楊宏宇:騰訊多模態內容理解技術及應用

分享嘉賓:楊宇鴻 騰訊 內容理解高級工程師
編輯整理:吳祺堯
出品平臺:DataFunTalk
導讀: 搜索內容的理解貫穿了整個搜索系統。我們需要從多個粒度理解搜索內容,包括語義分塊、核心要素提取、頁面渲染等。多模態內容理解技術在其中扮演了重要角色,它可以從內容解析、內容質量檢驗、內容關系的挖掘以及內容屬性的提取方面對候選內容進行更好的篩選與排序。今天分享的主題是多模態的內容理解技術在搜索中的應用。
今天的介紹會圍繞下面七點展開:
- 通用搜索:內容理解體系
- 千億規模大庫的內容排序
- 細粒度圖像語義向量的應用
- 多模態的內容質量識別技術
- 文檔領域權威性識別
- 多模態的重復識別技術
- 未來展望
01 通用搜索:內容理解體系
首先和大家分享下在通用搜索的場景下如何做內容理解。
1. 內容理解體系

從上圖我們可以看到,搜索內容理解可以分為兩大塊:內容特征 和索引選擇 。我們會從千億級別的大庫中進行索引選擇,形成一個去重的優質庫、地域庫、新聞庫、視頻庫等。從內容特征出發,我們會分析字粒度、詞粒度等從細到粗的分粒度建模,為排序模型提供多種特征。
比如,我們在構建內容時會使用語義表示來甄別相似內容,防止重復索引的建立。因為目前互聯網上30%的內容都是重復的,我們沒有必要在索引中浪費這種內存。其次,互聯網中有20%的內容都是低價值的,我們也不需要對它們建立索引。那么從內容特征上來看,我們會構建標題和內容的匹配特征以及其他一些特征,建模判別圖文不符或者題文不符的任務。
針對內容、屬性和標簽理解,我們會在篇章級別提取內容屬性,比如我們可以用新聞屬性構建新聞庫,地域屬性來構建地域庫。通過頁面的分類和頁面tag的提取,我們可以將多個特征輸入召回層和排序層。系統整體的目標是通過不同的內容特征保證優質內容的供給。

我們使用多個粒度對內容進行理解。
- 首先是頁面級別 的理解,它包含語義分塊任務、核心要素提取任務以及頁面旋繞任務。除了直接從文本或者html中做內容解析與內容提取,目前業界大部分會采用基于pattern或者基于正則表達式的方法,但是它們的泛化能力不夠。所以就有人提出了基于視覺的方式做核心要素的提取。在不同頁面上,核心要素的表現形式不一樣,例如在問答頁你需要提取問題,在通用頁你需要提取頁面的閱讀數、點贊數、評論數等供排序階段使用。
- 其次是圖片 的理解,主要是判斷圖片的質量、多模的語義匹配。我們通過深入理解圖片和語義之間的關聯關系,挖掘不同模態的互補性。
- 從篇章級別 上,我們抽象出了幾個NLP的任務,包括內容的分級、問答匹配、文本摘要抽取、文本屬性提取、低于提取等。針對內容質量我們有一套詳細的多維度評價方法,整體的目標是通過優化體驗來提升用戶對內容的評價。
- 對于段落級別 ,由于多個段落通常會包含多種語義,所以我們建立了lda模型去理解每個段落的主題分布。我們也會使用序列標注模型來尋找文本中段與段之間的切分點。
- 接下來是句子級別 的任務。在句子級別,我們會有小語種識別任務,因為搜索的內容來自于全網,會有一定可能會爬到如泰語等小語種網站。我們還有語句通順度識別來判斷內容質量,對那些機器生成的句子或者東拼西湊的內容進行剔除。文本相似度任務在搜索中也有相應的應用場景。比如在內容理解中,我們需要提出作弊標題,因為有些段落的分句與標題的分句十分相似。
- 在字級別 的任務中,我們會有錯別字檢測任務,例如上圖展示的例子中李佳琦的“琦”字就被寫錯了。我們可以通過基于BERT的序列標注模型進行識別。
2. 圖文理解

接下來我來介紹一下如何細化圖文理解。首先,圖文理解包含四個層次。
- 最底層是內容解析
它可以通過結構理解來實現。其中最典型的是KIE任務,即關鍵信息提取。另外,頁面理解可以對應于Document LayoutAnalysis任務。在結構理解后,我們還需要對頁面進行類型檢測,比如判斷這是一個資訊頁,是一個問答頁,是一個視頻頁還是一個論壇頁。最后,我們會去提取頁面的主體內容、名稱、出鏈入鏈等。轉評贊等信息可以在排序冷啟動的時候進行使用,比如我們計算文檔初始化的熱度值。
- 第二層是內容質量權威性的預估
對于圖文視頻,我們會指定不同的質量標準來判斷內容是優質文還是口水文,是否包含負反饋,是否包含軟文,是否有違法內容,以及是否是“標題黨”。在視頻粒度下還會有黑白邊識別、拉伸變形識別、人臉截斷識別、無營養的識別等。
- 再上一層是內容匹配層次
我們進行圖文匹配。比如標題和封面圖、內容和封面圖是否是匹配的。此外,我們還可以判斷圖片是否是一個最優封面圖。我們還可以利用內容相似性進行排序。由于互聯網上的內容會天然地將相似內容聚集在一起,使得排序的結果同質化嚴重,影響排序效率,進而影響NDCG指標。所以,我們會建立text embedding,image embedding以及其他一些淺層特征如圖片的哈希,建立一個相似度預估模型。這一模型可以完成原創內容識別、舊文過濾、抄襲搬運的識別、投訴系統等任務。
- 最上是內容屬性層面
我們會提取內容所屬領域,比如識別內容的新聞屬性、地域屬性、站點權威性、站點等級等。
3. 視頻理解
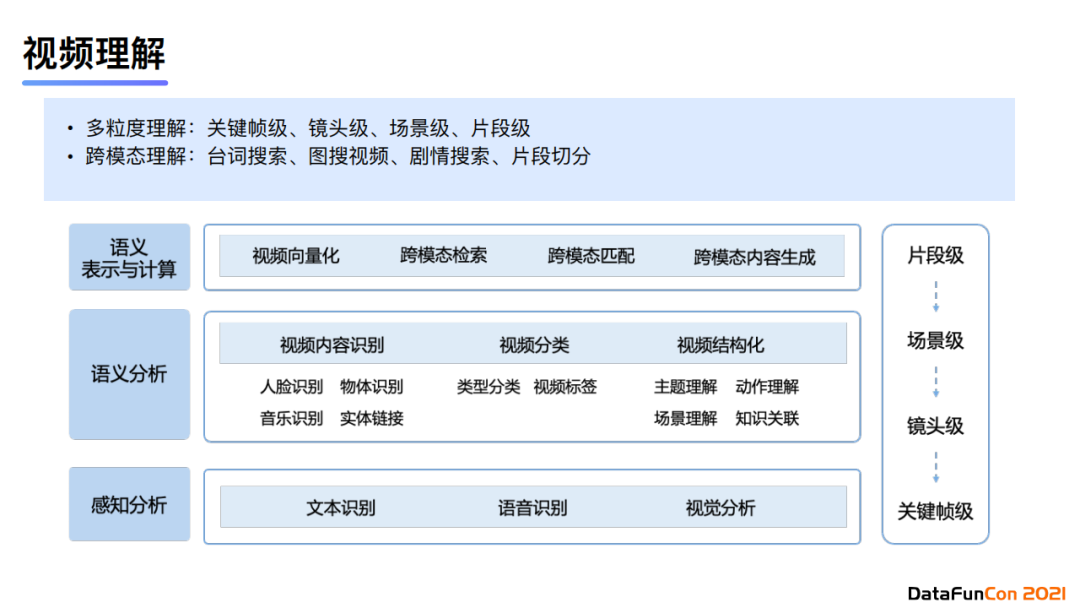
在視頻理解中,我們也會多粒度、跨模態地進行內容理解。首先我們會細化理解粒度,分為關鍵幀級、鏡頭級、場景級、片段級。在跨模態層面可以分為臺詞搜索、圖搜視頻、劇情搜索、片段切分等。
4. 結構理解
接下來我重點介紹內容解析中結構理解的部分。

結構理解主要任務之一是頁面解析,是一個非常重要的基礎工作,它的主要目標是提取頁面的關鍵部分,如正文、列表、問答等。常規的方法有基于模板的提取、基于html的提取以及基于css的提取,然后在后續處理中進行簡單的數據清洗。目前比較前沿的方法是以計算機視覺模型為基礎進行文檔布局的理解。如果我們無法正確提取頁面的文本內容,那么只做內容理解就會存在偏差。基于視覺的方法主要是用于模板匹配以及規則匹配失效的情況。目前有一個比較新的數據集,繼承了約五十萬條數據,可以用來訓練辨別頁面布局標注的模型。微軟最近也發表了一篇文章,提出了LayoutLM,他們利用文本在頁面布局下的普適性特征訓練一個預訓練模型。針對文檔這種結構,模型會將其轉化為一個序列。從上圖左下角我們可以看到,數據集由類別C和文檔D組成,模型的任務是將文檔的token歸類。預訓練模型中會加入二維的位置嵌入,對應文本候選框的坐標。最后的輸出和語言模型相似,會有一個CLS向量來表示整體的特征。

結構理解層面我們基于視覺模型做了正文排版美觀度打分。我們使用LSTM+CNN進行建模,LSTM負責擬合文本序列的特征,使用CNN來提取局部特征。模型最后會將LSTM得到的特征和CNN得到的特征進行拼接,最后對序列依次進行打分。序列打分的維度有段落類型、長度、圖片大小、清晰度、美觀度等。通過這種方式,我們就可以盡量保證線上的內容排版質量,并且展現的盡可能是優質內容。
02 千億規模大庫的內容排序

下面介紹一下我們如何在千億規模的大庫上做內容的排序。它屬于多模理解這一層級,利用內容質量的權威性、內容關系以及大規模索引來篩選優質內容。內容排序是通過多粒度、跨模態地理解全網內容,篩選內容質量優質、內容權威、高度原創的有價值的內容,并對它們建立索引。上圖展示了排序的流程圖。排序的目標是篩選topN價值的內容,數量大約在數百億的量級,全網候選內容則是在數千億的量級。

篩選的第一步是接入網頁庫。首先,面對千億級別的網頁,我們會進行內容前面計算,包括頁面tag簽名,最長句子簽名等。對于同簽名的內容我們會保留其中一條,使用的是LTR模型進行預估打分。具體地,我們使用優質內容作為正例,同一簽名下的其他文檔作為負樣本,優化目標是整體的Top1準確率。對于不同簽名的內容,它的優化目標則由頁面多樣性和查詢滿足性組成,構造的數據集來源于歷史標注數據以及點擊日志。我們使用LR模型,它接受的輸入特征有約100維,其中較為重要的特征有page rank特征、user rank特征(后驗排名)、site rank特征(整站排名)、站點排名等。這些特征聯合內容質量和物理質量,使用LR模型對內容進行打分。最后我們可以選出排名靠前的數百億內容,按比例放置在不同索引中。例如我們在索引召回時會先去使用VIP索引庫,當VIP庫已經滿足召回數量時就不需要查詢第二個庫;只有當優質文檔數量不滿足要求時才會進一步查詢二級庫甚至三級庫,最后是一個兜底庫。我們從實驗結果中可以發現,排序過程中剔除的典型頁面時同質化且內容權威性不高的內容,以及一些文不對題的內容。針對文不對題的問題,我們也有一個大模型進行識別。
內容排序模型會根據不同的準確率需求來制定不同的策略。如果召回要求的準確率不是很高,例如80%以上,那么我們會對結果做體驗評估。在滿足體驗且對相關性沒有造成損失的情況下,模型就可以進行一次上線。
03 細粒度圖像語義向量的應用

- 本文地址:楊宇鴻:騰訊多模態內容理解技術及應用
- 本文版權歸作者和AIQ共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出
接下來給大家介紹細粒度圖像語義向量在搜索中的應用。本質上來說,它屬于內容理解體系中的內容關系層級。圖像embedding可以用于檢索,包括重復檢索、實例檢索和語義檢索。它目前具有幾點挑戰。
首先,圖片庫的規模比較大,索引量從百萬級上升至億級別時,由于數據分布的變化,又因為基于空間的向量檢索會對數據分布相當敏感,所以embedding的Top1準確率會有很明顯的下降,不滿足業務需求。
其次,檢索需求是多樣的,我們無法做到embedding的統一,即需要根據不同的業務建立不同的embedding。比如某些圖片是語義相關的,另一些圖片是風格相關的、局部相關的或者整體相關的。所以,我們建立了多標簽粒度的圖片語義來滿足圖像風格等不同的檢索偏好。

整體系統包含預處理階段、向量化的索引、召回以及排序。預處理包括黑邊、拼接圖的裁剪、多樣性的分類等。在線上使用時,我們會將embedding進行0-1量化來減少內存占用,但也會不可避免地導致表達embedding能力的下降。所以需要注意的是,我們會對成本與性能進行權衡,選擇一個比較合適的應用方式。

圖像的檢索embedding有兩種技術路線:度量學習(即對比學習的方法)和傳統的圖像分類模型。我們的基線模型是基于ImageNet的預訓練模型MobileNet。在對比學習中,我們是可以任意定義數據之間的相似標準的。在我們的案例中,訓練數據中的正例來自于同一個視頻片段,且這組圖片是片段內距離最大的兩幀;負例則來自于不同片段中距離最小的一組視頻幀。

在使用ImageNet數據預訓練了第一版模型后,我們發現由于ImageNet分類粒度低,會導致召回結果中人不區分男人、女人、老人、小孩,經常會出現男人召回女人,小孩召回成人的情況。此外,由于ImageNet只對主體進行分類,不區分背景場景,所以導致召回結果的場景差異很大。
基于上述問題,我們對模型進行了一次迭代。新模型基于Open Image數據集,其數據數量在千萬級,總共包含兩萬多個標簽,所以它與ImageNet相比規模更大、標簽更為豐富,包含了多主體和場景信息。我們還對損失函數進行了優化,引入了非對稱損失。當負例的輸出概率超過一個較大的閾值時,損失函數的梯度會隨概率的增大而減小,達到標簽容錯的目的。將分類任務運用至檢索任務時,我們選擇加入對比學習的方式對模型進行訓練,那么整體的損失函數就包括了分類損失與相似度損失,兼顧分類精度以及檢索任務中要求的embedding相似度。使用這種方法后得到的召回結果明顯優于上一版的召回,比如從上圖中可以看到多標簽分類模型會在婚禮場景下召回正確的背景圖。

下面介紹有關圖文匹配的工作。圖文匹配任務適用于在素材檢索、封面優選等應用。我們的第一版方案是對圖片和文字分別進行特征提取,然后使用BERT將文字與圖像embedding進行對齊。后面我們使用了VIT替換ResNet,并將訓練數據集替換為千萬級中文圖文匹配數據集。使用自己構建的數據集的原因是目前業內還沒有一個針對圖文匹配的干凈數據集,造成模型匹配效果不甚理想。經過改進后的模型的匹配準確率相較于第一版模型有很大的提升。
04 多模態的內容質量識別技術

現在介紹我們在搜索中是如何應用多模態的內容質量識別技術的。首先,我們需要建模圖文混合排版、圖文信息匹配增益點以及文本內容深度。那么針對圖片模態,我們使用比較大的RCNN來提取圖像位置與大小信息,提取圖像前景目標特征;對于文本模態,我們會提取段落信息并實現tokenization。


雙模態聯合建模使用的是UNITER模型,它的優化目標是多種損失函數的組合,包含圖文匹配的matching loss、恢復圖像像素的masked region loss以及恢復token的masked token loss。模型的輸入包含圖像與文字模態。其中文本會使用段落與標題,不同內容會使用[SEP]進行分隔,使用token的形式進行輸入;圖像則使用ROI特征。最終,圖文匹配的輸出會使用文本與圖像部分的[CLS]輸出向量進行計算。
在實驗中,我們使用了約7000萬的訓練數據,包含純文本數據、純圖片數據以及圖片文本混合數據,其中圖文數據約有5000萬。從實驗結果上來看,我們的模型相較于基線在AUC指標上有了12%左右的提升。
05 文檔領域權威性識別

文檔領域權威性識別屬于內容理解中的內容屬性層級。我們提出這一任務的背景是想判斷query和賬號發文的領域是否一致。這一任務有兩大難點。首先,雙塔模型特征交互太晚,無法共享參數。我們的解決方案是使用多階段訓練的方法,首先先對兩個塔分別進行單獨的預訓練。具體地,query塔會使用TextCNN進行文本分類任務的預訓練,而author塔會使用 Roberta + CNN + Attention 建模文本與作者的特征,對領域進行分類預訓練任務。在第二階段,我們會做雙塔聯合訓練進行特征融合,目的是為了學習匹配向量之間的領域匹配度。

我們在訓練中會借鑒online hard negative mining的方法,將負樣本設置為得分與正樣本最相近的幾個doc,使得數據質量更加好,進而促使模型學習到更具區分度的特征。
06 多模態的重復識別技術

最后,我來介紹一下搜索場景下的大規模數據重復識別技術。它屬于內容理解中的內容關系層級。我們建立了多種方案來解決大規模數據重復控制,整體流程包括:重復組生成、重復組排序、觸發退場/入場。當特征發生變更的時候,我們會觸發一次輕量級特征計算。如果我們在每次特征變化時都實時計算如圖片向量等重量級特征并進行重排序的話,那么計算耗時非常大。具體地,我們的解決方案是一種二階段范式,首先我們實時計算淺層輕量特征,再在第二階段加入重量級特征進行召回,最后使用similarity ranking的方式進行排序。
最后我們需要判斷哪些內容需要被淘汰。目前線上有30%的內容是重復的,我們的目標是控制展現重復率和索引重復率。經過線上實驗,我們發現通過這樣一個二階段范式,系統的性能有了一定程度的提升,同時存儲成本大大降低。
07 未來展望
從整體上來看,正如2018年圖靈獎獲得者Yann LeCun所說,深度學習的趨勢是大規模無監督訓練,它是“蛋糕”的本質,而強化學習或者監督學習只是“蛋糕”表面的一小部分。所以未來我們需要考慮無監督學習技術應該如何促進多模態場景下不同領域之間的知識的交互,從而進一步提升性能。
08 精彩問答
Q:對頁面是如何做語義分塊的?
A:首先可以基于css渲染來進行分塊。因為頁面經過css強渲染后我們是可以得到原生的頁面分塊形式,使用html結構分析就可以拿到文本數據。其次,我們還可以使用鏈接密度來衡量分塊的類型,比如鏈接密度較大就有可能是索引列表。通常來說,強渲染的情況下分塊準確率都比較高。當我們想要提取正文主體內容時,采用的是噪聲標簽排除法,余下的高密度的主體部分就會是我們的目標內容。另外一種比較前沿的方法是基于視覺模型進行語義分塊,由于現有技術是基于傳統的基于規則或機器學習方法提出的,其中大多數無法很好地泛化,因為它們依賴于手工制作的特征,可能對布局變化不穩健, Vision 極大地推動了基于圖像的方法的文檔布局分析,根據 OCR 獲得的文本邊界框,能獲取文本在文檔中的具體位置,結合坐標轉化為虛擬坐標之后,融入位置Embedding,將布局分析任務轉換為序列標注任務。


![docker gpu報錯Error response from daemon: could not select device driver ““ with capabilities: [[gpu]]](http://pic.xiahunao.cn/docker gpu報錯Error response from daemon: could not select device driver ““ with capabilities: [[gpu]])
















