轉載:Python多進程抓取拉鉤網十萬數據
準備
安裝Mongodb數據庫
其實不是一定要使用MongoDB,大家完全可以使用MySQL或者Redis,全看大家喜好。這篇文章我們的例子是Mongodb,所以大家需要下載它。
在Windows中。由于MongoDB默認的數據目錄為C:datadb,建議大家直接在安裝的時候更改默認路徑為C:MongoDB.
然后創建如下目錄文件:
C:datalogmongod.log //用于存儲數據庫的日志
C:datadb //用于存儲數據庫數據
然后在C:MongoDB文件夾下(安裝 Mongodb 路徑)創建配置文件mongod.cfg。并且在配置文件里寫入以下配置:
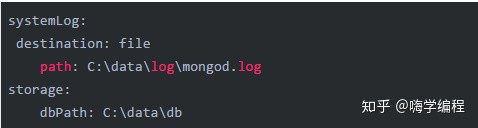
大家記住要打開文件后綴名,不然我們可能創建了一個mongod.cfg.txt文件。
最后我們需要打開管理員權限的 CMD 窗口,執行如下命令,安裝數據庫成服務:
"C:mongodbbinmongod.exe"--config "C:mongodbmongod.cfg"--install
設置為服務后,需要在管理員權限打開的windows cmd窗口用服務的方式啟動或停止MongoDB。
net start mongodb //啟動mongodb服務
net stop mongodb //關閉mongodb服務
好了,安裝好Mongodb數據庫后,我們需要安裝PyMongo,它是MongoDB的Python接口開發包。
pip install pymongo
推薦下我自己創建的Python學習交流群960410445
開始
準備完成后,我們就開始瀏覽拉勾網。我們可以發現拉勾網所有的招聘職位都在左側分類里。如圖:
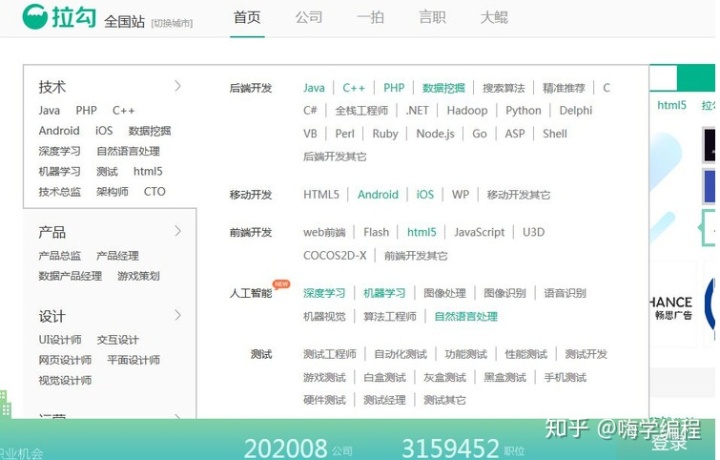
我們先獲取首頁HTML文件:
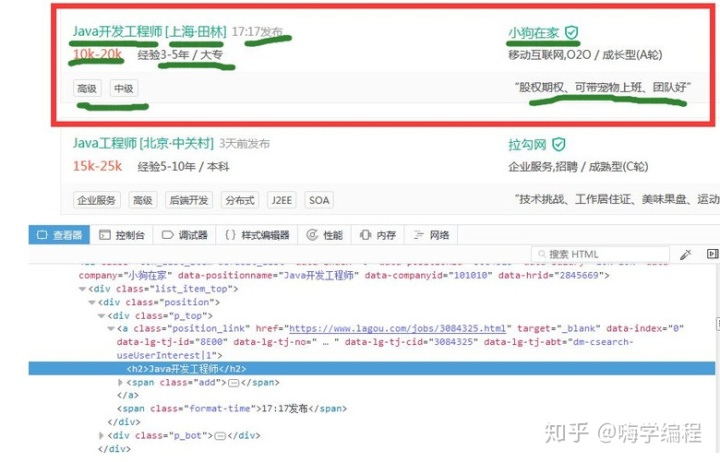
然后我們打開開發者工具,找到招聘職業的位置。
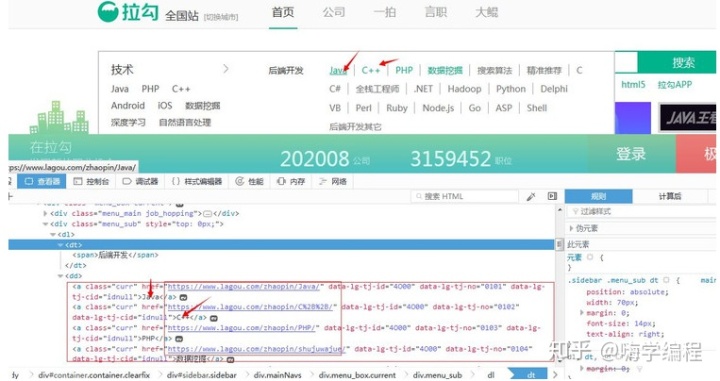
大家還記得BeautifulSoup的CSS選擇器吧,我們直接使用.select()方法獲取標簽信息。

輸出結果:
[<a class="curr"href="https://www.lagou.com/zhaopin/Java/"data-lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0101">Java</a>, <a class="curr"href="https://www.lagou.com/zhaopin/C%2B%2B/"data-lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0102">C++</a>, # ... 省略部分 https://www.lagou.com/zhaopin/fengxiankongzhizongjian/" data-lg-tj-cid="idnull" data-lg-tj-id="4U00" data-lg-tj-no="0404">風控總監, https://www.lagou.com/zhaopin/zongcaifuzongcai/" data-lg-tj-cid="idnull" data-lg-tj-id="4U00" data-lg-tj-no="0405">副總裁]
260
獲取到所有職位標簽的a標簽后,我們只需要提取標簽的href屬性和標簽內內容,就可以獲得到職位的招聘鏈接和招聘職位的名稱了。我們準備信息生成一個字典。方便我們后續程序的調用。
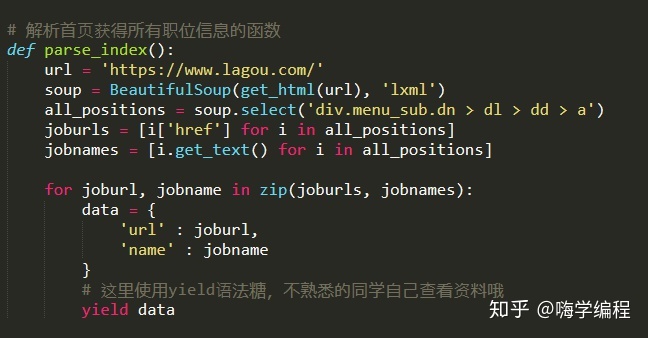
這里我們用zip函數,同時迭代兩個list。生成一個鍵值對。
接下來我們可以隨意點擊一個職位分類,分析招聘頁面的信息。
分頁
我們首先來分析下網站頁數信息。經過我的觀察,每個職位的招聘信息最多不超過 30 頁。也就是說,我們只要從第 1 頁循環到第 30 頁,就可以得到所有招聘信息了。但是也可以看到有的職位招聘信息,頁數并不到 30 頁。以下圖為例:
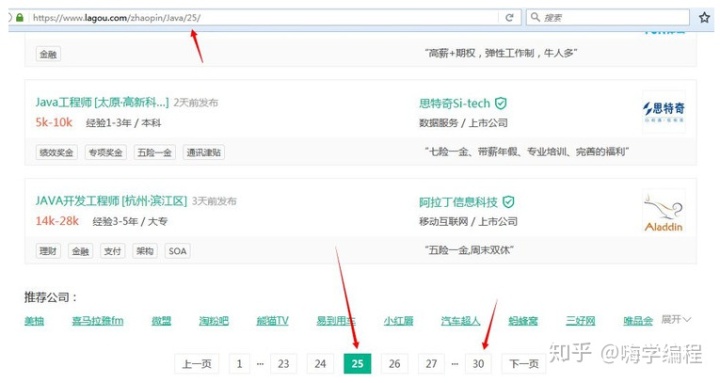
如果我們訪問頁面:https://www.lagou.com/zhaopin/Java/31/
也就是第 31 頁。我們會得到 404 頁面。所以我們需要在訪問到404頁面時進行過濾。
ifresp.status_code ==404:
pass
這樣我們就可以放心的 30 頁循環獲得每一頁招聘信息了。
我們的每一頁url使用format拼接出來:
link ='{}{}/'.format(url, str(pages))
獲取信息
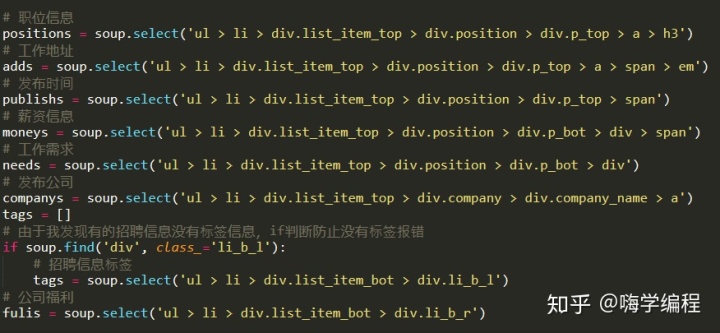
獲取到全部信息后,我們同樣的把他們組成鍵值對字典。
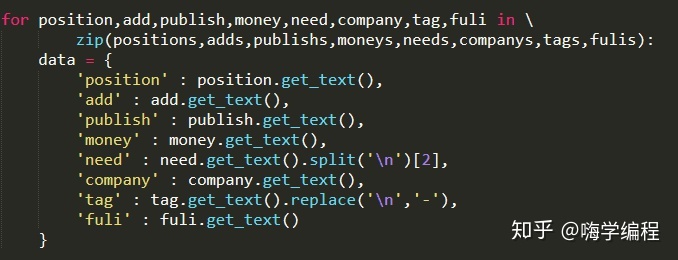
組成字典的目的是方便我們將全部信息保存到數據庫。
保存數據
保存數據庫前我們需要配置數據庫信息:
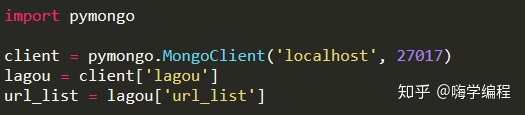
這里我們導入了pymongo庫,并且與MongoDB建立連接,這里是默認連接本地的MongoDB數據。創建并選擇一個數據庫lagou,并在這個數據庫中,創建一個table,即url_list。然后,我們進行數據的保存:
ifurl_list.insert_one(data):
print('保存數據庫成功', data)
如果保存成功,打印出成功信息。
多線程爬取
十萬多條數據是不是抓取的有點慢,有辦法,我們使用多進程同時抓取。由于Python的歷史遺留問題,多線程在Python中始終是個美麗的夢。
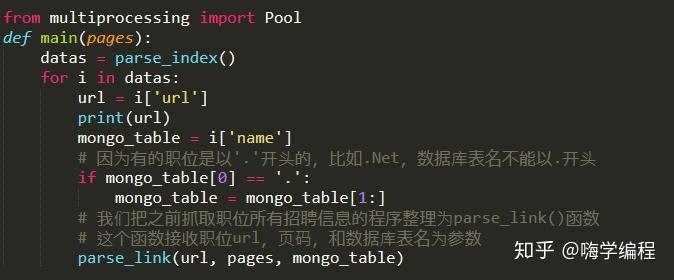
我們把之前提取職位招聘信息的代碼,寫成一個函數,方便我們調用。這里的parse_link()就是這個函數,他就收職位的 url 和所有頁數為參數。我們get_alllink_data()函數里面使用for循環 30 頁的數據。然后這個作為主函數傳給多進程內部調用。
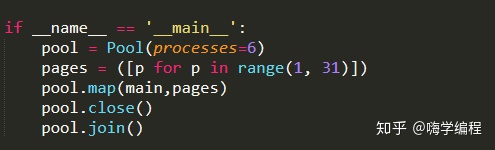
這里是一個pool進程池,我們調用進程池的map方法.
map(func, iterable[,chunksize=None])
多進程Pool類中的map方法,與Python內置的map函數用法行為基本一致。它會使進程阻塞,直到返回結果。需要注意,雖然第二個參數是一個迭代器,但在實際使用中,必須在整個隊列都就緒后,程序才會運行子進程。join()
方法等待子進程結束后再繼續往下運行,通常用于進程間的同步.
反爬蟲處理
如果大家就這樣整理完代碼,直接就開始抓取的話。相信在抓取的不久后就會出現程序中止不走了。我剛剛第一次中止后,我以為是網站限制了我的 ip。于是我做了如下改動。
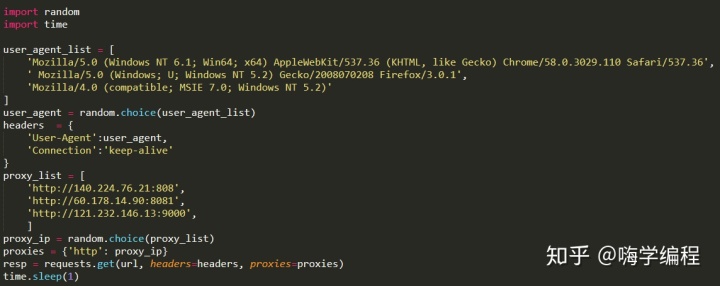







圖像可視化)
HashMap 源碼原理詳解)

![python計算執行時間的函數_[python] 統計函數運行時間](http://pic.xiahunao.cn/python計算執行時間的函數_[python] 統計函數運行時間)








