背景
最近在這家公司做了一些事情,做的事情和以往的工作不太一樣,不一樣的點呢就是 之前我主要的工作是關注計算這方面,因為數據量大,研究的是怎么加速查詢,怎么研究規則去優化,怎么去解規則的bug等等。因為現在業務的不同,每次獲取的數據量比較小,更加關注的索引效率,計算方面可能只是一些簡單的SUM AVG等。
接下來談談我對這個計算存儲引擎的理解與認知:
什么是SQL計算存儲引擎
SQL計算存儲引擎是利用SQL的能力進行計算,而用戶無需擔心后臺計算的細節,而且計算需要用到的數據都是在這個計算存儲引擎里。
它包括兩個部分,一個是計算部分:包括SQL解析,SQL優化,SQL執行; 一個是存儲部分,包括數據格式的存儲,數據的獲取。
SQL計算以及優化
如果單純從計算的角度來說話的,這類的引擎典型的有 Spark離線引擎,Flink實時引擎,presto adhoc引擎, 這種不關心數據的存儲,也就是說這類沒有存儲能力。這種往往在運行的時候,是從遠端拉取數據,拉數據數據來以后再進行計算。
從大的方面來說,SQL計算引擎 一般會包括任務調度和SQL計算。
任務調度
任務調度的模式一般包括 Spark 的 StageByStage 調度模式 和Flink 的 AllAtOnce 調度模式。
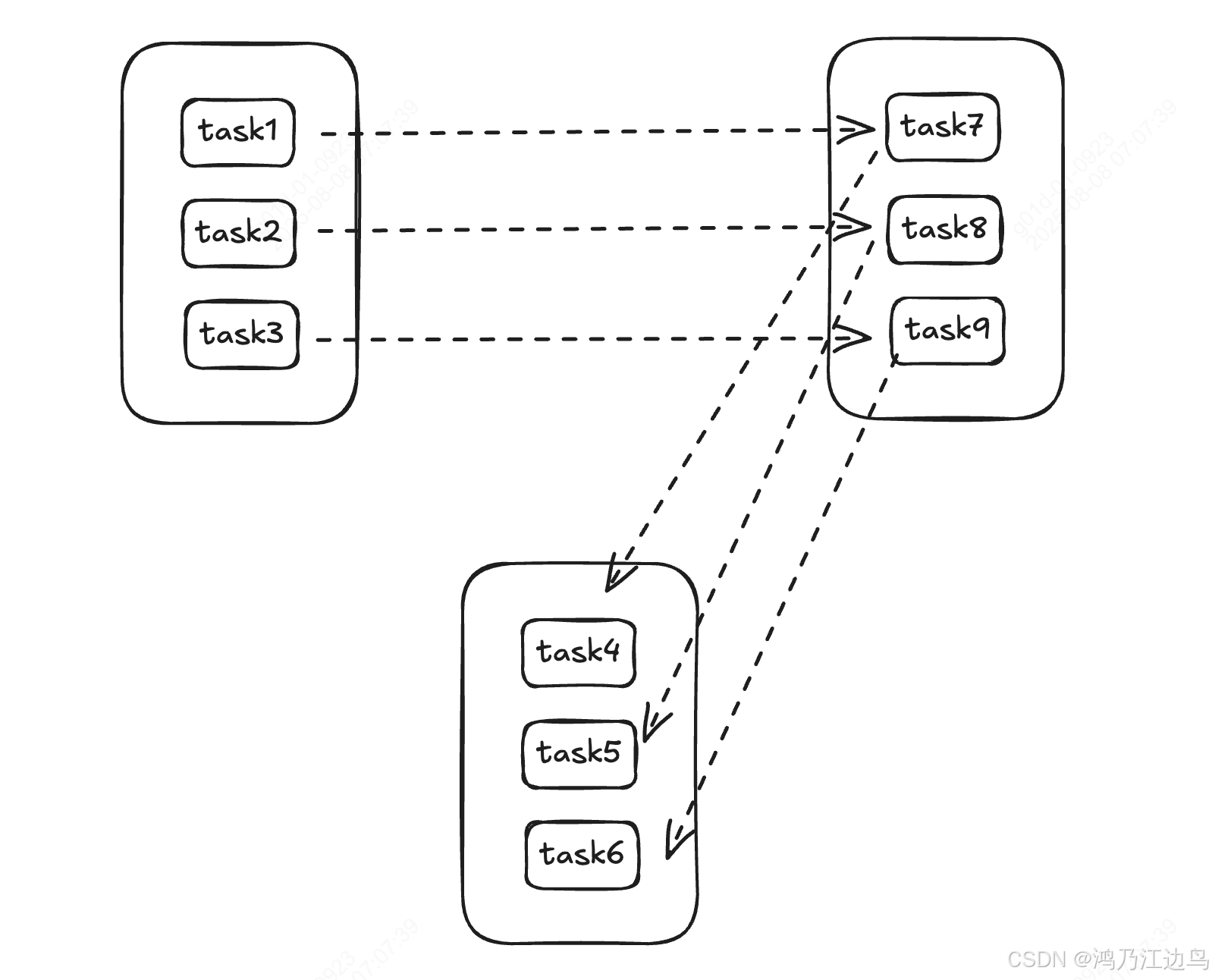
第一種模式:stageByStage, 這種是典型的離線調度模型,這種調度模型的運行方式為 一組任務按照Stage的方式進行組織,只有上一個Stage的所有Task運行完了以后下一個Stage才能繼續執行,這種方式的好處是任務的失敗的容錯性高,因為stage與stage之間的數據交互會進行暫存,一個任務或者stage的失敗,可以繼續從容錯點恢復重試執行。而且這種方式可以充分利用數據的親和性,也就是說,下游stage的任務可以依賴上游任務的分布情況來進行調度,比如說把下游Task調度到上游Task運行的節點上,這樣一來,就無須再進行遠程數據的拉取,直接從本地讀取數據,可以減少數據的拉取時間.
這種模式下,任務的調度和執行是穿插在一起的。
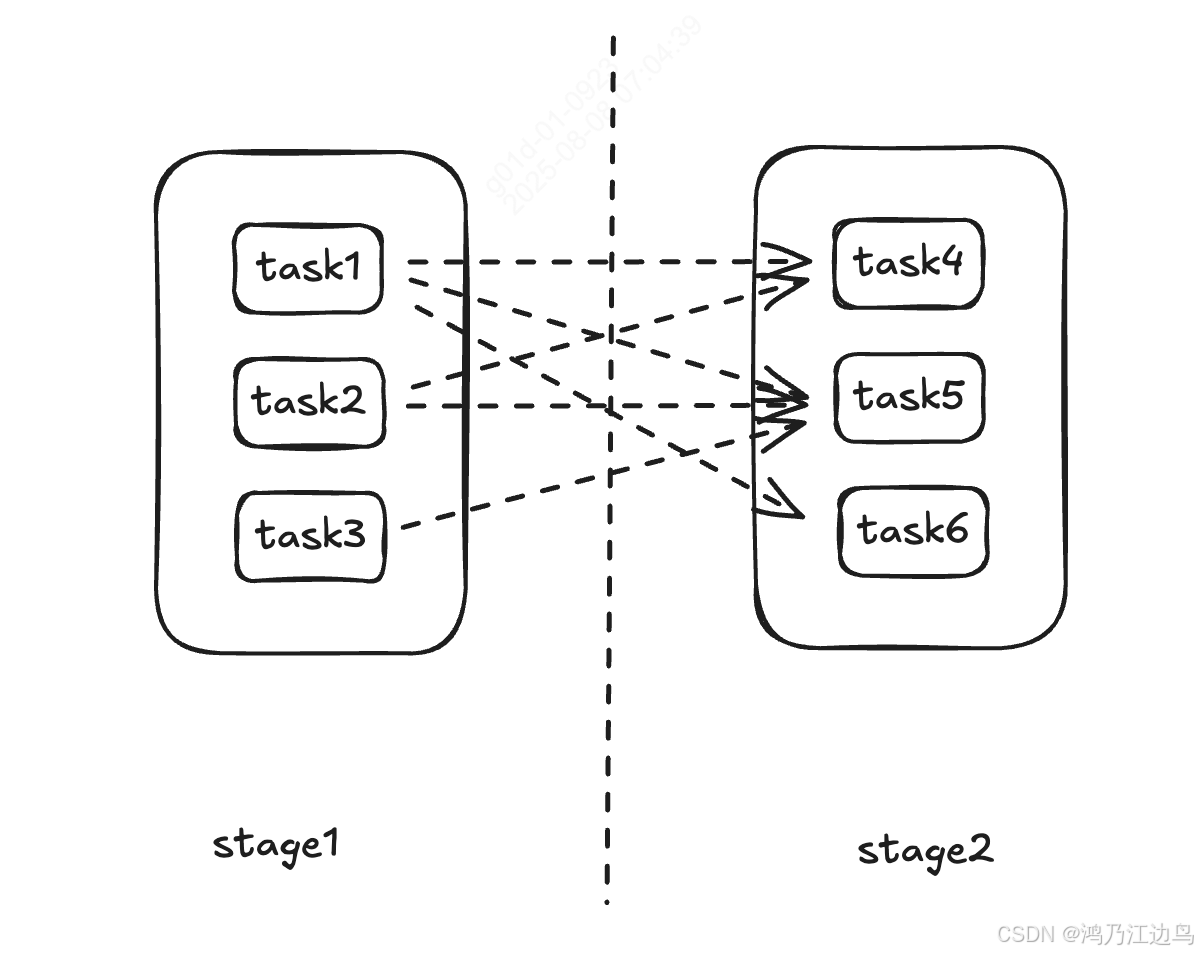
第二種模式:AllAtOnce,這種模式是典型的流式調度模型,也就是在任務執行之前,調度器會根據策略進行Task的調度了,這個時候每個任務在哪個節點執行都已經固定好了,之后所有的數據處理就像流水線一樣,來一個處理一個,這個階段Task的調度就是閑置狀態。所以這種模式的時效性很好,數據的延遲低。但是如果Task失敗或者task所在的容器重啟了,這個時候調度器會重新調度Task。
SQL計算
SQL計算的話,一般會包括SQL部分,以及SQL轉換成引擎底層API的部分,從整個引擎的發展來看,一般是先提供API接口,用戶寫底層的API進行調用,后著才慢慢的出現SQL引擎,這種SQL使用起來對用戶是友好的,當然這后面邏輯的轉換也會經過很多步驟:
- SQL解析為AST
- AST轉為邏輯計劃
- 邏輯計劃優化為優化計劃
- 優化計劃換轉為物理計劃
- 物理計劃轉換為可執行的底層API
這種SQL的解析,目前從大部分開源框架的用的趨勢來看,ANTLR4 是主流,只有一小部分,比如說Flink 用的是 Calcite,不得不說 ANTLR4還是挺好用的,這個階段主要是判斷語法的合規性,是不是符合定義的語法規則。
再者是 AST轉換為邏輯計劃,這個階段主要是y結合元數據做一些校驗,比如說 檢查表存不存在,字段合不合理,函數存不存在等。
優化計劃這一部分,這里面包括的內容就比較多了,但是一般來說,一種是基于規則的(RBO),一種是基于代價的(CBO)的。
這兩種也不是非黑即白的,主要看側重于那一方。
比如說,Spark主要是RBO,但是在join轉換的部分,也是會基于CBO的(AQE),AQE也就是說基于運行時的指標信息來及時調整運行的計劃以達到更好的加速效果。
又比如說 StarRocks 主要是基于CBO的,但是這種CBO的話,也是在RBO規則的下的,比如說這種常量折疊等這種都是RBO。而且這種CBO也有一部分是估算的,也沒有精確的數值。
優化計劃轉換為物理計劃這一塊,這一塊主要是轉換為可執行的物理計劃,也就是說這里的物理計劃都是可以執行了,調用某個方法就會返回對應的API的調用,比如說
Spark中RowDataSourceScanExec這里的doExecute方法就是返回RDD,Flink也是如此。
當然這里還有一個很大的部分就是代碼生成,這里主要就是為了減少虛函數的調用而采用的一種提速的方法,這種是因為JVM語言存在多態函數的二次尋址。
SQL優化
這一部分主要是從以下方面來優化
- 使獲取的數據盡可能的少,減少計算的數據量
- 使中間任務傳輸的數據盡可能的少,減少傳輸帶來的開銷
- 盡量減少shuffle的數據量,或者消除shuffle
- 減少shuffle所需要的時間
比如說
hashjoin轉換為 broadcastJoin 就是 消除shuffle
hashjoin轉為換sortmergejoin 就是減少shuffle需要的時間
runtimefilter 就是減少傳輸的數據量
謂詞下推 就是使獲取的數據盡可能的少
數據的存儲與索引
對于沒有自身存儲系統的計算引擎
這種引擎其實是沒沒有索引一說的,因為你無法快速的定位到某一行數據,這種如果想加速的話,只能依靠存儲系統的本身一種快讀過濾機制,就拿現在流行的數據湖來說,如paimon或者delta,他們的底層文件存儲是列式存儲,比如說parquet。
這種引擎如果想快速的過濾出出數據的話,得依靠parquet這個底層文件系統自帶的統計信息,比如說最大最小值,又或者說布隆過濾器(Bloom Filter),這些是基于rowgroup級別的來的,也就是說這些過濾器能夠做到快讀的跳過文件。
或者從計算層級來加速,比如說字典編碼,這種把String的比較轉換為整數的比較。
當然也可可以通過文件的布局來進行加速,比如說Zorder等
對于帶有自身存儲的計算引擎
這種引擎的話,大部分是存算一體的,也就是說計算和存儲耦合在一起,這種引擎在寫入數據的時候,往往會進行索引的建立,比如說主鍵索引(能夠快速定位到某一行數據),bitmap索引(能夠快讀定位過濾條件所在的行),聚簇索引(能夠根據聚簇鍵進行快速查詢)。
但是需要注意的是,這種索引是需要單獨維護的,尤其在大量數據更新的場景下,索引的維護也需要一定的開銷。不像前者,前者是把這些信息存儲在文件的元數據信息里。
點查
這里需要單獨說一下這個點查,大部分都是通過主鍵來查找來達到點查的效果的。
這里的如果要有點查的效果,必須是針對于帶有自身粗處的計算引擎。
以上所過,我們寫完SQL以后會進入到優化器以及調度環節,但是對于點查不一樣,它只需要簡單的優化,調度環節的的話直接越過。
為什么跳過呢?
因為我們是簡單的查詢,沒有計算,只需要查詢對應的數據,無需要進行Task的調度。就拿Starrocks來說,一個SQL的調度可能就需要花費20多毫秒
- -- Deploy[1] 23ms- -- DeployLockInternalTime[1] 23ms- -- DeploySerializeConcurrencyTime[1] 0- -- DeployStageByStageTime[3] 0- -- DeployWaitTime[3] 23ms- -- DeployAsyncSendTime[1] 0
)



:I2C總線的傳輸速率與上拉電阻有什么關系?)





用戶的區別)




)


