TVM:使用Tensor Expression (TE)來處理算子
在本教程中,我們將聚焦于在 TVM 中使用張量表達式(TE)來定義張量計算和實現循環優化。TE用純函數語言描述張量計算(即每個表達式都沒有副作用)。當在 TVM 的整體上下文中查看時,Relay 將計算描述為一組算子,并且其中每一個算子都可以表示為 TE 表達式,每個 TE 表達式獲取輸入張量并生成輸出張量。
本文是TVM中 TE 語言的入門教程。TVM 使用領域專用(domain specific)的張量表達式來高效地構造內核。我們以兩個使用 TE 語言的為例來演示基本工作流。第一個示例介紹了 TE 和帶有向量加法的 schedule。第二個示例通過逐步優化矩陣與 TE 的乘法來擴展這些概念。這個矩陣乘法示例將作為未來涵蓋更高級的 TVM 特性的教程的對比基礎。
示例一:使用TE為CPU編寫和調度向量加法
初始化 tvm環境
我們的第一個例子是使用 Python 來為向量加法實現一個 TE,然后是一個針對 CPU 的 schedule,我們從初始化 tvm 環境開始:
import tvm
import tvm.testing
from tvm import te
import numpy as np# 如果能夠指定目標 CPU,那么將會得到更好地性能
# 如果用的是llvm,可以通過 `llc --version` 來查看 CPU 類型
# 可以通過查看 /proc/cpuinfo 來查看你的處理器可能支持的其他擴展,
# 比如,如果你的 CPU 有 AVX-512 指令集,那么你可以使用 `llvm -mcpu=skylake-avx512` 選項tgt = tvm.target.Target(target="llvm", host="llvm")
描述向量計算
我們首先描述向量加法計算。TVM 采用張量語義,每個中間結果表示為一個多維數組。我們需要描述規則來得到張量。我們首先定義一個符號變量 n 來表示形狀。然后我們定義兩個 placeholder 張量:A、B,它們的形狀是 (n,)。然后我們通過一個 compute 操作,得到結果張量 C。compute 定義了一種計算,其輸出符合指定的張量形狀,并在由 lambda 函數定義的張量中的每個位置執行計算。注意,雖然 n 是一個變量,但它定義了A、B 和 C 張量之間的一致形狀。請注意,在這個階段沒有實際的計算發生,因為我們只是聲明應該如何進行計算。
n = te.var("n")
A = te.placeholder((n,), name="A")
B = te.placeholder((n,), name="B")
C = te.compute(A.shape, lambda i: A[i] + B[i], name="C")
注意:Lambda函數
te.compute方法的第二個參數是執行計算的函數。在本例中,我們使用一個匿名函數(也稱為lambda函數)來定義計算,在本例中是對
a和B的第i個元素的加法。
為計算創建一個默認的Schedule
雖然上面幾行描述了計算規則,但我們可以用許多不同的方法計算 C 以適應不同的設備。對于具有多個 axis 的張量,您可以選擇首先迭代哪個 axis ,另外計算可以跨不同的線程拆分。TVM要求用戶提供一個 schedule,來描述應如何執行計算。TE 中的 schedule 操作可以更改循環順序、跨不同線程拆分計算、將數據塊分組在一起,以及其他操作。schedule 背后的一個重要概念是,它們只描述如何執行計算,因此相同 TE 的不同 schedule 一定會產生相同的結果。
在 TVM 中,我們可以創建一種樸素的 schedule ,按照行優先的順序來計算 C。
for (int i = 0; i < n; ++i) {C[i] = A[i] + B[i];
}
s = te.create_schedule(C.op)
編譯并驗證默認的 schedule
通過 TE 表達式和 schedule,我們可以為目標語言和體系結構生成可運行的代碼,在本例中是 LLVM 和 CPU 。我們向 TVM 提供 schedule、schedule 中的TE表達式列表、目標和主機,以及我們正在生成的函數的名稱。輸出的結果是可以直接從 Python 調用 type-erased 函數。
在下一行中,我們使用 tvm.build 創建一個函數。build 函數接受 schedule、函數所需的簽名(包括輸入和輸出)以及我們要編譯到的目標語言。
fadd = tvm.build(s, [A, B, C], tgt, name="myadd")
我們運行該函數,并將輸出與 numpy 中的相同計算進行比較。編譯后的 TVM 函數提供了一個簡明的C API,可以被任何語言調用。我們首先創建一個設備(在本例中為CPU),這是一個 TVM 可以編譯 schedule 的設備。在本例中,設備是LLVM CPU target。然后,我們可以在設備中初始化張量并執行自定義的加法操作。為了驗證計算的正確性,我們可以將c張量的輸出結果與 numpy 執行的相同計算進行比較。
dev = tvm.device(tgt.kind.name, 0)n = 1024
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)
fadd(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
為了對比這個樸素版本的自定義向量加法與 numpy 的速度差異,創建一個輔助函數來運行 TVM 生成代碼的 profile。
import timeitnp_repeat = 100
np_running_time = timeit.timeit(setup="import numpy\n""n = 32768\n"'dtype = "float32"\n'"a = numpy.random.rand(n, 1).astype(dtype)\n""b = numpy.random.rand(n, 1).astype(dtype)\n",stmt="answer = a + b",number=np_repeat,
)
print("Numpy running time: %f" % (np_running_time / np_repeat))def evaluate_addition(func, target, optimization, log):dev = tvm.device(target.kind.name, 0)n = 32768a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)evaluator = func.time_evaluator(func.entry_name, dev, number=10)mean_time = evaluator(a, b, c).meanprint("%s: %f" % (optimization, mean_time))log.append((optimization, mean_time))log = [("numpy", np_running_time / np_repeat)]
evaluate_addition(fadd, tgt, "naive", log=log)
此處輸出:
Numpy running time: 0.000008
naive: 0.000006
使用并行性(paralleism)來優化 schedule
我們已經說明了 TE 的基本原理,現在讓我們更深入地了解 schedule 的作用,以及它們如何用于優化不同體系結構的張量表達式。schedule 是應用于表達式的一系列步驟,用于以多種不同方式對其進行轉換。當一個 schedule 應用于TE中的一個表達式時,輸入和輸出保持不變,但在編譯時,表達式的實現可能會改變。在默認 schedule 中,這個張量加法是串行運行的,但該操作其實是很容易在所有處理器線程之間并行。我們可以將我們的操作并行調度到計算中:
s[C].parallel(C.op.axis[0])
tvm.lower 命令將生成 TE 的中間表示(IR)以及相應的 schedule 。通過在執行不同的 schedule 操作時 lowing 表達式,我們可以看到 schedule 對計算順序的影響。我們使用標志 simple_mode=True 返回可讀的 C 風格語句。
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [n: int32], [stride: int32], type="auto"),A: Buffer(A_2: Pointer(float32), float32, [n], [stride_1: int32], type="auto"),B: Buffer(B_2: Pointer(float32), float32, [n], [stride_2: int32], type="auto")}buffer_map = {A_1: A, B_1: B, C_1: C} {for (i: int32, 0, n) "parallel" {C_2[(i*stride)] = ((float32*)A_2[(i*stride_1)] + (float32*)B_2[(i*stride_2)])}
}
TVM現在可以在獨立的線程上運行這些塊。我們在執行并行操作的情況下編譯并運行這個新的 schedule:
fadd_parallel = tvm.build(s, [A, B, C], tgt, name="myadd_parallel")
fadd_parallel(a, b, c)tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())evaluate_addition(fadd_parallel, tgt, "parallel", log=log)
此處輸出:
parallel: 0.000005
使用矢量化(vectorization)來優化 schedule
現代 CPU 能夠對浮點數進行 SIMD 操作,我們可以對計算表達式使用另一個 schedule 來利用這一點。實現這一點需要多個步驟:首先,我們必須使用 split scheduling 原語將 schedule 拆分為內部循環和外部循環。內部循環可以使用向量化來使用使用向量化調度原語的 SIMD 指令,然后外部循環可以使用并行調度原語進行并行化。選擇分割因子作為CPU上的線程數。
注:SIMD,全稱 Single Instruction Multiple Data,單指令多數據流,能夠復制多個操作數,并把它們打包在大型寄存器的一組指令集。
# 由于我們需要修改之前例子中的并行操作,因此這里要重建 schedule
n = te.var("n")
A = te.placeholder((n,), name="A")
B = te.placeholder((n,), name="B")
C = te.compute(A.shape, lambda i: A[i] + B[i], name="C")s = te.create_schedule(C.op)# factor 的選擇需要適合你的線程數,這取決于架構,
# 建議將此系數設置為等于可用CPU核心數。
factor = 4outer, inner = s[C].split(C.op.axis[0], factor=factor)
s[C].parallel(outer)
s[C].vectorize(inner)fadd_vector = tvm.build(s, [A, B, C], tgt, name="myadd_parallel")evaluate_addition(fadd_vector, tgt, "vector", log=log)print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
vector: 0.000016
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [n: int32], [stride: int32], type="auto"),C: Buffer(C_2: Pointer(float32), float32, [n], [stride_1: int32], type="auto"),B: Buffer(B_2: Pointer(float32), float32, [n], [stride_2: int32], type="auto")}buffer_map = {A_1: A, B_1: B, C_1: C} {for (i.outer: int32, 0, floordiv((n + 3), 4)) "parallel" {for (i.inner.s: int32, 0, 4) {if @tir.likely((((i.outer*4) + i.inner.s) < n), dtype=bool) {C_2[(((i.outer*4) + i.inner.s)*stride_1)] = ((float32*)A_2[(((i.outer*4) + i.inner.s)*stride)] + (float32*)B_2[(((i.outer*4) + i.inner.s)*stride_2)])}}}
}
對比不同的 schedule
下面我們來對比以下之前提到的不同 schedule:
baseline = log[0][1]
print("%s\t%s\t%s" % ("Operator".rjust(20), "Timing".rjust(20), "Performance".rjust(20)))
for result in log:print("%s\t%s\t%s"% (result[0].rjust(20), str(result[1]).rjust(20), str(result[1] / baseline).rjust(20)))
此處輸出:
Operator Timing Performancenumpy 7.98278022557497e-06 1.0naive 5.9189e-06 0.7414584684465222
parallel 4.9771999999999995e-06 0.6234920490550659vector 1.6127399999999997e-05 2.0202735819196875
注意:Code Specialization
代碼專門化
正如我們所看到的,
A、B和C的聲明都采用相同的形狀參數n。TVM將利用這一點,只向 kernel 傳遞一個 shape 參數,我們在打印的設備代碼中找到它。這是專門化化的一種形式。在 host 端,TVM 將自動生成檢查代碼,以檢查參數中的約束。因此,如果將具有不同形狀的數組傳遞到 fadd 中,將引發錯誤。
我們可以做更多的專門化。例如,我們可以在計算聲明中寫入
n=tvm.runtime.convert(1024)而不是n=te.var(“n”)。生成的函數將只獲取長度為1024的向量。
我們已經定義、調度并編譯了一個向量加法運算符,然后可以在 TVM Runtime 執行它。我們可以將算子保存為庫,稍后可以使用 TVM Runtime 加載該庫。
針對GPU的矩陣加法(可選)
在介紹保存與加載自定義算子庫的方法之前,我們先來看一下如何針對 GPU 做矩陣加法。
TVM能夠針對多種體系結構。在本例,我們將針對GPU中矢量加法的編譯。
# 本段代碼默認不運行,如果想要運行的話,請將 ``run_cuda = True``run_cuda = False
if run_cuda:# 這里的 target 需要根據自己的 GPU 類型修改:# NVIDIA:cuda# Radeon:rocm# OpenCL:opencltgt_gpu = tvm.target.Target(target="cuda", host="llvm")# 重建 schedulen = te.var("n")A = te.placeholder((n,), name="A")B = te.placeholder((n,), name="B")C = te.compute(A.shape, lambda i: A[i] + B[i], name="C")print(type(C))s = te.create_schedule(C.op)bx, tx = s[C].split(C.op.axis[0], factor=64)################################################################################# 最后,我們必須將迭代軸bx和tx綁定到GPU計算網格中的線程。# 樸素的 schedule 對GPU無效,這些是允許我們生成在GPU上運行的代碼的特定構造。s[C].bind(bx, te.thread_axis("blockIdx.x"))s[C].bind(tx, te.thread_axis("threadIdx.x"))####################################################################### 編譯# -----------# 在指定完 schdule 之后,我們可以將其編譯成一個 TVM 函數。默認情況下,TVM編譯成一個 type-erased 函 # 數,可以從python端直接調用該函數。# 在下一行中,我們使用 tvm.build 來創建一個函數。build 函數采用 schedule、函數所需的簽名(包括輸如和輸出)以及我們要編譯到的目標語言。# 編譯 fadd 的結果是一個GPU設備函數(如果涉及GPU)以及一個調用 GPU 函數的 host wrapper。fadd是生成的主機包裝函數,它在內部包含對生成的設備函數的引用。fadd = tvm.build(s, [A, B, C], target=tgt_gpu, name="myadd")################################################################################# 編譯過的 TVM 函數會有一個簡潔的 C API,它可以被任意的語言調用## 我們提供一個 Python 的最小的數組 API 來幫助快速的測試和原型化# 該數組 API 是基于 `DLPack <https://github.com/dmlc/dlpack>`_ 標準.## - 我們首先創建一個 GPU 設備# - 然后 tvm.nd.array 從 GPU 拷貝數據# - ``fadd`` 運行真正的計算# - ``numpy()`` 從 GPU 數組拷貝回 CPU (這樣我們就能驗證正確性了).## 請注意,將數據復制到 GPU 上的內存和從中復制數據是必需的步驟。dev = tvm.device(tgt_gpu.kind.name, 0)n = 1024a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)fadd(a, b, c)tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())################################################################################# 檢查生成的 GPU 代碼# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~# 我們可以檢查在 TVM 中生成的代碼,tvm.build 的結果是一個 TVM 模塊。fadd 是一個 host 模塊其中包含 # host wrapper 的 host module,它同樣包含一個CUDA(GPU)設備模塊## 下面的代碼取得設備模塊并打印內容代碼if (tgt_gpu.kind.name == "cuda"or tgt_gpu.kind.name == "rocm"or tgt_gpu.kind.name.startswith("opencl")):dev_module = fadd.imported_modules[0]print("-----GPU code-----")print(dev_module.get_source())else:print(fadd.get_source())
保存和加載編譯過的模塊
保存編譯過的模塊
除了運行時編譯之外,我們還可以將編譯后的模塊保存到一個文件中,并在以后重新加載。下面的代碼執行以下步驟:
- 它將編譯后的主機模塊保存到一個對象文件中。
- 然后將設備模塊保存到 ptx 文件中。
- cc.create_shared 調用編譯器(gcc)來創建共享庫
from tvm.contrib import cc
from tvm.contrib import utilstemp = utils.tempdir()
fadd.save(temp.relpath("myadd.o"))
if tgt.kind.name == "cuda":fadd.imported_modules[0].save(temp.relpath("myadd.ptx"))
if tgt.kind.name == "rocm":fadd.imported_modules[0].save(temp.relpath("myadd.hsaco"))
if tgt.kind.name.startswith("opencl"):fadd.imported_modules[0].save(temp.relpath("myadd.cl"))
cc.create_shared(temp.relpath("myadd.so"), [temp.relpath("myadd.o")])
print(temp.listdir())
此處輸出:
['myadd.o', 'myadd.so']
注意:Module Storage Format
模塊存儲格式
CPU(Host)模塊直接保存為共享庫(.so)。設備代碼可以有多種自定義格式。在我們的示例中,設備代碼存儲在 ptx 中,元數據在 json 文件中。它們可以通過導入單獨加載和鏈接。
加載編譯過的模塊
我們可以從文件系統加載已編譯的模塊并運行代碼。以下代碼分別加載主機和設備模塊,并將它們鏈接在一起。我們可以驗證新加載的函數是否有效。
fadd1 = tvm.runtime.load_module(temp.relpath("myadd.so"))
if tgt.kind.name == "cuda":fadd1_dev = tvm.runtime.load_module(temp.relpath("myadd.ptx"))fadd1.import_module(fadd1_dev)if tgt.kind.name == "rocm":fadd1_dev = tvm.runtime.load_module(temp.relpath("myadd.hsaco"))fadd1.import_module(fadd1_dev)if tgt.kind.name.startswith("opencl"):fadd1_dev = tvm.runtime.load_module(temp.relpath("myadd.cl"))fadd1.import_module(fadd1_dev)fadd1(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
將所有東西打包在一個庫中
在上面的示例中,我們分別存儲設備和主機代碼。TVM 還支持將所有內容導出為一個共享庫。在 hood 下,我們將設備模塊打包成二進制blob,并將它們與主機代碼鏈接在一起。目前我們支持Metal、OpenCL和CUDA模塊的包裝。
fadd.export_library(temp.relpath("myadd_pack.so"))
fadd2 = tvm.runtime.load_module(temp.relpath("myadd_pack.so"))
fadd2(a, b, c)
tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
注意:Runtime API and Thread Safety
運行時API與線程安全
TVM 的編譯模塊并不依賴于 TVM 編譯器。它們只依賴于最小 Runtime Library。TVM Runtime Library 包裝設備驅動程序,并向編譯函數提供線程安全和設備無關調用。
這意味著我們可以從任何GPU上的任何線程調用已編譯的TVM函數,前提是您已經為該GPU編譯了代碼。
生成OpenCL代碼
TVM 為多種后端提供代碼生成功能。我們還可以生成在 CPU 后端上運行的 OpenCL 代碼或 LLVM 代碼。
下面的代碼可以生成OpenCL代碼,在OpenCL設備上創建數組,并驗證代碼的正確性。
if tgt.kind.name.startswith("opencl"):fadd_cl = tvm.build(s, [A, B, C], tgt, name="myadd")print("------opencl code------")print(fadd_cl.imported_modules[0].get_source())dev = tvm.cl(0)n = 1024a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)fadd_cl(a, b, c)tvm.testing.assert_allclose(c.numpy(), a.numpy() + b.numpy())
注意:TE Scheduling Primitives
TE 調度原語
TVM 包括許多不同的調度原語:
split:按定義的因子將指定軸拆分為兩個軸。
tile:平鋪將按定義的因子沿兩個軸分割計算。
fuse:融合一次計算的兩個連續軸。
reorder:可以將計算軸重新排序為定義的順序。
bind:可以將計算綁定到特定線程,在GPU編程中很有用。
compute_at:默認情況下,TVM將在函數的最外層或根計算張量。compute_at指定應在另一個運算符的第一個計算軸上計算一個張量。
compute_inline:當標記為inline時,計算將展開,然后插入到需要張量的地址中。
compute_root:將計算移動到函數的最外層或根。這意味著,在進入下一個階段之前,將對計算階段進行完全計算。可以在Schedule primitives 文檔頁面中找到這些原語的完整描述。
示例二:用TE手動優化矩陣乘
現在,我們將考慮第二個更高級一些的示例,演示如何用 18 行 Python 代碼 TVM 加速一個共同的矩陣乘法運算 18倍。
矩陣乘法是一種計算密集型運算。要獲得良好的CPU性能,有兩個重要的優化:
- 提高內存訪問的緩存命中率。高緩存命中率可以加速復雜的數值計算和熱點內存訪問。這要求我們將源內存訪問模式轉換為適合緩存策略的模式。
- SIMD(單指令多數據),也稱為矢量處理單元。在每個循環中,SIMD 都可以處理一小批數據,而不是處理單個值。這要求我們以統一模式轉換循環體中的數據訪問模式,以便LLVM 后端可以將其 lower 到 SIMD。
本教程中使用的技術是這個倉庫中提到的技巧的一部分。其中一些已被 TVM 抽象自動使用,但由于 TVM 的一些約束,有一些無法自動使用。
準備工作和性能baseline
我們首先采集 numpy 實現的矩陣乘的數據:
import tvm
import tvm.testing
from tvm import te
import numpy# 矩陣的尺寸:
# (M, K) x (K, N)
# 你可以自己試一些不同的尺寸,有時候 TVM 的優化結果會好于含 MKL 的numpy
M = 1024
K = 1024
N = 1024# tvm 中默認的數據類型
dtype = "float32"# 與之前一樣,這里可以根據自己的處理器及其是否支持某些指令集來改變 targettarget = tvm.target.Target(target="llvm", host="llvm")
dev = tvm.device(target.kind.name, 0)# 隨機生成一些 tensor 用于測試
a = tvm.nd.array(numpy.random.rand(M, K).astype(dtype), dev)
b = tvm.nd.array(numpy.random.rand(K, N).astype(dtype), dev)# 重復實驗,得到 numpy 的矩陣乘實現的 baseline
np_repeat = 100
np_running_time = timeit.timeit(setup="import numpy\n""M = " + str(M) + "\n""K = " + str(K) + "\n""N = " + str(N) + "\n"'dtype = "float32"\n'"a = numpy.random.rand(M, K).astype(dtype)\n""b = numpy.random.rand(K, N).astype(dtype)\n",stmt="answer = numpy.dot(a, b)",number=np_repeat,
)
print("Numpy running time: %f" % (np_running_time / np_repeat))answer = numpy.dot(a.numpy(), b.numpy())
此處輸出:
Numpy running time: 0.009308
現在,我們用 TVM TE 編寫一個基本矩陣乘法,并驗證它產生的結果與numpy實現相同。我們還編寫了一個函數,它將幫助我們度量進度優化的性能。
# 使用 TE 實現的 TVM 的矩陣乘
k = te.reduce_axis((0, K), "k")
A = te.placeholder((M, K), name="A")
B = te.placeholder((K, N), name="B")
C = te.compute((M, N), lambda x, y: te.sum(A[x, k] * B[k, y], axis=k), name="C")# 默認 schedule
s = te.create_schedule(C.op)
func = tvm.build(s, [A, B, C], target=target, name="mmult")c = tvm.nd.array(numpy.zeros((M, N), dtype=dtype), dev)
func(a, b, c)
tvm.testing.assert_allclose(c.numpy(), answer, rtol=1e-5)def evaluate_operation(s, vars, target, name, optimization, log):func = tvm.build(s, [A, B, C], target=target, name="mmult")assert funcc = tvm.nd.array(numpy.zeros((M, N), dtype=dtype), dev)func(a, b, c)tvm.testing.assert_allclose(c.numpy(), answer, rtol=1e-5)evaluator = func.time_evaluator(func.entry_name, dev, number=10)mean_time = evaluator(a, b, c).meanprint("%s: %f" % (optimization, mean_time))log.append((optimization, mean_time))log = []evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="none", log=log)
此處輸出:
none: 3.109406
讓我們看一下使用 TVM lower 函數的算子和默認 schedule 的中間表示 IR。請注意,該實現本質上是矩陣乘法的簡單實現,在 A 和 B 矩陣的索引上使用三個嵌套循環。
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {for (x: int32, 0, 1024) {for (y: int32, 0, 1024) {C_2[((x*1024) + y)] = 0f32for (k: int32, 0, 1024) {C_2[((x*1024) + y)] = ((float32*)C_2[((x*1024) + y)] + ((float32*)A_2[((x*1024) + k)]*(float32*)B_2[((k*1024) + y)]))}}}
}
優化1:blocking阻塞
提高緩存命中率的一個重要技巧是阻塞,在這種情況下,我們可以構造內存訪問,使塊內部是具有高內存局部性的小鄰域。在本教程中,我們選擇塊因子 32。這會使得一個塊填充內存的 32*32*sizeof(float)區域。這對應于 4KB 的緩存大小,和一級緩存 32KB 的參考緩存大小。
我們首先為 C 操作創建一個默認的調度,然后使用指定的塊因子對其應用一個 tile 調度原語,調度原語以向量 [x_-outer,y_-outer,x_-inner,y_-inner] 的形式返回從最外層到最內層的循環順序。然后,我們得到操作輸出的縮減軸,并使用因子4對其執行拆分操作。這個因素不會直接影響我們現在正在進行的阻塞優化,但在以后應用矢量化時會很有用。
現在操作已被阻塞,我們可以對計算進行重新排序,將簡化操作放入計算的最外層循環中,從而幫助確保被阻塞的數據仍保留在緩存中。這就完成了 schedule,我們可以構建和測試與原始 schedule 相比的性能。
bn = 32# Blocking by loop tiling
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)# Hoist reduction domain outside the blocking loop
s[C].reorder(xo, yo, ko, ki, xi, yi)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="blocking", log=log)
此處輸出:
blocking: 0.291928
通過重新排序計算以利用緩存,我們可以看到計算性能的顯著提高。現在,打印內部表示并將其與原始表示進行比較:
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {for (y.inner.init: int32, 0, 32) {C_2[((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)) + y.inner.init)] = 0f32}}for (k.outer: int32, 0, 256) {for (k.inner: int32, 0, 4) {for (x.inner: int32, 0, 32) {for (y.inner: int32, 0, 32) {C_2[((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)) + y.inner)] = ((float32*)C_2[((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)) + y.inner)] + ((float32*)A_2[((((x.outer*32768) + (x.inner*1024)) + (k.outer*4)) + k.inner)]*(float32*)B_2[((((k.outer*4096) + (k.inner*1024)) + (y.outer*32)) + y.inner)]))}}}}}}
}
優化2: vectorization矢量化
另一個重要的優化技巧是矢量化。當內存訪問模式一致時,編譯器可以檢測到該模式并將連續內存傳遞給 SIMD 向量處理器。在TVM中,我們可以利用這個硬件特性,使用矢量化接口來提示編譯器這個模式。
在本教程中,我們選擇對內部循環行數據進行矢量化,因為它已經是我們之前優化中的緩存友好型數據。
# 應用矢量化的優化方式
s[C].vectorize(yi)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="vectorization", log=log)# 矢量化之后生成的 IR
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
vectorization: 0.331263
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {C_2[ramp((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (k.inner: int32, 0, 4) {for (x.inner: int32, 0, 32) {C_2[ramp((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)), 1, 32)] = ((float32x32*)C_2[ramp((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.inner*1024)) + (k.outer*4)) + k.inner)], 32)*(float32x32*)B_2[ramp((((k.outer*4096) + (k.inner*1024)) + (y.outer*32)), 1, 32)]))}}}}}
}
優化3:Loop Permutation循環置換
如果我們看一下上面的 IR,我們可以看到內環行數據被矢量化,B 被轉換成 PackedB(這在內環的(float32x32)B2部分中很明顯)。PackedB 的遍歷現在是順序的。因此,我們將研究 A 的訪問模式。在當前 schdule中,A 是逐列訪問的,這對緩存不友好。如果我們改變嵌套循環順序 ki 和內部軸 xi,對 A 的訪問模式將變得更加緩存友好。
s = te.create_schedule(C.op)
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)# re-ordering
s[C].reorder(xo, yo, ko, xi, ki, yi)
s[C].vectorize(yi)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="loop permutation", log=log
)# 再一次打印新生成的 IR
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
loop permutation: 0.113750
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {C_2[ramp((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.inner: int32, 0, 32) {for (k.inner: int32, 0, 4) {C_2[ramp((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)), 1, 32)] = ((float32x32*)C_2[ramp((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.inner*1024)) + (k.outer*4)) + k.inner)], 32)*(float32x32*)B_2[ramp((((k.outer*4096) + (k.inner*1024)) + (y.outer*32)), 1, 32)]))}}}}}
}
優化4:Array Packing數組打包
另一個重要技巧是數組打包。此技巧是對陣列的存儲維度重新排序,以便在展平后將特定維度上的連續訪問模式轉換為序列模式。
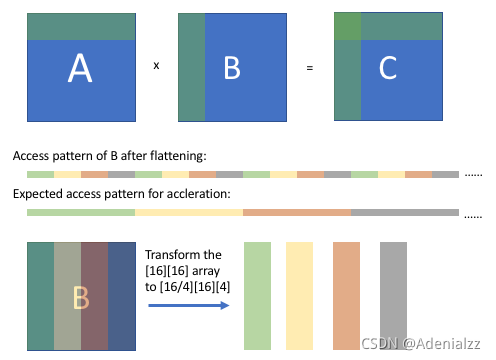
如上圖所示,在阻塞計算后,我們可以觀察到 B 的陣列訪問模式(平坦后),它是規則的但不連續的。我們希望經過一些轉換后,我們可以得到一個連續的訪問模式。通過將[16][16]數組重新排序為[16/4][16][4]數組,在從壓縮數組中獲取相應值時,B 的訪問模式將是順序的。
為了實現這一點,我們必須從一個新的默認 schedule 開始,考慮到 B 的新 wrapper。花點時間對此進行討論是值得的:TE 是一種用于編寫優化算子的功能強大的表達性語言,但它通常需要一些底層算法、數據結構,以及您正在編寫的硬件 target。在本教程的后面,我們將討論讓 TVM 承擔這一負擔的一些選擇。不管怎樣,讓我們繼續新的優化 schedule。
# 我們要輕微地重寫算法
packedB = te.compute((N / bn, K, bn), lambda x, y, z: B[y, x * bn + z], name="packedB")
C = te.compute((M, N),lambda x, y: te.sum(A[x, k] * packedB[y // bn, k, tvm.tir.indexmod(y, bn)], axis=k),name="C",
)s = te.create_schedule(C.op)xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)s[C].reorder(xo, yo, ko, xi, ki, yi)
s[C].vectorize(yi)x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="array packing", log=log)# 這里是數組打包之后生成的 IR
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
array packing: 0.224114
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {allocate(packedB: Pointer(global float32x32), float32x32, [32768]), storage_scope = global {for (x: int32, 0, 32) "parallel" {for (y: int32, 0, 1024) {packedB[ramp(((x*32768) + (y*32)), 1, 32)] = (float32x32*)B_2[ramp(((y*1024) + (x*32)), 1, 32)]}}for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {C_2[ramp((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.inner: int32, 0, 32) {for (k.inner: int32, 0, 4) {C_2[ramp((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)), 1, 32)] = ((float32x32*)C_2[ramp((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.inner*1024)) + (k.outer*4)) + k.inner)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + (k.inner*32)), 1, 32)]))}}}}}}
}
優化5:Optimizing Block Writing Through Caching通過緩存優化塊寫入
到目前為止,我們所有的優化都集中在高效地訪問和計算來自 A 和 B 矩陣的數據,以計算C矩陣。阻塞優化后,操作員將結果逐塊寫入 C,并且訪問模式不是順序的。我們可以通過使用順序緩存數組來解決這個問題,使用cache_write、compute_at 和 unroll 的組合來保存塊結果,并在所有塊結果就緒時寫入到 C。
s = te.create_schedule(C.op)# Allocate write cache
CC = s.cache_write(C, "global")xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)# Write cache is computed at yo
s[CC].compute_at(s[C], yo)# New inner axes
xc, yc = s[CC].op.axis(k,) = s[CC].op.reduce_axis
ko, ki = s[CC].split(k, factor=4)
s[CC].reorder(ko, xc, ki, yc)
s[CC].unroll(ki)
s[CC].vectorize(yc)x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="block caching", log=log)# Here is the generated IR after write cache blocking.
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
block caching: 0.224213
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {allocate(packedB: Pointer(global float32x32), float32x32, [32768]), storage_scope = global;allocate(C.global: Pointer(global float32), float32, [1024]), storage_scope = global {for (x: int32, 0, 32) "parallel" {for (y: int32, 0, 1024) {packedB[ramp(((x*32768) + (y*32)), 1, 32)] = (float32x32*)B_2[ramp(((y*1024) + (x*32)), 1, 32)]}}for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.c.init: int32, 0, 32) {C.global[ramp((x.c.init*32), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.c: int32, 0, 32) {C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[(((x.outer*32768) + (x.c*1024)) + (k.outer*4))], 32)*(float32x32*)packedB[ramp(((y.outer*32768) + (k.outer*128)), 1, 32)]))C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.c*1024)) + (k.outer*4)) + 1)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + 32), 1, 32)]))C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.c*1024)) + (k.outer*4)) + 2)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + 64), 1, 32)]))C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.c*1024)) + (k.outer*4)) + 3)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + 96), 1, 32)]))}}for (x.inner: int32, 0, 32) {for (y.inner: int32, 0, 32) {C_2[((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)) + y.inner)] = (float32*)C.global[((x.inner*32) + y.inner)]}}}}}
}
優化6:Parallelization并行化
# 并行
s[C].parallel(xo)x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="parallelization", log=log
)# 這里是并行化之后的 IR
print(tvm.lower(s, [A, B, C], simple_mode=True))
此處輸出:
parallelization: 0.067949
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], []),B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], [])}buffer_map = {A_1: A, B_1: B, C_1: C} {allocate(packedB: Pointer(global float32x32), float32x32, [32768]), storage_scope = global {for (x: int32, 0, 32) "parallel" {for (y: int32, 0, 1024) {packedB[ramp(((x*32768) + (y*32)), 1, 32)] = (float32x32*)B_2[ramp(((y*1024) + (x*32)), 1, 32)]}}for (x.outer: int32, 0, 32) "parallel" {allocate(C.global: Pointer(global float32), float32, [1024]), storage_scope = global;for (y.outer: int32, 0, 32) {for (x.c.init: int32, 0, 32) {C.global[ramp((x.c.init*32), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.c: int32, 0, 32) {C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[(((x.outer*32768) + (x.c*1024)) + (k.outer*4))], 32)*(float32x32*)packedB[ramp(((y.outer*32768) + (k.outer*128)), 1, 32)]))C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.c*1024)) + (k.outer*4)) + 1)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + 32), 1, 32)]))C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.c*1024)) + (k.outer*4)) + 2)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + 64), 1, 32)]))C.global[ramp((x.c*32), 1, 32)] = ((float32x32*)C.global[ramp((x.c*32), 1, 32)] + (broadcast((float32*)A_2[((((x.outer*32768) + (x.c*1024)) + (k.outer*4)) + 3)], 32)*(float32x32*)packedB[ramp((((y.outer*32768) + (k.outer*128)) + 96), 1, 32)]))}}for (x.inner: int32, 0, 32) {for (y.inner: int32, 0, 32) {C_2[((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)) + y.inner)] = (float32*)C.global[((x.inner*32) + y.inner)]}}}}}
}
矩陣乘例子的總結
在僅用 18 行代碼應用上述簡單優化之后,我們生成的代碼就可以得到與使用數學內核庫(MKL)的 numpy 接近的性能。我們剛才一直都記錄了性能,因此在這里可以直接比較結果:
baseline = log[0][1]
print("%s\t%s\t%s" % ("Operator".rjust(20), "Timing".rjust(20), "Performance".rjust(20)))
for result in log:print("%s\t%s\t%s"% (result[0].rjust(20), str(result[1]).rjust(20), str(result[1] / baseline).rjust(20)))
此處輸出:
Operator Timing Performancenone 3.1094061458 1.0blocking 0.29192816779999997 0.09388550549895809vectorization 0.3312631714 0.10653583220302389
loop permutation 0.1137497149 0.036582456445468314array packing 0.2241142794 0.07207623221003798block caching 0.22421289339999997 0.07210794694763607parallelization 0.0679485881 0.021852593361526892
請注意,以上的輸出反映的是非獨占 Docker 容器上的運行時間,因此并不可靠。強烈建議您自己運行本教程,觀察 TVM 實現的性能增益,并仔細閱讀每個示例,以了解矩陣乘法運算的迭代改進。
總結
如前所述,如何使用 TE 和調度原語應用優化可能需要一些底層架構和算法的知識。然而,TE 設計為更復雜的算法是為了可以搜索潛在的優化。有了本 TE 簡介中的知識,我們現在可以開始探索 TVM 如何自動化進度優化過程。
本教程提供了使用向量加法和矩陣乘法示例的TVM張量表達式(TE)工作流演練。一般的工作流程是:
-
通過一系列操作描述您的計算。
-
描述我們希望如何計算和使用調度原語。
-
編譯到我們想要的目標函數。
-
保存要稍后加載的函數(可選)。
接下來的教程將擴展矩陣乘法示例,并展示如何使用可調參數構建矩陣乘法和其他操作的通用模板,這些參數使得我們能夠自動優化特定平臺的計算。
Ref:
https://tvm.apache.org/docs/tutorial/tensor_expr_get_started.html



















