Nvidia CUDA初級教程6 CUDA編程一
視頻:https://www.bilibili.com/video/BV1kx411m7Fk?p=7
講師:周斌
GPU架構概覽
- GPU特別使用于:
- 密集計算,高度可并行計算
- 圖形學
- 晶體管主要被用于:
- 執行計算
- 而不是
- 緩存數據
- 控制指令流
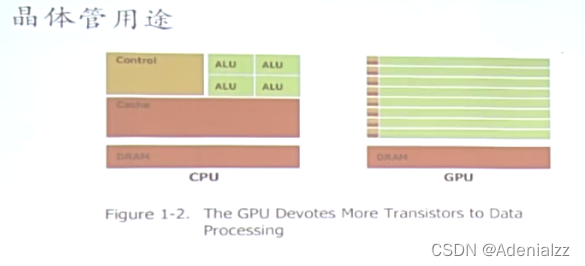
圖中分別是CPU、GPU各個部件所占的芯片面積。可以看到,CPU芯片中大量部分是緩存和控制邏輯,而GPU中則絕大部分都是計算單元。
CUDA編程相關簡介
CUDA的一些信息
- 層次化線程集合
- 共享存儲
- 同步
CUDA術語
主機端和設備端
- HOST - 主機端,通常指CPU
- 采用ANSI標準C語言編程
- Device - 設備端,通常指GPU(數據可并行)
- 采用ANSI標準C的擴展語言編程 (CUDA C)
- HOST 和 Device 擁有各自的存儲器
- CUDA編程
- 包括主機端和設備端兩部分代碼
核
- Kernel 數據并行處理函數
- 通過調用 Kernel 函數在設備端創建輕量級的線程,線程由硬件負責創建并調度
類似于 OpenCL 的 shader?
-
核函數會在 N 個不同的 CUDA 線程上并行執行
// 定義核函數 __global__ void VecAdd(float* a, float* B, float* C) {int i = threadIdx.x;C[i] = A[i] + B[i]; }int main() {// ...// 在N個線程上調用核函數VecAdd<<<1, N>>>(A, B, C); }
CUDA程序的執行
CUDA程序執行的流程大體上是這樣的:當我們在CPU端的代碼是串行執行的(這里簡單地認為指令在CPU上串行執行),當遇到需要并行大量處理數據時,會調用核函數在GPU上進行計算,計算完成后將結果返回給CPU。

線程層次
- Grid - 一維或多維線程塊(block)
- 一維或二維
- Block - 一維線程
- 一維,二維或三維
- 一個 Grid 中的每個 Block 的線程數是一樣的
- Block 內部的每個線程可以:
- 同步 Synchronize
- 訪問共享存儲器 shared memory
一個線程可以類比為一個員工,一個 block 是一個科室,grid 是整個公司。
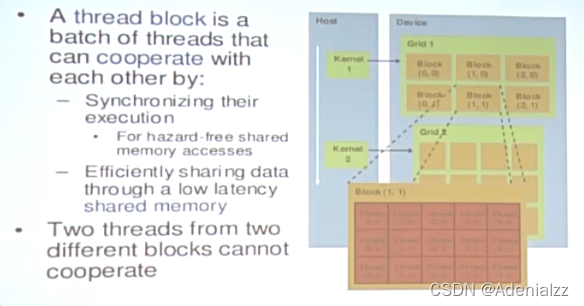
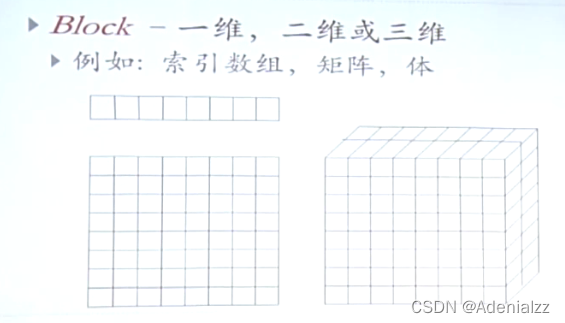
線程ID
每一個線程都有一個索引:threadIdx
- 一維 Block Thread ID == Thread Index
- 二維 Block (Dx, Dy)
- 索引為 (x, y) 的 Thread ID == x + yDy
- 三維 Block (Dx, Dy, Dz)
- 索引為 (x, y) 的 Thread ID == x + yDy + zDxDy
代碼實例
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {int i = threadIdx.x;int j = threadIdx.y;C[i][j] = A[i][j] + B[i][j];
}int main() {int numBlocks = 1;dim3 threadsPerBlock(N, N);MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
}
每個 Block 中的線程的索引是二維的,這在我們處理二維數據(矩陣)時可以很方便地進行對應。
線程數
Thread Block 線程塊
- 線程的的集合
- G80 和 GT200:多達512個線程
- Fermi:多達1024個線程
- 位于相同的處理器核(相同的SM)
- 共享所在核的存儲器

塊索引
- 塊索引:blockIdx
- 維度:blockDim
- 一維,二維或三維
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;if (i < N && j < N)C[i][j] = A[i][j] + B[i][j];
}int main() {// ...dim3 threadsPerBlock(16, 16);dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
}
例如 N = 32
- 每個塊有16x16個線程(跟N無關)
- threadIdx([0, 15], [0, 15])
- Grid 里面有 2x2 個線程塊 block
- blockIdx([0, 1], [0, 1])
- blockDim = 16
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
i = [0, 1] * 16 + [0, 15]
線程塊之間
線程塊彼此之間獨立執行
- 任意順序:并行或串行
- 被任意數量的處理器以任意順序調度
- 處理器的數量具有可擴展性
一個塊內部的線程
一個塊內部的線程有一些重要的特性:
- 共享容量有限的低延遲存儲器 (shared memory)
- 同步執行
- 合并訪存
- __syncThreads()
- barrier - 塊內線程一起等待所有的線程都
- 輕量級線程
CUDA內存傳輸
主機端與設備端
CUDA內存傳輸

-
device 端代碼可以:
- 讀寫該線程的 registers
- 讀寫該線程的local memory
- 讀寫該線程所屬的塊的 shared memory
- 讀寫grid的 global memory
- 只讀grid的 constant memory
-
host 端代碼可以:
- 讀寫grid的 global memory 和 constant memory
-
host 可以從 device 往返傳輸數據
- global memory 全局存儲器
- constant memory 常量存儲器
CUDA內存傳輸函數
- 在設備端分配 global memory:
cudaMalloc() - 釋放存儲空間
cudaFree()
float* Md;
int size = Width * Width * sizof(float);
cudaMalloc((void**)&Md, size);
//...
cudaFree(Md);
注意這里的指針 Md 是指向 device(GPU)上的存儲空間。
- 內存傳輸:
cudaMemcpy()- host to host
- host to device
- device to host
- device to device
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);
示例:矩陣相乘 Matrix Multiply
矩陣相乘簡介
- 向量
- 點乘
- 行優先或列優先
- 每次點乘結果輸出一個元素
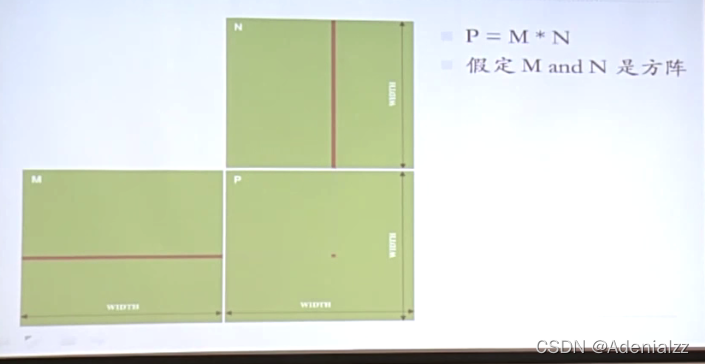
矩陣相乘CPU實現
void MatrixMulOnHost(float* M, float* N, float* P, int width) {for (int i=0; i<width; ++i) {for (int j=0; j<width; ++j) {float sum = 0;for (int k=0; k<width; ++k) {float a = M[i * width + k];float b = N[k * width + j]:sum += a * b;}P[i * width + j] = sum;}}
}
CUDA算法框架
三步走:
int main(void) {// 1 分配device空間// 2 在GPU上,并行計算MatrixMulOnDevice(M, N, P, width);// 3 將結果拷貝回CPU,并釋放device空間return 0;
}
偽代碼如下:
void MatrixMulOnDevice(float* M, float* N, float* P, int Width) {int size = Width * Width * sizeof(float);// 1cudaMalloc(Md, size);cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);cudaMalloc(Nd, size);cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);cudaMalloc(Pd, size);// 2 調用cuda核函數,并行計算// 3cudaMemcpy(P. Pd, size, cudaMemcpyDeivceToHost)cudaFree(Md); cudaFree(Nd); cudaFree(Pd);
}
CUDA C 實現
矩陣相乘樣例
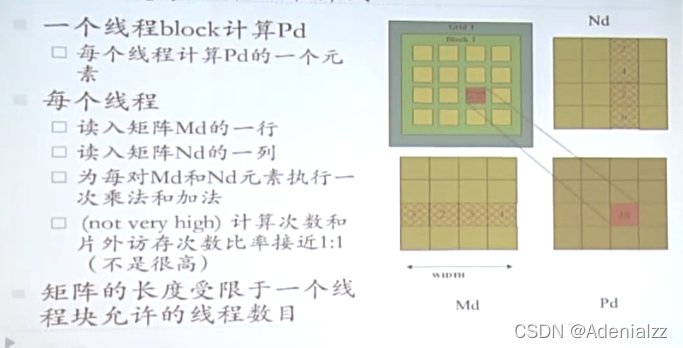
目前版本矩陣相乘的問題
- 在上述算法實現中最主要的性能問題是什么?
- 訪存
- 主要的限制是什么?
- 訪存帶寬













)





