Go 中 map 利用率
今天刷 B 站看見有 Up 主在講布隆過濾器,提到了利用率的問題,假設有一組數據,范圍分布非常廣,使用布隆過濾器時如何盡量少的減少內存使用,感覺除了針對特定數據的定向優化外沒什么特別好的辦法,類似于 Google 那種加數據頭以跳過大段間隙那樣。然后想到類似的問題應該廣泛存在于所有使用哈希表的數據結構中,那 go 中 map 的利用率如何呢?
數據收集
在 go 中 map 是一個內置的數據結構,沒有一個簡單的方法來拿到它占用的內存,以下兩種方法供參考:
pprof
通過 pprof 定向收集內存分配和使用,我們可以直觀的得到某個函數占用了多少內存:
package main
import ("net/http"_ "net/http/pprof"
)func demo() {n := 90000m := make(map[int64]int64)for i := 0; i < n; i++ {m[int64(i)] = int64(i)}for {}
}func TestSize(t *testing.T) {go func() {http.ListenAndServe(":3390", nil)}()demo()
}
然后通過 go tool pprof -http :9090 http://127.0.0.1:3390/debug/pprof/heap 觀察 demo 的內存使用情況就可以了:
2468.70kB 100% | github.com/520MianXiangDuiXiang520/MapSize.TestSize /Users/junebao/Project/MapSize/mapsize_test.go:23 (inline)2468.70kB 40.77% 83.09% 2468.70kB 40.77% | github.com/520MianXiangDuiXiang520/MapSize.demo /Users/junebao/Project/MapSize/mapsize_test.go:13
如上,我們就可以知道九萬個 int64 的鍵值對占用了 2468.70KB
上面的辦法簡單粗暴,但要統計起來很麻煩
unsafe
我們知道 map 的底層結構其實是 runtime_hmap 那通過 unsafe 理論上就可以強轉得到原始結構,只要知道了數據桶和溢出桶的個數,我們也可以計算出 map 的真實內存:
func Size[K comparable, V any](m map[K]V) int64 {var zeroK Kvar zeroValue VkeySize := unsafe.Sizeof(zeroK)valueSize := unsafe.Sizeof(zeroValue)vo := reflect.ValueOf(m)hm := (*hmap)(unsafe.Pointer(vo.Pointer()))bn := 1<<hm.B + uintptr(hm.noverflow)bz := unsafe.Sizeof(bmap{}) + (keySize+valueSize)*bucketCntreturn int64(unsafe.Sizeof(hmap{}) + bz*bn)
}
這個方法的缺點在于數值不精確,一來是 noverflow 是一個統計值,某些情況下可能會導致得到的溢出桶數量略小于真實數量,二來 bmap 中的 overflow 指針會根據鍵值對的類型有所變化,上面的程序中并沒有計算該字段,因為鍵值對都不包含指針,理論上 map 會使用 hmap 的拓展字段存儲溢出指針,總體來說該方法得到的值會小于真實值,但作為參考足夠。如同樣的九萬個鍵值對使用上面方法得到的大小是 2457.976KB 比 pprof 版本少了 11KB
統計
func main() {for i := 0; i < 1000; i++ {n := i * 100m := make(map[int64]int64)for i := 0; i < n; i++ {m[int64(i)] = int64(i)}res := Size(m)t := int64(16 * n)fmt.Printf("%d,%d,%d,%d,%f\n", n, res, t, res-t, float64(t)/float64(res))}
}
以 100 為 步幅測試一千組用例,導入 CSV 用 python 繪制出圖表:
import matplotlib.pyplot as plt
import csvclass MapSizeStatistic:"""A statistic of map storage usage in go where key-value pairs are all int64"""def __init__(self):self.utilization_list = []with open("./int64.csv") as fp:reader = csv.reader(fp)self.utilization_list = [float(i[-1]) for i in reader]print(self.utilization_list)def draw_utilization(self):x = [i*100 for i in range(len(self.utilization_list))]plt.plot(x, self.utilization_list)plt.show()if __name__ == '__main__':mss = MapSizeStatistic()mss.draw_utilization()結果如下:
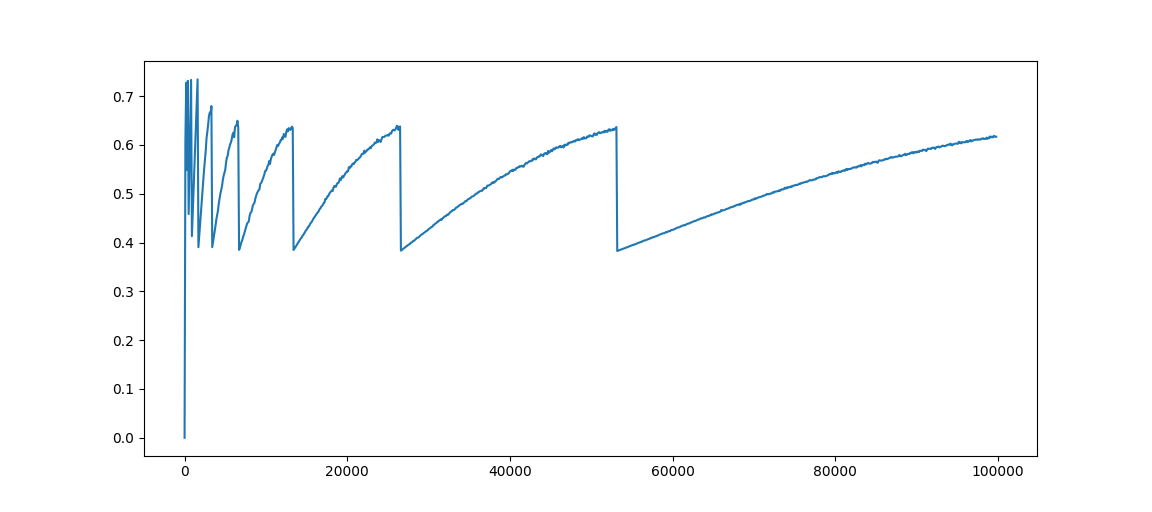
將鍵全部使用隨機數,得到結果如下:
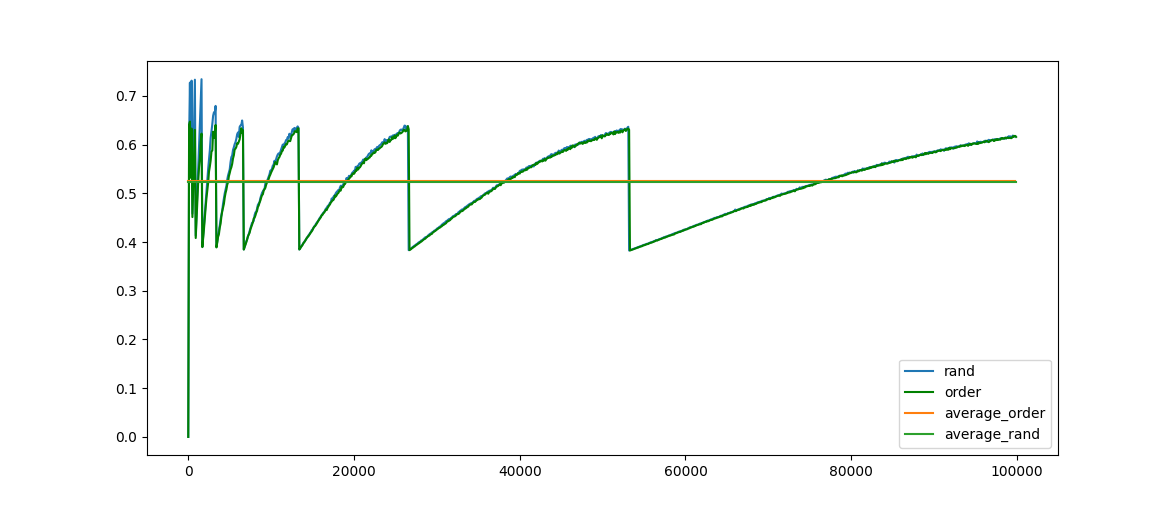
幾乎沒有差別,周期性變化非常明顯,可以確定引起利用率變化的主要原因在于元素數量,而利用率突然降低的節點就是發生了等量擴容。
從上面的測試可以看到最高利用率在 0.8 左右,最低利用率只有 0.4, 平均只有 0.5 左右
總結
總體利用率在 50% 左右,主要影響因素在于等量擴容,雖然 map 本就是空間換時間,但如果確實需要優化并且走投無路時,希望這些數據或許可以提供一些參考(分片,卡利用率的點……)
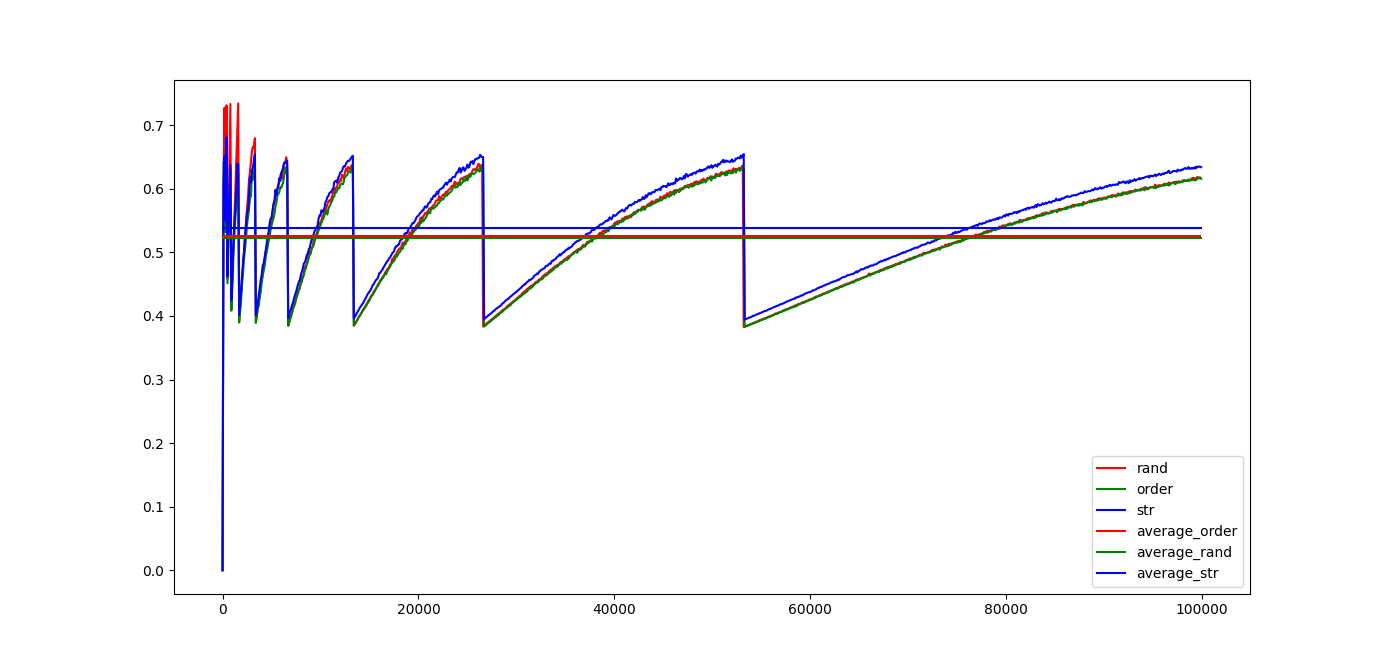
最后放上一張合影:
代碼














)




