CUDA刷新器:CUDA編程模型
CUDA Refresher: The CUDA Programming Model
CUDA,CUDA刷新器,并行編程
這是CUDA更新系列的第四篇文章,它的目標是刷新CUDA中的關鍵概念、工具和初級或中級開發人員的優化。
CUDA編程模型提供了GPU體系結構的抽象,它充當了應用程序與其在GPU硬件上的可能實現之間的橋梁。這篇文章概述了CUDA編程模型的主要概念,概述了它如何在通用編程語言如C/C++中暴露出來。
介紹一下CUDA編程模型中常用的兩個關鍵詞:主機和設備。
主機是系統中可用的CPU。與CPU相關聯的系統內存稱為主機內存。GPU被稱為設備,GPU內存也被稱為設備內存。
要執行任何CUDA程序,有三個主要步驟:
將輸入數據從主機內存復制到設備內存,也稱為主機到設備傳輸。
加載GPU程序并執行,在片上緩存數據以提高性能。
將結果從設備內存復制到主機內存,也稱為設備到主機傳輸。
CUDA內核和線程層次結構
圖1顯示了CUDA內核是一個在GPU上執行的函數。應用程序的并行部分由K個不同的CUDA線程并行執行k次,而不是像常規C/C++函數那樣只進行一次。
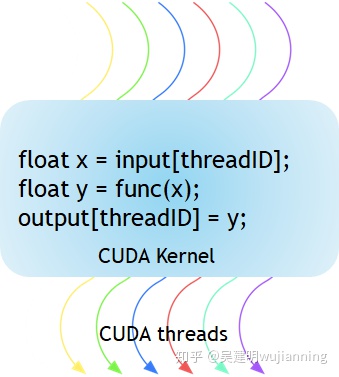
Figure 1. The kernel is a function executed on the GPU.
每一個CUDA內核都以一個__global__聲明說明符開頭。程序員通過使用內置變量為每個線程提供唯一的全局ID。
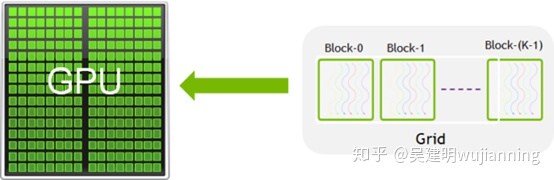
圖2. CUDA內核被細分為塊。
一組線程稱為CUDA塊。CUDA塊被分組到一個網格中。內核作為線程塊的網格來執行(圖2)。
每個CUDA塊由一個流式多處理器(SM)執行,不能遷移到GPU中的其他SMs(搶占、調試或CUDA動態并行期間除外)。一個SM可以根據CUDA塊所需的資源運行多個并發CUDA塊。每個內核在一個設備上執行,CUDA支持一次在一個設備上運行多個內核。圖3顯示了GPU中可用硬件資源的內核執行和映射。
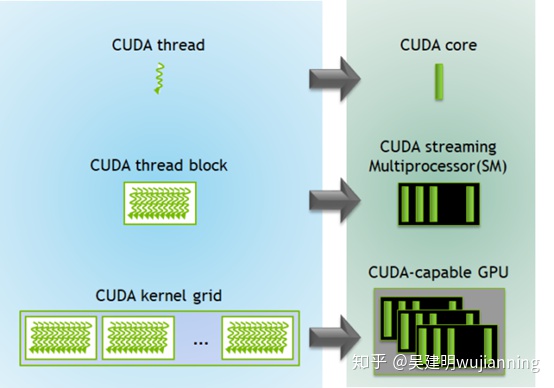
圖3. 在GPU上執行內核。
CUDA為線程和塊定義了內置的三維變量。線程使用內置的三維變量threadIdx編制索引。三維索引提供了一種自然的方法來索引向量、矩陣和體積中的元素,并使CUDA編程更容易。類似地,塊也使用名為blockIdx的內置三維變量編制索引。
以下是幾個值得注意的要點:
CUDA架構限制每個塊的線程數(每個塊限制1024個線程)。
線程塊的維度可以通過內置的blockDim變量在內核中訪問。
syncu中的線程可以使用syncu函數同步。使用同步線程時,塊中的所有線程都必須等待,然后才能繼續。
在<<…>>>語法中指定的每個塊的線程數和每個網格的塊數可以是int或dim3類型。這些三角括號標記從主機代碼到設備代碼的調用。它也被稱為內核啟動。
下面用于添加兩個矩陣的CUDA程序顯示多維blockIdx和threadIdx以及blockDim等其他變量。在下面的例子中,為了便于索引,選擇了一個2D塊,每個塊有256個線程,x和y方向各有16個線程。使用數據大小除以每個塊的大小來計算塊的總數。
// Kernel - Adding two matrices MatA and MatB__global__ void MatAdd(float MatA[N][N], float MatB[N][N],float MatC[N][N]){ int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) MatC[i][j] = MatA[i][j] + MatB[i][j];}int main(){ ... // Matrix addition kernel launch from host code dim3 threadsPerBlock(16, 16); dim3 numBlocks((N + threadsPerBlock.x -1) / threadsPerBlock.x, (N+threadsPerBlock.y -1) / threadsPerBlock.y); MatAdd<<<numBlocks, threadsPerBlock>>>(MatA, MatB, MatC); ...}
Memory hierarchy
支持CUDA的GPU有一個內存層次結構,如圖4所示。
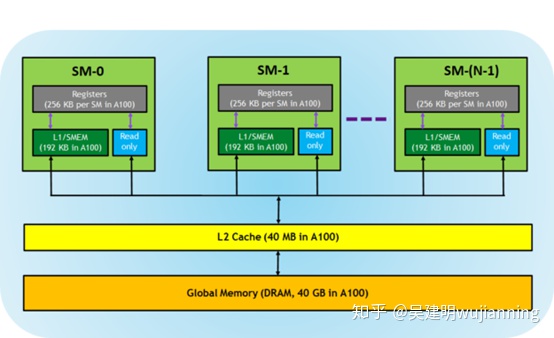
圖4. gpu中的內存層次結構。
以下內存由GPU架構公開:
這些寄存器對每個線程都是私有的,這意味著分配給線程的寄存器對其他線程不可見。編譯器決定寄存器的利用率。
一級/共享內存(SMEM)-每個SM都有一個快速的片上草稿行內存,可用作一級緩存和共享內存。CUDA塊中的所有線程都可以共享共享內存,在給定SM上運行的所有CUDA塊都可以共享SM提供的物理內存資源。。
只讀內存每個SM都有一個指令緩存、常量內存、紋理內存和對內核代碼只讀的RO緩存。 二級緩存二級緩存在所有SMs中共享,因此每個CUDA塊中的每個線程都可以訪問該內存。nvidiaa100 GPU已經將二級緩存大小增加到40mb,而v100gpu中只有6mb。 全局內存這是位于GPU中的GPU和DRAM的幀緩沖區大小。
NVIDIA CUDA編譯器在優化內存資源方面做得很好,但專家CUDA開發人員可以選擇有效地使用這種內存層次結構來優化CUDA程序。
計算能力
GPU的計算能力決定了GPU硬件支持的通用規范和可用特性。此版本號可由應用程序在運行時使用,以確定當前GPU上可用的硬件功能或指令。
每個GPU都有一個版本號,表示為X.Y,其中X包括主要修訂號,Y包含次要修訂號。小版本號對應于架構的增量改進,可能包括新特性。
有關任何支持CUDA的設備的計算能力的更多信息,請參閱CUDA示例代碼設備查詢。此示例枚舉系統中存在的CUDA設備的屬性
摘要
CUDA編程模型提供了一種異構環境,其中主機代碼在CPU上運行C/C++程序,內核在物理上分離的GPU設備上運行。CUDA編程模型還假設主機和設備都保持各自獨立的內存空間,分別稱為主機內存和設備內存。CUDA代碼還通過PCIe總線提供主機和設備內存之間的數據傳輸。
CUDA還公開了許多內置變量,并提供了多維索引的靈活性,以簡化編程。CUDA還管理不同的內存,包括寄存器、共享內存和一級緩存、二級緩存和全局內存。高級開發人員可以有效地使用這些內存來優化CUDA程序。













Socket和ServerSocket)



...)

