RDD中的所有轉換(Transformation)算子都是延遲加載的,也就是說,它們并不會直接計算結果。相反的,它們只是記住這些應用到基礎數據集(例如一個文件)上的轉換動作。只有當發生一個要求返回結果給Driver的動作時,這些轉換才會真正運行。這種設計讓Spark更加有效率地運行。
常用Transformation類算子列表
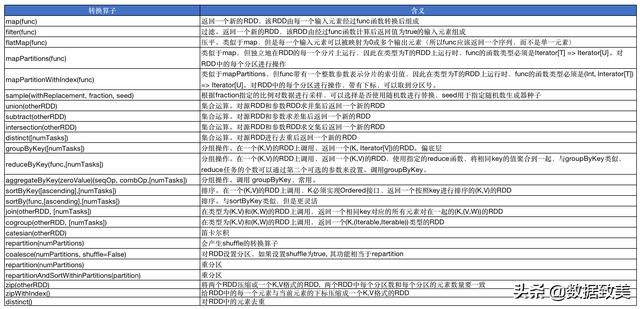
常用Transformation類算子列表
常用Transformation類算子實例
- map(func): 返回一個新的RDD,該RDD由每一個輸入元素經過func函數轉換后組成, map操作是一對一操作,每進去一個元素,就出來一個元素
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8,9,10))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at :24# 對每個元素乘以10返回新的rdd2scala> val rdd2 = rdd1.map(_*10)rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at map at :25scala> rdd2.collectres1: Array[Int] = Array(10, 20, 30, 40, 50, 60, 70, 80, 90, 100)# 對每個元素拼接一個字符串,返回新的String類型的RDDscala> val rdd3 = rdd1.map(_+"@map.com")rdd3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at map at :25scala> rdd3.collectres3: Array[String] = Array(1@map.com, 2@map.com, 3@map.com, 4@map.com, 5@map.com, 6@map.com, 7@map.com, 8@map.com, 9@map.com, 10@map.com)- filter(func): 過濾。返回一個新的RDD,該RDD由經過func函數計算后返回值為true的輸入元素組成, RDD元素的類型不會改變。
scala> val rdd1 = sc.parallelize(Array("喬峰","段譽","虛竹","鳩摩智","達摩祖師"))rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at parallelize at :24# filter中為true的會被保留,會false的會被過濾scala> val rdd2 = rdd1.filter(!_.contains("摩"))rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at filter at :25scala> rdd2.collectres4: Array[String] = Array(喬峰, 段譽, 虛竹)- flatMap(func): 壓平。類似于map,但是每一個輸入元素可以被映射為0或多個輸出元素(所以func應該返回一個序列,而不是單一元素)
scala> val rdd1 = sc.parallelize(Array("say you say me say it together","good good study day day up"))rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at :24# 進去一條,出來多條,是一對多的轉換scala> val rdd2 = rdd1.flatMap(_.split(" "))rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[8] at flatMap at :25scala> rdd2.collectres5: Array[String] = Array(say, you, say, me, say, it, together, good, good, study, day, day, up)集合類Transformation算子實例
- union(otherRDD): 對源RDD和參數RDD求并集后返回一個新的RDD, 需要兩個RDD
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,5))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at :24scala> val rdd2 = sc.parallelize(Array(2,3,4,5,6))rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at :24# 求兩個RDD的并集scala> val rdd3 = rdd1.union(rdd2)rdd3: org.apache.spark.rdd.RDD[Int] = UnionRDD[11] at union at :27scala> rdd3.collectres6: Array[Int] = Array(1, 2, 3, 4, 5, 2, 3, 4, 5, 6)- subtract(otherRDD): 對源RDD和參數RDD求差集后返回一個新的RDD, 需要兩個RDD
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,5))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at :24scala> val rdd2 = sc.parallelize(Array(2,3,4,5,6))rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at :24scala> val rdd3 = rdd1.subtract(rdd2)rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[15] at subtract at :27# rdd1與rdd2的差集是"1"scala> rdd3.collectres7: Array[Int] = Array(1)# rdd2與rdd1的差集是"6"scala> val rdd4 = rdd2.subtract(rdd1)rdd4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[19] at subtract at :27scala> rdd4.collect()res8: Array[Int] = Array(6)- intersection(otherRDD): 對源RDD和參數RDD求交集后返回一個新的RDD, 需要有兩個RDD
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,5))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at :24scala> val rdd2 = sc.parallelize(Array(2,3,4,5,6))rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at :24# 求兩個RDD的交集返回新的RDDscala> val rdd3 = rdd1.intersection(rdd2)rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[25] at intersection at :27scala> rdd3.collect()res9: Array[Int] = Array(4, 3, 5, 2)- distinct(): 對源RDD進行去重后返回一個新的RDD, 只需要一個RDD
scala> val rdd1 = sc.parallelize(Array(1,1,1,2,2,2,3,3,3))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at parallelize at :24# 在一個RDD中實現去重功能scala> val rdd2 = rdd1.distinct()rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[29] at distinct at :25scala> rdd2.collect()res10: Array[Int] = Array(1, 3, 2)其底層的實現原理(如下面Java代碼所示)是:mapToPair+reduceByKey+mapToPair =>
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.*;import scala.Tuple2;import java.util.Arrays;import java.util.Iterator;/** * distinct: 對RDD中的元素去重 */public class distinctOperator { public static void main(String[] args) { SparkConf conf = new SparkConf() .setMaster("local") .setAppName("distinct"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setLogLevel("WARN"); JavaRDD rdd1 = sc.parallelize(Arrays.asList( "a", "a", "a", "a", "b", "b", "b", "b" )); /** * 傳統方式實現RDD元素去重需要三步 * 第一步:把RDD轉換成K,V格式的RDD, K為元素,V為1 * 每二步:對K,V格式的RDD的Key進行分組計算 * 第三步:對得到的RDD只取第一位鍵 */ // [(a,1),(a,1),(a,1),(a,1),(b,1),b,1),b,1),b,1)] JavaPairRDD mapToPairRDD = rdd1.mapToPair(new PairFunction() { @Override public Tuple2 call(String s) throws Exception { return new Tuple2(s, 1); } }); //對每個key進行聚合 //[(a,4),(b,4)] JavaPairRDD reduceRDD = mapToPairRDD.reduceByKey(new Function2() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); //只取鍵,不要值 JavaRDD mapRDD = reduceRDD.map(new Function, String>() { @Override public String call(Tuple2 tuple) throws Exception { return tuple._1; } }); mapRDD.foreach(new VoidFunction() { @Override public void call(String s) throws Exception { System.out.println(s); } }); System.out.println("-----------------------------------"); //使用Spark提供的算子distinct實現RDD元素去重 JavaRDD distinctRDD = rdd1.distinct(); distinctRDD.foreach(new VoidFunction() { @Override public void call(String s) throws Exception { System.out.println(s); } }); sc.stop(); }}分組類的轉換算子
groupByKey([numTasks]): 在一個(K,V)的RDD上調用,返回一個(K, Iterator[V])的RDD。偏底層scala> val rdd1 = sc.parallelize(List(("張軍",1000),("李軍",2500),("王軍",3000),("張軍",1500)))rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[30] at parallelize at :24scala> val rdd2 = rdd1.groupByKey()rdd2: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[31] at groupByKey at :25scala> rdd2.collect()res11: Array[(String, Iterable[Int])] = Array((王軍,CompactBuffer(3000)), (張軍,CompactBuffer(1000, 1500)), (李軍,CompactBuffer(2500)))- reduceByKey(func, [numTasks]): 在一個(K,V)的RDD上調用,返回一個(K,V)的RDD,使用指定的reduce函數,將相同key的值聚合到一起,與groupByKey類似,reduce任務的個數可以通過第二個可選的參數來設置。調用groupByKey。
scala> val rdd1 = sc.parallelize(Array(("red",10),("red",20),("red",30),("red",40),("red",50),("yellow",100),("yellow",100)))rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[32] at parallelize at :24# 按照key進行聚合操作scala> val rdd2 = rdd1.reduceByKey(_+_)rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[33] at reduceByKey at :25scala> rdd2.collect()res12: Array[(String, Int)] = Array((yellow,200), (red,150))- cogroup(otherRDD, [numTasks]): 在類型為(K,V)和(K,W)的RDD上調用,返回一個(K,(Iterable,Iterable))類型的RDD
scala> val rdd1 = sc.parallelize(Array(("張飛","丈八蛇矛"),("關羽","青龍偃月刀"),("呂布","方天畫戟")))rdd1: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[34] at parallelize at :24scala> val rdd2 = sc.parallelize(Array(("張飛",30),("關羽",35),("呂布",45),("劉備",42)))rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[35] at parallelize at :24scala> val rdd3=rdd1.cogroup(rdd2)rdd3: org.apache.spark.rdd.RDD[(String, (Iterable[String], Iterable[Int]))] = MapPartitionsRDD[37] at cogroup at :27scala> rdd3.collect()res13: Array[(String, (Iterable[String], Iterable[Int]))] = Array((呂布,(CompactBuffer(方天畫戟),CompactBuffer(45))), (關羽,(CompactBuffer(青龍偃月刀),CompactBuffer(35))), (張飛,(CompactBuffer(丈八蛇矛),CompactBuffer(30))), (劉備,(CompactBuffer(),CompactBuffer(42))))排序類Transformation算子
sortBy(func,[ascending], [numTasks]): 與sortByKey類似,但是更靈活scala> val rdd1=sc.parallelize(Array(10,9,8,7,4,6,5,3,1,2))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[38] at parallelize at :24scala> val rdd2=rdd1.sortBy(x=>x,true)rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[41] at sortBy at :25scala> rdd2.collect()res14: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)# K, V格式的RDDscala> val rdd1=sc.parallelize(Array(("張飛",30),("劉備",42),("關羽",32),("曹操",46),("公孫瓚",62)))rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[42] at parallelize at :24scala> val rdd2=rdd1.sortBy(tuple=>tuple._2, false)rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[45] at sortBy at :25scala> rdd2.collect()res15: Array[(String, Int)] = Array((公孫瓚,62), (曹操,46), (劉備,42), (關羽,32), (張飛,30))scala> val rdd1=sc.parallelize(Array(("張飛",30),("劉備",42),("關羽",32),("曹操",46),("公孫瓚",62)))rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[42] at parallelize at :24# 同樣對rdd1調用,需要進行轉換scala> val rdd2=rdd1.map(tuple=>tuple.swap).sortByKey(false).map(tuple=>tuple.swap)rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[48] at map at :25scala> rdd2.collect()res16: Array[(String, Int)] = Array((公孫瓚,62), (曹操,46), (劉備,42), (關羽,32), (張飛,30))高級類的轉換算子
- mapPartitionWithIndex(func): 類似于mapPartitions, 但是func帶有一個整數參數表示分片的索引值,因此在類型為T的RDD上運行時,func的函數類型必須是(Int, Iterator[T]) => Iterator[U]。其功能是對RDD中的每個分區進行操作,帶有索引下標,可以取到分區號。
- func: 接收兩個參數,第一個參數代表分區號,第二參數代表分區中的元素。
scala> val rdd1 = sc.parallelize(List("son1","son2","son3","son4","son5","son6","son7","son8","son9","son10","son11","son12"),4)rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at :24scala> val rdd2 = rdd1.mapPartitionsWithIndex((index, iter) => {iter.toList.map(x=> "【分區號為:"+index+", 值為:" + x+ "】").iterator})rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at mapPartitionsWithIndex at :25scala> rdd2.collect()res0: Array[String] = Array(【分區號為:0, 值為:son1】, 【分區號為:0, 值為:son2】, 【分區號為:0, 值為:son3】, 【分區號為:1, 值為:son4】, 【分區號為:1, 值為:son5】, 【分區號為:1, 值為:son6】, 【分區號為:2, 值為:son7】, 【分區號為:2, 值為:son8】, 【分區號為:2, 值為:son9】, 【分區號為:3, 值為:son10】, 【分區號為:3, 值為:son11】, 【分區號為:3, 值為:son12】)- aggregateByKey: 后面有單獨文章講解此算子
多屬性詳解)







判斷勝負)










