[2020-ECCV] PIPAL: a Large-Scale Image Quality Assessment Dataset for Perceptual Image Restoration 論文簡析
論文:https://arxiv.org/abs/2007.12142
代碼及數據集:https://github.com/HaomingCai/PIPAL-dataset
概述
本文認為隨著圖像重建(IR)算法的快速發展(特別是一些基于GAN的模型的出現),使得現有的圖像質量評價(IQA)的方法已經不能很好地評估這些圖像重建方法。因此,IQA方法應當隨著IR算法一起演進更新。基于此,本文提出了一個新的大型圖像感知評估數據集PIPAL,并且該數據集使用了Elo評分系統來對兩兩圖像進行比較,更新評分,這使得該數據集的評分標簽可以不斷地更新,以適應將來可能會出現的新型IR算法。并且,本文基于PIPAL數據集為IQA和IR提出了一種新的指標。結果顯示本文的數據集和指標能更好地評價最近基于GAN的IR算法。
其借用的Elo等級分系統的一個好處是:每次接收評分者給出的標簽時,并不需要評分者直接給出MOS分的絕對數值,而是請評分者在兩張圖像中選出較好的一張即可。這無疑降低了受訪評分者評分的難度,并大大提高了了收集評分的可信度。畢竟,按照人類的主觀感知對一張圖像直接給出數值分數還是一件相當tricky的事情。受到個人狀態、心情等方面的影響,同一個人在不同的時間對同一張圖像的打分可能是不同的,但是兩張圖像中哪一張更好一點的判斷基本是不會變的。
摘要
圖像質量評價(IQA)是圖像重建(IR)算法發展的關鍵因素。最近的基于GAN的圖像重建方法取得了較大的性能提升,但是量化評估仍然是較大的挑戰。尤其是,我們觀察到感知質量和評估結果之間越來越不一致。由此,我們提出兩個問題:一是現有的IQA方法能否客觀地評估最近的IR算法?二是當致力于打敗最新的benchmark,我們是否真的得到了更好地IR算法?為了回答這些問題,和促進IQA模型的發展,我們提出了一個大規模的IQA數據集,叫做Peceptual Image Processing Algorithms(PIPAL) 數據集。特別之處在于,本數據集是基于GAN的方法的結果,這在之前的數據集中是沒有的。我們收集了超過113萬條人類判斷來使用更可靠的“Elo系統”為PIPAL圖像分配主觀分數。基于PIPAL,我們為IQA和SR模型提出了一種新的指標。我們的結果顯示現有的IQA方法并不能很好地評估基于GAN的IR算法。使用合適的評估方法是很重要的,IQA方法應當隨著IR算法的發展一起更新。最后,我們通過引入 anti-aliasing pooling 來提高基于GAN畸變的IQA網絡的性能。實驗證明了該方法的有效性。
PIPAL數據集
本文從以下三個方面來介紹PIPAL數據集:
- 參考圖像的收集
- 降質方法的質量和種類
- 主觀分數的收集
參考圖像的收集
從高質量圖像數據集DIV2K和Flickr2K,更關注與較難重建的部分,比如高頻紋理信息。我們將這些表示紋理的部分塊從所選圖像中切下來。所選的圖像包含了各種不同的真實世界的紋理信息,包括但不限于:建筑物、動植物、人臉、文字和合成的紋理等。切下來的圖像的尺寸為288。
圖像降質
本數據集中有40中降質方法,分為四個子類。總覽如下表:

- 第一個子類包含了許多傳統的降質方法。比如模糊、噪聲、壓縮等,即一些低層的圖像編輯操作。
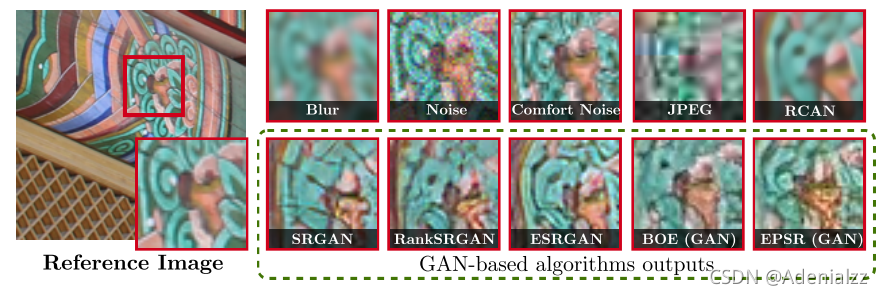
- 第二個子類是一些現有算法的超分結果。這些超分算法又分為三類。傳統算法、PSNR導向的算法和基于GAN的算法。傳統算法在某種程度上可以理解為細節上的損失;PSNR導向的算法通常是基于深度模型的,它們比傳統算法有更銳利的邊緣和更好的PSNR表現;基于GAN的算法通常與細節損失的質量不太匹配,因為它們通常包含類紋理噪聲,或噪聲的質量,類紋理噪聲在外觀上與GT相似但不準確。 基于 GAN 的失真示例如下圖所示。測量不正確但相似特征的相似性對于感知超分的發展非常重要。
- 第三個子類包括幾種去噪算法的輸出。 與圖像 SR 類似,所使用的去噪算法包含基于模型的算法和基于深度學習的算法。 除了高斯噪聲,我們還包括 JPEG 壓縮噪聲去除結果。
- 最后,我們包括混合退化的恢復結果。 如之前的工作所述,依次執行去噪和 SR 將帶來新的偽影或不同的模糊效果。
總之,我們有40中降質類型和116中不同的降質等級,總共29K張降質圖像。
Elo等級分系統
前人的MOS得分方法
給定失真圖像,為每個失真圖像提供平均意見得分 (MOS)。
- 早期的數據集使用“五級評級”方法,其中圖像直接分為五個類別。 當評分者沒有足夠的經驗時,使用這種方法會導致巨大的偏差。
- 后來,數據集通常使用瑞士評級系統通過大量成對選擇來收集 MOS。 然而,這種成對 MOS 的計算方式使其依賴于特定的數據集,這意味著當兩個失真圖像包含在兩個不同的數據集中時,它們的 MOS 分數可能會發生顯著變化。
- 為了消除這種集合依賴效應,又有人提出僅基于成對偏好的概率來構建數據集。這種方法可以提供更準確的傾向概率。 但是,它不僅需要大量的人工判斷,而且無法提供失真類型的 MOS。
ELo等級分系統
在本文提出的數據集中,我們采用 Elo 評分系統將成對偏好概率和評分系統結合在一起。 Elo 系統的使用不僅提供了可靠的人工評級,而且還減少了所需人工判斷的次數。
Elo 評分系統是一種基于統計的評分方法,最初被提出用于評估國際象棋選手的水平。 我們假設兩個圖像 IAI_AIA? 和 IBI_BIB? 之間的用戶偏好遵循由他們的 Elo 分數參數化的邏輯分布logistic distribution。 給定他們的 Elo 分數 RAR_ARA? 和 RBR_BRB?,期望的偏好概率如下:
PA>B=11+10(RB?RA)/M,PB>A=11+10(RA?RB)/MP_{A>B}=\frac{1}{1+10^{(R_B-R_A)/M}},\ \ \ P_{B>A}=\frac{1}{1+10^{(R_A-R_B)/M}} PA>B?=1+10(RB??RA?)/M1?,???PB>A?=1+10(RA??RB?)/M1?
其中 PA>BP_{A>B}PA>B? 表示一個評分者會相比與 IBI_BIB? 更喜歡 IAI_AIA? 的概率。MMM 是分布的一個參數,在我們的數據集中 M=400M=400M=400 。一旦評分者作出了選擇,我們會根據以下規則為 IAI_AIA? 和 IBI_BIB? 更新Elo分數:
RA′=RA+K×(SA?PA>B),RB′=RB+K×(SB?PB>A)R'_A=R_A+K\times (S_A-P_{A>B}), \ \ \ R'_B=R_B+K\times (S_B-P_{B>A}) RA′?=RA?+K×(SA??PA>B?),???RB′?=RB?+K×(SB??PB>A?)
其中 KKK 是一次判斷的變化步長,設置為16。SAS_ASA? 表示是否選擇 IAI_AIA?:如果IA獲勝,SA=1S_A=1SA?=1,如果 IAI_AIA? 失敗,SA=0S_A=0SA?=0。 通過數千次人工判斷,每個扭曲圖像的 Elo 分數都會收斂。 最后幾個步驟的 Elo 分數的平均值將被指定為 MOS 主觀分數。 平均操作旨在減少 Elo 變化的隨機性。
例子
舉個例子。 假設 RA=1500R_A = 1500RA?=1500,和 Rb=1600R_b = 1600Rb?=1600,那么我們有 PA>B≈0.36P_{A>B} ≈ 0.36PA>B?≈0.36 和 PB>A≈0.64P{B>A} ≈ 0.64PB>A≈0.64。 在這種情況下,如果選擇 IAI_AIA?,則 IAI_AIA? 的更新 Elo 分數將為 RA=1500+16×(1?0.36)≈1510R_A = 1500 + 16× (1 ?0.36) ≈ 1510RA?=1500+16×(1?0.36)≈1510,IBI_BIB? 的新分數為 RB=1600+16×(0?0.64)≈1594R_B = 1600 + 16 × (0 ? 0.64)≈1594RB?=1600+16×(0?0.64)≈1594; 如果選擇 IBI_BIB?,新的分數將是RA≈1494R_A≈1494RA?≈1494 和 RB≈1605R_B≈1605RB?≈1605。注意,由于選擇不同圖像的預期概率不同,Elo分數的值變化也會不同。 這也表明,當質量相差太大時,獲勝者不會從糟糕的圖像中獲得很多收益。 根據上式,200 的分差表示 76% 的獲勝機會,400 表示超過 90% 的機會。 最開始,我們為每個扭曲的圖像分配一個 1400 的 Elo 分數。 經過多次人工判斷(在我們的數據集中,我們有 113 萬次人工判斷),最終得到了每張圖像的 Elo 分數。
采用 Elo 系統的另一個優勢是我們的數據集可以是動態的,并且可以在未來擴展。 Elo 系統在電子游戲中被廣泛用于評估玩家的相對水平,在電子游戲中,玩家不斷變化,Elo 系統可以在少數游戲玩法中為新玩家提供評分。 回想一下,“這些 IQA 方法面臨挑戰”的主要原因之一是 GAN 和基于 GAN 的 IR 方法的出現。如果將來提出其他新型的圖像生成技術會怎樣? 人們是否需要構建一個新的數據集來包含這些新算法? 憑借 Elo 系統的可擴展特性,人們可以輕松地將新的失真類型添加到該數據集中并遵循相同的評級過程。 Elo 系統會自動調整所有失真的 Elo 分數,而不需要再對舊的重新評分。
結果
本文基于提出的 PIPAL 數據集進行了全面的研究。 首先為IQA方法建立一個基準。 通過這個基準,回答了“現有的 IQA 方法能否客觀地評估最近的 IR 算法?”的問題。 然后,本文為一些最近的 SR 算法建立了一個基準,以探索 IQA 方法的發展與 IR 研究之間的關系。 我們可以得到這樣的答案:“我們是否通過在這些 IQA 方法上擊敗基準來獲得更好的 IR 算法?” 最后,我們通過與其他現有的失真類型進行比較來研究基于 GAN 的失真的特征。 最后還通過引入anti-aliasing pooling來提高 IQA 網絡在基于 GAN 的失真上的性能。
實驗部分有興趣的話,請自行查閱原文吧。

![(2021) 18 [代碼講解] 可執行文件](http://pic.xiahunao.cn/(2021) 18 [代碼講解] 可執行文件)




![(2021) 26 [持久化] 持久數據的可靠性:RAID和journaling](http://pic.xiahunao.cn/(2021) 26 [持久化] 持久數據的可靠性:RAID和journaling)
_百度百科)











