變量的定義和使用
變量的定義與初始化
TensorFlow中,變量是一種特殊的張量,其值可以是一個任意類型的形狀的張量。
與其他張量不同,變量存在于單個回話調用的上下文之外,主要作用是保存和更新模型中的參數。
聲明變量通常使用tf.Variable()函數,其語法格式如表所示
| 函數 | 說明 |
| tf.Variable( initial_value, trainable=True, collections=None, validate_shape=True, name=None) | 主要作用是聲明一個變量。 initial_value:必選,指定變量的初始值。所有可轉換為張量的類型均可。 trainable:可選,設置是否可以訓練,默認為True collections:可選,設置該圖變量的類型,默認為GraphKeys.GLOBAL_VARIABLES. validate_shape:可選,默認為True。如果為False,則不進行類型和維度檢查。 name:變量名稱。如果未指定會自動分配一個唯一的值。 |
tf.Variable()的主要作用是構造一個變量并添加到計算圖模型中。在運行其他操作之前,需要對所有變量進行初始化。
最簡單的初始化方法是添加一個對所有變量進行初始化的操作,然后在使用模型前運行此操作。
最常見的方式是運行tf.global_variables_initializer()函數進行全局初始化,該函數會初始化計算圖中所有的變量。
下面的代碼演示了如何在模型中初始化變量
import tensorflow as tf
# tf.Variable()定義了一個1行3列的整型變量,該變量的初始值為1,2,3
v = tf.Variable([1,2,3],dtype=tf.int32)
# tf.global_variables_initializer()定義了一個全局初始化操作。
init_op = tf.global_variables_initializer()
with tf.Session() as sess:#在會話中運行sess.run()初始化模型中的所有變量sess.run(init_op)print(sess.run(v))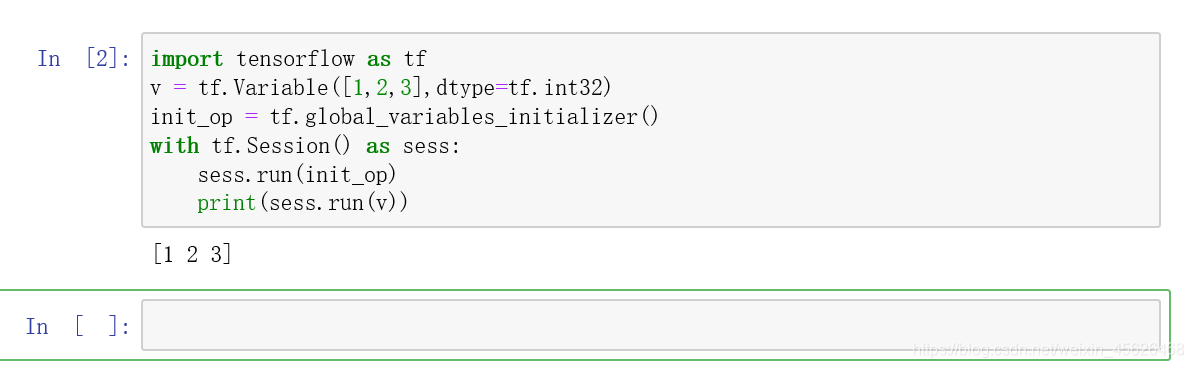
隨機初始化變量
在聲明變量時需要指定初始化,一般使用隨機數給TensorFlow的變量初始化,常見的初始化方法如下:
| 函數 | 說明 |
| tf.random_normal( shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None) | 產生一個符合正態分布的張量。 shape:必選,生成張量的形狀。 mean:可選,正態分布的均值,默認為0 stddev:可選,正態分布的標準差,默認為1.0 dtype:可選,生成張量的類型,默認為tf.float32. seed:可選,隨機數種子,是一個整數。當設置之后,每次生成的隨機數都一樣 |
| tf.trunceated_normal( shape, mean=0, stddev=1.0) | 產生一個滿足正態分布的張量,當如果隨機數偏離平均值超過2個標準差以上,將會被重新分配一個隨機數 shape:必選,生成張量的形狀 mean:可選,正態分布的均值,默認為0. stddev:可選,正態分布的標準差,默認為1.0 |
| tf.random_uniform( shape, minval=low, maxval=high, dtype=tf.float32) | 產生一個滿足平均分布的張量 shape:必選,生成張量的形狀 mean:必選,產生值的最小值 stddev:必選,產生值的最大值 dtype:可選,產生值的類型,默認為float32 |
下面代碼分別用不用的方式產生變量
import tensorflow as tf #導入TensorFlow類庫,別名為tf
#產生一個符合正態分布的2行3列張量,均值為0,方差為1,隨機種子為1
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
#產生一個截斷的2行3列張量,均值為0,方差為1
w2 = tf.truncated_normal(shape=[2,3],mean=0,stddev=1)
#產生一個符合均勻分布的2行2列張量,最小值為1.0,最大值為2.0
w3 = tf.random_uniform((2,2),minval=1.0,maxval=2.0,dtype=tf.float32)
init_op = tf.global_variables_initializer()
#在會話中初始化計算圖中的所有變量
with tf.Session() as sess:sess.run(init_op)print("w1:",sess.run(w1))print("w2:",sess.run(w2))print("w3:",sess.run(w3))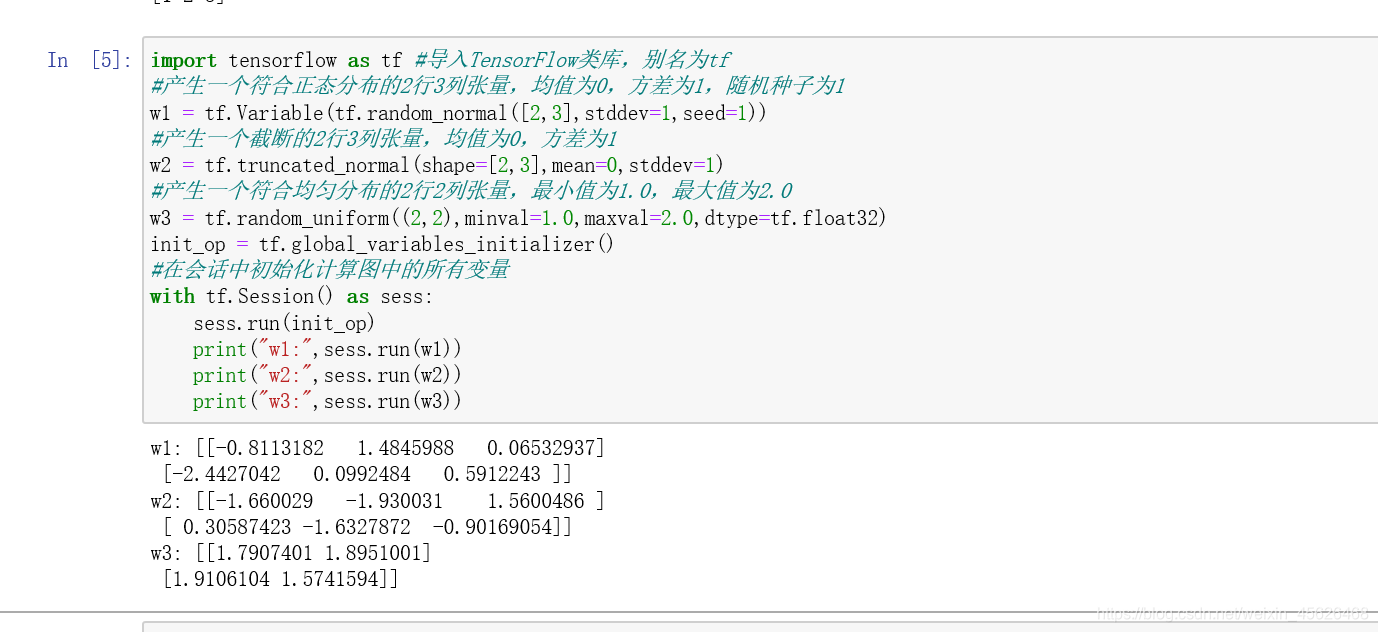
獲取變量
除了可使用tf.Variable()創建變量,還可以使用tf.get_variable()函數創建或獲取變量。
tf.get_variable()函數用于創建變量時,它和tf.Variable()的功能是等價的。
以下代碼給出了通過兩個函數創建變量的實例:
m = tf.Variable(tf.constant(1.0,shape=[1],name="m"))
n = tf.get_variable(shape=[1],name="n",initializer=tf.constant_initializer[1])
可以看出,tf.Variable()和tf.get_variable()創建變量的過程是一樣的,兩者最大的區別在于指定變量名稱的參數不同。
tf.Variable()函數中,變量名稱是可選參數;
tf.get_variable()函數中,變量名是必選參數,當變量名存在時,將直接獲取變量。
tf.get_variable()函數的語法格式如表
| 函數 | 說明 |
| tf.get_variable( name, shape, initializer ) | 用來初始化或獲取變量 name:變量的名稱,必填 shape:變量的形狀,必填 initializer:變量初始化的方法,選填 |
tf.get_variable()函數擁有一個變量檢查機制,會檢測已經存在的變量是否設置為共享變量。
如果未設置為共享變量,Tensorflow運行到第二個擁有相同名字變量的時候,就會拋出異常錯誤。
共享變量
tf.variable_scope()函數用來指定變量的作用域。
不同作用域中的變量可以有相同的命名,包括使用tf.get_variable()函數得到的變量以及tf.Variable()函數創建的變量。
tf.get_variable()常常會配合tf.variable_scope()一起使用,以實現變量共享。tf.variable_scope()函數會生成上下文管理器,并指定變量的作用域。
tf.variable_scope()里還有一個reuse = True 屬性,表示使用已經定義過的變量,這時tf.get_variable()不會創建新的變量,而是直接獲取已經創建好的變量。如果變量不存在,則會報錯。
下面代碼使用了變量共享的功能:
import tensorflow as tf
with tf.variable_scope("V1"):a1 = tf.get_variable(name = 'a1',shape = [1],initializer = tf.constant_initializer(1))
with tf.variable_scope("V2"):a2 = tf.get_variable(name = 'a1',shape = [1],initializer = tf.constant_initializer(1))
with tf.variable_scope("V2",reuse = True):a3 = tf.get_variable('a1')
with tf.Session() as sess:sess.run(tf.global_variables_initializer())print(a1.name)print(a2.name)print(a3.name)2-3行代碼:在V1變量空間中定義變量a1
4-5行代碼:在V2變量空間中定義變量a1。由于兩個a1位于不同的變量空間,所以不會產生沖突
6-7行代碼:重用V2命名空間的a1變量。調用tf.get_variable()時,會獲取V2命名空間的a1變量的值

?


)
)
)

)

)

)
)


)

)

)
