(2021) 20 [虛擬化] 進程調度
南京大學操作系統課蔣炎巖老師網絡課程筆記。
視頻:https://www.bilibili.com/video/BV1HN41197Ko?p=20
講義:http://jyywiki.cn/OS/2021/slides/11.slides#/
背景 — 機制與策略分離
- 機制:一個通用的、可定制的抽象
- 策略:在機制上實現的具體
- 例子:
- 分頁和存儲保護(機制) VS. 進程實現(策略)
- 操作系統API(機制)VS. 應用程序(策略)
中斷和虛擬存儲為我們提供了進程抽象(機制),操作系統的實現者在中斷時獲得了 ”選擇一個程序執行“ 的權利,但是到底應該選哪個呢?(策略)
本次課內容與目標
理解常見的處理器調度策略
- 輪轉調度(round - robin)
- 優先級 / 反饋調度
- 公平調度
了解調度是操作系統領域重要的、未解決的問題。
虛假的(課本上的)處理器調度
一組基本的假設
我們接下來的討論,基于這樣一組基本的假設,這使得我們能夠更好地聚焦與調度問題。
- 系統中有一個處理器(1970s)
- 多個進程共享CPU
- 包括系統調用(進程的一部分代碼在syscall中運行)
- 偶爾會等待I/O返回,不適用CPU(通常時間較長)
- 處理器以固定的頻率被中斷
- 隨時有可能有新的進程被創建 / 舊的進程退出
中斷機制:在中斷 / 系統調用中可以切換到其他進程執行
策略:Round-Robin 輪轉
假設檔期 TiT_iTi? 運行,中斷之后會試圖切換到下一個線程 T(i+1)modnT_{(i+1)\ mod\ n}T(i+1)?mod?n? ,如果下一個線程正在等待 I / O返回,就繼續嘗試下一個,如果所有的線程都不需要 CPU,就調度idle進程執行。
中斷之間進程的執行稱為時間片 (time-slicing)
沒有優先級的處理。
策略:引入優先級
UNIX niceness
- -20 … 19
- 越 nice,越被不 nice 的人搶占
- -20: 極壞; most favorable to the process
- 19: 極好; least favorable to the process
- 基于優先級的各種策略
- 有壞人,永遠輪不到好人 (RTOS;
好人流下了悔恨的淚水),除非高優先級的進程在等待IO,否則永遠是高優先級先執行 - nice 相差 10, CPU 獲得相差 10 倍 (Linux)(linux實測應為1:9)
- 有壞人,永遠輪不到好人 (RTOS;
- 不妨試一試: nice/renice
taskset -c 0 nice -n 19 ./a.out &taskset -c 0 nice -n 9 ./a.out &
top命令除了查看進程的CPU和內存的占用情況之外,也可以查看進程的NICE值,即NI。
真實的處理器調度
策略:動態優先級,多級反饋隊列調度(MLFQ)
不會設置優先級?能不能讓系統自動設定?
- 交互進程 (vi, vscode, …),大部分時候在等待外界輸入,這時這種進程會主動讓出CPU
- 優先調度它們能提升用戶體驗,減少卡頓 (試想 Round-Robin)
- 計算進程 (gcc, ld, …),拼命使用 CPU
調度策略
設置若干個 Round-Robin 隊列,每個隊列對應一個優先級。
如果將時間片用完了,則判定該進程執行大量運算,就下調其的優先級
- 優先調度高優先級隊列
- 用完時間片 → 壞人,請你變得更好
- 讓出 CPU I/O → 好人,可以變得更壞
詳見教科書OSTEP
問題
這種方式在早年間可以很好地工作,但是在現代操作系統中,大量的進程之間會有通信和互動。這時,如果兩個進程之間彼此頻繁通信,我們的多級反饋調度也會把它們識別成互動進程,提高其優先級。
策略:Complete Fair Scheduling (CFS)
基本策略
隨著現代操作系統越來越復雜,操作系統的設計者已經放棄了設計一個完美的調度算法,而是轉而使用一種按執行時間完全公平的調度算法。注意其中還有NICE機制來調節優先級,但其他情況下完全公平。
所有復雜系統的調度都是拙劣的 Workaround
試圖去模擬一個 “ideal multi-task CPU”
“讓系統里的所用進程盡可能公平地分享處理器”。具體來說,它會為每個進程記錄精確的運行時間,中斷 / 異常發生之后,就切換到運行時間最少的進程來執行,而當下次中斷 / 異常之后,當前進程可能就不是運行時間最少的了,這時再選擇當前最少運行時間的進程來執行。
CFS實現優先級
讓好人的時間變得快一些,壞人的時間變得慢一些……
- 不再是運行時間,而是 “vruntime” (virtual runtime)
- vrt[i]/vrt[j]vrt[i]\ /\ vrt[j]vrt[i]?/?vrt[j] 的增加比例 =wt[j]/wt[i]= wt[j]\ /\ wt[i]=wt[j]?/?wt[i]
const int sched_prio_to_weight[40] = {/* -20 */ 88761, 71755, 56483, 46273, 36291,/* -15 */ 29154, 23254, 18705, 14949, 11916,/* -10 */ 9548, 7620, 6100, 4904, 3906,/* -5 */ 3121, 2501, 1991, 1586, 1277,/* 0 */ 1024, 820, 655, 526, 423,/* 5 */ 335, 272, 215, 172, 137,/* 10 */ 110, 87, 70, 56, 45,/* 15 */ 36, 29, 23, 18, 15,
};
CFS 的復雜性
-
新進程 / 線程:子進程繼承符進程的vruntime
-
I/O (例如 1 分鐘) 以后回來 vruntime 嚴重落后。為了趕上,CPU 會全部歸它所有。
Linux 的實現:被喚醒的進程獲得 “最小” 的 vruntime (可以立即被執行)。
-
vruntime 有優先級的 “倍數”,如果溢出了 64-bit 整數怎么辦?
假設:系統中最近、最遠的時刻差不超過數軸的一半。我們可以比較它們的相對大小,
a < b不再代表 “小于” !bool less(u64 a, u64 b) {return (i64)(a - b) < 0; }
實現CFS的數據結構
用什么數據結構維護所有進程的 vruntime?考慮:我們需要什么操作?
為每個進程維護映射 t?vt(t)t?v_t(t)t?vt?(t)
- 維護進程的 vruntimevt(t)←vt(t)+Δt/wvruntime v_t(t)←v_t(t)+Δt/wvruntimevt?(t)←vt?(t)+Δt/w
- 找到 ttt 滿足 vt(t)v_t(t)vt?(t) 最小
- 進程創建/退出/睡眠/喚醒時插入/刪除 ttt
Linux內核中的實現:紅黑樹。
調度與互斥鎖
處理器調度:不僅是計算
線程不是 while (1) 的循環,還可能等待互斥鎖/信號量/設備 (比一個時間片短很多)。在此情形下,會發生什么?
- round-robin?
- 考慮三個進程/線程: producer, consumer, while (1)
- 主要是因為沒有精確的時間統計
- CFS?
- (似乎沒問題?) 線程有精確的 accounting 信息
優先級反轉(priority inversion)
void bad_guy() { // 高優先級mutex_lock(&lk);...mutex_unlock(&lk);
}void nice_guy() { // 中優先級while (1) ;
}void very_nice_guy() { // 最低優先級mutex_lock(&lk);...mutex_unlock(&lk);
}
very nice guy 在持有鎖的時候讓出了處理器……
- bad guy 順便也無法運行了 (nice guy 搶在了它前面 )
解決優先級反轉問題
Linux: CFS 湊合用吧;實時系統(RTOS):火星車在 CPU Reset 啊喂??
- 優先級繼承 (Priority Inheritance)/優先級提升 (Priority Ceiling)
- 持有 mutex 的線程/進程會繼承 block 在該 mutex 上的最高優先級
- 不總是能 work (例如條件變量喚醒)
- 在系統中動態維護資源依賴關系
- 優先級繼承是它的特例
- 似乎更困難了……
- 避免高/低優先級的任務爭搶資源
- 對潛在的優先級反轉進行預警 (lockdep)
- TX-based: 沖突的 TX 發生時,總是低優先級的 abort
由于在現代操作系統中進程 / 線程之間的資源依賴(如互斥鎖等)過于復雜,Linux選擇躺平。
實際情況下的一些問題
多處理器調度:多用戶、多任務
還沒完:我們的 CPU 里有多個共享內存的處理器啊!
- 不能簡單地每個處理器上執行 CFS
- 出現 “一核出力,七核圍觀”
- 也不能簡單地一個全局 CFS 維護隊列
- 在處理器之間遷移會導致 L1 cache/TLB 全都白給
- 遷移?可能過一會兒還得移回來
- 不遷移?造成處理器的浪費
- 在處理器之間遷移會導致 L1 cache/TLB 全都白給
注意L1、L2緩存是每個CPU獨立的,L3緩存共享的。
實際情況(1)
- A 要跑一個任務,因為要調用一個庫,只能單線程跑
- B 跑并行的任務,創建 1000 個線程跑
- CFS 會發生什么?
- 提示: CFS 公平地在線程之間共享 CPU
更糟糕的是,優先級解決不了這個問題……
- B 不能隨便提高自己進程的優先級
- “An unprivileged user can only increase the nice value and such changes are irreversible…”
Linux Control Groups (cgroups)
可以去讀一下手冊,man 7 cgroups。
順便提一下:cgroups也是docker實現所依賴的機制之一。
實際情況(2):Big.LITTLE/能耗
處理器的計算能力不同
- 均分 workloads 會讓小核上的任務饑餓
- Linux Kernel EAS (Energy Aware Scheduler)
- 移動平臺的考慮 (能耗 vs. 速度 vs. 吞吐量)。頻率越低,IPC (Instruction per Cycle) 和能效都更好
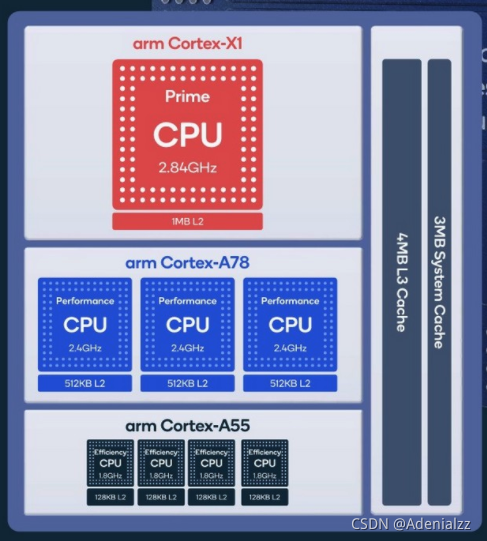
如驍龍888中:Snapdragon 888
- 1X Prime Cortex-X1 (2.84GHz)
- 3X Performance Cortex-A78 (2.4GHz)
- 4X Efficiency Cortex-A55 (1.8GHz)
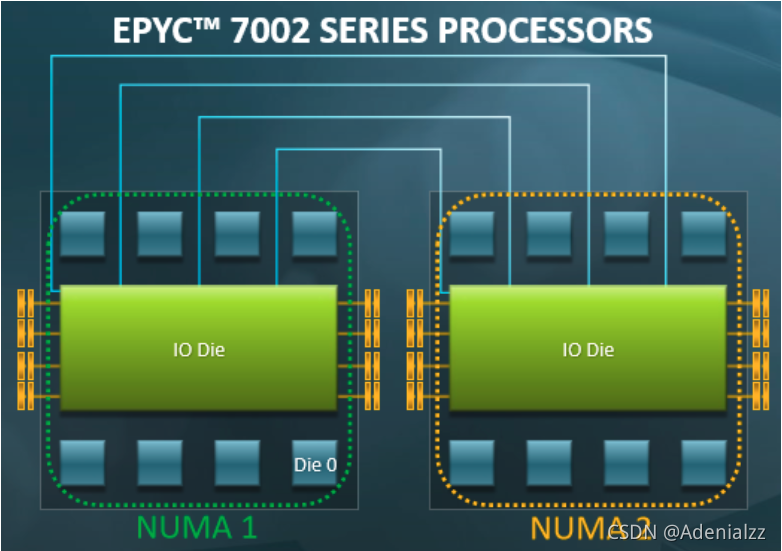
實際情況(3):Non-Uniform Memory Access
線程看起來在 “共享內存”,但共享內存卻是 memory hierarchy 造就的假象,roducer/consumer 位于同一個/不同 module 性能差距可能很大。
實際情況(4):CPU Hot-plug
指CPU的熱插拔的情況,就像彈出U盤一樣彈出CPU。
總結
本次課內容與目標
- 理解常見的處理器的調度策略
- 了解調度是操作系統領域重要的、未解決的問題
Takeaway messages
- 機制和策略分離
- “做系統” 的矛盾
- 必須把問題簡單化,才能做 “第一個” 東西出來
- 但隨著需求的增長,復雜系統會失控
- 所有復雜系統的調度都是拙劣的 Workaround
.doc)


![(2021) 22 [持久化] 1-Bit的存儲](http://pic.xiahunao.cn/(2021) 22 [持久化] 1-Bit的存儲)

![(2021) 23 [持久化] I/O設備與驅動](http://pic.xiahunao.cn/(2021) 23 [持久化] I/O設備與驅動)

![(2021) 24 [持久化] 文件系統API](http://pic.xiahunao.cn/(2021) 24 [持久化] 文件系統API)




![(2021) 25 [持久化] 文件系統實現:FAT和UNIX文件系統](http://pic.xiahunao.cn/(2021) 25 [持久化] 文件系統實現:FAT和UNIX文件系統)




![[2020-ECCV]PIPAL-a Large-Scale Image Quality Assessment Dataset for Perceptual Image Restoration論文簡析](http://pic.xiahunao.cn/[2020-ECCV]PIPAL-a Large-Scale Image Quality Assessment Dataset for Perceptual Image Restoration論文簡析)

![(2021) 18 [代碼講解] 可執行文件](http://pic.xiahunao.cn/(2021) 18 [代碼講解] 可執行文件)