移動互聯網時代,海量的用戶數據每天都在產生,基于用戶使用數據的用戶行為分析等這樣的分析,都需要依靠數據都統計和分析,當數據量小時,數據庫方面的優化顯得不太重要,一旦數據量越來越大,系統響應會變慢,TPS直線下降,直至服務不可用。
可能有人會問,為何不用Oracle呢?確實,很多開發者寫代碼時并不會關心SQL的問題,凡是性能問題都交給DBA負責SQL優化,可是,不是每一個項目都會有DBA,也不是所有的項目都會采用Oracle數據庫,而且,Oracle數據庫在大數據量的背景下,解決性能問題,也不見的是一個非常輕松的事情。那么,Mysql能不能支撐億級的數據量呢,我的答案是肯定的,絕大部分的互聯網公司,它們采用的數據存儲方案,絕大部分都是以Mysql為主,不差錢的國企和銀行,以Oracle為主,而且有專職的DBA為你服務。
本文會以一個實際的項目應用為例,層層向大家剖析如何進行數據庫的優化。項目背景是企業級的統一消息處理平臺,客戶數據在5千萬加,每分鐘處理消息流水1千萬,每天消息流水1億左右。雖說Mysql單表可以存儲10億級的數據,但這個時候性能非常差。既然一張表無法搞定,那么就想辦法將數據放到多個地方來解決問題吧,于是,數據庫分庫分表的方案便產生了,目前比較普遍的方案有三個:分區,分庫分表,NoSql/NewSql。
在實際的項目中,往往是這三種方案的結合來解決問題,目前絕大部分系統的核心數據都是以RDBMS存儲為主,NoSql/NewSql存儲為輔。
分區
首先來了解一下分區方案。
分區表是由多個相關的底層表實現,這些底層表也是由句柄對象表示,所以我們也可以直接訪問各個分區,存儲引擎管理分區的各個底層表和管理普通表一樣(所有的底層表都必須使用相同的存儲引擎),分區表的索引只是在各個底層表上各自加上一個相同的索引,從存儲引擎的角度來看,底層表和一個普通表沒有任何不同,存儲引擎也無須知道這是一個普通表還是一個分區表的一部分。這個方案也不錯,它對用戶屏蔽了sharding的細節,即使查詢條件沒有sharding column,它也能正常工作(只是這時候性能一般)。不過它的缺點很明顯:很多的資源都受到單機的限制,例如連接數,網絡吞吐等。如何進行分區,在實際應用中是一個非常關鍵的要素之一。在我們的項目中,以客戶信息為例,客戶數據量5000萬加,項目背景要求保存客戶的銀行卡綁定關系,客戶的證件綁定關系,以及客戶綁定的業務信息。此業務背景下,該如何設計數據庫呢。項目一期的時候,我們建立了一張客戶業務綁定關系表,里面冗余了每一位客戶綁定的業務信息。基本結構大致如下:
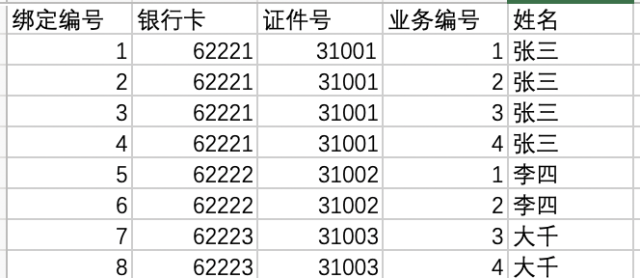
查詢時,對銀行卡做索引,業務編號做索引,證件號做索引。隨著需求大增多,這張表的索引會達到10個以上。而且客戶解約再簽約,里面會保存兩條數據,只是綁定的狀態不同。假設我們有5千萬的客戶,5個業務類型,每位客戶平均2張卡,那么這張表的數據量將會達到驚人的5億,事實上我們系統用戶量還沒有過百萬時就已經不行了。mysql數據庫中的數據是以文件的形勢存在磁盤上的,默認放在/mysql/data下面(可以通過my.cnf中的datadir來查看), 一張表主要對應著三個文件,一個是frm存放表結構的,一個是myd存放表數據的,一個是myi存表索引的。這三個文件都非常的龐大,尤其是.myd文件,快5個G了。下面進行第一次分區優化,Mysql支持的分區方式有四種:
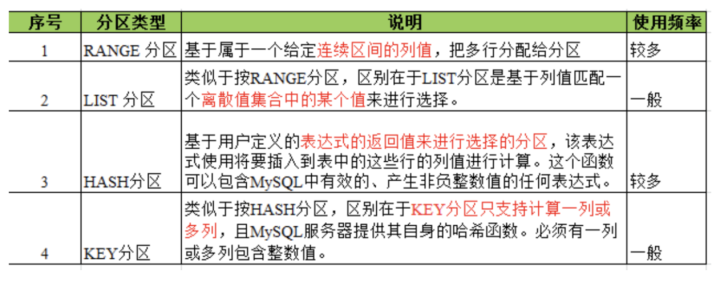
在我們的項目中,range分區和list分區沒有使用場景,如果基于綁定編號做range或者list分區,綁定編號沒有實際的業務含義,無法通過它進行查詢,因此,我們就剩下 HASH 分區和 KEY 分區了, HASH 分區僅支持int類型列的分區,且是其中的一列。看看我們的庫表結構,發現沒有哪一列是int類型的,如何做分區呢?可以增加一列,綁定時間列,將此列設置為int類型,然后按照綁定時間進行分區,將每一天綁定的用戶分到同一個區里面去。這次優化之后,我們的插入快了許多,但是查詢依然很慢,為什么,因為在做查詢的時候,我們也只是根據銀行卡或者證件號進行查詢,并沒有根據時間查詢,相當于每次查詢,mysql都會將所有的分區表查詢一遍。
然后進行第二次方案優化,既然hash分區和key分區要求其中的一列必須是int類型的,那么創造出一個int類型的列出來分區是否可以。分析發現,銀行卡的那串數字有秘密。銀行卡一般是16位到19位不等的數字串,我們取其中的某一位拿出來作為表分區是否可行呢,通過分析發現,在這串數字中,其中確實有一位是0到9隨機生成的,不同的卡串長度,這一位不同,絕不是最后一位,最后位數字一般都是校驗位,不具有隨機性。我們新設計的方案,基于銀行卡號+隨機位進行KEY分區,每次查詢的時候,通過計算截取出這位隨機位數字,再加上卡號,聯合查詢,達到了分區查詢的目的,需要說明的是,分區后,建立的索引,也必須是分區列,否則的話,Mysql還是會在所有的分區表中查詢數據。那么通過銀行卡號查詢綁定關系的問題解決了,那么證件號呢,如何通過證件號來查詢綁定關系。前面已經講過,做索引一定是要在分區健上進行,否則會引起全表掃描。我們再創建了一張新表,保存客戶的證件號綁定關系,每位客戶的證件號都是唯一的,新的證件號綁定關系表里,證件號作為了主鍵,那么如何來計算這個分區健呢,客戶的證件信息比較龐雜,有身份證號,港澳臺通行證,機動車駕駛證等等,如何在無序的證件號里找到分區健。為了解決這個問題,我們將證件號綁定關系表一分為二,其中的一張表專用于保存身份證類型的證件號,另一張表則保存其他證件類型的證件號,在身份證類型的證件綁定關系表中,我們將身份證號中的月數拆分出來作為了分區健,將同一個月出生的客戶證件號保存在同一個區,這樣分成了12個區,其他證件類型的證件號,數據量不超過10萬,就沒有必要進行分區了。這樣每次查詢時,首先通過證件類型確定要去查詢哪張表,再計算分區健進行查詢。
作了分區設計之后,保存2000萬用戶數據的時候,銀行卡表的數據保存文件就分成了10個小文件,證件表的數據保存文件分成了12個小文件,解決了這兩個查詢的問題,還剩下一個問題就是,業務編號呢,怎么辦,一個客戶有多個簽約業務,如何進行保存,這時候,采用分區的方案就不太合適了,它需要用到分表的方案。
分庫分表
如何進行分庫分表,目前互聯網上有許多的版本,比較知名的一些方案:阿里的TDDL,DRDS和cobar,京東金融的sharding-jdbc;民間組織的MyCAT;360的Atlas;美團的zebra
其他比如網易,58,京東等公司都有自研的中間件。
但是這么多的分庫分表中間件方案,歸總起來,就兩類:client模式和proxy模式。
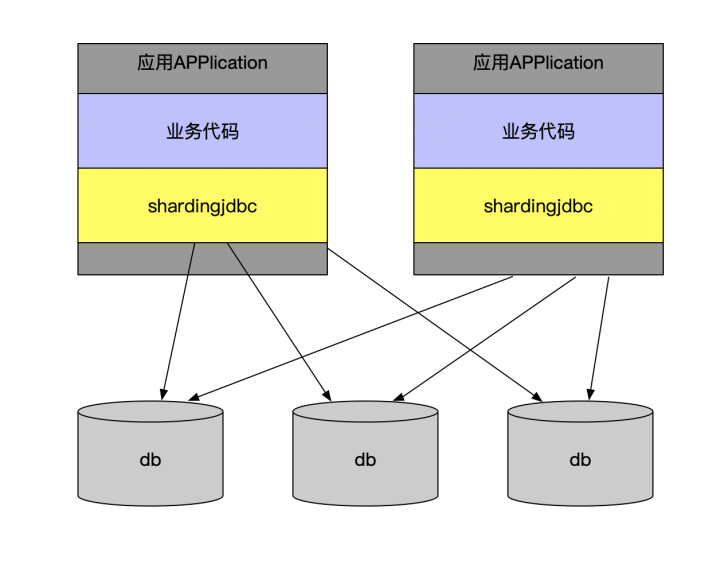
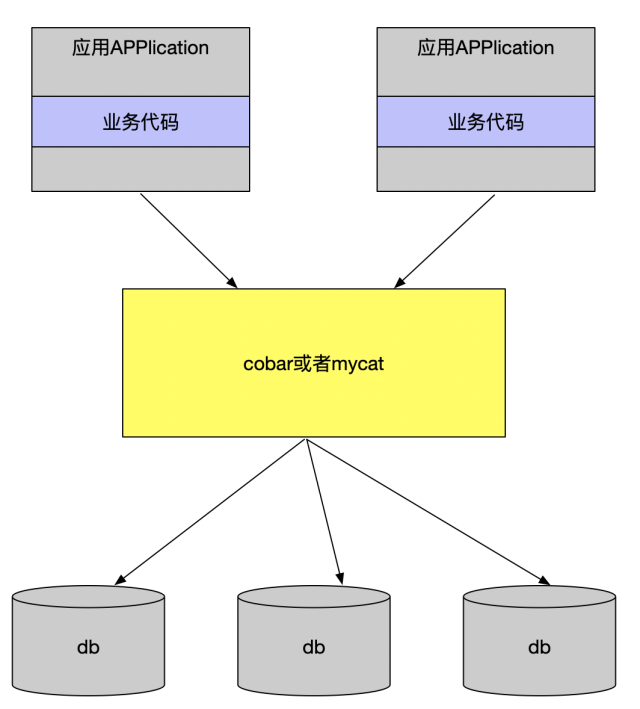
無論是client模式,還是proxy模式,幾個核心的步驟是一樣的:SQL解析,重寫,路由,執行,結果歸并。個人比較傾向于采用client模式,它架構簡單,性能損耗也比較小,運維成本低。如果在項目中引入mycat或者cobar,他們的單機模式無法保證可靠性,一旦宕機則服務就變得不可用,你又不得不引入HAProxy來實現它的高可用集群部署方案, 為了解決HAProxy的高可用問題,又需要采用Keepalived來實現。
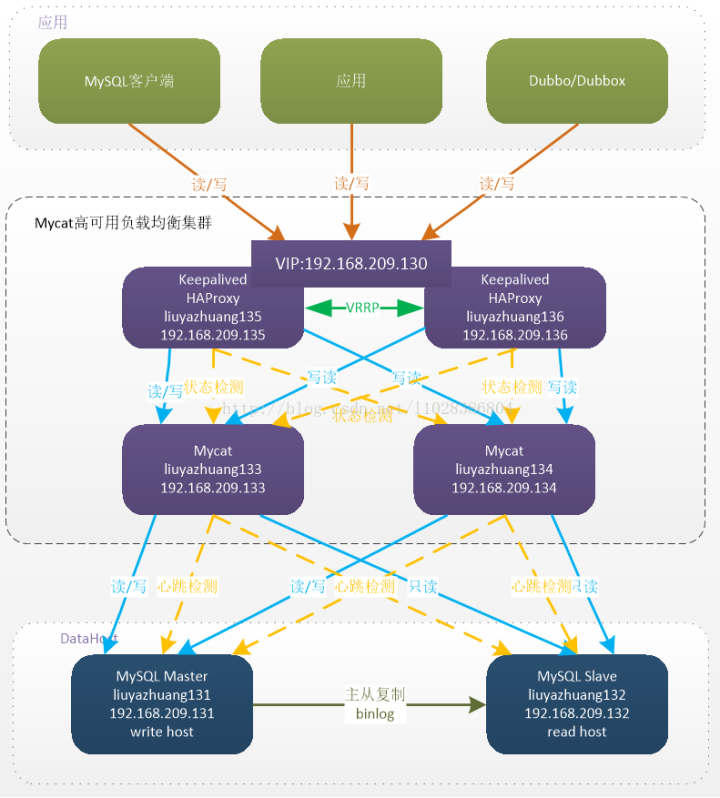
我們在項目中放棄了這個方案,采用了shardingjdbc的方式。回到剛才的業務問題,如何對業務類型進行分庫分表。分庫分表第一步也是最重要的一步,即sharding column的選取,sharding column選擇的好壞將直接決定整個分庫分表方案最終是否成功。而sharding column的選取跟業務強相關。在我們的項目場景中,sharding column無疑最好的選擇是業務編號。通過業務編號,將客戶不同的綁定簽約業務保存到不同的表里面去,查詢時,根據業務編號路由到相應的表中進行查詢,達到進一步優化sql的目的。
前面我們講到了基于客戶簽約綁定業務場景的數據庫優化,下面我們再聊一聊,對于海量數據的保存方案。
垂直分庫
對于每分鐘要處理近1000萬的流水,每天流水近1億的量,如何高效的寫入和查詢,是一項比較大的挑戰。還是老辦法,分庫分表分區,讀寫分離,只不過這一次,我們先分表,再分庫,最后分區。我們將消息流水按照不同的業務類型進行分表,相同業務的消息流水進入同一張表,分表完成之后,再進行分庫。我們將流水相關的數據單獨保存到一個庫里面去,這些數據,寫入要求高,查詢和更新到要求低,將它們和那些更新頻繁的數據區分開。分庫之后,再進行分區。
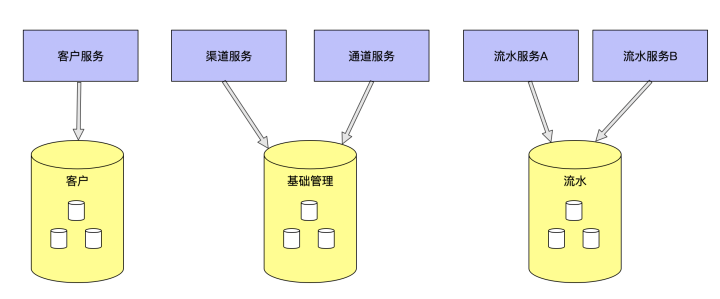
這是基于業務垂直度進行的分庫操作,垂直分庫就是根據業務耦合性,將關聯度低的不同表存儲在不同的數據庫,以達到系統資源的飽和利用率。這樣的分庫方案結合應用的微服務治理,每個微服務系統使用獨立的一個數據庫。將不同模塊的數據分庫存儲,模塊間不能進行相互關聯查詢,如果有,要么通過數據冗余解決,要么通過應用代碼進行二次加工進行解決。若不能杜絕跨庫關聯查詢,則將小表到數據冗余到大數據量大庫里去。假如,流水大表中查詢需要關聯獲得渠道信息,渠道信息在基礎管理庫里面,那么,要么在查詢時,代碼里二次查詢基礎管理庫中的渠道信息表,要么將渠道信息表冗余到流水大表中。
將每天過億的流水數據分離出去之后,流水庫中單表的數據量還是太龐大,我們將單張流水表繼續分區,按照一定的業務規則,(一般是查詢索引列)將單表進行分區,一個表編程N個表,當然這些變化對應用層是無法感知的。
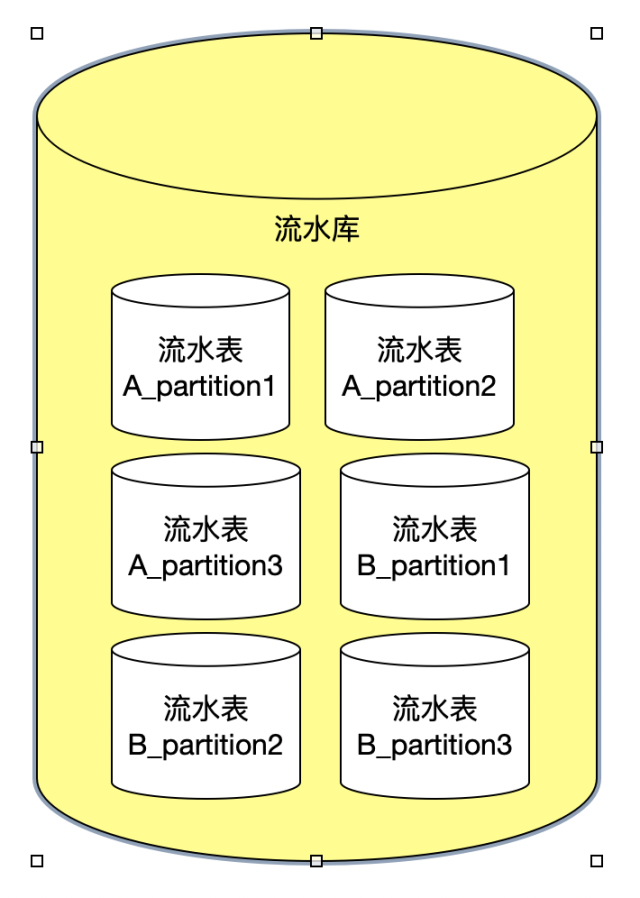
分區表的設置,一般是以查詢索引列進行分區,例如,對于流水表A,查詢需要根據手機號和批次號進行查詢,所以我們在創建分區的時候,就選擇以手機號和批次號進行分區,這樣設置后,查詢都會走索引,每次查詢Mysql都會根據查詢條件計算出來,數據會落在那個分區里面,直接到對應的分區表中檢索即可,避免了全表掃描。
對于每天流水過億的數據,當然是要做歷史表進行數據遷移的工作了。客戶要求流水數據需要保存半年的時間,有的關鍵流水需要保存一年。刪數據是不可能的了,也跑不了路,雖然當時非常有想刪數據跑路的沖動。其實即時是刪數據也是不太可能的了,delete的拙劣表演先淘汰了,truncate也快不了多少,我們采用了一種比較巧妙方法,具體步驟如下:
- 創建一個原表一模一樣的臨時表1 create table test_a_serial_1 like test_a_serial;
- 將原表命名為臨時表2 alter table test_a_serial rename test_a_serial_{date};
- 將臨時表1改為原表 alter table able test_a_serial_1 rename able test_a_serial; 此時,當日流水表就是一張新的空表了,繼續保存當日的流水,而臨時表2則保存的是昨天的數據和部分今天的數據,臨時表2到名字中的date時間是通過計算獲得的昨日的日期;每天會產生一張帶有昨日日期的臨時表2,每個表內的數據大約是有1000萬。
- 將當日表中的歷史數據遷移到昨日流水表中去 這樣的操作都是用的定時任務進行處理,定時任務觸發一般會選擇凌晨12點以后,這個操作即時是幾秒內完成,也有可能會有幾條數據落入到當日表中去。因此我們最后還需要將當日表內的歷史流水數據插入到昨日表內; insert into test_a_serial_{date}(cloumn1,cloumn2….) select(cloumn1,cloumn2….) from test_a_serial where LEFT(create_time,8) > CONCAT(date); commit;
如此,便完成了流水數據的遷移;
根據業務需要,有些業務數據需要保存半年,超過半年的進行刪除,在進行刪除的時候,就可以根據表名中的_{date}篩選出大于半年的流水直接刪表;
半年的時間,對于一個業務流水表大約就會有180多張表,每張表又有20個分區表,那么如何進行查詢呢?由于我們的項目對于流水的查詢實時性要求不是特別高,因此我們在做查詢時,進行了根據查詢時間區間段進行路由查詢的做法。大致做法時,根據客戶選擇的時間區間段,帶上查詢條件,分別去時間區間段內的每一張表內查詢,將查詢結果保存到一張臨時表內,然后,再去查詢臨時表獲得最終的查詢結果。
以上便是我們面對大數據量的場景下,數據庫層面做的相應的優化,一張每天一億的表,經過拆分后,每個表分區內的數據在500萬左右。這樣設計之后,我們還面臨了一些其他問題,例如流水的統計問題,這么大量的數據,項目中的統計維度達到100多種,哪怕是每天count100次,也是及其困難多,我們采用了實時計算統計的方式來解決了這個問題,相關的技術涉及到實時計算,消息隊列,緩存中間件等內容,盡請期待吧!
推薦閱讀:
Elasticsearch --讓你的搜索引擎全面發展!?rdc.hundsun.com如何高效操作Redis數據庫? - 數據庫 - 恒生研究院?rdc.hundsun.com




-PASCAL VOC圖像分割...)














