福哥答案2020-08-17:
數據傾斜是大數據領域繞不開的攔路虎,當你所需處理的數據量到達了上億甚至是千億條的時候,數據傾斜將是橫在你面前一道巨大的坎。很可能有幾周甚至幾月都要頭疼于數據傾斜導致的各類詭異的問題。
數據傾斜是指:mapreduce程序執行時,reduce節點大部分執行完畢,但是有一個或者幾個reduce節點運行很慢,導致整個程序的處理時間很長,這是因為某一個key的條數比其他key多很多(有時是百倍或者千倍之多),這條key所在的reduce節點所處理的數據量比其他節點就大很多,從而導致某幾個節點遲遲運行不完。Hive的執行是分階段的,map處理數據量的差異取決于上一個stage的reduce輸出,所以如何將數據均勻的分配到各個reduce中,就是解決數據傾斜的根本所在。
以下是一些常見的數據傾斜情形:
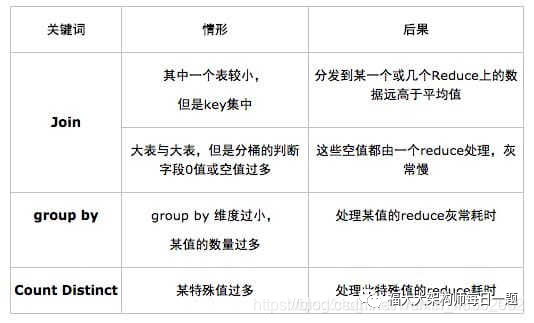
一、Group by 傾斜
group by造成的傾斜相對來說比較容易解決。hive提供兩個參數可以解決:
1.1 hive.map.aggr
一個是hive.map.aggr,默認值已經為true,他的意思是做map aggregation,也就是在mapper里面做聚合。這個方法不同于直接寫mapreduce的時候可以實現的combiner,但是卻實現了類似combiner的效果。事實上各種基于mr的框架如pig,cascading等等用的都是map aggregation(或者叫partial aggregation)而非combiner的策略,也就是在mapper里面直接做聚合操作而不是輸出到buffer給combiner做聚合。對于map aggregation,hive還會做檢查,如果aggregation的效果不好,那么hive會自動放棄map aggregation。判斷效果的依據就是經過一小批數據的處理之后,檢查聚合后的數據量是否減小到一定的比例,默認是0.5,由hive.map.aggr.hash.min.reduction這個參數控制。所以如果確認數據里面確實有個別取值傾斜,但是大部分值是比較稀疏的,這個時候可以把比例強制設為1,避免極端情況下map aggr失效。hive.map.aggr還有一些相關參數,比如map aggr的內存占用等,具體可以參考這篇文章。
1.2 hive.groupby.skewindata
另一個參數是hive.groupby.skewindata。這個參數的意思是做reduce操作的時候,拿到的key并不是所有相同值給同一個reduce,而是隨機分發,然后reduce做聚合,做完之后再做一輪MR,拿前面聚合過的數據再算結果。所以這個參數其實跟hive.map.aggr做的是類似的事情,只是拿到reduce端來做,而且要額外啟動一輪job,所以其實不怎么推薦用,效果不明顯。
1.3 count distinct 改寫
另外需要注意的是count distinct操作往往需要改寫SQL,可以按照下面這么做:
```bash
/*改寫前*/
select a, count(distinct b) as c from tbl group by a;
/*改寫后*/
select a, count(*) as c from (select a, b from tbl group by a, b) group by a;
```
二、Join傾斜
2.1 skew join
join造成的傾斜,常見情況是不能做map join的兩個表(能做map join的話基本上可以避免傾斜),其中一個是行為表,另一個應該是屬性表。比如我們有三個表,一個用戶屬性表users,一個商品屬性表items,還有一個用戶對商品的操作行為表日志表logs。假設現在需要將行為表關聯用戶表:
```bash
select * from logs a join users b on a.user_id = b.user_id;
```
其中logs表里面會有一個特殊用戶user_id = 0,代表未登錄用戶,假如這種用戶占了相當的比例,那么個別reduce會收到比其他reduce多得多的數據,因為它要接收所有user_id = 0的記錄進行處理,使得其處理效果會非常差,其他reduce都跑完很久了它還在運行。
hive給出的解決方案叫skew join,其原理把這種user_id = 0的特殊值先不在reduce端計算掉,而是先寫入hdfs,然后啟動一輪map join專門做這個特殊值的計算,期望能提高計算這部分值的處理速度。當然你要告訴hive這個join是個skew join,即:set
> hive.optimize.skewjoin = true;
還有要告訴hive如何判斷特殊值,根據hive.skewjoin.key設置的數量hive可以知道,比如默認值是100000,那么超過100000條記錄的值就是特殊值。總結起來,skew join的流程可以用下圖描述:
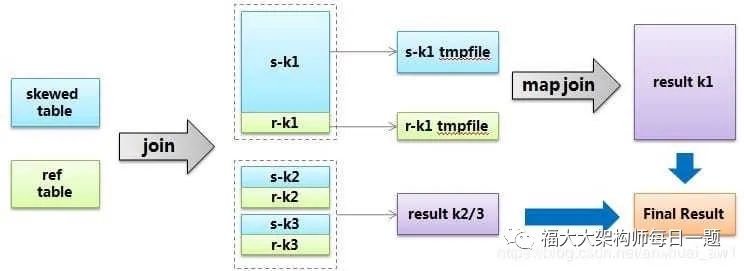
2.2 特殊值分開處理法
不過,上述方法還要去考慮閾值之類的情況,其實也不夠通用。所以針對join傾斜的問題,一般都是通過改寫sql解決。對于上面這個問題,我們已經知道user_id = 0是一個特殊key,那么可以把特殊值隔離開來單獨做join,這樣特殊值肯定會轉化成map join,非特殊值就是沒有傾斜的普通join了:
```bash
select
*
from
(
select * from logs where user_id = 0
)
a
join
(
select * from users where user_id = 0
)
b
on
a.user_id = b.user_id
union all
select * from logs a join users b on a.user_id <> 0 and a.user_id = b.user_id;
```
2.3 隨機數分配法
上面這種個別key傾斜的情況只是一種傾斜情況。最常見的傾斜是因為數據分布本身就具有長尾性質,比如我們將日志表和商品表關聯:
```bash
select * from logs a join items b on a.item_id = b.item_id;
```
這個時候,分配到熱門商品的reducer就會很慢,因為熱門商品的行為日志肯定是最多的,而且我們也很難像上面處理特殊user那樣去處理item。這個時候就會用到加隨機數的方法,也就是在join的時候增加一個隨機數,隨機數的取值范圍n相當于將item給分散到n個reducer:
```bash
select
a.*,
b.*
from
(
select *, cast(rand() * 10 as int) as r_id from logs
)
a
join
(
select *, r_id from items lateral view explode(range_list(1, 10)) rl as r_id
)
b
on
a.item_id = b.item_id
and a.r_id = b.r_id
```
上面的寫法里,對行為表的每條記錄生成一個1-10的隨機整數,對于item屬性表,每個item生成10條記錄,隨機key分別也是1-10,這樣就能保證行為表關聯上屬性表。其中range_list(1,10)代表用udf實現的一個返回1-10整數序列的方法。這個做法是一個解決join傾斜比較根本性的通用思路,就是如何用隨機數將key進行分散。當然,可以根據具體的業務場景做實現上的簡化或變化。
2.4 業務設計
除了上面兩類情況,還有一類情況是因為業務設計導致的問題,也就是說即使行為日志里面join key的數據分布本身并不明顯傾斜,但是業務設計導致其傾斜。比如對于商品item_id的編碼,除了本身的id序列,還人為的把item的類型也作為編碼放在最后兩位,這樣如果類型1(電子產品)的編碼是00,類型2(家居產品)的編碼是01,并且類型1是主要商品類,將會造成以00為結尾的商品整體傾斜。這時,如果reduce的數量恰好是100的整數倍,會造成partitioner把00結尾的item_id都hash到同一個reducer,引爆問題。這種特殊情況可以簡單的設置合適的reduce值來解決,但是這種坑對于不了解業務的情況下就會比較隱蔽。
三、典型的業務場景
3.1 空值產生的數據傾斜
場景:如日志中,常會有信息丟失的問題,比如日志中的 user_id,如果取其中的 user_id 和 用戶表中的user_id 關聯,會碰到數據傾斜的問題。
解決方法1:user_id為空的不參與關聯
```bash
select
*
from
log a
join users b
on
a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a where a.user_id is null;
```
解決方法2 :賦與空值分新的key值
```bash
select
*
from
log a
left outer join users b
on
case
when a.user_id is null
then concat(‘hive’, rand())
else a.user_id
end = b.user_id;
```
結論:方法2比方法1效率更好,不但io少了,而且作業數也少了。解決方法1中 log讀取兩次,jobs是2。解決方法2 job數是1 。這個優化適合無效 id (比如 -99 , ’’, null 等) 產生的傾斜問題。把空值的 key 變成一個字符串加上隨機數,就能把傾斜的數據分到不同的reduce上 ,解決數據傾斜問題。
3.2 不同數據類型關聯產生數據傾斜
場景:用戶表中user_id字段為int,log表中user_id字段既有string類型也有int類型。當按照user_id進行兩個表的Join操作時,默認的Hash操作會按int型的id來進行分配,這樣會導致所有string類型id的記錄都分配到一個Reducer中。
解決方法:把數字類型轉換成字符串類型
```bash
select
*
from
users a
left outer join logs b
on
a.usr_id = cast(b.user_id as string)
```
3.3 小表不小不大,怎么用 map join 解決傾斜問題
使用 map join 解決小表(記錄數少)關聯大表的數據傾斜問題,這個方法使用的頻率非常高,但如果小表很大,大到map join會出現bug或異常,這時就需要特別的處理。以下例子:
```bash
select * from log a left outer join users b on a.user_id = b.user_id;
```
users 表有 600w+ 的記錄,把 users 分發到所有的 map 上也是個不小的開銷,而且 map join 不支持這么大的小表。如果用普通的 join,又會碰到數據傾斜的問題。
```bash
select
/*+mapjoin(x)*/
*
from
log a
left outer join
(
select
/*+mapjoin(c)*/
d.*
from
(
select distinct user_id from log
)
c
join users d
on
c.user_id = d.user_id
)
x on a.user_id = b.user_id;
```
假如,log里user_id有上百萬個,這就又回到原來map join問題。所幸,每日的會員uv不會太多,有交易的會員不會太多,有點擊的會員不會太多,有傭金的會員不會太多等等。所以這個方法能解決很多場景下的數據傾斜問題。
四、總結
使map的輸出數據更均勻的分布到reduce中去,是我們的最終目標。由于Hash算法的局限性,按key Hash會或多或少的造成數據傾斜。大量經驗表明數據傾斜的原因是人為的建表疏忽或業務邏輯可以規避的。在此給出較為通用的步驟:
1)采樣log表,哪些user_id比較傾斜,得到一個結果表tmp1。由于對計算框架來說,所有的數據過來,他都是不知道數據分布情況的,所以采樣是并不可少的。
2)數據的分布符合社會學統計規則,貧富不均。傾斜的key不會太多,就像一個社會的富人不多,奇特的人不多一樣。所以tmp1記錄數會很少。把tmp1和users做map join生成tmp2,把tmp2讀到distribute file cache。這是一個map過程。
3)map讀入users和log,假如記錄來自log,則檢查user_id是否在tmp2里,如果是,輸出到本地文件a,否則生成的key,value對,假如記錄來自member,生成的key,value對,進入reduce階段。
4)最終把a文件,把Stage3 reduce階段輸出的文件合并起寫到hdfs。
如果確認業務需要這樣傾斜的邏輯,考慮以下的優化方案:
1)對于join,在判斷小表不大于1G的情況下,使用map join
2)對于group by或distinct,設定 hive.groupby.skewindata=true
3)盡量使用上述的SQL語句調節進行優化
五、參考文獻
[數據分析系列(3):數據傾斜](https://blog.csdn.net/anshuai_aw1/article/details/84033160)
***
[評論](https://user.qzone.qq.com/3182319461/blog/1597618770)






-PASCAL VOC圖像分割...)












