TVM:設計與架構
本文檔適用于想要了解 TVM 架構和/或積極開發項目的開發人員。頁面組織如下:
-
示例編譯流程概述了 TVM 將模型的高層描述轉換為可部署模塊所采取的步驟。要開始使用,請先閱讀本節。
-
邏輯架構組件部分描述了邏輯組件。后面的部分是針對每個邏輯組件的特定指南,按組件的名稱組織。
-
設備/目標交互描述了 TVM 如何與每種支持的物理設備和代碼生成目標進行交互。
-
請查看開發人員操作指南以獲取有用的開發技巧。
本指南提供了架構的一些補充視圖。首先,我們回顧了一個端到端的編譯流程,并討論了關鍵的數據結構和轉換。這種基于運行時的視圖側重于運行編譯器時每個組件的交互。然后我們將回顧代碼庫的邏輯模塊及其關系。這部分提供了設計的靜態總體視圖。
示例編譯流程
在部分,我們將研究編譯器中的示例編譯流程。 下圖展示了該流程。 總體來說,它包含幾個步驟:
-
導入:前端組件將模型引入到 IRModule 中,IRModule 包含內部表示模型的函數集合。
-
轉換:編譯器將一個 IRModule 轉換為另一個功能等效或近似等效(例如在量化的情況下)IRModule。 許多轉換與目標(后端)無關。目標轉換pipeline的配置還可以根據具體設備目標改變。
-
目標翻譯:編譯器將 IRModule 翻譯(代碼生成 codegen )為目標指定的可執行格式。 目標翻譯結果被封裝為一個runtime.Module,可以在目標運行時環境中導出、加載和執行。
-
運行時執行:用戶加載一個 runtime.Module 并在支持的運行時環境中運行編譯好的函數。
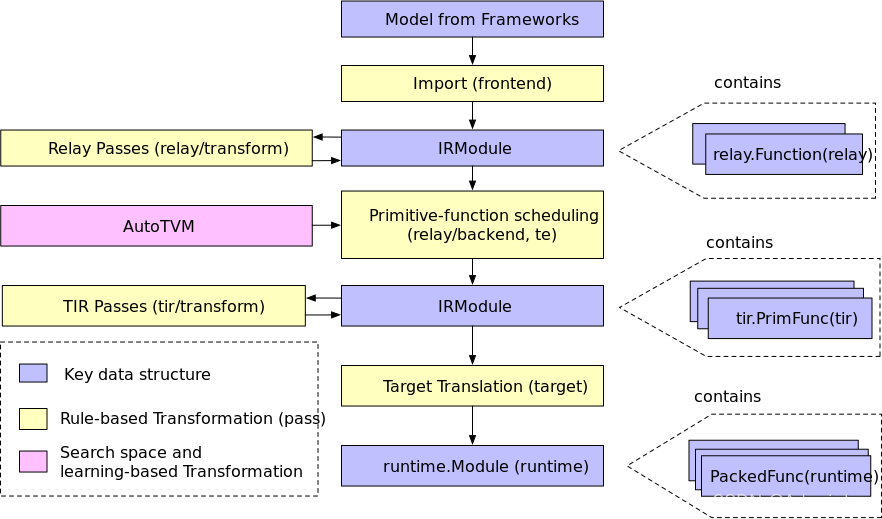
關鍵數據結構
設計和理解復雜系統的最佳方法之一是識別關鍵數據結構和操作(轉換)這些數據結構的 API。一旦我們確定了關鍵數據結構,我們就可以將系統分解為邏輯組件,這些邏輯組件要么定義關鍵數據結構的集合,要么定義數據結構之間的轉換。
IRModule 是全棧中使用的基本數據結構。 IRModule(中間表示模塊)包含一組函數。目前,我們支持兩種基本的函數變體。
-
relay::Function 是一種高層程序表示。一個 relay.Function 通常對應一個端到端的模型。您可以將 relay::Function 視為一張計算圖,它額外支持控制流、遞歸和復雜數據結構。
-
tir::PrimFunc 是一種低層程序表示,它包含包括循環嵌套選擇、多維加載/存儲、線程和向量/張量指令在內的元素。它通常用于表示在模型中執行(可能是經過融合的)層的算子程序。
在編譯過程中,一個中繼函數可能會被 lowered 為多個 tir::PrimFunc 函數和一個調用這些 tir::PrimFunc 函數的高層函數。
轉換
現在我們已經介紹了關鍵數據結構,讓我們談談轉換。每個轉換都可以用于以下目的之一:
-
優化:將程序轉換為等效的,可能更優化的版本。
-
降低(lowering):將程序轉換為更接近目標的較低級別表示。
relay/transform 包含一組優化模型的 pass。優化包括通用的程序優化,例如常量折疊和無用代碼消除,以及特定于張量計算的 pass,例如排布轉換和縮放因子折疊。
在 relay 優化 pipeline 的最后,我們將通過 pass(FuseOps) 以將端到端function(例如 MobileNet)分解為sub-function(例如 conv2d-relu)碎片。我們稱這些 function 碎片。這個過程幫助我們將原始問題分為兩個子問題:
-
每個 sub-function 的編譯和優化。
-
整體執行結構:我們需要對生成的 sub-function 進行一系列調用來執行整個模型。
我們使用低層 tir 階段來編譯和優化每個 sub-function。對于具體的目標,我們也可以直接進入目標翻譯階段并使用外部代碼生成器。
有幾種不同的方法(在 relay/后端)來處理對整體執行問題的調用。對于具有已知形狀且沒有控制流的簡單模型,我們可以 lower 為將執行結構存儲在圖中的 graph executor。我們還支持用于動態執行的虛擬機后端。最后,我們計劃支持 AOT 編譯,將高級執行結構編譯成可執行和生成的原語函數。所有這些執行模式都被一個統一的 runtime.Module 接口封裝,我們將在本文的后半部分討論。
tir/transform 包含 TIR 層次的函數的轉換 pass。許多 tir pass 的目的是 lowering。例如,通過將多維訪問扁平化到一維指針訪問,將內在函數擴展為特定于目標的內在函數,以及修飾函數入口以滿足運行時調用約定。當然,也有優化 pass,比如訪問索引簡化和死代碼消除。
許多低級優化可以在目標階段由 LLVM、CUDA C 和其他目標編譯器處理。因此,我們將寄存器分配等低層優化留給下游編譯器,只關注它們未涵蓋的優化。
搜索空間和基于學習的轉換
到目前為止,我們描述的轉換過程是確定性的和基于規則的。 TVM 的一個設計目標是支持針對不同硬件平臺的高性能代碼優化。為此,我們需要研究盡可能多的優化選擇,包括但不限于多維張量訪問、循環平鋪行為、特殊加速器內存層次結構和線程。
很難定義一個啟發式來做出所有選擇。相反,我們將采用基于搜索和學習的方法。我們首先定義一組可以用來轉換程序的操作。示例操作包括循環轉換、內聯、矢量化。我們將這些動作稱為調度原語 (scheduling primitives)。調度原語的集合定義了我們可以對程序進行的可能優化的搜索空間。然后系統搜索不同的可能調度序列以選擇最佳調度組合。搜索過程通常由機器學習算法來優化。
一旦搜索完成,我們可以記錄(可能是經過融合的)算子的最佳調度順序。然后編譯器可以查找最佳調度序列并將其應用于程序。值得注意的是,這個調度應用階段與基于規則的轉換完全一樣,使我們能夠與傳統 pass 共享相同的接口約定。
我們使用基于搜索的優化來處理初始 tir 函數生成問題。這部分模塊稱為 AutoTVM(auto_scheduler)。隨著我們繼續開發 TVM ,我們希望將基于學習的轉換擴展到更多領域。
目標轉換
目標轉換階段將 IRModule 轉換為相應的目標可執行格式。 對于 x86 和 ARM 等后端,我們使用 LLVM IRBuilder 來構建內存中的 LLVM IR。 我們還可以生成源級語言,例如 CUDA C 和 OpenCL。 最后,我們支持通過外部代碼生成器將 Relay 函數(子圖)直接轉換為特定目標。 重要的是最終代碼生成階段盡可能輕量級。 絕大多數的轉換和 lowering 應該在目標翻譯階段之前進行。
我們還提供了一個 Target 結構來指定編譯目標。 目標翻譯階段之前的轉換也可能受到目標的影響——例如,目標的向量長度會改變向量化行為。
運行時執行
TVM 運行時的主要目標是提供一個最小的 API,用于以他們選擇的語言加載和執行編譯的工件,包括 Python、C++、Rust、Go、Java 和 JavaScript。 下面的代碼片段顯示了 Python 中的這樣一個示例:
import tvm
# Example runtime execution program in python, with type annotated
mod: tvm.runtime.Module = tvm.runtime.load_module("compiled_artifact.so")
arr: tvm.runtime.NDArray = tvm.nd.array([1, 2, 3], device=tvm.cuda(0))
fun: tvm.runtime.PackedFunc = mod["addone"]
fun(a)
print(a.numpy())
tvm.runtime.Module 封裝了編譯的結果。 runtime.Module 包含一個 GetFunction 方法,用于按名稱獲取 PackedFuncs。
tvm.runtime.PackedFunc 是兩個生成函數的類型擦除函數接口。 runtime.PackedFunc 可以采用以下類型的參數和返回值:POD 類型(int,float)、字符串、runtime.PackedFunc、runtime.Module、runtime.NDArray 和 runtime.Object 的其他子類。
tvm.runtime.Module 和 tvm.runtime.PackedFunc 是模塊化運行時的強大機制。 例如,要在 CUDA 上獲取上述 addone 函數,我們可以使用 LLVM 生成主機端代碼來計算啟動參數(例如線程組的大小),然后從由支持的 CUDAModule 調用另一個 PackedFunc CUDA 驅動程序 API。 相同的機制可用于 OpenCL 內核。
上面的例子只處理了一個簡單的 addone 函數。 下面的代碼片段給出了使用相同接口執行端到端模型的示例:
import tvm
# Example runtime execution program in python, with types annotated
factory: tvm.runtime.Module = tvm.runtime.load_module("resnet18.so")
# Create a stateful graph execution module for resnet18 on cuda(0)
gmod: tvm.runtime.Module = factory["resnet18"](tvm.cuda(0))
data: tvm.runtime.NDArray = get_input_data()
# set input
gmod["set_input"](0, data)
# execute the model
gmod["run"]()
# get the output
result = gmod["get_output"](0).numpy()
主要的收獲是 runtime.Module 和 runtime.PackedFunc 足以封裝操作員級別的程序(例如 addone)以及端到端模型。
總結與討論
綜上所述,編譯流程中的關鍵數據結構有:
-
IRModule:包含relay.Function和tir.PrimFunc
-
runtime.Module:包含 runtime.PackedFunc
編譯的大部分是關鍵數據結構之間的轉換。
-
relay/transform 和 tir/transform 是確定性的基于規則的轉換
-
auto_scheduler 和 autotvm 包含基于搜索的轉換
最后,編譯流程示例只是 TVM 的一個典型用例。 我們將這些關鍵數據結構和轉換公開給 python 和 C++ API。 因此,您可以像使用 numpy 一樣使用 TVM,只是感興趣的數據結構從 numpy.ndarray 更改為 tvm.IRModule。 以下是一些示例用例:
-
使用python API直接構建IRModule。
-
編寫一組自定義轉換(例如自定義量化)。
-
使用 TVM 的 python API 直接操作 IR。
邏輯架構組件
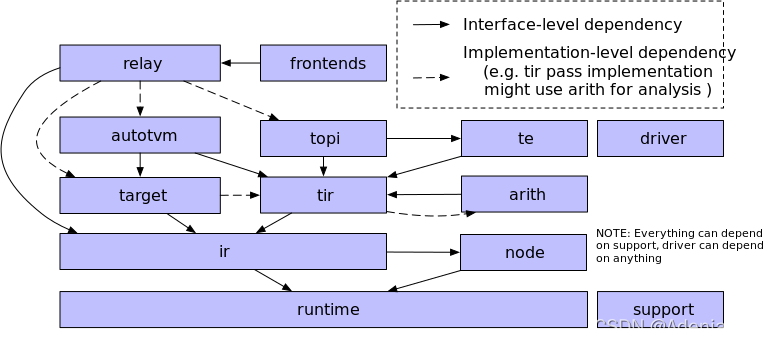
上圖顯示了項目中的主要邏輯組件。 請閱讀以下部分以獲取有關組件及其關系的信息。
tvm/support
支持模塊包含基礎設施最常用的實用程序,例如通用 arena 分配器、套接字和日志記錄。
tvm/runtime
*Runtime (運行時)*是 TVM 的基礎。它提供了加載和執行已編譯工件的機制。運行時定義了一組穩定的標準 C API 來與 Python 和 Rust 等前端語言交互。
runtime::Object 是 TVM 運行時中除 runtime::PackedFunc 之外的主要數據結構之一。它是一個具有類型索引的引用計數基類,以支持運行時類型檢查和向下轉型。對象系統允許開發人員向運行時引入新的數據結構,例如 Array、Map 和新的 IR 數據結構。
除了部署用例,編譯器本身也大量使用 TVM 的運行時機制。所有 IR 數據結構都是 runtime::Object 的子類,因此可以從 Python 前端直接訪問和操作它們。我們使用 PackedFunc 機制向前端公開各種 API。
對不同硬件后端的運行時支持在運行時的子目錄中定義(例如 runtime/opencl)。這些特定于硬件的運行時模塊定義了用于設備內存分配和設備功能序列化的 API。
runtime/rpc 實現了對 PackedFunc 的 RPC 支持。我們可以使用 RPC 機制將交叉編譯的庫發送到遠程設備,并對執行性能進行基準測試。 rpc 基礎架構支持從各種硬件后端收集數據,以進行基于學習的優化。
-
TVM Runtime System
-
Runtime-Specific Information
-
Debugger
-
Putting the VM in TVM: The Relay Virtual Machine
-
Introduction to Module Serialization
-
Device/Target Interactions
tvm/node
節點模塊在 runtime::Object 之上為 IR 數據結構添加了額外的功能。 主要特征包括反射、序列化、結構等價和哈希。
有了 node 模塊,我們可以通過 Python 中的名稱直接訪問 TVM 的 IRNode 的任何字段。
x = tvm.tir.Var("x", "int32")
y = tvm.tir.Add(x, x)
# a and b are fields of a tir.Add node
# we can directly use the field name to access the IR structures
assert y.a == x
我們還可以將任意 IR 節點序列化為 JSON 格式,然后將它們加載回來。 保存/存儲和檢查 IR 節點的能力是使得編譯器更易于訪問的基礎。
tvm/ir
tvm/ir 目錄包含所有 IR 函數變體的統一數據結構和接口。 tvm/ir 中的組件由 tvm/relay 和 tvm/tir 共享,值得注意的包括
-
IRModule
-
Type
-
PassContext 和 Pass
-
Op
不同的函數變體(例如,relay.Function 和 tir.PrimFunc)可以在 IRModule 中共存。 雖然這些變體可能沒有相同的內容表示,但它們使用相同的數據結構來表示類型。 因此,我們使用相同的數據結構來表示這些變體的函數(類型)簽名。 一旦我們明確定義了調用約定,統一類型系統就允許一個函數變體調用另一個函數。 這為未來的跨功能變體優化打開了大門。
我們還提供了一個統一的 PassContext 用于配置 pass 行為,以及通用的復合 pass 來執行 pass 管道。 以下代碼片段給出了 PassContext 配置的示例。
# configure the behavior of the tir.UnrollLoop pass
with tvm.transform.PassContext(config={"tir.UnrollLoop": { "auto_max_step": 10 }}):# code affected by the pass context
Op 是表示所有系統定義的原始運算符/內在函數的通用類。 開發人員可以向系統注冊新的 Ops 以及它們的附加屬性(例如 Op 是否為 elementwise)。
- Pass Infrastructure
tvm/target
target 模塊包含將 IRModule 轉換為目標 runtime.Module 的所有代碼生成器。 它還提供了一個描述目標的通用 Target 類。
通過查詢 target 中的屬性信息和注冊到每個 target id(cuda, opencl) 的 builtin 信息,可以根據target定制編譯 pipeline。
- Device/Target Interactions
tvm/tir
TIR 包含低層程序表示的定義。 我們使用 tir::PrimFunc 來表示可以通過 TIR 通道轉換的函數。 除了 IR 數據結構外,tir 模塊還通過通用 Op 注冊表定義了一組內置內在函數及其屬性,以及 tir/transform 中的轉換 pass。
tvm/arith
該模塊與 TIR 密切相關。 低層代碼生成的關鍵問題之一是分析索引的算術屬性——正性、變量界限和描述迭代器空間的整數集。 arith 模塊提供了一組進行(主要是整數)分析的工具。 TIR pass 可以使用這些分析來簡化和優化代碼。
tvm/te
te 全稱為 “張量表達式”。 這是一個特定領域的語言模塊,它允許我們通過編寫張量表達式來快速構造 tir::PrimFunc 變體。 重要的是,張量表達式本身并不是一個可以存儲到 IRModule 中的自包含函數,而是 IR 的一個片段,我們可以拼接起來構建一個 IRModule。
te/schedule 提供了一組調度原語來控制正在生成的函數。 將來,我們可能會將其中一些調度組件帶到一個tir::PrimFunc 本身。
- InferBound Pass
- Hybrid Frontend Developer Guide
tvm/topi
雖然可以通過 TIR 或張量表達式 (TE) 為每個用例直接構造運算符,但這樣做很乏味。 topi(張量算子清單)提供一組由 numpy 定義的預定義算子(在 TE 或 TIR 中),在深度學習 workload 中很常見。 我們還提供了一組常見的 schedule 模板,以實現跨不同目標平臺的高性能實現。
tvm/relay
Relay 是用于表示完整模型的高層功能 IR。 在 relay.transform 中定義了各種優化。 Relay 編譯器定義了多種方言,每種方言都旨在支持特定的優化風格。 值得注意的包括 QNN(用于導入預量化模型)、VM(用于降低到動態虛擬機)、內存(用于內存優化)。
- Introduction to Relay IR
- Relay Operator Strategy
- Convert Layout Pass
tvm/autotvm
AutoTVM 和 AutoScheduler 都是自動化基于搜索的程序優化的組件。 這正在迅速發展,主要包括:
-
成本模型和特征提取。
-
用于存儲成本模型構建的程序基準結果的記錄格式。
-
一組關于程序轉換的搜索策略。
自動化程序優化仍然是一個活躍的研究領域。 因此,我們嘗試將設計模塊化,以便研究人員可以通過 Python 綁定快速修改組件或應用他們自己的算法,并從 Python 綁定自定義搜索和插件他們的算法。
- Benchmark Performance Log Format
Frontends
前端將來自不同框架的模型攝取到 TVM 中。 tvm.relay.frontend 是模型攝取 API 的命名空間。
- TensorFlow Frontend
Security
- Security Guide
microTVM
- microTVM Design Document
- microTVM Project API
- Model Library Format



















)