TcMalloc 的核心是分層緩存,前端沒有鎖競爭,可以快速分配和釋放較小的內存對象(一般是 256 KB)前端有兩種實現,分別是 pre-CPU 和 pre-Thread 模式,前者申請一塊大的連續內存,每一個邏輯 CPU 將獲得其中的一段。這種模式下 TcMalloc 通過保存額外的元數據來動態地調整每種大小類的實際緩存大小。Per-Thread 模式為每個線程分配一個本地緩存,線程緩存中每種大小類的可用對象通過鏈表連接。
當前端緩存耗盡時,將會向中端請求新的緩存,中端分為兩部分:傳輸緩存和中央空閑列表。傳輸緩存可以將其他前端返還給中端的內存快速分配給請求申請內存的前端,如果傳輸緩存無法滿足就會向中央空閑列表申請,中央空閑列表以 Span 為單位管理內存,Span 是一組連續的 TcMalloc 頁,Span 通過基數樹管理。
當中端緩存耗盡或應用申請較大內存時,需要后端參與,后端一方面會管理一部分已經申請的頁面,同時還需要與 OS 交互真正申請和釋放內存。后端有兩種,傳統 pageheap 通過一個 256 位的鏈表數組管理特定長度的連續頁面;Hugepage Aware Allocator 包含三種緩存,可以根據請求的內存大小動態確定使用哪種緩存。
【譯】TcMalloc: Thread-Caching Malloc
原文鏈接
動力
TcMalloc 是一種內存分配器,它作為系統默認分配器的一種替代方案被設計,具有以下特征:
- 快,他可以無競爭地分配和釋放大部分的對象。根據模式不同,這些對象是按線程(per-thread)或邏輯 CPU (per-CPU)緩存的。大部分的分配不需要搶占鎖,因此在多線程程序中它的鎖競爭更少,伸縮性也更好。
- 內存使用更靈活,因為釋放的內存可以用于其他不同大小的對象,或返回給操作系統。
- 通過分配擁有相同大小的對象的“頁面”來降低每個對象的內存開銷。使得對小對象的空間表示更高效。
- 采樣開銷更低,能夠詳細地了解應用程序的內存使用情況。
使用
您可以通過將 Bazel 中二進制規則的 Malloc 屬性指定為 TCMalloc 來使用它。
概覽
下面的框圖顯示了 TCMalloc 的大致內部結構:

我們可以將 TCMalloc 分為三個組件:前端、中端和后端。我們將在下面的部分中更詳細地討論這些。職責的大致劃分如下:
- 前端是一個緩存,為應用程序提供快速的內存分配和回收。
- 中間端負責重新填充前端緩存。
- 后端處理從操作系統獲取內存。
請注意,前端既可以在 per-CPU(邏輯 CPU) 模式下運行,也可以在傳統的 per-thread 模式下運行,而后端既可以支持巨型頁面堆(hugepage),也可以支持傳統的頁面堆(legacy pageheap)。
TcMalloc 前端
前端處理特定大小的內存請求。前端有一個內存緩存,它可以用于分配或持有空閑內存。該緩存一次只能被一個線程訪問,應此不需要任何鎖,因此大多數的分配和釋放是很快的。
對于任何請求,如果前端有適當大小的內存緩存,它就可以滿足。如果特定大小的緩存為空,前端將從中端請求一批內存來重新填充緩存。中端包括 CentralFreeList 和 TransferCache。、
如果中端內存已耗盡,或者請求的大小大于前端緩存所能處理的最大大小,則請求將轉到后端,以滿足較大的分配,或者重新填充中端緩存。后端也稱為 PageHeap。
TCMalloc 前端有兩種實現:
- 開始時只支持的 per-thread(每線程)緩存(這也是 TcMalloc 名字的由來)。但是,這會導致內存占用隨著線程數量的增加而增加。現代應用程序可能有很多的線程數,這導致要么聚集大量的 per-thread 內存,要么許多線程擁有非常小的 per-thread 緩存。
- 最近,TCMalloc 支持 per-CPU 模式。在這種模式下,系統中的每個邏輯 CPU 都有自己的緩存來分配內存。注意: 在 x86 上,邏輯 CPU 相當于超線程(hyperthread)。
per-thread 和 per-CPU 模式之間的差異完全局限于 malloc/new 和 free/delete 的實現。
小對象和大對象分配
小對象的分配被映射到 60 ~ 80 個可分配大小類中的一個。例如,一個 12 字節的分配將被四舍五入到 16 字節大小類。大小類的設計目的是盡量減少四舍五入到下一個最大大小類時所浪費的內存。
當用 __STDCPP_DEFAULT_NEW_ALIGNMENT__ <= 8 編譯時,對于用 ::operator new 分配的原始存儲,我們使用一組大小與 8 字節對齊的大小類。對于許多常見的分配大小(24、40 等),這種更小的對齊可以最大限度地減少浪費的內存,否則這些大小將被四舍五入到 16 字節的倍數。在許多編譯器上,此行為由 -fnew-alignment=... 標志控制。當沒有指定 __STDCPP_DEFAULT_NEW_ALIGNMENT__ 或指定的值大于 8 字節時,對 ::operator new 我們使用標準的 16 字節對齊,然而,對于16字節以下的分配,我們可能會返回一個對齊較低的對象,因為空間中不能分配具有較大對齊要求的對象。
當請求給定大小的對象時,使用 SizeMap::GetSizeClass() 函數將該請求映射到特定大小類的請求,返回的內存來自該大小類。這意味著返回的內存至少與請求的大小一樣大。大小類的分配由前端處理。
大于 kMaxSize 大小的對象直接從后端分配。因此,它們不會緩存在前端或中間端。大對象分配請求的大小將被四舍五入到 TCMalloc 頁面大小(TCMalloc page size) 。
釋放
當對象唄釋放時,編譯器會提供對象的大小,但如果不知道大小,將會在頁面映射中查找。如果對象很小,它會被放回前端緩存。如果大小大于 kMaxSize 它將會被直接返回給 pageheap。
Pre-CPU 模式
在 Pre-CPU 模式下,只會有一個大的內存塊被分配。下圖展示了這個內存片是如何在 CPU 之間進行分配的以及每個 CPU 如何使用片的一部分來保存元數據以及指向可用對象的指針。
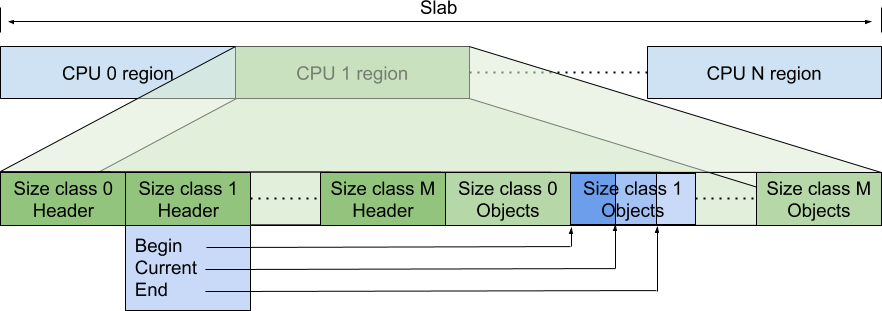
每個邏輯 CPU 都被分配了該內存的一部分,以保存元數據和指向特定大小類的可用對象的指針。元數據包括每個大小類的一個 /header/ 塊。header 有一個指向每個大小類數組頭部的指針(Begin)以及一個指向當前動態最大容量(End)和該數組段中的當前位置(Current)的指針。每個每個大小類指針數組的靜態最大容量在開始時由該大小類的數組的開始和下一個下一個類的數組的開始之間的差確定。
header 有三個指針,Begin 指向當前大小類內存起始位置,Current 指向當前大小類已分配的內存位置,end 指向動態可分配的最大內存地址(動態可分配不是可分配,這部分區域是已經劃給當前大小類的,但并不是說大小類只能分配到 End)
在運行時,可以存儲在每個 CPU 塊中的特定大小類的最大條目數量會有所變化,但它永遠不會超過啟動時靜態確定的最大容量。
當請求特定大小類的對象時,將從該數組中刪除該對象,當釋放該對象時將其添加到數組中。如果數組耗盡,則使用中端的一批對象重新填充數組。如果數組溢出,則從數組中刪除一批對象并返回到中端。
每個 CPU 可以緩存的內存量由參數 MallocExtension::SetMaxPerCpuCacheSize 限制。這意味著緩存的內存總量取決于活躍的每個 CPU 中緩存的數量。因此,具有更多 CPU 數量的機器可以緩存更多的內存。
為了避免不長時間運行程序的 CPU 占用大量內存,MallocExtension::ReleaseCpuMemory 會釋放保存在指定 CPU 緩存中的對象。
在 CPU 中,內存的分布是跨所有大小類管理的,以便使緩存的最大內存量低于限制。注意,它管理的是可緩存的最大數量,而不是當前緩存的數量。平均而言,實際緩存的量應該是限制的一半左右。
當某一大小類的對象耗盡時,該大小類的容量會增加。同時,當申請較多對象時,也會考慮增加該大小類的容量。我們可以擴大某一大小類的容量直到總緩存占用達到每個 CPU 的限制或某一大小類的容量達到該大小類硬編碼的限制。如果大小類沒有達到硬編碼的限制,那么為了增加容量,它可以從同一 CPU 上的另一個大小類竊取容量。
可重啟序列和 Pre-CPU TCMalloc
為了正確工作,Pre-CPU 模式依賴于可重啟序列(man rseq(2))。可重新啟動序列只是(匯編語言)指令塊,很大程度上像一個典型的函數。可重啟序列的一個限制是它們不能將部分狀態寫入內存,最終指令必須是更新狀態的單次寫入。可重啟序列的想法是,如果一個線程在執行可重啟序列時從 CPU 中換出(例如上下文切換),該序列將從從頭開始執行。因此,序列要么不間斷地完成,要么反復重啟,直到它不間斷地完成。這是在不使用任何鎖定或原子指令的情況下實現的,從而避免了序列本身的任何競爭。
這對 TCMalloc 的實際意義是,代碼可以使用可重啟的序列(如 TcMallocSLab_Internal_Push)從每個 CPU 數組中獲取元素或將元素返回到該數組,而不需要鎖定。可重新啟動序列可以確保在不中斷線程的情況下更新數組,或者在線程中斷時重新啟動序列(例如,通過上下文切換,允許在該 CPU 上運行另一個線程)。
關于設計選擇和實現的其他信息將在特定的設計文檔中進行討論。
傳統的 Per-Thread 模式
在 Per-Thread 模式中,TCMalloc 為每個線程分配一個線程本地緩存。這個線程本地緩存滿足較小的分配。根據需要,將對象從中端移動到線程本地緩存中或從線程本地緩存中移出。
一個線程緩存包含每個大小類的一個空閑對象列表的單獨的鏈表(所以如果有 N 個大小類,就會有 N 個相應的鏈表),如下圖所示。

在分配時,將從對應大小類鏈表中刪除一個對象,釋放時,將會將對象插入到鏈表頭部。可以訪問中端以獲取更多對象和返回一些對象到中端來處理下溢或溢出。
每個線程緩存的最大容量是由參數 MallocExtension::SetMaxTotalThreadCacheBytes 設置的。但是,總大小可能會超過這個限制,因為每個線程緩存的最小大小 KMinThreadCacheSize 通常是 512KiB。如果一個線程希望增加它的容量,它需要從其他線程中竊取容量。
當線程退出時,他們的緩存內存將返還給中端。
前端緩存的運行時大小
對前端緩存空閑列表的大小進行優化調整非常重要。如果空閑列表太小,我們將需要經常訪問中端空閑列表。如果空閑列表太大,我們將浪費內存,因為對象在其中處于空閑狀態。
請注意,緩存對于回收和分配的重要性是一樣的。如果沒有緩存,每次釋放都需要將內存移動到中央空閑列表(Central free)。
Pre-CPU 和 Pre-Thread 模式有不同的動態緩存大小算法的實現。
- 在 Pre-Thread 模式中,每當需要從中間端獲取更多對象時,可以存儲的最大對象數量都會增加到一個限制。同樣,當我們發現緩存了太多對象時,容量也會降低。如果緩存對象的總大小超過每個線程的限制,緩存的大小也會減小。
- 在 Pre-CPU 模式中,空閑列表的容量增加取決于我們是否在下溢和上溢之間交替(這表明更大的緩存可能會停止這種交替)。當容量一段時間沒有增長,因此可能會出現容量過剩時,就會減少容量。
TcMalloc 中端
中端負責向前端提供內存并將內存返回給后端。中端包括 傳輸緩存 (Transfer Cache) 和 中央空閑列表(Central free list)。雖然它們通常寫作單數,但每個大小類都有一個傳輸緩存和一個中央空閑列表。這些緩存都由互斥鎖保護 —— 因此訪問它們需要序列化代價。
傳輸緩存
當前端申請或返還內存時,它將接觸到傳輸緩存。
傳輸緩存持有一個指向空閑內存指針的數組,他可以快速地將對象移動到這個數組中或者代表前端從此數組中獲取對象。
傳輸緩存得名于這樣一種情況: 一個 CPU(或線程) 分配到由另一個 CPU(或線程) 釋放的內存。傳輸緩存允許內存在兩個不同的 CPU(或線程) 之間快速流動。
如果傳輸緩存無法滿足內存請求,或者沒有足夠的空間來保存返回的對象,它將訪問中央空閑列表。
中央空閑列表
中央空閑列表以 span 為單位管理內存,一個 span 是一個或多個 “TCMalloc 內存頁” 的集合。這些術語將在接下來的幾節中進行解釋。
對于申請一個或多個對象的請求,中央空閑列表會不斷通過向 Span 獲取對象直到該請求被滿足。如果 span 中沒有足夠的可用對象,則會向后端請求更多 span。
當對象返還到中央空閑列表時,每個對象被映射并釋放到它所屬的 span (使用頁面映射 Pagemap )。如果駐留在特定 span 中的所有對象都返還給了它,則整個 span 返還給后端。
Pagemap 和 span
由 TCMalloc 管理的堆被分為多個頁,其大小由編譯時確定。連續頁面的運行由一個 Span 對象表示。一個 Span 可以用于管理交付給應用程序的大對象,也可以作為已經被拆分成一系列小對象的頁運行。如果 span 管理的是小對象,則 span 中會記錄對象的大小類。
pagemap 用于查找對象所屬的 span 或標識給定對象的大小類。
TCMalloc使用兩層或三層的 基數樹 radix-tree 將所有可能的內存位置映射到 span 上.
下面的圖顯示了如何使用兩層 radix-tree 將對象的地址映射到控制對象所在頁面的 span 上。在圖中,span A 涵蓋兩頁,span B 涵蓋三頁。
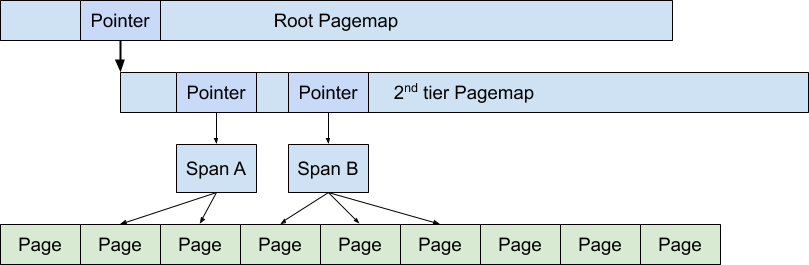
span 在中端用來確定將返回的對象放在哪里,并在后端用來管理頁面范圍的處理。
在 span 中存儲小對象
span 包含一個指向 TcMalloc span 控制頁面基地址的指針。對于小對象,這些頁面最多分為 2162^{16}216 個對象。選擇這個值是為了在 span 內通過兩個字節的索引引用對象。
這意味著我們可以使用松散鏈表來保存對象。例如,如果我們有 8 個字節的對象,如果我們有八個字節的對象,我們可以存儲三個隨時可用的對象的索引,并使用第四個槽來存儲鏈中下一個對象的索引。這種數據結構減少了全鏈接列表上的緩存丟失。
使用兩個字節索引的另一個好處是,我們可以使用 span 本身的空閑容量來緩存四個對象。
當某大小類沒有可用對象時,需要從頁面堆中獲取一個新的 span 并填充它。
TCMalloc 頁大小
可以使用不同的頁大小構建 TCMalloc。請注意,這些與底層硬件的 TLB 中使用的頁面大小不對應。TCMalloc 的頁面大小目前為 4KiB、8KiB、32KiB 和 256KiB。
TcMalloc 的頁可以容納特定大小的多個對象,也可以作為容納超出單個頁大小的對象的一組頁面的一部分。如果整個頁面空閑了,它將被返還給后端。以后可以重新利用它來保存不同大小的對象(或返回到操作系統)。
較小的頁面能夠以較少的開銷更好地處理應用程序的內存需求。例如,使用了一半的 4KiB 頁面將剩余 2KiB,而32KiB 的頁面將剩余 16KiB。小頁面也更有可能變得空閑。再例如,4KiB 頁可以容納 8 個 512 字節的對象,而32KiB 頁可以容納 64 個對象;64 個對象同時空閑的可能性比 8 個對象空閑的可能性要小得多。
大頁面減少了從后端獲取和返回內存的需要。單個 32KiB 頁面可以容納 8 倍于 4KiB 頁面的對象,這可能會導致管理較大頁面的成本較小。映射整個虛擬地址空間所需的大頁面也更少。TCMalloc 有一個頁面映射,它將虛擬地址映射到管理該地址范圍內的對象的結構上。較大的頁面意味著頁面映射需要較少的條目,因此較小。
因此,對于內存占用小的應用程序,或者對內存占用大小敏感的應用程序,使用較小的 TCMalloc 頁面大小是有意義的。占用較大內存的應用程序可能會受益于較大的 TCMalloc 頁面大小。
TcMalloc 后端
TcMalloc 后端干三件事:
- 管理未使用的大塊內存。
- 當沒有合適大小的內存來滿足分配請求時,它負責從操作系統獲取內存。
- 它負責將不需要的內存返回給操作系統。
TcMalloc 后端有兩種:
- 管理 TcMalloc 中 page 大小內存塊的 Legacy pageheap (傳統頁堆)
- 以 hugepage 大小為單位管理內存的 hugepage aware pageheap(超大頁感知分配器)。以 hugepage 為單位管理內存,使分配器能夠通過減少 TLB 未命中來提高應用程序性能。
Legacy pageheap
傳統頁堆是一個可用內存中連續頁面的特定長度的空閑列表的數組。當 k < 256 時,它的第 k 個節點就是一個由 k 個 TcMalloc 頁組成的空閑運行列表。第 256 個節點是長度大于 256 頁的空閑運行列表。
大白話就是 Legacy pageheap 是一個長度為 256 的數組,數組每一位保存一個可用內存的鏈表,鏈表的每個節點都是連續的 i 個 TcMalloc 頁。i 由鏈表在數組中的位置決定,大于 255 的 i 都保存在數組最后一位。
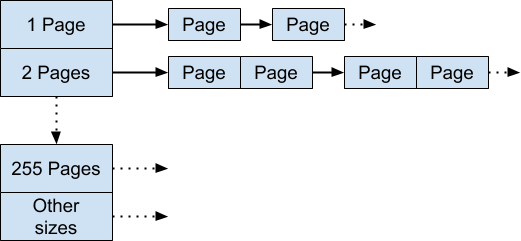
我們可以通過查找第 k 個空閑列表來滿足 k 個頁面的分配。如果那個空閑列表是空的,我們就查找下一個空閑列表,依此類推。最后,如果需要,當我們查找到最后一個空閑列表依然失敗時,我們將通過系統的 mmap 獲取內存。
如果長度大于 k 的頁面滿足了對 k 個頁面的分配,則結點剩余的部分將被重新插入到適當的空閑列表中。
假設要申請兩個頁面,但第二條空閑列表空了,第三條列表中每個節點有三個頁面,分配掉兩個后,余下一個會被插入到第一條列表中
當向頁面堆返回一定范圍的頁面時,將檢查相鄰的頁面,以確定它們現在是否形成了一個連續的區域,如果是這樣,則將這些頁面連接起來并放置到適當的空閑列表中。
盡量減少碎片
Hugepage Aware Allocator
Hugepage Aware Allocator 的目標是將內存保存在 hugepage 大小的塊中。在 x86 上,一個 hugepage 的大小是 2MiB。為此,后端有三個不同的緩存:
-
填充緩存(filler cache)保存已從其分配了一些內存的 hugepage。可以認為這類似于 Legacy pageheap ,因為它保存特定數量的 TCMalloc 頁的內存鏈表。(通常)從填充緩存返回對小于 hugepage 大小的大小的分配請求。如果填充緩存沒有足夠的可用內存,它將請求額外的 hugepage 來分配。
-
區域緩存(region cache),用于處理大于一個 hugepage 的分配。這個緩存允許跨多個 hugepage 的分配,并將多個這樣的分配打包到一個連續的區域中。這對于稍微超過一個大頁面大小的分配尤其有用(例如,2.1 MiB)。
Essentially, the path of an allocation goes like this:(本質上,分配思路是這樣的:)
-
If it is sufficiently small and we have the space we take an existing, backed, partially empty hugepage and fit our allocation within it.(如果它足夠小,并且我們有足夠的空間,我們就使用一個現有的、有支持的、部分空的 hugepage,并將我們的分配放在其中。)
-
If it is too large to fit in a single hugepage, but too small to simply round up to an integral number of hugepages, we best-fit it into one of several larger slabs (whose allocations can cross hugepage boundaries). We will back hugepages as needed for the allocation.(如果它太大了,不能放在一個 hugepage 中,但又太小了,不能簡單地四舍五入到一個整數 hugepage,那么我們最好把它放在幾個更大的 slab 中(它們的分配可以跨越 hugepage 邊界)。我們將根據分配的需要支持 hugepage。)
-
Sufficiently large allocations are rounded up to the nearest hugepage; the extra space may be used for smaller allocations.(足夠大的分配被四舍五入到最近的 hugepage;額外的空間可用于較小的分配。)
-
-
hugepage 緩存處理至少一個 hugepage 的大量分配。與區域緩存的使用有重疊,但區域緩存僅在確定(在運行時)分配模式將使其受益時才啟用。
有關 HPAA 的設計和選擇的其他信息在其特定設計文檔中進行討論。
注意事項
TCMalloc 將在啟動時為元數據保留一些內存。元數據的數量將隨著堆的增長而增長。特別是,頁面映射將隨著TCMalloc 使用的虛擬地址范圍而增長,span 將隨著內存的活動頁面數量的增長而增長。在 pre-CPU 模式下,TCMalloc 將為每個 CPU 保留一個內存片(通常為 256 KiB),這在具有大量邏輯 CPU 的系統上可能會導致幾兆字節的占用空間。
值得注意的是,TCMalloc 以大塊(通常為 1 GiB 區域)的形式向操作系統請求內存。地址空間是保留的,但在使用之前不會得到物理內存的支持。由于該方法,應用的 VSS 可以比 RSS 大得多。這樣做的一個副作用是,在應用程序使用了那么多物理內存之前,試圖通過限制 VSS 來限制應用程序的內存使用將會失敗很久。
不要試圖將 TCMalloc 加載到運行的二進制文件中(例如,在 Java 程序中使用 JNI)。二進制文件將使用系統 Malloc 分配一些對象,并可能嘗試將它們傳遞給 TCMalloc 以進行釋放。TCMalloc 將無法處理此類對象。










)





臨時數據庫(tempdb))


