論文閱讀: YOLO9000-Better,Faster,Stronger
?
YOLOv2 是經過改造之后的YOLO?

?
Batch Normalization:在所有的conv layer后加了BN之后提高了2% mAP,BN可以幫助regularize模型,這樣的話就可以放棄 dropout。
?
High Resolution Classifier: 之前的 YOLO是基于224X224,將resolution提高到448,首先在imagenet 上fine tune Network 10 epochs。
?
Convolutional With Anchor Boxes: 對于之前的YOLO,conv layers之后的 FC layer,YOLOv2 將FC layer移除之后,使用anchor boxes來預測 bounding boxes。
使用了anchor boxes在accuracy有了微小的提高,YOLO只有98 (7 x 7 x 2) 個bboxs,在anchor boxes下可以產生上千個box。
Diminsion Cluster:使用k-means來自動挑選box dimensions,選擇非Euclidean distance,而是 distance metric:

在VOC和COCO上的表現:

?
Direct Location Prediction:在YOLOv2中不直接regression計算offsets,而是predict location of the grid cell,利用 logistic activation來選擇 predictions,限制predictions落在range之內。
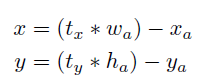
所以,prediction為:

如圖:

?
Fine-Grained Features
13 x 13 feature map , good for finer grained features for localizing smaller objects.
multi-scale training: change the network every few iterations. (Every 10 batches our network randomly chooses a new image dimension size)
?
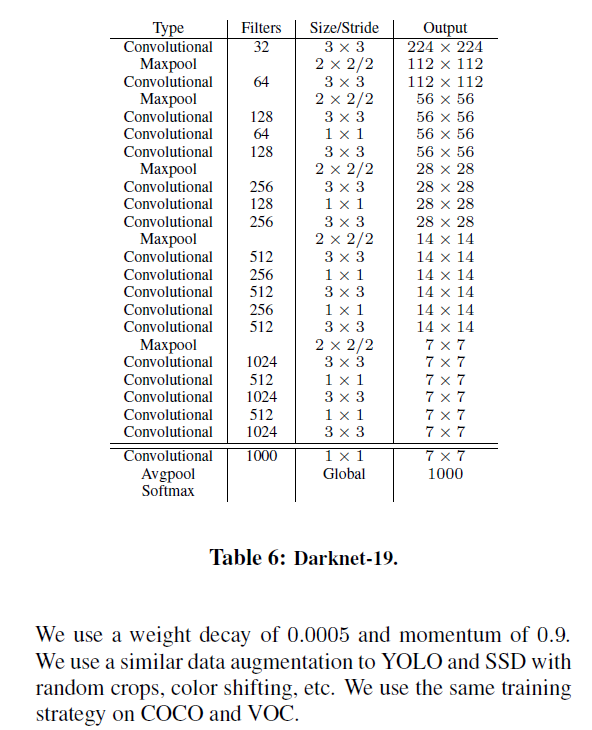
為了Faster,重新修改了網絡結構:
?
YOLO9000, 利用細粒度分類 fine grained, wordTree 來幫助分類。
在train YOLO9000時候使用了 data combination,將COCO和ImageNet兩個數據集合并。
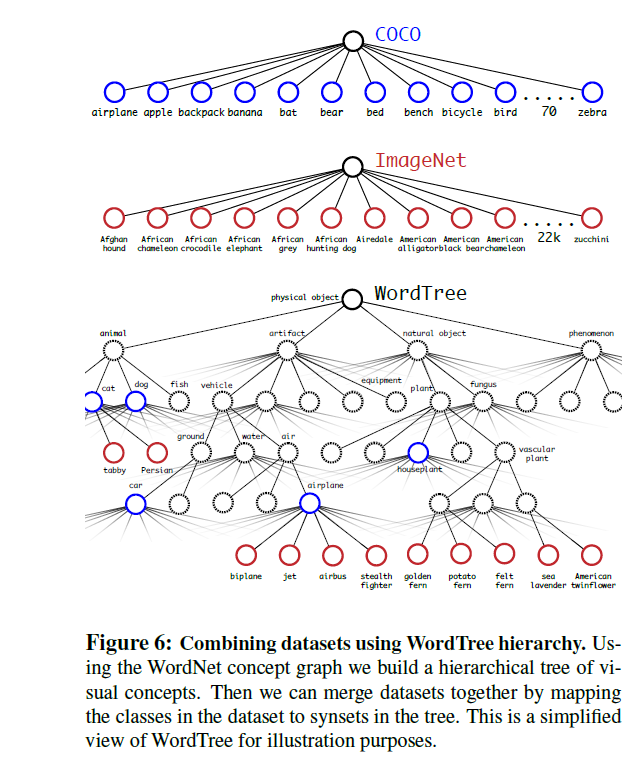
ImageNet的WordTree representation為圖像分類提供了更加豐富更加細致的輸出空間。
?
本人觀點:之前的YOLO出的早,網絡結構是很不錯,但是這兩年的classification、Detection領域發展太快,有太多好的trick和method,作者重新取長補短,將那些好的思想融入到YOLO中。實現了題目中的 Better,Faster, Stronger的特點。不錯的paper。
?










)
V1.0發布!)




![[轉載]建立團隊溝通協作工作方式](http://pic.xiahunao.cn/[轉載]建立團隊溝通協作工作方式)


)