視頻質量評價:挑戰與機遇
轉自:https://zhuanlan.zhihu.com/p/384603663
本文整理自鵬城實驗室助理研究員王海強在LiveVideoStack線上分享上的演講。他通過自身的實踐經驗,詳細講解了視頻質量評價的挑戰與機遇。
文 / 王海強
整理 / LiveVideoStack
大家晚上好,感謝參加今晚的分享。我叫王海強,來自鵬城實驗室。今天我分享的題目是“視頻質量評價的挑戰與機遇”。這是今天要分享的內容。
首先,我會簡單介紹一下什么是視頻質量評價及它的分類。第二部分,我會結合實際業務介紹一下視頻質量評價在業務鏈路中到底有什么作用。接下來會簡單介紹一下目前視頻質量評價在業界應用的現狀、挑戰與機遇。第四部分將會介紹一個我們之前所開發的基于深度學習的視頻質量評價算法。然后,我會宣傳一下在ICME 2021正在舉辦的質量評價競賽。最后是QA環節。
01 視頻質量評價簡介
第一部分是視頻質量評價的簡介。什么是視頻質量評價呢?因為大部分視頻業務是以服務于用戶為目的,以人眼觀看、最終體驗為基準。視頻質量評價致力于衡量視頻的人眼感知質量。

上圖用JPEG壓縮圖像給出一個例子。最左邊圖像是無損的,所以它的分數是1.0最高分。最右邊圖像是JPEG壓縮質量最差的,它的分數非常低,接近最低分0。而中間三個圖像的碼率是逐漸降低的,質量是在逐漸變化的,相應的分數也在逐漸降低。而質量評價的目的就是,對于一個圖像或視頻,我們希望能夠給出這樣一個分數作為參考,再以這個分數為前提去優化系統或者做監控。

這里給出一個H.264壓縮視頻作為例子。因為線上分享播放視頻不是很方便,所以我在這里只給出一個視頻作為例子,其他地方我都是給出圖片例子,但背后的概念都是相通的。
這個是無損的視頻,它的分數為5分,最高分。然后是4分,也是質量非常好的狀態。然后是3分,在臉部已經可以看到一些block了。而2分的質量就已經很模糊了。最后是相當差的質量,我覺得可能沒有人愿意為這種服務而付錢吧。
總體來說,視頻質量評價可以從下面幾個方向來分類。
1.1 視頻質量評價方法分類
第一個就是根據視頻質量評價的方法來分類。

主觀質量評估
如果我們讓人去觀看,并讓人去打分,這叫作主觀質量評估,即依賴人眼觀看并給出打分。這是一個費時費力,而且對環境要求非常嚴格的過程。但是它得到的分數是比較可依賴的,我們經常用這個分數來衡量客觀質量評估算法。
這里的客觀質量評估算法就是,我不可能將所有視頻、所有場景都找人來觀看,我想要一個算法可以自動計算出這個視頻的質量分數。
而衡量一個算法好壞,就是看一下客觀分數與主觀分數的逼近程度。一個好的算法會給出一個接近于主觀分數的估計。
客觀質量評價
具體到客觀質量評估,根據使用多少源視頻的信息,它可以分為三個大類。
第一類是全參考。當我們衡量損傷視頻的時候,無損的源視頻是可用的,我們就可以通過對比兩個視頻的方式作出評價。第二類是無參考。源視頻的任何信息都沒有,我們只使用損傷視頻的信息來衡量其質量。第三類是不太常見的,即部分參考。沒有像素級的源視頻,只從源視頻里提取很少量信息,再用這些信息加上損傷視頻來作估計。
1.2 視頻質量評價內容分類

傳統的視頻質量評價都是對于PGC(Professional Generated Contents),叫作專業制作內容,如傳統VoD、家里看的電視或電影,它們都是由專業人員拍攝,它們的構圖、環境、燈光等各方面都比較好。這種情況下,我們假設它們的無損源視頻就有完美的質量,我們比較難去進一步增強它們的質量。近年來,用戶原創視頻UGC(User Generated Contents)開始興起,比如手機上看的短視頻、直播場景、實時會議場景。一方面,因為這種視頻發出去的源已經經過壓縮了,所以它并沒有完美的質量,例如實時視頻通話就有視頻的損傷。另外一方面,我們作為普通用戶,視頻構圖不好,拍攝有抖動,光照也不好,有些人還會后期處理加濾鏡,看起來好看一些,導致視頻經受多層損傷處理。
總體來說,以評價內容來分,視頻可以分為PGC和UGC的視頻內容,PGC是傳統的研究領域,UGC是近幾年興起的領域。
02 質量評價在視頻業務鏈路中的作用
下面我就結合具體的業務線來介紹質量評價能起到什么作用。
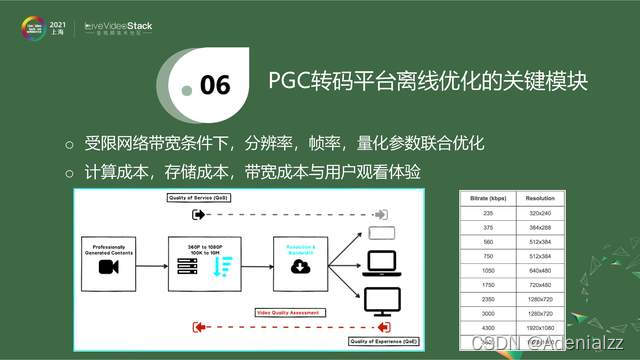
上圖是一個簡化版的PGC轉碼平臺示意圖。對于系統來說,拿到一個原始的、無損的、高分辨率、高幀率的源,一般將其采樣成不同的分辨率,每一個分辨率會壓縮成特定的碼率,這樣經過CDN,根據用戶端可用帶寬,自動選擇一個碼率,然后分發給用戶。
圖中右邊是給出一個碼表,它來自Netflix 2015年的技術帖子,即把一個視頻壓縮到對應的分辨率后,它的碼率就是固定的。當你的可用帶寬是200k~6Mb,每個碼率點分發的視頻分辨率也是固定的,這就是固定碼表。這樣一個系統是單向的,它根據用戶的可用帶寬,決定分發什么,而沒有考慮到視頻的差異性。譬如我剛才播放的視頻,需要的碼率要高一點。現在一個靜止頁面,需要的碼率低一點。這種固定碼給的形式完全忽略了視頻本身的特性,沒有一個從用戶端去feedback的過程。就是說,在受限帶寬下,是動態調整分辨率,還是調整幀率,還是調整具體的量化參數,我們需要一個更好的策略來達到我的目標的碼率。

然后,對于UGC來說,它的播放量有一個長尾效應,也叫作馬太效應、二八效應。它大概類似于一個恐龍的形狀,播放量和點擊量最高的視頻永遠只有一小部分,后面有一個比較長的尾巴,這代表了有相當一部分視頻其實是沒有什么人去看的。如果統計一下,你就會發現,播放量最高的視頻永遠是內容、質量比較好,比較有趣,畫面比較清晰等類似特性。而尾部視頻要么拍攝得不好,要么畫面很渣,要么趣味性不夠。
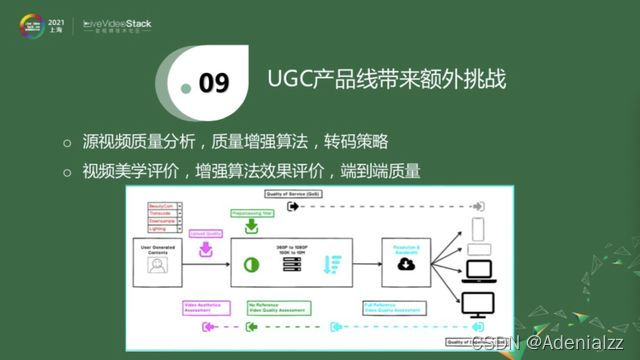
對于UGC視頻來說,除了上面介紹的PGC轉碼平臺,即得到一個上傳的源進行降分辨率、降幀率的分發之外,還有一些額外的工作可以做。譬如說這是一個UP主或者用戶上傳的短視頻,它可能經過了美顏相機處理。而且目前我們的手機是不支持無損拍攝的,手機自己會壓縮一下,否則流量是非常可觀的,而且手機會做一些其他的調整。這時候上傳的視頻質量已經不是無損的。我們在這里需要一個算法來衡量一下,用戶上傳的視頻是不是很好的質量,它是屬于頭部、中部,還是尾部。如果檢測到它是屬于頭部,那它的推送量就更高一些。如果它是屬于脖子這一塊,即不是最優質的視頻,我們是否可以用一些方法將其增強一下,盡量把它變成頭部視頻。我可以選擇性地加入一些處理手段,來進一步增強它的質量。實際情況往往沒那么簡單,我們也需要確認一下,這里是不是已經增強了它的質量。處理之后,后面就是一個類似PGC的轉碼平臺。以上的討論是對于單個模塊的。如果我們把這一切串聯起來,就是從用戶上傳到用戶接收,當整個系統串聯起來的時候,這就是一個比較大的視頻質量評價范疇。因為對某一部分,我們有比較好的估計,那串聯起來的情況,就可能變得復雜很多了。
03 質量評價在業界的挑戰與機遇

目前來說,視頻質量評價在業界經歷了十幾年的發展,但以我的了解,其實視頻質量評價在業界用的還不是特別多。原因也是很客觀的,有如下四點。第一是算力成本,因為視頻質量評價從技術上來說還是相對比較難的問題。比如會議場景,發送端經過騰訊會議后臺轉碼,然后分發到對面的接收端,我想衡量一下接收的視頻質量是否還好。在源端和接收端去做這件事是比較有挑戰性的,因為對于用戶來說,可能百分之五、百分之十的CPU消耗都是很可觀的、甚至是不能接受的一個指標。那么把計算放到轉碼服務器上進行相對來說會好一點,但是也有一定的問題,比如隱私問題,或者是如果算法過于復雜,后臺的壓力問題。第二,不同的業務場景具有不同的業務核心指標。如實時會議要求時延不能太高,不能兩個人說話的時候,一個人等了好幾秒對面才會聽到,然后才回復。第三,雖然視頻質量評估在學術界匯報的結果會比較高,但真正在業務場景下,各種各樣的 bad case都會出現,即如果把一個指標放在線上跑完后就會發現,剩下的工作量可能就是解決各種bad case了。
最后,綜合以上,作為領導或者負責人就會衡量一個問題,這么大的投入,對系統改變這么大,這到底能帶來多少收益?以上問題,導致了視頻質量評價在業界的應用不是很廣泛,雖然感興趣的人有很多。

但是,對于一個視頻業務,不管是PGC還是UGC,競爭是比較激烈的。雖然在目前階段,視頻以內容為王,特別是優質內容,當解決了優質內容之后,你和競品的差異究竟在哪兒,就是你有什么殺手锏,可以讓你的視頻比競品更優秀,我們相信這個答案就是極致的用戶體驗。目前,UGC的視頻質量評價在業界的情況是,現有算法較難滿足業務需要,因為準確度是很有限的。而且大部分算法是對單個失真類型,而UGC視頻是串聯了多個失真視頻類型,這樣綜合下來,它的性能比較有限。另外,新的算法大都處于起步階段,特別是基于深度學習的算法。
04 基于深度學習的視頻質量評價算法設計
我們圍繞著UGC視頻質量評價,特別是無參考算法,也做了一定的探索。這一部分內容我今天先簡單介紹一下,然后在4月份的分享會給出更詳實的數據和更多細節。

相對于全參考視頻質量算法,無參考視頻質量評價面臨著更多的問題。第一,無參考質量評價算法沒有一個原始的無損源做參考,不能從對比的角度來評價質量,而只能從失真視頻里提取有限的信息。另外,我們知道訓練一個深度神經網絡需要的數據量比較大,而目前的關于視頻質量的數據庫的量都比較小,訓練起來是比較有難度的,特別是多失真的場景。
目前在學術界有一些對應的策略,針對第一個無參考源可用的問題,有些學者會使用基于多任務的學習來融合額外信息。這里我會給出一些例子。而對于人工標注數據庫太小的問題,一個策略是使用與主觀分數無關的額外表征來幫助網絡訓練。
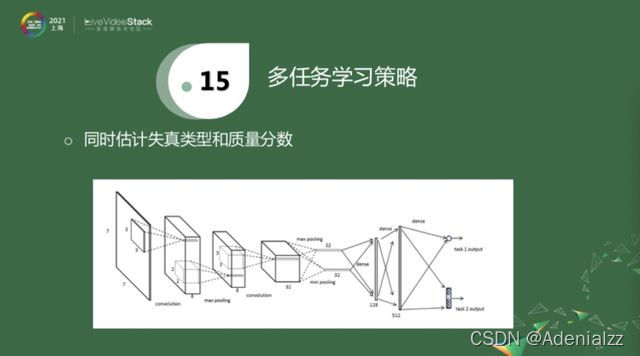
對于第一項多任務學習策略來融合額外信息,我先簡單介紹一下兩個工作。上圖是一個很簡單的神經網絡,經過三層卷積層和兩層全連接層之后,得到一個分數輸出。同時也有另外一個輸出,它是在分數估計的基礎之上額外添加了一個信息,即估計失真類型。就是一方面估計失真類型,另一方面估計客觀分數。因為失真類型相對來說是比較容易獲得的。它的一個比較大的缺陷就是,標注的視頻必須要同時知道這兩個label,才能進行訓練。
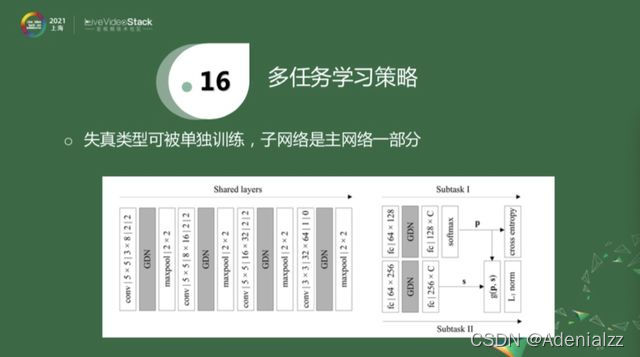
還有一個工作和上面的方法大致類似,就是在一個更復雜的網絡中,前面的系數是被共享的,后面有兩個subtask,一個task去估計失真類型,另外一個task去估計分數。相對于上面網絡的來說,失真類型的參數可以被共享,這一塊是否存在對于分數估計子任務來說是沒有影響的,即上面的網絡是下面的一部分。這樣就有一個好處,當一些視頻沒有分數標記的時候,我們可以對源視頻進行壓縮,只使用失真類型去預訓練這個網絡。當經過預訓練之后,在同時有兩種label的數據庫中,再去fine-tune。即先人工生成一些只包含失真類型去預訓練這個分支,再用同時包含兩種label的數據庫去做進一步的訓練。這是對上面策略的一個改進,即使用多任務策略來引入額外信息,以幫助網絡訓練。
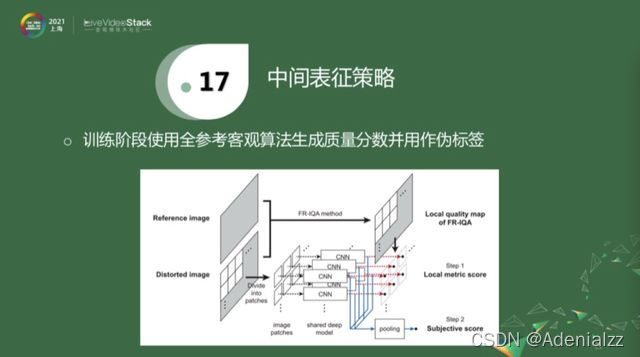
中間表征策略,是最近幾年的工作。對于一個失真圖像和參考圖像,它們沒有標注,就用一些性能比較好的全參考算法去算出偽標簽,再用偽標簽去訓練網絡。訓練階段應該對應于紅線,用得著這些偽標簽。在inference階段,直接從失真圖像拿出patch,經過下面的藍線給出估計,再把它們pull到一塊,得到分數估計。這就是利用偽標簽作為中間表征。
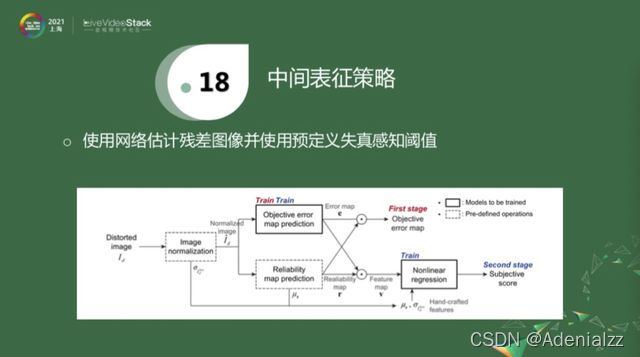
還有一種中間表征策略就是用殘差圖像。殘差圖像就是原始圖像和失真圖像的一個差值,專業術語是residual。給我一個失真圖像,這個分支的學習對象是這個殘差圖像。如果有失真圖像所對應的參考圖像的話,做一個簡單的減法,就可以得到label,再用這個label去訓練這些網絡。這個算法,要提前定義一些失真感知閾值,一旦學到殘差幀之后,就把兩個值乘起來,做進一步的分數估計。
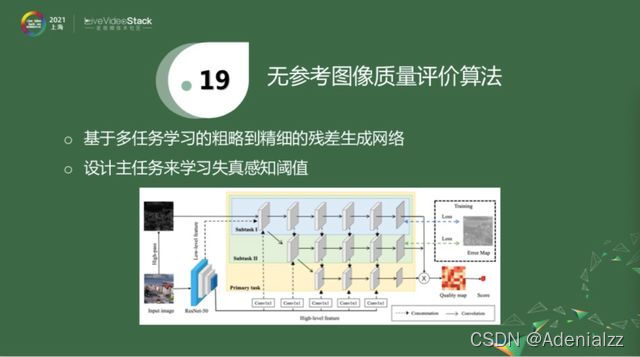
我們最近也圍繞這個方向做了一些探索,我們的方法是融合了以上兩種策略。第一種策略是,也使用中間表征這個殘差幀來作為初步的學習對象。相對于上面的改進就是,我們失真感知閾值是經網絡學習得到的,如上圖有三個subtask。Subtask1學習一個粗略的殘差幀。Subtask2學習更精細的殘差幀。主任務會學習失真感知閾值。三個網絡訓練完后,就可以把失真感知閾值和殘差幀乘起來,做進一步的質量評估。關于這個算法,今天先簡單分享這些,我們在4月份會介紹更多內容。
05 ICME 2021質量評價競賽
最后,我想分享一個信息,ICME 2021舉辦了一個質量評價競賽。

這個競賽的初衷是,結合目前學術界的研究熱點和業界痛點,以推動UGC視頻質量評價在學術界和業界的進展。為了這個目的,我們自己構建了一個大規模數據集,其中用于訓練的數據集是對外公開的,我們保留了一部分測試集。作為比賽的主辦方,我們在比賽結束之前會提供相對客觀、獨立的性能驗證結果,作為評測標準。它包含了兩個track,因為是UGC視頻。其中一個是MOS track,就是估計每一個視頻的絕對質量,這里包含用戶上傳的非完美的視頻,也包含對其做壓縮所得到的失真視頻。另一個是DMOS track,類似于傳統的PGC視頻,去估計源視頻經壓縮之后的質量變化。

上圖給出了大會的網址,搜索icme challenge就可以搜索到。具體的競賽網址是由ugcvqa給出。下面是具體比賽的timeline。目前已經是3月,模型提交時間是4月底,大概還是一個月的時間。最后在5月底,我們會給出提交的模型在非公開的測試集上驗證的結果,大家可以將其作為某種參考。如果感興趣的話,歡迎參加,或者討論。

最后是今天所用的一些參考文獻。
這是我今天所分享的內容,謝謝大家。







)






![docker gpu報錯Error response from daemon: could not select device driver ““ with capabilities: [[gpu]]](http://pic.xiahunao.cn/docker gpu報錯Error response from daemon: could not select device driver ““ with capabilities: [[gpu]])




