可監聽ZNode變化(創建/刪除/數據更新) |
| 順序性保證 | 所有寫操作全局有序(通過事務IDzxid實現) |
| 高可用 | 集群部署(通常3/5/7節點),Leader 故障時自動選舉新Leader |
2、數據模型:ZNode
-
節點類型:
- 持久節點(PERSITENT):客戶端斷開后仍存在(如配置信息)
- 臨時節點(EPHEMERAL):客戶端會話結束自動刪除(適合服務注冊)
- 順序節點(SEQUENTIAL):節點名自動追加全局單調遞增序號(如
/lock-00000001)
-
節點數據結構
class ZNode {String path; // 節點路徑(如 、service/provider)byte[] data; // 存儲的數據(最大1MB)Stat stat; // 元數據(版本號,時間戳等)List<String> children; // 子節點列表 }Zookeeper 為了保證高吞吐和低延遲,在內存中維護了整個樹狀的目錄結構,所以Zookeeper不能存放大量的數據,每個節點存儲數據上線 1MB。
3、集群架構與ZAB協議
-
集群角色
角色 職責 Leader 處理所有寫請求,發起事務提案(Proposal) Follower 同步Leader數據,參與寫操作的ACK投票,處理讀請求 Observer 僅同步數據、處理請求(不參與投票),用于擴展讀性能 -
ZAB 協議工作流程
基于ZAB協議保證集群節點數據強一致性
-
兩階段提交:
- 廣播 Proposal:Leader 生成帶
zxid的提案發送給 Followers - ACK 投票:Followers 持久化提案并返回 ACK
- 提交事務:Leader 收到多數 ACK 后發送 COMMIT
- 廣播 Proposal:Leader 生成帶
-
崩潰恢復:
- Leader 宕機后,新 Leader 選舉基于 最大 zxid 優先 原則
- 新 Leader 用內存快照 + 事務日志恢復數據
-
-
Zookeeper 數據復制
Zookeeper 作為一個集群提供一致的數據服務,自然,它要在 所有機器間 做數據復制。
數據復制的好處:
1、容錯:一個節點出錯,不致于讓整個系統停止工作,別的節點可以接管它的工作;
2、提高系統的擴展能力 :把負載分布到多個節點上,或者增加節點來提高系統的負載能力;
3、提高性能:讓 客戶端本地訪問就近的節點,提高用戶訪問速度 。數據復制集群系統分下面兩種:
1、 寫主 (WriteMaster) :對數據的 修改提交給指定的節點 。讀無此限制,可以讀取任何一個節點。這種情況下
客戶端需要對讀與寫進行區別,俗稱 讀寫分離 ;
2、 寫任意 (Write Any):對數據的 修改可提交給任意的節點 ,跟讀一樣。對 zookeeper 來說,它采用的方式是 寫任意 。通過增加機器,它的讀吞吐能力和響應能力擴展性非常好,而寫請求隨著機器的增多吞吐能力肯定下降(這也是它建立 observer 的原因),而響應能力則取決于具體實現方式,是 延遲復制保持最終一致性 ,還是 立即復制快速響應 。
4、核心應用場景
分布式鎖
利用zookeeper的一致性文件系統,可以創建一個保持獨占且控制時序的鎖。
每個客戶端都去同一目錄下創建臨時順序節點znode,編號最小的獲得鎖,用完刪除。
// 偽代碼:基于臨時順序節點
public void lock() {// 1. 創建臨時順序節點:/lock/lock-00001String lockPath = zk.create("/lock/lock-", EPHEMERAL_SEQUENTIAL);// 2. 獲取所有子節點并排序List<String> children = zk.getChildren("/lock");Collection.sort(children);// 3. 若當前節點是最小節點,獲得鎖if (lockPath.endsWith(children.get(0))) {return;}// 4. 否則監聽前一個節點String prevNode = children.get(Collections.binarySearch(children, lockPath) - 1);zk.exists("/lock/" + prevNode, watcher -> {if (watcher.event == NodeDeleted) lock(); // 前節點釋放,重新嘗試});
}
服務注冊與發現
- 服務注冊:服務啟動時在
/services/serviceA下創建臨時節點(如ip:192.168.1.10:8080) - 服務發現:客戶端監聽
/services/serviceA的子節點變化,實時獲取可用服務列表 - 健康檢測:會話超時后臨時節點自動刪除(相當于服務下線)
配置中心
將應用程序的配置信息放到zookeeper的 下,當有配置發生改變時,也就是znode發生變化時,可以通過改變zk中某個目錄節點的內容(已被客戶端監聽),利用 watcher 通知給各個客戶端,從而更改配置
// 全局配置存儲于 /config/app
String config = zk.getData("/config/app", true, null); // 監聽配置變更
zk.addWatch("/config/app", (event) -> {if (event.type == NodeDataChanged) {reloadConfig(); // 熱更新配置}
});
集群選舉
- 所有候選節點嘗試創建
/election/leader(臨時節點) - 創建成功者成為 Leader,失敗者監聽該節點
- Leader 宕機時節點刪除,其他節點重新選舉
Zookeeper 同步流程
? 選完 Leader 以后,zk 就進入狀態同步過程。
? 1、Leader 等待 server 連接;
? 2、Follower 連接 leader,將最大的 zxid 發送給 leader;
? 3、Leader 根據 follower 的 zxid 確定同步點;
? 4、完成同步后通知 follower 已經成為 uptodate 狀態;
? 5、Follower 收到 uptodate 消息后,又可以重新接受 client 的請求進行服務了。
5、集群部署與配置
所有機器約定在父目錄下創建臨時目錄節點,然后監聽這個父目錄節點的子節點變化消息,有新的機器加入或斷開,其對應的臨時目錄節點也會新增和刪除,所有的機器都會收到通知。另外所有機器創建臨時順序編號目錄節點,可以方便選取編號最小的機器作為master。
集群搭建(3節點示例)
配置文件zoo.cfg:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=10 # Follower初始連接Leader的超時(tick倍數)
syncLimit=5 # Follower與Leader同步數據的超時
server.1=node1:2888:3888 # 2888: Leader通信端口, 3888: 選舉端口
server.2=node2:2888:3888
server.3=node3:2888:3888
節點標識文件(在 dataDir 下創建 myid):
# node1 機器執行
echo "1" > /var/lib/zookeeper/myid
關鍵命令
| 命令 | 作用 |
|---|---|
zkServer.sh start | 啟動 ZooKeeper 服務 |
zkCli.sh -server ip:port | 連接集群 |
create /path data | 創建節點 |
get -w /path | 獲取數據并監聽 |
ls /path | 列出子節點 |
stat /path | 查看節點狀態 |
6、生產環境最佳實踐
1. 性能優化
-
分離事務日志與快照:將
dataLogDir指向 SSD 磁盤 -
增加 Observer 節點:擴展讀能力(如跨機房部署)
-
JVM 調優:設置堆大小(建議 4-8GB),啟用 G1 垃圾回收器
export JVMFLAGS="-Xmx8G -Xms8G -XX:+UseG1GC"
2. 高可用設計
-
集群規模:至少 3 節點(容忍 1 節點故障),5 節點(容忍 2 節點故障)
-
避免磁盤寫滿:監控磁盤空間,設置自動清理策略
autopurge.snapRetainCount=3 # 保留3個快照 autopurge.purgeInterval=24 # 每24小時清理
3. 安全加固
-
SASL 認證:啟用 Kerberos 或用戶名/密碼認證
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider requireClientAuthScheme=sasl -
網絡隔離:用防火墻限制訪問 IP
-
加密通信:啟用 SSL/TLS
7、常見問題解決方案
| 問題 | 解決方案 |
|---|---|
| 腦裂(Split-Brain) | 集群節點數必須為奇數(2n+1),確保投票多數決 |
| ZNode 數據過大 | 嚴格限制數據大小(≤1MB),大配置拆分存儲 |
| Watch 丟失 | 會話超時或網絡抖動導致 Watch 失效,需代碼重注冊監聽 |
| 連接耗盡 | 調整 maxClientCnxns 參數,使用連接池 |
| 寫性能瓶頸 | 寫請求必須由 Leader 處理,可通過分片(如 Curator 的 DistributedQueue)緩解 |
8、與同類技術對比
| 工具 | 一致性模型 | 數據模型 | 適用場景 |
|---|---|---|---|
| ZooKeeper | 強一致性(CP) | 樹形 ZNode | 協調服務(鎖、選舉、配置) |
| etcd | 強一致性(CP) | 鍵值對+版本號 | K8s 元數據存儲、服務發現 |
| Consul | 可調一致性(AP/CP) | 鍵值對+服務目錄 | 多數據中心服務網格 |
| Redis | 最終一致性(AP) | 多種數據結構 | 緩存、消息隊列、分布式鎖(Redlock) |
9、總結
- 核心價值:提供分布式系統的基礎協調能力(像分布式系統的神經系統)。
- 選型建議:
- ? 需要強一致性的協調場景(如金融核心系統)。
- ? 中小規模集群(≤1000節點)的選舉/配置管理。
- ? 超大規模數據存儲(改用 etcd 或專用存儲)。
- 學習建議:掌握 ZNode 操作、Watch 機制 和 ZAB 協議原理 是三大核心。
部署口訣:
奇數節點保選舉,分離日志提性能,監控會話防超時,數據小微忌貪心。
通過zkCli.sh實操練習,結合 Curator 框架可快速構建分布式應用!
10、面試題
ZooKeeper是什么
ZooKeeper 是一個開放源碼的分布式協調服務,它是集群的管理者,監視著集群中各
個節點的狀態根據節點提交的反饋進行下一步合理操作。最終,將簡單易用的接口和
性能高效、功能穩定的系統提供給用戶。
分布式應用程序可以基于 Zookeeper 實現諸如數據發布/訂閱、負載均衡、命名服務、
分布式協調/通知、集群管理、Master 選舉、分布式鎖和分布式隊列等功能。
Zookeeper 保證了如下分布式一致性特性:
● 順序一致性
● 原子性
● 單一視圖
● 可靠性
● 實時性(最終一致性)
客戶端的讀請求可以被集群中的任意一臺機器處理,如果讀請求在節點上注冊了監聽
器,這個監聽器也是由所連接的 zookeeper 機器來處理。對于寫請求,這些請求會同
時發給其他 zookeeper 機器并且達成一致后,請求才會返回成功。因此,隨著
zookeeper 的集群機器增多,讀請求的吞吐會提高但是寫請求的吞吐會下降。
有序性是 zookeeper 中非常重要的一個特性,所有的更新都是全局有序的,每個更新
都有一個唯一的時間戳,這個時間戳稱為 zxid(Zookeeper Transaction Id)。而讀請
求只會相對于更新有序,也就是讀請求的返回結果中會帶有這個 zookeeper 最新的
zxid。
Zookeeper Watcher機制–數據變更通知
Zookeeper 允許客戶端向服務端的某個 Znode 注冊一個 Watcher 監聽,當服務端的一些指定事件觸發了這個 Watcher,服務端會向指定客戶端發送一個事件通知來實現分布式的通知功能,然后客戶端根據 Watcher 通知狀態和事件類型做出業務上的改變。
工作機制:
● 客戶端注冊 watcher
● 服務端處理 watcher
● 客戶端回調 watcher
Watcher特性總結:
(1)一次性
無論是服務端還是客戶端,一旦一個 Watcher 被觸發,Zookeeper 都會將其從相應的
存儲中移除。這樣的設計有效的減輕了服務端的壓力,不然對于更新非常頻繁的節
點,服務端會不斷的向客戶端發送事件通知,無論對于網絡還是服務端的壓力都非常
大。
(2)客戶端串行執行
客戶端 Watcher 回調的過程是一個串行同步的過程。
(3)輕量
Watcher 通知非常簡單,只會告訴客戶端發生了事件,而不會說明事件的具體內容。
客戶端向服務端注冊 Watcher 的時候,并不會把客戶端真實的 Watcher 對象實體傳
遞到服務端,僅僅是在客戶端請求中使用 boolean 類型屬性進行了標記。
watcher event 異步發送 watcher 的通知事件從 server 發送到 client 是異步的,這就
存在一個問題,不同的客戶端和服務器之間通過 socket 進行通信,由于網絡延遲或其
他因素導致客戶端在不通的時刻監聽到事件,由于 Zookeeper 本身提供了 ordering
guarantee,即客戶端監聽事件后,才會感知它所監視 znode 發生了變化。所以我們
使用 Zookeeper 不能期望能夠監控到節點每次的變化。Zookeeper 只能保證最終的一
致性,而無法保證強一致性。
注冊 watcher getData、exists、getChildren
觸發 watcher create、delete、setData
當一個客戶端連接到一個新的服務器上時,watch 將會被以任意會話事件觸發。當與
一個服務器失去連接的時候,是無法接收到 watch 的。而當 client 重新連接時,如果
需要的話,所有先前注冊過的 watch,都會被重新注冊。通常這是完全透明的。只有
在一個特殊情況下,watch 可能會丟失:對于一個未創建的 znode 的 exist watch,如
果在客戶端斷開連接期間被創建了,并且隨后在客戶端連接上之前又刪除了,這種情
況下,這個 watch 事件可能會被丟失。
ZooKeeper分布式鎖的實現原理
使用 zookeeper 創建臨時序列節點來實現分布式鎖,適用于順序執行的程序,大體思
路就是創建臨時序列節點,找出最小的序列節點,獲取分布式鎖,程序執行完成之后
此序列節點消失,通過 watch 來監控節點的變化,從剩下的節點的找到最小的序列節
點,獲取分布式鎖,執行相應處理。
Eureka
一、Eureka核心概念
- 服務注冊中心(Eureka Server)
- 管理所有服務的注冊信息,提供狀態監控頁面
- 高可用時支持多節點集群(相互注冊)
- 服務提供者/消費者(Eureka Client)
- 提供者:向Eureka注冊自身服務
- 消費者:從Eureka獲取服務列表并調用其他服務
- 自我保護機制
- 當網絡故障導致大量服務心跳丟失時,Eureka保留所有注冊信息避免誤刪,生產環境建議開啟,開發環境可關閉
二、搭建Eureka Server
步驟 1:創建項目并添加依賴
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
步驟 2:配置文件 application.yml
server:port: 8761 # 默認端口
eureka:client:register-with-eureka: false # 不注冊自己fetch-registry: false # 不拉取注冊表server:enable-self-preservation: false # 開發環境關閉自我保護
步驟 3:啟動類添加注解
@SpringBootApplication
@EnableEurekaServer // 啟用 Eureka 服務端
public class EurekaServerApplication {public static void main(String[] args) {SpringApplication.run(EurekaServerApplication.class, args);}
}
- 訪問控制臺:
http://localhost:8761。
三、注冊 Eureka Client(服務提供者)
步驟 1:添加客戶端依賴
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
步驟 2:配置文件 application.yml
spring:application:name: user-service # 服務名稱(需唯一)
eureka:client:service-url:defaultZone: http://localhost:8761/eureka # 注冊到 Eureka Serverinstance:instance-id: user-service-8001 # 控制臺顯示的名稱:cite[1]:cite[7]
步驟 3:啟動類添加注解
@SpringBootApplication
@EnableEurekaClient // 啟用客戶端注冊
public class UserServiceApplication {public static void main(String[] args) {SpringApplication.run(UserServiceApplication.class, args);}
}
四、服務發現與調用
方法 1:使用 RestTemplate(負載均衡)
@Bean
@LoadBalanced // 啟用負載均衡
public RestTemplate restTemplate() {return new RestTemplate();
}// 調用服務
String url = "http://user-service/user/1"; // 通過服務名調用
String result = restTemplate.getForObject(url, String.class);
方法 2:使用 FeignClient(聲明式調用)
@FeignClient(name = "user-service")
public interface UserClient {@GetMapping("/user/{id}")String getUser(@PathVariable("id") Long id);
}
- 需添加依賴:
spring-cloud-starter-openfeign。
五、高可用集群配置
1. 配置多節點 Eureka Server
-
節點 1(端口 8761):
eureka:instance:hostname: eureka1client:service-url:defaultZone: http://eureka2:8762/eureka # 注冊到其他節點 -
節點 2(端口 8762):
eureka:instance:hostname: eureka2client:service-url:defaultZone: http://eureka1:8761/eureka
2. 客戶端注冊到集群
eureka:client:service-url:defaultZone: http://eureka1:8761/eureka,http://eureka2:8762/eureka
? 關鍵點:所有節點需相互注冊,客戶端需配置全部節點地址
六、常見問題與優化
1. 服務無法注冊
- 檢查點:
- 客戶端配置的
defaultZone是否拼寫正確(必須包含/eureka)。 - 確保 Eureka Server 已啟動且網絡連通58。
- 客戶端配置的
2. 狀態顯示異常
-
添加
actuator依賴解決/info報錯:<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId> </dependency> -
配置服務信息:
info:app.name: my-servicecompany: example.com :cite[1]
3. 調優參數
eureka:instance:lease-renewal-interval-in-seconds: 30 # 心跳間隔(默認30秒)lease-expiration-duration-in-seconds: 90 # 服務失效時間(默認90秒)client:registry-fetch-interval-seconds: 5 # 客戶端刷新注冊表間隔:cite[5]:cite[7]
總結與建議
| 場景 | 配置要點 |
|---|---|
| 單機開發 | 關閉自我保護,快速剔除失效服務 |
| 生產集群 | 開啟自我保護,配置多節點互注冊 |
| 高頻調用優化 | 縮短 registry-fetch-interval-seconds |
| 替代方案 | 考慮 Nacos 或 Consul(Eureka 已維護模式) |
Apollo
一、Apollo 核心概念與架構
-
核心角色
組件 作用 Config Serviece 提供配置的讀取、推送服務(客戶端直連) Admin Serviece 管理配置的修改、發布(Portal調用) Portal 配置管理界面(用戶操作入口) Client 集成到業務應用,實時同步配置(支持Java/.Net) -
核心功能
- 多環境管理:支持DEV/TEST/PROD 等環境獨立配置
- 實時推送:配置修改后1秒內推送到客戶端
- 灰度發布:新配置可先對部分實例生效
- 權限控制:配置編輯、發布分離,支持操作審計
- 版本回滾:意見回滾到歷史版本
二、部署模式詳解
1. 快速啟動模式(開發環境)
步驟:
-
環境準備:JDK 1.8+、MySQL 5.6.5+ 3
-
下載安裝包:
wget https://github.com/nobodyiam/apollo-build-scripts/archive/master.zip -
初始化數據庫:執行
sql/目錄下的腳本創建ApolloConfigDB和ApolloPortalDB3 -
修改連接配置:編輯
demo.sh文件:apollo_config_db_url="jdbc:mysql://localhost:3306/ApolloConfigDB?characterEncoding=utf8" apollo_portal_db_url="jdbc:mysql://localhost:3306/ApolloPortalDB?characterEncoding=utf8" ```:cite[3] -
啟動服務:
./demo.sh start # 啟動后訪問 http://localhost:8070 (賬號: apollo/admin)
2. 生產環境分布式部署
| 組件 | 部署要求 | 端口 |
|---|---|---|
| Config Service | 多節點 + SLB 負載均衡 | 8080 |
| Admin Service | 與 Config Service 同機部署 | 8090 |
| Portal | 獨立部署,連接統一 PortalDB | 8070 |
| 關鍵配置: |
- Meta Server 地址指向 SLB(如:
-Dapollo.meta=http://slb-ip:8080) - 數據庫高可用:MySQL 主從 + 讀寫分離
三、Portal 核心功能操作指南
1. 應用與命名空間管理
- 創建應用:
Portal → “創建應用” → 填寫AppId(如order-service)、部門 1 - 命名空間(Namespace):
- 私有:僅當前應用可用(如
application) - 公共:跨應用共享(如
redis-config)
- 私有:僅當前應用可用(如
- 配置發布流程:
編輯配置 → 保存 → 提交發布 → 審核(可選)→ 生效
2. 集群與灰度發布
- 集群配置:
為同一應用分配不同集群(如SH-AZ、SZ-AZ),實現地域差異化配置 - 灰度發布:
- 發布時選擇“灰度發布”
- 指定部分 IP 或機器名生效
- 驗證后全量推送
3. 權限與用戶管理
-
自定義部門:
修改organizations參數(格式為 JSON 數組):json
[{"orgId":"dev","orgName":"研發部"}, {"orgId":"ops","orgName":"運維部"}] ?```:cite[1] -
用戶權限:
- 超級管理員:
apollo - 應用管理員:可管理指定應用的配置(通過“系統權限”分配)
- 超級管理員:
四、客戶端集成(SpringBoot 示例)
依賴與配置
<dependency> <groupId>com.ctrip.framework.apollo</groupId> <artifactId>apollo-client</artifactId> <version>1.10.0</version>
</dependency>
配置文件 bootstrap.yml:
apollo: bootstrap: enabled: true namespaces: application,redis-config # 需加載的命名空間 meta: http://localhost:8080 # Meta Server 地址
app: id: order-service # 必須與 Portal 中 AppId 一致
```:cite[5] #### 2. **動態配置讀取**
- **注解方式**(實時刷新): ```java @Value("${redis.host}") private String redisHost;
五、高級特性與最佳實踐
1. 安全加固
- 配置加密:
使用@EnableEncryptableProperties+jasypt集成敏感信息加密 - 網絡隔離:
Portal 部署在內網,通過 VPN 訪問;Client 與 Config Service 間使用 HTTPS
2. 災備與監控
- 配置備份:定期導出配置到 Git(通過開放平臺 API)
- 客戶端監控:
訪問http://config-service-ip:8080/configs/{AppId}/{ClusterName}/{Namespace}查看配置加載狀態
3. 常見問題解決
| 問題 | 解決方案 |
|---|---|
| 客戶端無法連接 Meta Server | 檢查 -Dapollo.meta 參數是否生效 |
| @Value 不刷新 | 確保配置在 bootstrap.yml 且啟用 @RefreshScope |
| 公共 Namespace 不生效 | 在 bootstrap.yml 中顯式聲明 namespaces |
六、與同類產品對比
| 特性 | Apollo | Nacos | Spring Cloud Config |
|---|---|---|---|
| 配置實時推送 | ? 秒級 | ? 秒級 | ? 依賴客戶端輪詢 |
| 權限管理 | ? 完善 | ? 完善 | ? 需自行集成 |
| 多語言支持 | ? Java/.Net | ? 多語言 | ? 主要支持 Java |
| 部署復雜度 | ??? (需MySQL) | ?? (內嵌數據庫) | ? (Git 直連) |
Nacos
一、Nacos核心概念
| 組件 | 作用 |
|---|---|
| Naming Service | 服務注冊與發現(管理微服務實例狀態) |
| Config Service | 動態配置管理(實時推送配置變更) |
| MCP Router | 路由AI服務(3.0新增,支持動態篩選和協議轉換) |
| Console | 可視化控制臺(管理服務、配置、命名空間) |
特性優勢:
- 服務發現:支持臨時/持久實例,心跳檢測(默認5秒心跳,15秒標記異常,30秒剔除)
- 配置管理:基于Data ID + Group + Namespace 三要素隔離環境
- 高可用:集群模式依賴Raft(CP配置一致性) + Distro(AP服務發現最終一致性協議)協議
二、安裝與部署
單機模式(開發測試)
wget https://github.com/alibaba/nacos/releases/download/2.3.2/nacos-server-2.3.2.zip
unzip nacos-server-2.3.2.zip
cd nacos/bin
./startup.sh -m standalone # Linux/Mac
startup.cmd -m standalone # Windows
控制臺訪問:http://localhost:8848/nacos(默認賬號 nacos/nacos)
集群模式(生產環境)
-
修改
conf/cluster.conf,添加節點IP:192.168.0.1:8848 192.168.0.2:8848 192.168.0.3:8848 -
切換數據庫為MySQL(避免數據丟失):
spring.datasource.platform=mysql db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?useUnicode=true ```:cite[1]:cite[10] -
啟動所有節點:sh startup.sh
安全加固:生產環境需在
conf/application.properties中啟用鑒權:nacos.core.auth.enabled=true
三、服務注冊與發現
服務注冊(Spring Boot 示例)
步驟:
-
添加依賴:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> -
配置
bootstrap.yml:spring:application:name: user-servicecloud:nacos:discovery:server-addr: 127.0.0.1:8848cluster-name: SH-AZ # 集群名稱(可選) ```:cite[1]:cite[4] -
啟動類添加注解(可選,Spring Cloud 2020+ 可省略):
@SpringBootApplication @EnableDiscoveryClient public class UserApplication { ... }
2. 服務發現與調用
-
方式 1:RestTemplate + 負載均衡
@Bean @LoadBalanced public RestTemplate restTemplate() {return new RestTemplate(); } // 調用示例 String url = "http://user-service/getUser"; String result = restTemplate.getForObject(url, String.class); ```:cite[1]:cite[9] -
方式 2:權重控制
在 Nacos 控制臺調整實例權重(范圍 0~1),流量按權重分配:- 權重 0.3:接收 30% 流量
- 權重 0:停止接收流量
四、配置中心集成
1. 動態配置管理
配置示例(bootstrap.yml):
spring:config:import: nacos:user-service.yaml # 導入遠程配置cloud:nacos:config:server-addr: 127.0.0.1:8848file-extension: yamlnamespace: dev # 環境隔離(如 dev/test/prod)group: ORDER_GROUP # 業務分組
```:cite[1]:cite[8] #### 2. **配置動態刷新**
- **注解方式**: ```java@RefreshScope@RestControllerpublic class ConfigController {@Value("${app.max.retry:3}") // 默認值 3private int maxRetry;}
-
配置類綁定:
@Component @ConfigurationProperties(prefix = "app") @Data public class AppConfig {private int maxRetry;private String env; } ```:cite[1]
3. 配置隔離三要素
| 維度 | 作用 | 示例 |
|---|---|---|
| Namespace | 環境隔離(dev/test) | namespace: dev |
| Data ID | 配置文件標識 | user-service.yaml |
| Group | 業務分組 | group: ORDER_GROUP |
五、高級特性與生產實踐
1. MCP Router(Nacos 3.0)
- 功能:動態路由 AI 服務,支持協議轉換(如 stdio → streamable)
- 應用場景:
- 篩選與 LLM 關鍵字相關的服務
- 代理模式統一服務接口
2. 性能調優
-
通信模型:gRPC 長連接(替代 HTTP 短連接),吞吐量提升 10 倍
-
JVM 參數:
# bin/startup.sh 中調整 JAVA_OPT="${JAVA_OPT} -Xms4g -Xmx4g -Xmn2g"
3. 安全與監控
| 措施 | 操作 |
|---|---|
| 開啟鑒權 | nacos.core.auth.enabled=true |
| Prometheus 監控 | 訪問 http://nacos-ip:8848/nacos/actuator/prometheus 獲取指標 |
| 定期清理無效實例 | 控制臺手動下線或 API 自動巡檢 |
六、對比其他中間件
| 特性 | Nacos | Eureka | Consul |
|---|---|---|---|
| 服務發現 | ? 臨時/持久實例 | ? 僅臨時實例 | ? |
| 配置中心 | ? 動態推送 | ? | ? |
| 一致性協議 | Raft(CP) + Distro(AP) | AP(最終一致) | Raft(CP) |
| 多語言支持 | ? Java/.Net/Go | ? 主要 Java | ? |
📌 選型建議:
- 需統一注冊中心與配置中心 → Nacos
- 純 Java 生態輕量級部署 → Eureka
- 多數據中心強一致性場景 → Consul
常見問題解決
| 問題 | 解決方案 |
|---|---|
| 客戶端無法連接 Nacos | 檢查 server-addr 配置;確認防火墻開放 8848 端口 |
| 配置更新未生效 | 確保添加 @RefreshScope;檢查 bootstrap.yml 優先級高于 application.yml |
| 集群節點數據不同步 | 驗證 cluster.conf IP 列表;檢查 MySQL 主從狀態 |
動態線程池
背景:
轉賬等核心業務功能往往設計的業務邏輯比較復雜,有一系列的校驗規則,所以就引入了線程池來并發處理,但是在設置線程池的幾個核心參數時,是憑經驗在代碼里面寫死的,上線后發現線程資源不合理,想要調整就必須改代碼重新發布服務,非常麻煩,
以下是一個基于美團DynamicTp設計思想、集成Apollo配置中心的動態線程池完整實現方案,涵蓋參數動態調整、實時監控與告警三大核心模塊。方案分為六個部分,結合代碼實現與架構設計,可直接用于生產環境。
一、整體架構設計
二、基礎環境搭建
1. 依賴引入
<dependencies><!-- Apollo配置中心 --><dependency><groupId>com.ctrip.framework.apollo</groupId><artifactId>apollo-client</artifactId><version>1.9.0</version></dependency><!-- 線程池監控 --><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId><version>1.10.0</version></dependency>
</dependencies>
2. Apollo配置初始化
- 在
application.yml中配置Apollo:
app:id: your-application-id
apollo:meta: http://apollo-config-service:8080bootstrap:enabled: truenamespaces: application, dynamic-tp-config
三、動態線程池核心實現
1. 線程池動態化改造
public class DynamicThreadPoolExecutor extends ThreadPoolExecutor {// 重寫set方法支持動態調整@Overridepublic void setCorePoolSize(int corePoolSize) {super.setCorePoolSize(corePoolSize);if (corePoolSize > getPoolSize()) {prestartCoreThread(); // 立即創建新線程}}@Overridepublic void setMaximumPoolSize(int maxPoolSize) {if (maxPoolSize < getLargestPoolSize()) throw new IllegalArgumentException();super.setMaximumPoolSize(maxPoolSize);}// 支持動態隊列容量(關鍵!)public void setQueueCapacity(int capacity) {if (getQueue() instanceof ResizableBlockingQueue) {((ResizableBlockingQueue<Runnable>) getQueue()).setCapacity(capacity);}}
}// 可擴容隊列實現(仿RabbitMQ設計)
public class ResizableBlockingQueue<E> extends LinkedBlockingQueue<E> {public synchronized void setCapacity(int capacity) {this.capacity = capacity; // 突破JDK隊列final限制}
}
2. 線程池Bean初始化
@Configuration
public class ThreadPoolConfig {@Beanpublic DynamicThreadPoolExecutor orderThreadPool() {return new DynamicThreadPoolExecutor(8, 20, 60, TimeUnit.SECONDS,new ResizableBlockingQueue<>(1000),new NamedThreadFactory("order-pool"),new CallerRunsPolicy());}
}
四、Apollo動態配置集成
1. 參數配置設計(Apollo命名空間:dynamic-tp-config)
threadpool:order:coreSize: 10maxSize: 50queueCapacity: 2000warn:activeThreshold: 40 # 活躍線程告警閾值queueThreshold: 1800 # 隊列容量告警閾值
2. 配置變更監聽器
@Component
public class ThreadPoolRefresher {@Autowiredprivate DynamicThreadPoolExecutor executor;@ApolloConfigChangeListener("dynamic-tp-config")public void onConfigChange(ConfigChangeEvent event) {// 核心線程數變更if (event.isChanged("threadpool.order.coreSize")) {executor.setCorePoolSize(Integer.parseInt(event.getChange("coreSize").getNewValue()));}// 隊列容量變更if (event.isChanged("threadpool.order.queueCapacity")) {executor.setQueueCapacity(Integer.parseInt(event.getChange("queueCapacity").getNewValue()));}}
}
五、監控與告警系統
1. 監控指標采集(Micrometer)
@Scheduled(fixedRate = 5000)
public void collectMetrics() {Metrics.gauge("threadpool.active.threads", executor.getActiveCount());Metrics.gauge("threadpool.queue.size", executor.getQueue().size());Metrics.gauge("threadpool.rejected.count", executor.getRejectedCount());
}
2. 告警規則引擎
public class AlertManager {// 閾值檢查public void checkThresholds() {if (executor.getActiveCount() > activeThreshold) {sendAlert("活躍線程超限!當前值: " + executor.getActiveCount());}if (executor.getQueue().size() > queueThreshold) {sendAlert("隊列堆積預警!當前值: " + executor.getQueue().size());}}// 釘釘告警實現private void sendAlert(String message) {DingTalkSender.send("動態線程池告警: " + message);}
}
3. 可視化看板(Grafana)
- Prometheus指標配置:
scrape_configs:- job_name: 'dynamic-tp'metrics_path: '/actuator/prometheus'static_configs:- targets: ['app-server:8080']
- Grafana面板指標:
threadpool_active_threads:實時活躍線程數threadpool_queue_size:任務隊列堆積量threadpool_rejected_count:任務拒絕次數
六、生產環境最佳實踐
1. 安全兜底策略
// 參數變更前校驗
public void setCorePoolSize(int coreSize) {if (coreSize < 2 || coreSize > 100) throw new IllegalArgumentException("核心線程數超出安全范圍");super.setCorePoolSize(coreSize);
}
2. 灰度發布機制
- 在Apollo中為特定實例打標:
# 僅對IP為192.168.1.101的實例生效
curl -X PUT 'http://apollo-portal/api/v1/namespaces/dynamic-tp-config/items/coreSize' \-d 'value=15&dataChangeCreatedBy=admin&ip=192.168.1.101'
3. 優雅停機處理
@PreDestroy
public void shutdown() {executor.shutdown();if (!executor.awaitTermination(30, TimeUnit.SECONDS)) {executor.shutdownNow(); // 強制終止殘留任務}
}
七、擴展優化方向
- 自適應線程池
基于歷史負載預測自動調整參數(如QPS+RT計算理想線程數) - 跨組件線程池管理
適配Tomcat/Dubbo等中間件線程池 - AI驅動的彈性調度
結合時序預測模型(如LSTM)預擴容線程池
方案優勢總結
| 模塊 | 傳統線程池 | 本方案 |
|---|---|---|
| 參數調整 | 需重啟應用 | 秒級動態生效 |
| 隊列容量 | 固定不可變 | 運行時動態擴容/縮容 |
| 監控粒度 | 需手動埋點 | 全自動指標采集+可視化 |
| 告警時效 | 依賴日志巡檢 | 實時閾值檢測+多通道通知 |
| (executor.getActiveCount() > activeThreshold) { |
sendAlert("活躍線程超限!當前值: " + executor.getActiveCount());}if (executor.getQueue().size() > queueThreshold) {sendAlert("隊列堆積預警!當前值: " + executor.getQueue().size());}
}// 釘釘告警實現
private void sendAlert(String message) {DingTalkSender.send("動態線程池告警: " + message);
}
}
#### 3. **可視化看板(Grafana)**- **Prometheus指標配置**:~~~yaml
scrape_configs:- job_name: 'dynamic-tp'metrics_path: '/actuator/prometheus'static_configs:- targets: ['app-server:8080']
- Grafana面板指標:
threadpool_active_threads:實時活躍線程數threadpool_queue_size:任務隊列堆積量threadpool_rejected_count:任務拒絕次數
六、生產環境最佳實踐
1. 安全兜底策略
// 參數變更前校驗
public void setCorePoolSize(int coreSize) {if (coreSize < 2 || coreSize > 100) throw new IllegalArgumentException("核心線程數超出安全范圍");super.setCorePoolSize(coreSize);
}
2. 灰度發布機制
- 在Apollo中為特定實例打標:
# 僅對IP為192.168.1.101的實例生效
curl -X PUT 'http://apollo-portal/api/v1/namespaces/dynamic-tp-config/items/coreSize' \-d 'value=15&dataChangeCreatedBy=admin&ip=192.168.1.101'
3. 優雅停機處理
@PreDestroy
public void shutdown() {executor.shutdown();if (!executor.awaitTermination(30, TimeUnit.SECONDS)) {executor.shutdownNow(); // 強制終止殘留任務}
}
七、擴展優化方向
- 自適應線程池
基于歷史負載預測自動調整參數(如QPS+RT計算理想線程數) - 跨組件線程池管理
適配Tomcat/Dubbo等中間件線程池 - AI驅動的彈性調度
結合時序預測模型(如LSTM)預擴容線程池
方案優勢總結
| 模塊 | 傳統線程池 | 本方案 |
|---|---|---|
| 參數調整 | 需重啟應用 | 秒級動態生效 |
| 隊列容量 | 固定不可變 | 運行時動態擴容/縮容 |
| 監控粒度 | 需手動埋點 | 全自動指標采集+可視化 |
| 告警時效 | 依賴日志巡檢 | 實時閾值檢測+多通道通知 |
| 生產安全 | 變更風險高 | 灰度發布+參數校驗兜底 |
革新自動化軟件測試 —— 測試工程師必讀深度解析)





:解鎖視覺與多模態任務的深度學習核心》)





)






