
前言
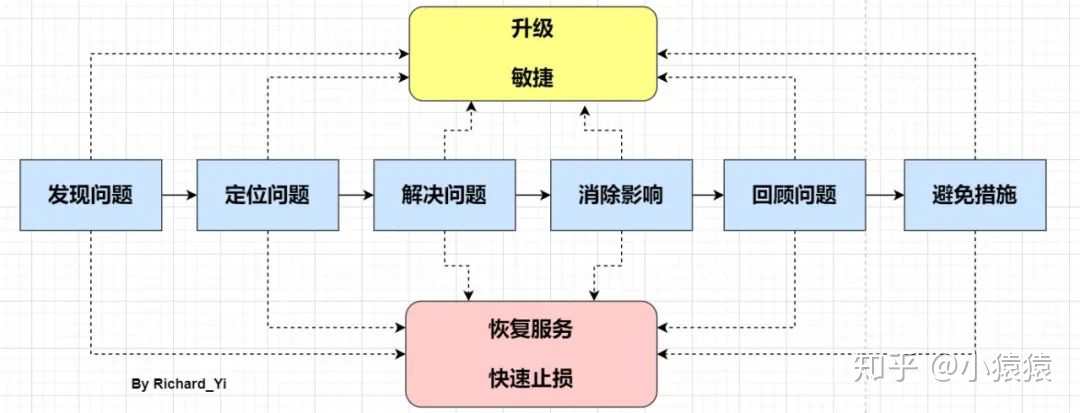
本文總結了一些常見的線上應急現象和對應排查步驟和工具。分享的主要目的是想讓對線上問題接觸少的同學有個預先認知,免得在遇到實際問題時手忙腳亂。畢竟作者自己也是從手忙腳亂時走過來的。
只不過這里先提示一下。在線上應急過程中要記住,只有一個總體目標:盡快恢復服務,消除影響。不管處于應急的哪個階段,我們首先必須想到的是恢復問題,恢復問題不一定能夠定位問題,也不一定有完美的解決方案,也許是通過經驗判斷,也許是預設開關等,但都可能讓我們達到快速恢復的目的,然后保留部分現場,再去定位問題、解決問題和復盤。
在大多數情況下,我們都是先優先恢復服務,保留下當時的異常信息(內存dump、線程dump、gc log等等,在緊急情況下甚至可以不用保留,等到事后去復現),等到服務正常,再去復盤問題。
好,現在讓我們進入正題吧。
常見現象:CPU 利用率高/飆升
場景預設:
監控系統突然告警,提示服務器負載異常。
預先說明:
CPU飆升只是一種現象,其中具體的問題可能有很多種,這里只是借這個現象切入。
注:CPU使用率是衡量系統繁忙程度的重要指標。但是CPU使用率的安全閾值是相對的,取決于你的系統的IO密集型還是計算密集型。一般計算密集型應用CPU使用率偏高load偏低,IO密集型相反。
常見原因:
- 頻繁 gc
- 死循環、線程阻塞、io wait...etc
模擬
這里為了演示,用一個最簡單的死循環來模擬CPU飆升的場景,下面是模擬代碼,
在一個最簡單的SpringBoot Web 項目中增加CpuReaper這個類,
/*** 模擬 cpu 飆升場景* @author Richard_yyf*/
@Component
public class CpuReaper {@PostConstructpublic void cpuReaper() {int num = 0;long start = System.currentTimeMillis() / 1000;while (true) {num = num + 1;if (num == Integer.MAX_VALUE) {System.out.println("reset");num = 0;}if ((System.currentTimeMillis() / 1000) - start > 1000) {return;}}}
}
打包成jar之后,在服務器上運行。java -jar cpu-reaper.jar &
第一步:定位出問題的線程
方法 a: 傳統的方法
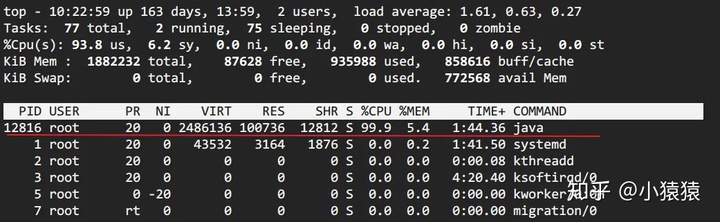
top定位CPU 最高的進程
執行top命令,查看所有進程占系統CPU的排序,定位是哪個進程搞的鬼。在本例中就是咱們的java進程。PID那一列就是進程號。(對指示符含義不清楚的見【附錄】)
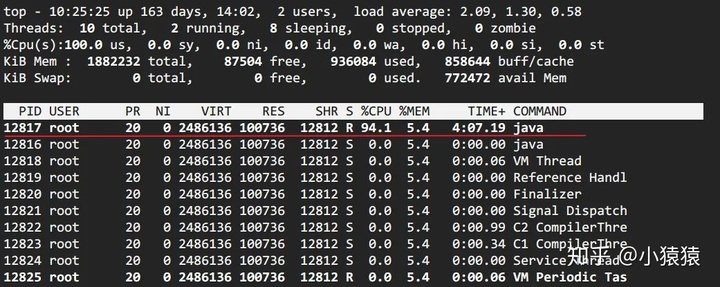
top -Hp pid定位使用 CPU 最高的線程
printf '0x%x' tid線程 id 轉化 16 進制
> printf '0x%x' 12817> 0x3211
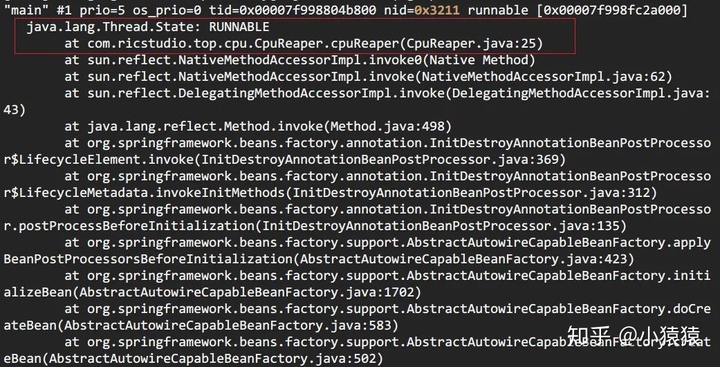
jstack pid | grep tid找到線程堆棧
> jstack 12816 | grep 0x3211 -A 30
方法 b: show-busy-java-threads
這個腳本來自于github上一個開源項目,項目提供了很多有用的腳本,show-busy-java-threads就是其中的一個。使用這個腳本,可以直接簡化方法A中的繁瑣步驟。如下,
> wget --no-check-certificate https://raw.github.com/oldratlee/useful-scripts/release-2.x/bin/show-busy-java-threads
> chmod +x show-busy-java-threads
> ./show-busy-java-threads
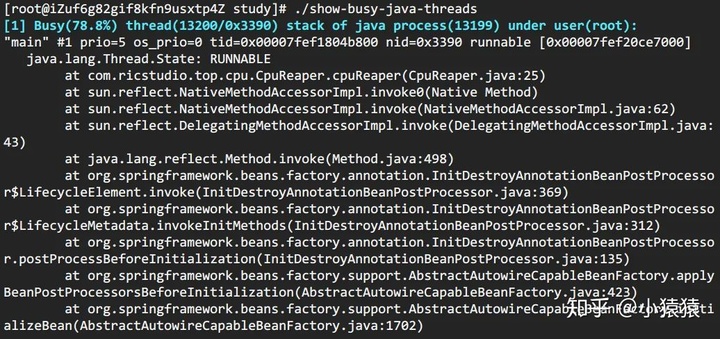
show-busy-java-threads
# 從所有運行的Java進程中找出最消耗CPU的線程(缺省5個),打印出其線程棧
# 缺省會自動從所有的Java進程中找出最消耗CPU的線程,這樣用更方便
# 當然你可以手動指定要分析的Java進程Id,以保證只會顯示你關心的那個Java進程的信息
show-busy-java-threads -p <指定的Java進程Id>show-busy-java-threads -c <要顯示的線程棧數>
方法 c: arthas thread
阿里開源的arthas現在已經幾乎包攬了我們線上排查問題的工作,提供了一個很完整的工具集。在這個場景中,也只需要一個thread -n命令即可。
> curl -O https://arthas.gitee.io/arthas-boot.jar # 下載
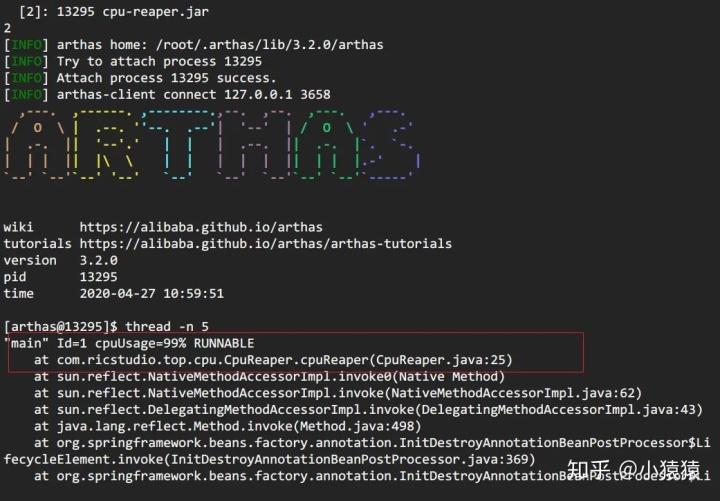
要注意的是,arthas的cpu占比,和前面兩種cpu占比統計方式不同。前面兩種針對的是Java進程啟動開始到現在的cpu占比情況,arthas這種是一段采樣間隔內,當前JVM里各個線程所占用的cpu時間占總cpu時間的百分比。
具體見官網:https://alibaba.github.io/arthas/thread.html
后續
通過第一步,找出有問題的代碼之后,觀察到線程棧之后。我們就要根據具體問題來具體分析。這里舉幾個例子。
情況一:發現使用CPU最高的都是GC 線程。
GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fd99001f800 nid=0x779 runnableGC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fd990021800 nid=0x77a runnable GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fd990023000 nid=0x77b runnable GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fd990025000 nid=0x77c runnabl
gc 排查的內容較多,所以我決定在后面單獨列一節講述。
情況二:發現使用CPU最高的是業務線程
- io wait
- 比如此例中,就是因為磁盤空間不夠導致的io阻塞
- 等待內核態鎖,如 synchronized
jstack -l pid | grep BLOCKED查看阻塞態線程堆棧- dump 線程棧,分析線程持鎖情況。
- arthas提供了
thread -b,可以找出當前阻塞其他線程的線程。針對 synchronized 情況
常見現象:頻繁 GC
1. 回顧GC流程
在了解下面內容之前,請先花點時間回顧一下GC的整個流程。

接前面的內容,這個情況下,我們自然而然想到去查看gc 的具體情況。
- 方法a : 查看gc 日志
- 方法b :
jstat -gcutil 進程號 統計間隔毫秒 統計次數(缺省代表一致統計 - 方法c : 如果所在公司有對應用進行監控的組件當然更方便(比如Prometheus + Grafana)
這里對開啟 gc log 進行補充說明。一個常常被討論的問題(慣性思維)是在生產環境中GC日志是否應該開啟。因為它所產生的開銷通常都非常有限,因此我的答案是需要開啟。但并不一定在啟動JVM時就必須指定GC日志參數。
HotSpot JVM有一類特別的參數叫做可管理的參數。對于這些參數,可以在運行時修改他們的值。我們這里所討論的所有參數以及以“PrintGC”開頭的參數都是可管理的參數。這樣在任何時候我們都可以開啟或是關閉GC日志。比如我們可以使用JDK自帶的jinfo工具來設置這些參數,或者是通過JMX客戶端調用HotSpotDiagnostic MXBean的setVMOption方法來設置這些參數。
這里再次大贊arthas??,它提供的vmoption命令可以直接查看,更新VM診斷相關的參數。
獲取到gc日志之后,可以上傳到GC easy幫助分析,得到可視化的圖表分析結果。
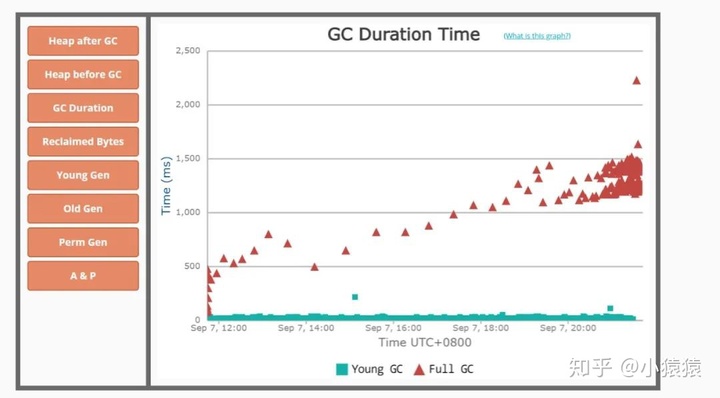
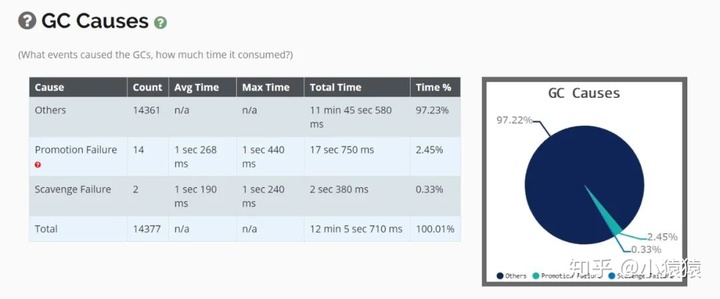
2. GC 原因及定位
prommotion failed
從S區晉升的對象在老年代也放不下導致 FullGC(fgc 回收無效則拋 OOM)。
可能原因:
- survivor 區太小,對象過早進入老年代
查看 SurvivorRatio 參數 - 大對象分配,沒有足夠的內存
dump 堆,profiler/MAT 分析對象占用情況 - old 區存在大量對象
dump 堆,profiler/MAT 分析對象占用情況
你也可以從full GC 的效果來推斷問題,正常情況下,一次full GC應該會回收大量內存,所以 正常的堆內存曲線應該是呈鋸齒形。如果你發現full gc 之后堆內存幾乎沒有下降,那么可以推斷:**堆中有大量不能回收的對象且在不停膨脹,使堆的使用占比超過full GC的觸發閾值,但又回收不掉,導致full GC一直執行。換句話來說,可能是內存泄露了。
一般來說,GC相關的異常推斷都需要涉及到內存分析,使用jmap之類的工具dump出內存快照(或者 Arthas的heapdump)命令,然后使用MAT、JProfiler、JVisualVM等可視化內存分析工具。
至于內存分析之后的步驟,就需要小伙伴們根據具體問題具體分析啦。
常見現象:線程池異常
場景預設:
業務監控突然告警,或者外部反饋提示大量請求執行失敗。
異常說明:
Java 線程池以有界隊列的線程池為例,當新任務提交時,如果運行的線程少于 corePoolSize,則創建新線程來處理請求。如果正在運行的線程數等于 corePoolSize 時,則新任務被添加到隊列中,直到隊列滿。當隊列滿了后,會繼續開辟新線程來處理任務,但不超過 maximumPoolSize。當任務隊列滿了并且已開辟了最大線程數,此時又來了新任務,ThreadPoolExecutor 會拒絕服務。
常見問題和原因
這種線程池異常,一般可以通過開發查看日志查出原因,有以下幾種原因:
- 下游服務 響應時間(RT)過長
這種情況有可能是因為下游服務異常導致的,作為消費者我們要設置合適的超時時間和熔斷降級機制。
另外針對這種情況,一般都要有對應的監控機制:比如日志監控、metrics監控告警等,不要等到目標用戶感覺到異常,從外部反映進來問題才去看日志查。 - 數據庫慢 sql 或者數據庫死鎖
查看日志中相關的關鍵詞。
- Java 代碼死鎖
jstack –l pid | grep -i –E 'BLOCKED | deadlock'
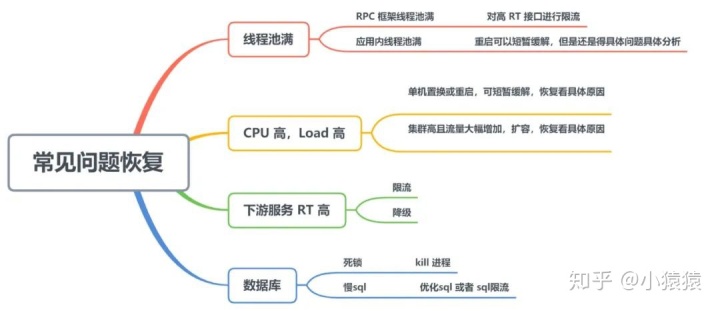
四、常見問題恢復
這一部分內容參考自此篇文章
對于上文提到的一些問題,這里總結了一些恢復的方法。
五、Arthas
這里還是想單獨用一節安利一下Arthas這個工具。
Arthas 是阿里巴巴開源的Java 診斷工具,基于 Java Agent 方式,使用 Instrumentation 方式修改字節碼方式進行 Java 應用診斷。
- dashboard :系統實時數據面板, 可查看線程,內存,gc 等信息
- thread :查看當前線程信息,查看線程的堆棧,如查看最繁忙的前 n 線程
- getstatic:獲取靜態屬性值,如
getstatic className attrName可用于查看線上開關真實值 - sc:查看 jvm 已加載類信息,可用于排查 jar 包沖突
- sm:查看 jvm 已加載類的方法信息
- jad:反編譯 jvm 加載類信息,排查代碼邏輯沒執行原因
- logger:查看logger信息,更新logger level
- watch:觀測方法執行數據,包含出參、入參、異常等
- trace:方法內部調用時長,并輸出每個節點的耗時,用于性能分析
- tt:用于記錄方法,并做回放
以上內容節選自Arthas官方文檔。
另外,Arthas里的 還集成了 ognl 這個輕量級的表達式引擎,通過ognl,你可以用arthas 實現很多的“騷”操作。
其他的這里就不多說了,感興趣的可以去看看arthas的官方文檔、github issue。
六、涉及工具
再說下一些工具。
- Arthas
- useful-scripts
- GC easy
- Smart Java thread dump analyzer - thread dump analysis in seconds
- PerfMa - Java虛擬機參數/線程dump/內存dump分析
- Linux 命令
- Java N 板斧
- MAT、JProfiler...等可視化內存分析工具
參考
- https://developer.aliyun.com/article/757655
- Arthas 3.2.0 文檔
- 《分布式服務架構:原理、設計與實戰》
附錄
top 命令顯示的指示符的含義
指示符含義PID進程idUSER進程所有者PR進程優先級NInice值。負值表示高優先級,正值表示低優先級VIRT進程使用的虛擬內存總量,單位kb。VIRT=SWAP+RESRES進程使用的、未被換出的物理內存大小,單位kb。RES=CODE+DATASHR共享內存大小,單位kbS進程狀態。D=不可中斷的睡眠狀態 R=運行 S=睡眠 T=跟蹤/停止 Z=僵尸進程%CPU上次更新到現在的CPU時間占用百分比%MEM進程使用的物理內存百分比TIME+進程使用的CPU時間總計,單位1/100秒COMMAND進程名稱(命令名/命令行)
來源 | https://ricstudio.top/archives/java-online-question-probe
版權申明:內容來源網絡,版權歸原創者所有。除非無法確認,我們都會標明作者及出處,如有侵權煩請告知,我們會立即刪除并表示歉意。謝謝














這么慢?)

)



