目錄
特征工程
一、特征提取
1、字典特征提取
2、文本特征提取
2.1 英文文本提取
2.2 中文文本提取
3、TF-IDF文本特征詞的重要程度特征提取
二、無量綱化-預處理
1?MinMaxScaler 歸一化
2?normalize歸一化
3?StandardScaler 標準化
三、特征降維
1、特征選擇
1.1?VarianceThreshold 低方差過濾特征選擇
1.2 主成份分析(PCA)
特征工程
????????就是對特征進行相關的處理,一般使用pandas來進行數據清洗和數據處理、使用sklearn來進行特征工程。特征工程是將任意數據(如文本或圖像)轉換為可用于機器學習的數字特征。
????????步驟:特征提取(dataframe類型不用)---- 無量綱化(預處理)---- 降維
API:
DictVectorizer 字典特征提取
CountVectorizer 文本特征提取
TfidfVectorizer TF-IDF文本特征詞的重要程度特征提取
MinMaxScaler 歸一化
StandardScaler 標準化
VarianceThreshold 底方差過濾降維
PCA 主成分分析降維一、特征提取
? ? ? ? 1、字典特征提取
? ? ? ? 稀疏矩陣:一個矩陣中大部分元素為零,只有少數元素是非零的矩陣。由于稀疏矩陣中零元素非常多,存儲和處理稀疏矩陣時,通常會采用特殊的存儲格式,以節省內存空間并提高計算效率
? ? ? ? 三元組表:一種稀疏矩陣類型數據,存儲非零元素的行索引、列索引和值:(行,列)值
? ? ? ? 非稀疏矩陣(稠密矩陣):是指矩陣中非零元素的數量與總元素數量相比接近或相等,也就是說矩陣中的大部分元素都是非零的。通常采用二維數組形式存儲
from sklearn.feature_extraction import DictVectorizer示例:
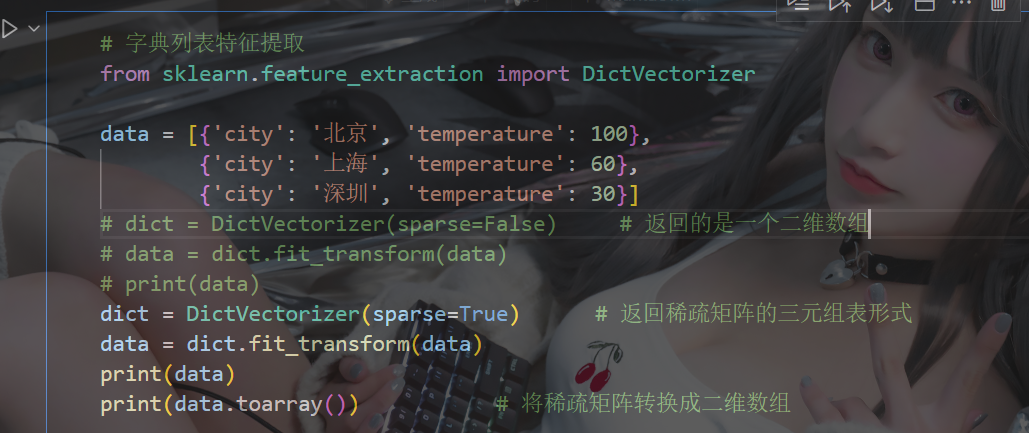
(稀疏矩陣對象調用toarray()函數, 得到類型為ndarray的二維稀疏矩陣 )
????????2、文本特征提取
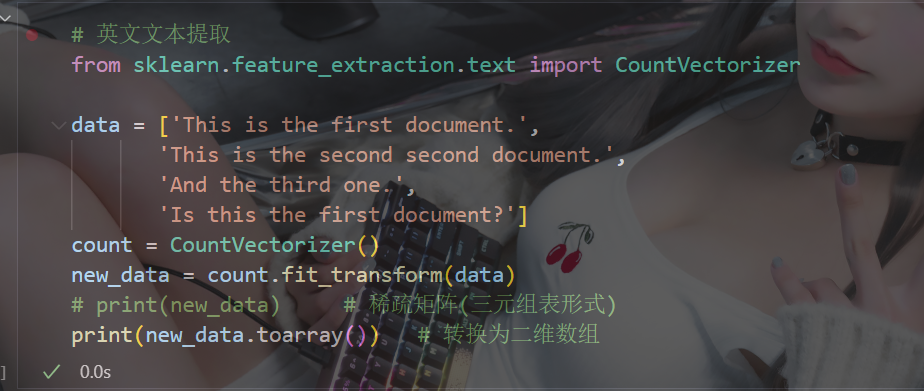
from sklearn.feature_extraction.text import CountVectorizer構造函數關鍵字參數stop_words,值為list,表示詞的黑名單(不提取的詞)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? fit_transform函數的返回值為稀疏矩陣
? ? ? ? 2.1 英文文本提取
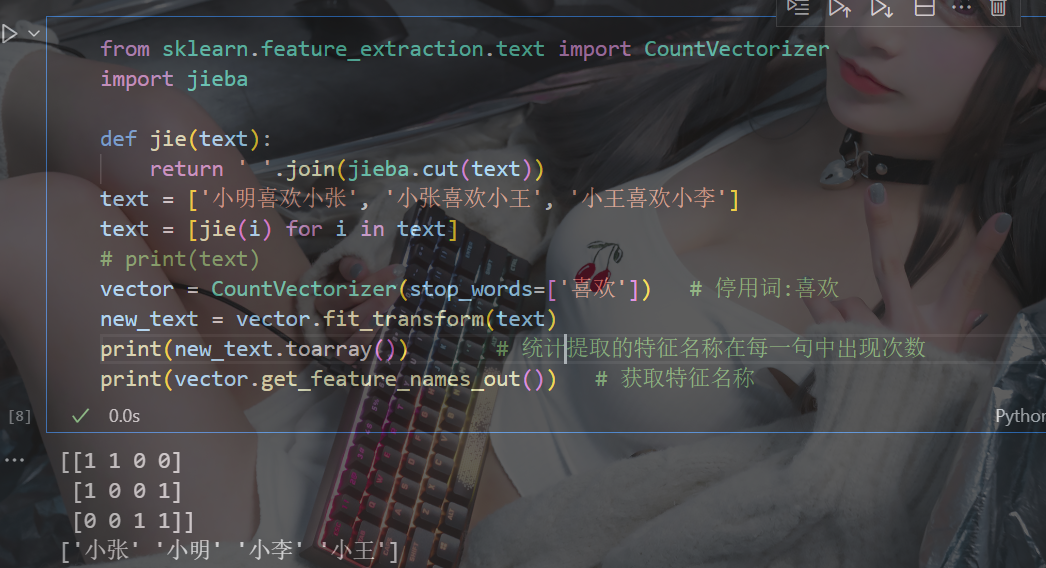
? ? ? ? 2.2 中文文本提取
????????中文文本不像英文文本,中文文本文字之間沒有空格,所以要先分詞,一般使用jieba分詞
# 下載jieba組件
pip install jieba示例:
? ? ? ? 3、TF-IDF文本特征詞的重要程度特征提取
from sklearn.feature_extraction.text import TfidfVectorizer詞頻(Term Frequency, TF), 表示一個詞在當前篇文章中的重要性
逆文檔頻率(Inverse Document Frequency, IDF), 反映了詞在整個文檔集合中的稀有程度

逆文檔頻率衡量一個詞的普遍重要性。如果一個詞在許多文檔中都出現,那么它的重要性就會降低。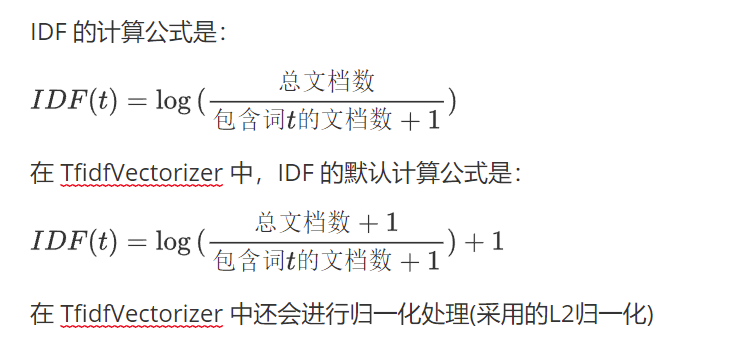
代碼與CountVectorizer的示例基本相同,僅僅把CountVectorizer改為TfidfVectorizer即可,繼續上面中文文本提取的示例修改(把三段文字分別看成三份文檔)
(這里方便對比數據,用的pandas做了個表)
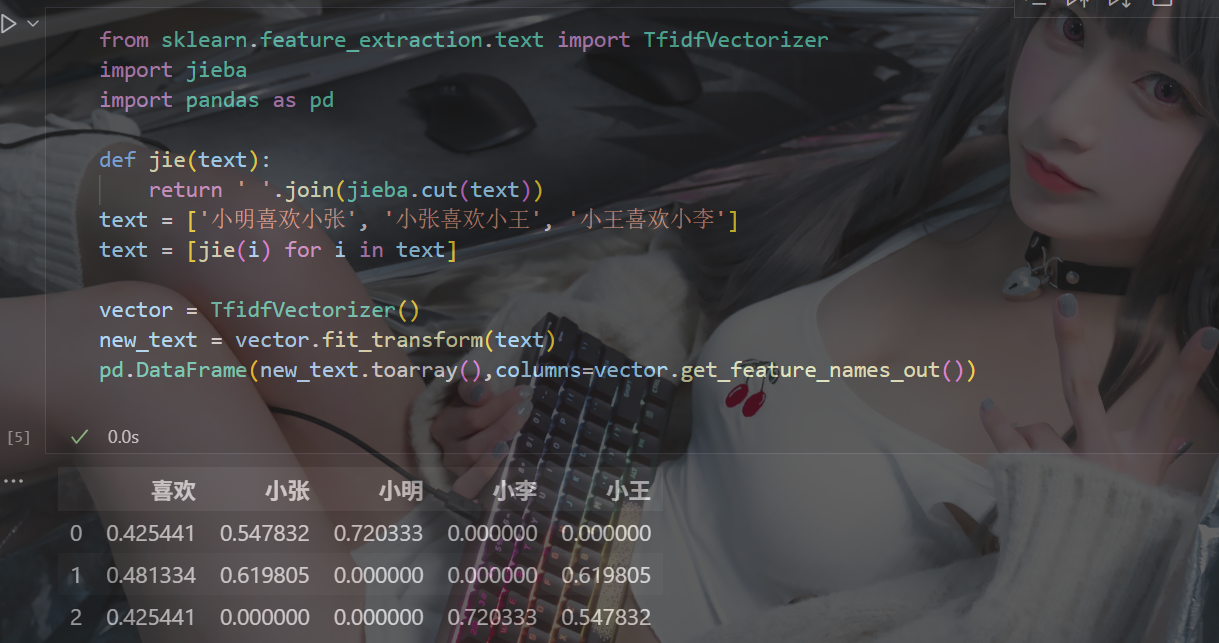
根據輸出結果可以看到,明明 “喜歡” 出現次數最多,反而在每一篇的重要性偏低,這是為什么?
這里要注意,TF-IDF 的核心假設:一個詞如果在很多文檔都出現,那它對區分文檔就沒有什么價值。IDF 的作用是抑制全局高頻詞的影響,以突出在某些文檔中特有的、有區分度的詞。
所以,“喜歡” 在每一份文檔中都出現了,它的重要性反而比較低,“小明” 只在第一篇中出現過,所以 “小明” 在第一篇中的重要性很高
由此可見,TF-IDF有著嚴重的局限性,一定要注意其符不符合使用場景,誤傷高頻關鍵詞!!
二、無量綱化-預處理
????????無量綱,即沒有單位的數據,無量綱化包括"歸一化"和"標準化", 為什么要進行無量綱化呢?
是為了去掉單位影響,提取本質參數,讓方程、數據或現象在數值計算和理論分析中更簡單、更穩定、更有可比性
????????1?MinMaxScaler 歸一化
from sklearn.preprocessing import MinMaxScaler????????通過對原始數據進行變換把數據映射到指定區間(默認為0-1)
? ? ? ? 歸一化公式是:![]()
示例:
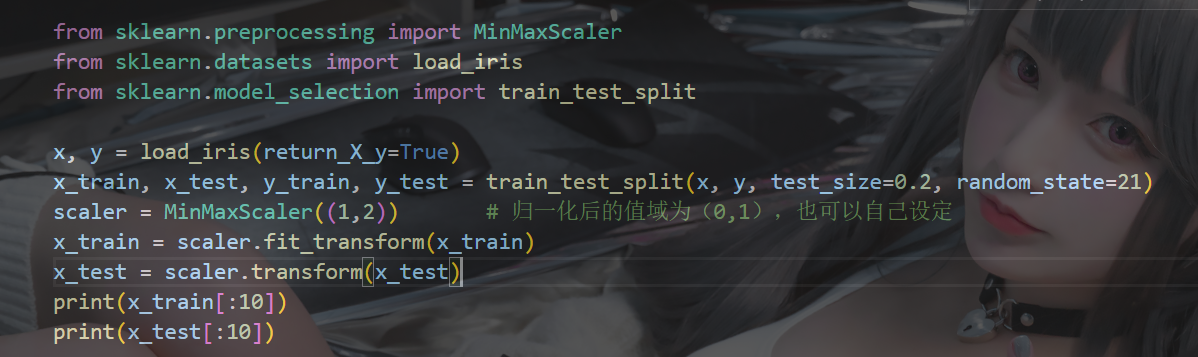
(缺點:最大值和最小值容易受到影響,所以魯棒性較差,常使用標準化的無量綱化 )
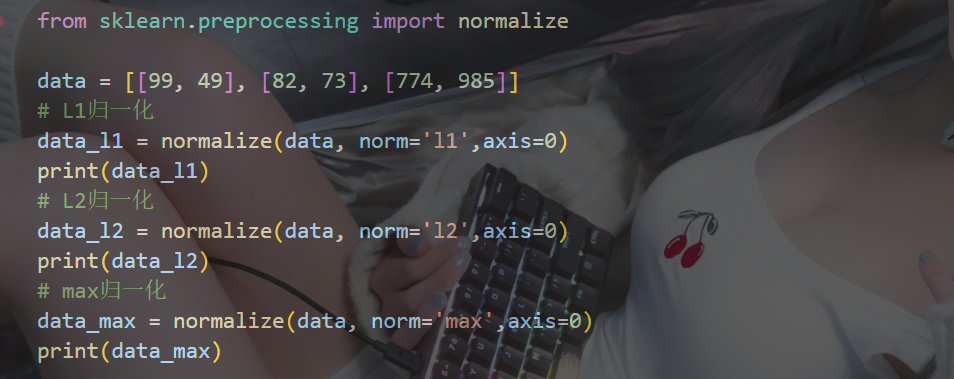
? ? ? ? 2?normalize歸一化
from sklearn.preprocessing import normalize
normalize(data, norm='l2', axis=1)
# data是要歸一化的數據
# norm是使用那種歸一化:"l1" "l2" "max"
# axis=0是列 axis=1是行????????normalize 歸一化主要指把數據按某種規則縮放到一個統一的尺度(常見是 0~1 或者向量長度為 1),以減少量綱和數值范圍對計算的影響
L1:絕對值相加作為分母,,特征值作為分子
L2:平方相加作為分母,特征值作為分子
max:max作為分母,特征值作為分子
示例:
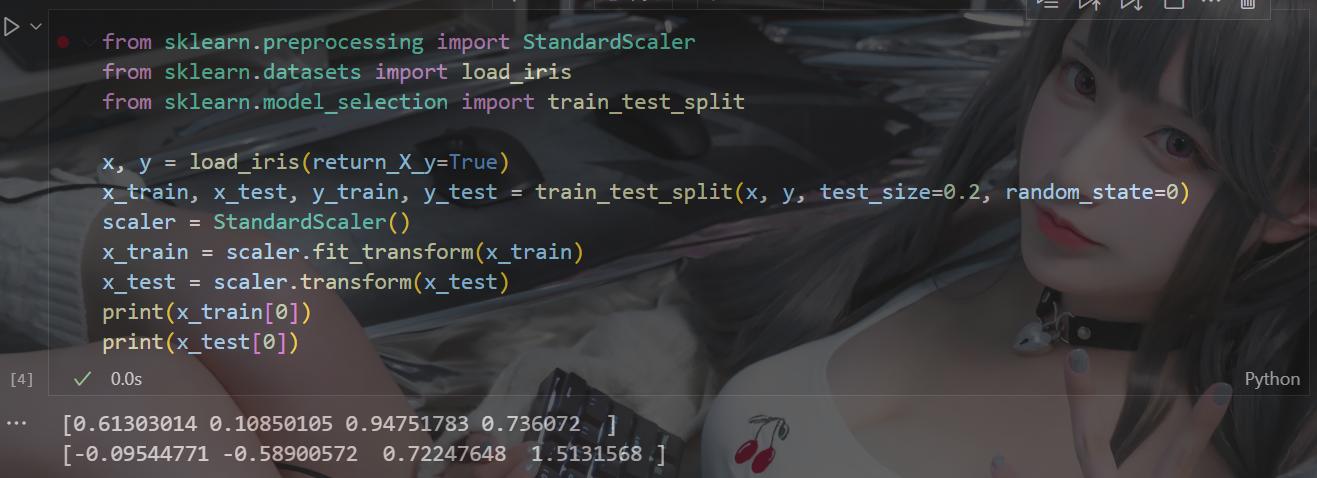
? ? ? ? 3?StandardScaler 標準化
from sklearn.preprocessing import StandardScale在機器學習中,標準化是一種數據預處理技術,也稱為數據歸一化或特征縮放。它的目的是將不同特征的數值范圍縮放到統一的標準范圍,以便更好地適應一些機器學習算法,特別是那些對輸入數據的尺度敏感的算法
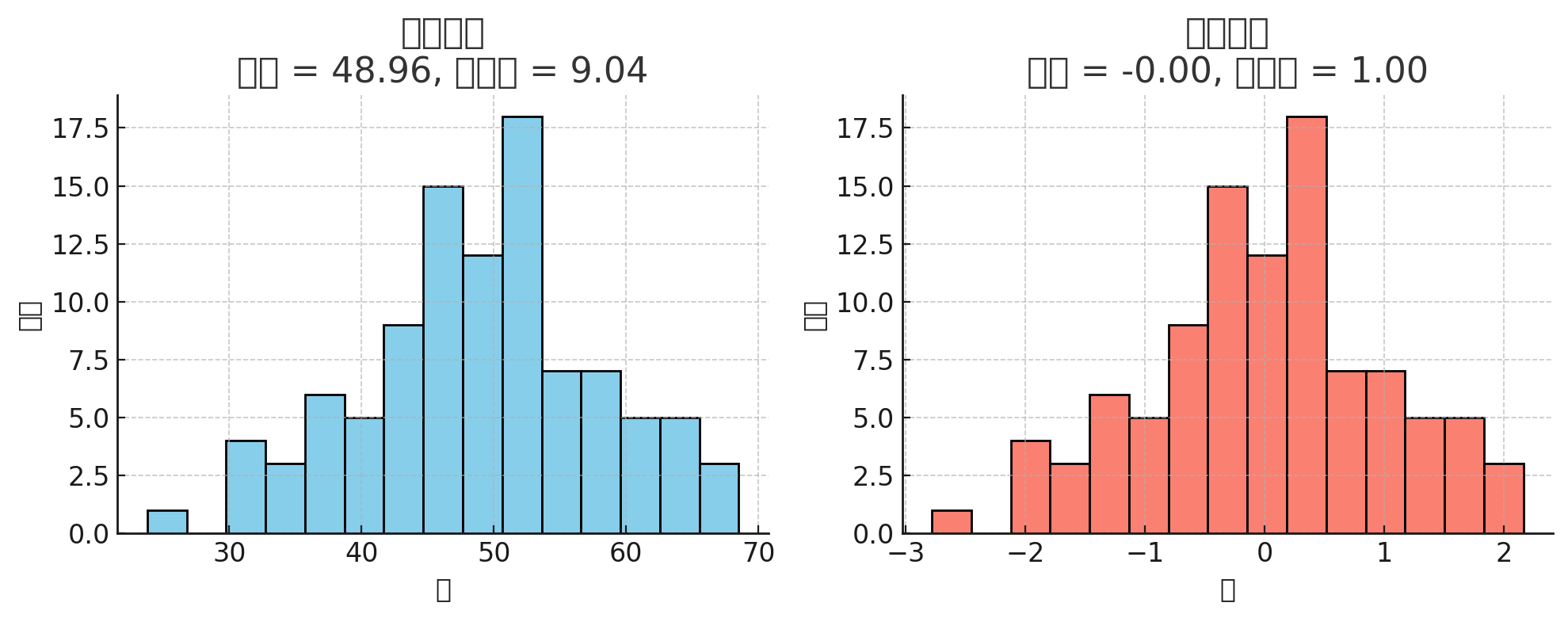
這是標準化前后分布的對比圖:左邊是原始數據(均值 50,標準差 10),右邊是 StandardScaler 標準化后(均值變成 0,標準差變成 1)。就是把左邊的分布“平移+縮放”成右邊的形狀
三、特征降維
????????實際數據中,有時候特征很多,會增加計算量,降維就是去掉一些特征,或者轉化多個特征為少量個特征,特征降維其目的:是減少數據集的維度,同時盡可能保留數據的重要信息。
????????1、特征選擇
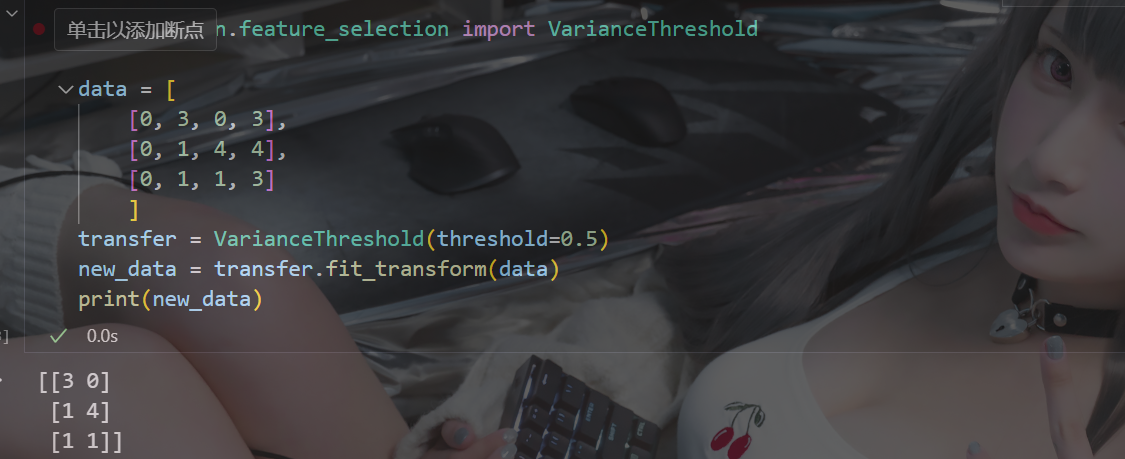
? ? ? ? 1.1?VarianceThreshold 低方差過濾特征選擇
from sklearn.feature_selection import VarianceThreshold????????如果一個特征的方差很小,說明這個特征的值在樣本中幾乎相同或變化不大,包含的信息量很少,模型很難通過該特征區分不同的對象
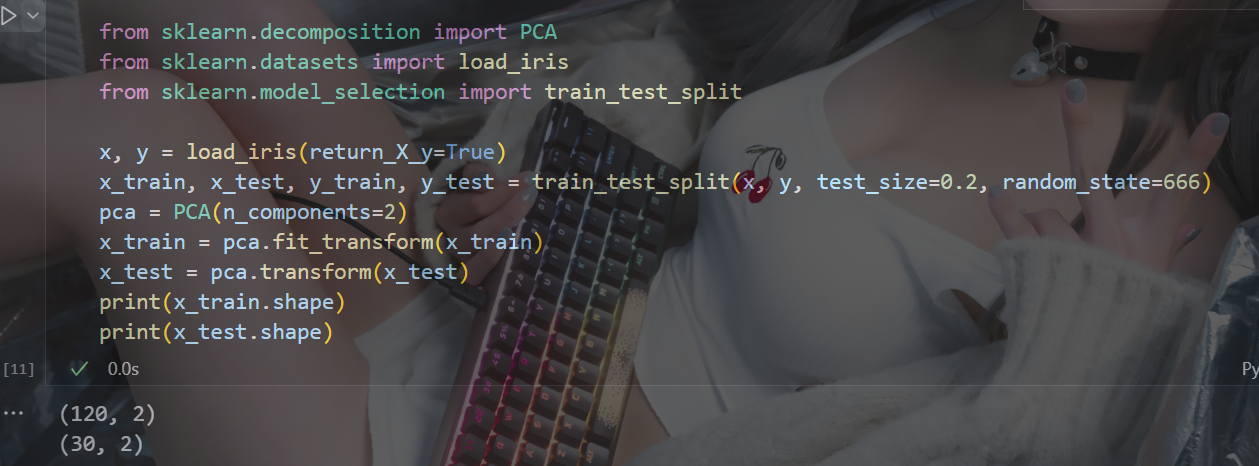
? ? ? ? 1.2 主成份分析(PCA)
from sklearn.decomposition import PCA
PCA(n_components=None)n_components:實參為小數時:表示降維后保留百分之多少的信息實參為整數時:表示減少到多少特征????????PCA的核心目標是從原始特征空間中找到一個新的坐標系統,使得數據在新坐標軸上的投影能夠最大程度地保留數據的方差,同時減少數據的維度


)



:I2C總線的傳輸速率與上拉電阻有什么關系?)





用戶的區別)




)

