

目錄
Celery
一、官方
二、Celery異步任務框架Celery架構圖消息中間件任務執行單元任務結果存儲
三、使用場景
四、Celery的安裝配置
五、兩種celery任務結構:提倡用包管理,結構更清晰
七、Celery執行異步任務包架構封裝
八、基本使用celery.py 基本配置tasks.py 添加任務add_task.py 添加立即、延遲任務get_result.py 獲取結果
九、高級使用celery.py 定時任務配置(循環的)tasks.pyget_result.py
十、django中使用(更新輪播圖案例)redis的配置接口緩存views.py啟動服務celery.pytasks.py
Celery
一、官方
Celery 官網:http://www.celeryproject.org/
Celery 官方文檔英文版:http://docs.celeryproject.org/en/latest/index.html
Celery 官方文檔中文版:http://docs.jinkan.org/docs/celery/
二、Celery異步任務框架
"""
1)可以不依賴任何服務器,通過自身命令,啟動服務(內部支持socket)
2)celery服務為為其他項目服務提供異步解決任務需求的
注:會有兩個服務同時運行,一個是項目服務,一個是celery服務,項目服務將需要異步處理的任務交給celery服務,celery就會在需要時異步完成項目的需求
人是一個獨立運行的服務 | 醫院也是一個獨立運行的服務
正常情況下,人可以完成所有健康情況的動作,不需要醫院的參與;但當人生病時,就會被醫院接收,解決人生病問題
人生病的處理方案交給醫院來解決,所有人不生病時,醫院獨立運行,人生病時,醫院就來解決人生病的需求
"""
Celery架構圖
Celery的架構由三部分組成,消息中間件(message broker)、任務執行單元(worker)和 任務執行結果存儲(task result store)組成。
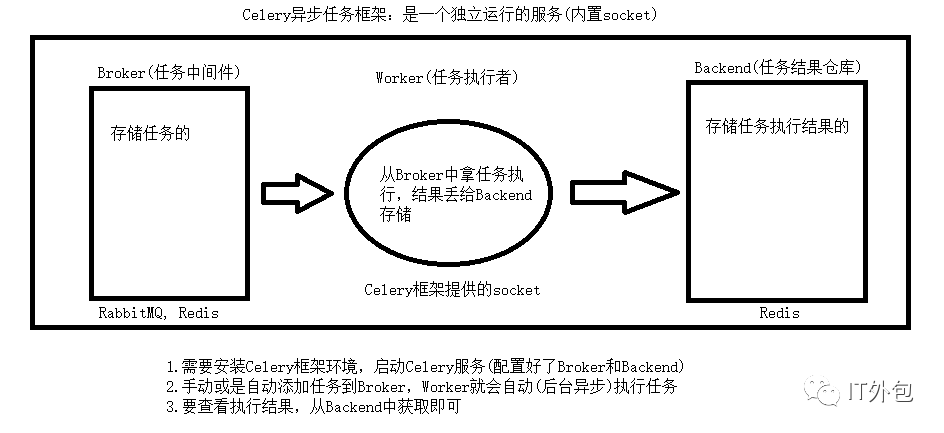
消息中間件
Celery本身不提供消息服務,但是可以方便的和第三方提供的消息中間件集成。包括,RabbitMQ, Redis等等
任務執行單元
Worker是Celery提供的任務執行的單元,worker并發的運行在分布式的系統節點中。
任務結果存儲
Task result store用來存儲Worker執行的任務的結果,Celery支持以不同方式存儲任務的結果,包括AMQP, redis等
三、使用場景
異步執行:解決耗時任務
延遲執行:解決延遲任務
定時執行:解決周期(周期)任務
四、Celery的安裝配置
pip install celery
消息中間件:RabbitMQ/Redis
app=Celery('任務名', broker='xxx', backend='xxx')
五、兩種celery任務結構:提倡用包管理,結構更清晰
# 如果 Celery對象:Celery(...) 是放在一個模塊下的
# 1)終端切換到該模塊所在文件夾位置:scripts
# 2)執行啟動worker的命令:celery worker -A 模塊名 -l info -P eventlet
# 注:windows系統需要eventlet支持,Linux與MacOS直接執行:celery worker -A 模塊名 -l info
# 注:模塊名隨意
# 如果 Celery對象:Celery(...) 是放在一個包下的
# 1)必須在這個包下建一個celery.py的文件,將Celery(...)產生對象的語句放在該文件中
# 2)執行啟動worker的命令:celery worker -A 包名 -l info -P eventlet
# 注:windows系統需要eventlet支持,Linux與MacOS直接執行:celery worker -A 模塊名 -l info
# 注:包名隨意
放在根目錄下就行:
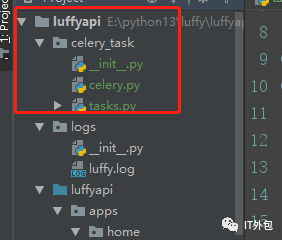
七、Celery執行異步任務
包架構封裝
project
├── celery_task # celery包
│ ├── __init__.py # 包文件
│ ├── celery.py # celery連接和配置相關文件,且名字必須交celery.py
│ └── tasks.py # 所有任務函數
├── add_task.py # 添加任務
└── get_result.py # 獲取結果
八、基本使用
celery.py 基本配置
# 1)創建app + 任務
# 2)啟動celery(app)服務:
# 非windows
# 命令:celery worker -A celery_task -l info
# windows:
# pip3 install eventlet
# celery worker -A celery_task -l info -P eventlet
# 3)添加任務:手動添加,要自定義添加任務的腳本,右鍵執行腳本
# 4)獲取結果:手動獲取,要自定義獲取任務的腳本,右鍵執行腳本
from celery import Celery
# 無密碼
broker = 'redis://127.0.0.1:6379/1'
backend = 'redis://127.0.0.1:6379/2'
# 有密碼:
broker = 'redis://:123@127.0.0.1:6379/1'
backend = 'redis://:123@127.0.0.1:6379/2'
app = Celery(broker=broker, backend=backend, include=['celery_task.tasks'])
'''
broker : 任務倉庫
backend :任務結果倉庫
include :任務(函數)所在文件
'''
tasks.py 添加任務
from .celery import app
@app.task
def add(n1,n2):
res = n1+n2
print('n1+n2 = %s' % res)
return res
@app.task
def low(n1,n2):
res = n1-n2
print('n1-n2 = %s' % res)
return res
add_task.py 添加立即、延遲任務
from celery_task import tasks
# delay :添加立即任務
# apply_async :添加延遲任務
# eta :執行的utc時間
# 添加立即執行任務
t1 = tasks.add.delay(10, 20)
t2 = tasks.low.delay(100, 50)
print(t1.id)
# 添加延遲任務
from celery_package.tasks import jump
from datetime import datetime,timedelta
# 秒
def eta_second(second):
ctime = datetime.now() # 當前時間
utc_ctime = datetime.utcfromtimestamp(ctime.timestamp()) # 當前UTC時間
time_delay = timedelta(seconds=second) # 秒
return utc_ctime + time_delay # 當前時間+往后延遲的秒
# 天
def eta_days(days):
ctime = datetime.now() # 當前時間
utc_ctime = datetime.utcfromtimestamp(ctime.timestamp()) # 當前UTC時間
time_delay = timedelta(days=days) # 天
return utc_ctime + time_delay # 當前時間+往后延遲的天
jump.apply_async(args=(20,5), eta=eta_second(10)) # 10秒后執行
jump.apply_async(args=(20,5), eta=eta_days(1)) # 1天后執行
get_result.py 獲取結果
from celery_task.celery import app
from celery.result import AsyncResult
id = '21325a40-9d32-44b5-a701-9a31cc3c74b5'
if __name__ == '__main__':
async = AsyncResult(id=id, app=app)
if async.successful():
result = async.get()
print(result)
elif async.failed():
print('任務失敗')
elif async.status == 'PENDING':
print('任務等待中被執行')
elif async.status == 'RETRY':
print('任務異常后正在重試')
elif async.status == 'STARTED':
print('任務已經開始被執行')
九、高級使用
celery.py 定時任務配置(循環的)
特點:
添加任務的終端關閉之后,停止添加
celery服務端關閉后,把關閉之后未執行的任務都執行一遍,然后繼續接收任務
# 1)創建app + 任務
# 2)啟動celery(app)服務:
# 注):-A 表示相對路徑,所以一定先進入celery_task所在包
-l 表示打印到日志 info 級別
# 非windows
# 命令:celery worker -A celery_task -l info
# windows:
# pip3 install eventlet
# celery worker -A celery_task -l info -P eventlet
# 3)添加任務:自動添加任務,所以要啟動一個添加任務的服務
# 命令:celery beat -A celery_task -l info
# 4)獲取結果
from celery import Celery
# 無密碼
broker = 'redis://127.0.0.1:6379/1'
backend = 'redis://127.0.0.1:6379/2'
# 有密碼:
broker = 'redis://:123@127.0.0.1:6379/1'
backend = 'redis://:123@127.0.0.1:6379/2'
app = Celery(broker=broker, backend=backend, include=['celery_task.tasks'])
# 時區
app.conf.timezone = 'Asia/Shanghai'
# 是否使用UTC
app.conf.enable_utc = False
# 自動任務的定時配置
from datetime import timedelta
from celery.schedules import crontab
app.conf.beat_schedule = {
# 定時任務名字
'fall_task': {
'task': 'celery_task.tasks.fall',
'args':(30,20),
'schedule': timedelta(seconds=3), # 3秒后執行
# 'schedule': crontab(hour=8, day_of_week=1), # 每周一早八點
}
}
'''
fall_task:任務名自定義
task:任務來源
args:任務參數
schedule:定時時間
'''
'schedule': crontab(hour=8, day_of_week=1), # 每周一早八點
'''
minute : 分鐘
hour :小時
day_of_week :禮拜
day_of_month:月
month_of_year:年
'''
tasks.py
from .celery import app
@app.task
def fall(n1,n2):
res = n1/n2
print('n1 /n2 = %s' % res)
return res
get_result.py
from celery_task.celery import app
from celery.result import AsyncResult
id = '21325a40-9d32-44b5-a701-9a31cc3c74b5'
if __name__ == '__main__':
async = AsyncResult(id=id, app=app)
if async.successful():
result = async.get()
print(result)
elif async.failed():
print('任務失敗')
elif async.status == 'PENDING':
print('任務等待中被執行')
elif async.status == 'RETRY':
print('任務異常后正在重試')
elif async.status == 'STARTED':
print('任務已經開始被執行')
十、django中使用(更新輪播圖案例)
最終達到的效果:根據定時任務來更新redis中的緩存。用戶獲取資源都是從redis緩存中獲取。避免了數據庫的壓力
redis的配置
dev.py
# 緩存redis數據庫配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/10",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}, # 同時的并發量
"DECODE_RESPONSES": True,
"PASSWORD": "123",
}
}
}
接口緩存
"""
1)什么是接口的后臺緩存
前臺訪問后臺接口,后臺會優先從緩存(內存)中查找接口數據
如果有數據,直接對前臺響應緩存數據
如果沒有數據,與(mysql)數據庫交互,得到數據,對前臺響應,同時將數據進行緩存,以備下次使用
了解:前臺緩存 - 前臺在請求到接口數據后,在前臺建立緩存,再發送同樣請求時,發現前臺緩存有數據,就不再對后臺做請求了
2)什么的接口會進行接口緩存
i)接口會被大量訪問:比如主頁中的接口,幾乎所有人都會訪問,而且會重復訪問
ii)在一定時間內數據不會變化(或數據不變化)的接口
iii)接口數據的時效性不是特別強(數據庫數據發生變化了,不是立即同步給前臺,驗后時間同步給前臺也沒事)
注:理論上所有接口都可以建立緩存,只要數據庫與緩存數據同步及時
3)如何實現接口緩存:主頁輪播圖接口
"""
views.py
from rest_framework.viewsets import ModelViewSet
from rest_framework import mixins
from . import models, serializers
from django.conf import settings
from rest_framework.response import Response
from django.core.cache import cache
class BannerViewSet(ModelViewSet, mixins.ListModelMixin):
queryset = models.Banner.objects.filter(is_delete=False, is_show=True).order_by('-orders')[:settings.BANNER_COUNT]
serializer_class = serializers.BannerSerializer
# 有緩存走緩存,沒有緩存走數據庫,然后同步給緩存。接口自己實現
def list(self, request, *args, **kwargs):
banner_list = cache.get('banner_list')
if not banner_list:
print('走了數據庫')
response = self.list(request, *args, **kwargs)
banner_list = response.data
cache.set('banner_list', banner_list, 86400) # 存進緩存中,緩存配置了redis數據庫
return Response(banner_list)
啟動服務
'''
1):先切換到celery_task所在的同級目錄(一般為根目錄下)
2):開一個終端(啟動服務): celery worker -A celery_task -l info -P eventlet
3):再開一個終端(添加任務): celery beat -A celery_task -l info
'''
# 注):-A 表示相對路徑,所以一定先進入celery_task所在包
-l 表示打印到日志 info 級別
celery.py
"""
celery框架django項目工作流程
1)加載django配置環境
2)創建Celery框架對象app,配置broker和backend,得到的app就是worker
3)給worker對應的app添加可處理的任務函數,用include配置給worker的app
4)完成提供的任務的定時配置app.conf.beat_schedule
5)啟動celery服務,運行worker,執行任務
6)啟動beat服務,運行beat,添加任務
重點:由于采用了django的反射機制,使用celery.py所在的celery_task包必須放置項目的根目錄下
"""
# 一、加載django配置環境
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "luffyapi.settings.dev")
# 二、加載celery配置環境
from celery import Celery
broker = 'redis://:123@127.0.0.1:6379/1'
backend = 'redis://:123@127.0.0.1:6379/2'
# worker
app = Celery(broker=broker, backend=backend, include=['celery_task.tasks']) # 外面的包名和文件名,一般都是固定
# 時區
app.conf.timezone = 'Asia/Shanghai'
# 是否使用UTC
app.conf.enable_utc = False
# 任務的定時配置
from datetime import timedelta
from celery.schedules import crontab
app.conf.beat_schedule = {
# 定時任務名字
'update_banner_cache': {
'task': 'celery_task.tasks.update_banner_list',
'args': (),
'schedule': timedelta(seconds=10), # 3秒一次
# 'schedule': crontab(hour=8, day_of_week=1), # 每周一早八點
# 'schedule': crontab(minute=0, day_of_week=1), # 每周一早八點
}
}
'''
minute : 分鐘
hour :小時
day_of_week :禮拜
day_of_month:月
month_of_year:年
'''
'''
fall_task:任務名自定義
task:任務來源
args:任務參數
schedule:定時時間(秒)
'''
tasks.py
from .celery import app
from django.core.cache import cache
from home import models, serializers
from django.conf import settings
@app.task
def update_banner_list():
queryset = models.Banner.objects.filter(is_delete=False, is_show=True).order_by('-orders')[:settings.BANNER_COUNT]
banner_list = serializers.BannerSerializer(queryset, many=True).data
# 拿不到request對象,所以頭像的連接base_url要自己組裝
for banner in banner_list:
banner['image'] = 'http://127.0.0.1:8000%s' % banner['image']
cache.set('banner_list', banner_list, 86400)
return True
選擇了IT,必定終身學習
作者:Jeff
出處:http://dwz.date/aNfM
圖片和內容源自網絡分享,若有侵權,請聯系刪除!
上海艾磊科技有限公司專門為企業提供IT咨詢,IT外包,系統集成,以及各類IT增值服務。其中增值服務包括OFFICE 365云服務,鼎捷企業ERP管理軟件,云備份,企業郵箱,無線覆蓋,上網行為管理,VPN架設,網絡安全服務,INTERNET接入,設備租賃, IP電話服務



)







方法及示例)
)


函數)




