1 K-means算法
K-means是最普及的聚類算法,算法接受一個未標記的數據集,然后將數據聚類成不同的組。
它是一個迭代算法,假設我們想要將數據聚類成 n 個組,其方法為:
- 選擇K個隨機的點,稱為聚類中心
- 對于數據集中的每一個數據,按照距離K個中心點的距離,將其與距離最近的中心點關聯起來,與同一個中心點關聯的所有點聚成一類
- 計算每一類的平均值,將該類所關聯的中心點移動到平均值的位置
- 重復步驟2-3,直至中心點不再變化
偽代碼表示為:
Repeat {
for i = 1 to m
c(i) := 當前樣本x(i)與k個聚類中心中距離最近的索引 index (form 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk := k聚類中樣本的均值,即聚類中心 average (mean) of points assigned to cluster k
}1.1 優化目標
用μ^1,μ^2,...,μ^k 來表示聚類中心,用c^(1),c^(2),...,c^(m)來存儲與第i個實例數據最近的聚類中心的索引,μ_(c^(i))表示當前樣本x^(i)所處的簇中心,其代價函數與優化目標如下圖所示

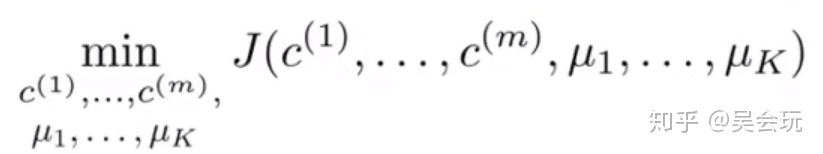
由上圖可知,K-means算法的優化目標即是找出使得代價函數最小的c^(i)和μ^(i)
1.2 隨機初始化
在運行 K-均值算法之前,首先要隨機初始化所有的聚類中心點
1. 選擇K<m,即聚類中心點的個數要小于所有訓練集實例的數量
2. 隨機選擇K個訓練實例(x^(i)),然后令K個聚類中心分別與這K個訓練示例相等
K-means的一個問題為,他有可能會停留在一個局部最小值處,解決這個問題的方法如下:
多次運行 K-均值算法,每一次都重新進行隨機初始化,最后再比較多次運行 K-means的結果,選擇代價函數最小的結果。
這種方法在 較小的時候(2-10)還是可行的,但是如果 較大,這么做也可能不會有明顯地改善。
1.3 選擇聚類數
一個是肘部法則,不斷改變K值,計算每一個K的代價,如下圖左所示,如若出現了一個類似于肘關節的拐點的話,那么就采用該K值,但如果像下圖右所示,是較為光滑的曲線的話,就不能用肘部法則去選擇K值。
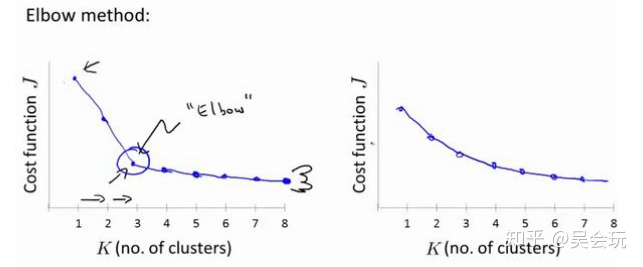
大多數情況下聚類個數都是根據各訓練示例可視化之后手動選擇的
2 實現方法
2.1 將各樣本點分簇
def find_closest_centroids(X, centroids):m = X.shape[0]k = centroids.shape[0]idx = np.zeros(m) # idx[i]為距離樣本i最近的集聚中心的索引for i in range(m):min_dist = 1000000 #每計算完一個樣本點后需要將最短距重新初始化 for j in range(k):dist = np.sum((X[i,:] - centroids[j,:]) ** 2) #代價函數if dist < min_dist:min_dist = distidx[i] = jreturn idx2.2 計算各簇的所有樣本的平均值
def compute_centroids(X, idx, k): #k為聚類中心個數m, n = X.shape centroids = np.zeros((k, n)) #聚類中心為(k,n)for i in range(k):indices = np.where(idx == i) #為i簇的各樣本點的索引centroids[i,:] = (np.sum(X[indices,:], axis=1) / len(indices[0])).ravel() #len(indices[0])為樣本點的數量,axis=1為按列相加 return centroid2.3 隨機初始化
def init_centroids(X, k):m, n = X.shapecentroids = np.zeros((k, n))idx = np.random.randint(0, m, k)for i in range(k):centroids[i,:] = X[idx[i],:] #隨機選擇訓練示例作為聚類中心return centroids2.4 聚類算法實現
def run_k_means(X, initial_centroids, max_iters):m, n = X.shapek = initial_centroids.shape[0]idx = np.zeros(m)centroids = initial_centroidsfor i in range(max_iters):idx = find_closest_centroids(X, centroids)centroids = compute_centroids(X, idx, k)return idx, centroids# 使用sklearn實現
from sklearn.cluster import KMeans #導入kmeans庫model = KMeans(n_clusters=16, n_init=100, n_jobs=-1)
model.fit(data) #用數據擬合分類器模型
centroids = model.cluster_centers_
C = model.predict(data) #輸出輸入數據的預測結果筆記參考資料:fengdu78/Coursera-ML-AndrewNg-Notes: 吳恩達老師的機器學習課程個人筆記
判斷勝負)


















