總述
Focal loss主要是為了解決one-stage目標檢測中正負樣本比例嚴重失衡的問題。該損失函數降低了大量簡單負樣本在訓練中所占的權重,也可理解為一種困難樣本挖掘。
目標識別有兩大經典結構:
- 第一類是以Faster RCNN為代表的兩級識別方法,這種結構的第一級專注于proposal的提取,第二級則對提取出的proposal進行分類和精確坐標回歸。兩級結構準確度較高,但因為第二級需要單獨對每個proposal進行分類/回歸,速度就打了折扣;
- 第二類結構是以YOLO和SSD為代表的單級結構,它們摒棄了提取proposal的過程,只用一級就完成了識別/回歸,雖然速度較快但準確率遠遠比不上兩級結構。
那有沒有辦法在單級結構中也能實現較高的準確度呢?Focal Loss就是要解決這個問題。
為什么單級結構的識別準確度低
作者認為單級結構準確度低是由類別失衡(class imbalance)引起的。計算Loss的bbox可以分為 positive 和 negative 兩類。當bbox(由anchor加上偏移量得到)與ground truth間的IOU大于上門限時(一般是0.5),會認為該bbox屬于positive example,如果IOU小于下門限就認為該bbox屬于negative example。在一張輸入image中,目標占的比例一般都遠小于背景占的比例,所以兩類example中以negative為主,這引發了兩個問題:
- negative example過多造成它的loss太大,以至于把positive的loss都淹沒掉了,不利于目標的收斂;
- 大多negative example不在前景和背景的過渡區域上,分類很明確(這種易分類的negative稱為easy negative),訓練時對應的背景類score會很大,換個角度看就是單個example的loss很小,反向計算時梯度小。梯度小造成easy negative example對參數的收斂作用很有限,我們更需要loss大的對參數收斂影響也更大的example,即hard positive/negative example。
- 這里要注意的是前一點我們說了negative的loss很大,是因為negative的絕對數量多,所以總loss大;后一點說easy negative的loss小,是針對單個example而言。
Faster RCNN的兩級結構可以很好的規避上述兩個問題:
- 會根據前景score的高低過濾出最有可能是前景的example (1K~2K個),因為依據的是前景概率的高低,就能把大量背景概率高的easy negative給過濾掉,這就解決了前面的第2個問題;
- 會根據IOU的大小來調整positive和negative example的比例,比如設置成1:3,這樣防止了negative過多的情況(同時防止了easy negative和hard negative),就解決了前面的第1個問題。
所以Faster RCNN的準確率高。
OHEM是近年興起的另一種篩選example的方法,它通過對loss排序,選出loss最大的example來進行訓練,這樣就能保證訓練的區域都是hard example。這個方法有個缺陷,它把所有的easy example都去除掉了,造成easy positive example無法進一步提升訓練的精度。
Focal Loss
Focal Loss的目的:消除類別不平衡 + 挖掘難分樣本
Focal loss是在交叉熵損失函數基礎上進行的修改,首先回顧二分類交叉上損失:
CE(p,y)={?log(p),y=1?log(1?p),y=otherwise.CE(p,y)=\left\{\begin{matrix} -log(p),&y=1 & & \\ -log(1-p),&y=otherwise \end{matrix}\right..CE(p,y)={?log(p),?log(1?p),?y=1y=otherwise?.
可以進行如下定義:
pt={p,y=11?p,y=otherwise.p_t=\left\{\begin{matrix} p,&y=1 & & \\ 1-p,&y=otherwise \end{matrix}\right..pt?={p,1?p,?y=1y=otherwise?.
就可以得到:
CE(pt)?=?log(pt)CE(p_t)?=-log(p_t)CE(pt?)?=?log(pt?)
對于這個公式,Pt越大,代表越容易分類,也就是越接近target。
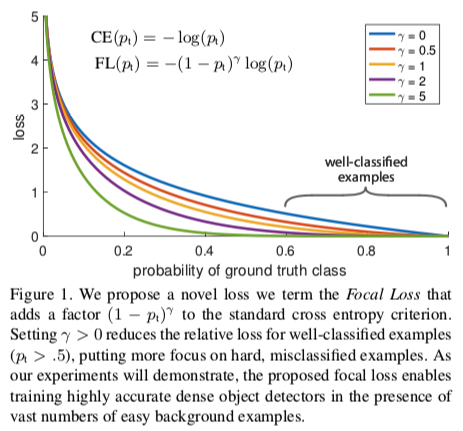
CE曲線是下圖中的藍色曲線,可以看到,相比較其他曲線,藍色線條是變化最平緩的,即使在p>0.5(已經屬于很好區分的樣本)的情況下,它的損失相對于其他曲線仍然是高的,也許你會說,它相對于自己前面的已經下降很多了,對,是下降很多了,然后呢?看似每一個是微不足道,但是當數量巨大的易區分樣本損失相加,就會主導你的訓練過程而忽略hard examples
Balanced Cross Entropy
那怎么解決類不平衡呢?常見的思想是引入一個權重因子 α ,α ∈[0,1],當類標簽是1是,權重因子是α ,當類標簽是-1時,權重因子是1-α 。同樣為了表示方便,用 ata_tat? 表示權重因子,那么此時的損失函數被改寫為:
CE(pt)?=?αtlog(pt)CE(p_t)?=-α_t log(p_t)CE(pt?)?=?αt?log(pt?)
Focal Loss Definition
解決了正負樣本的比例失衡問題(positive/negative examples),但是這種方法僅僅解決了正負樣本之間的平衡問題,并沒有區分簡單還是難分樣本(easy/hard examples),那么怎么去抑制容易區分的負樣本的泛濫呢?不然整個訓練過程都是圍繞容易區分的樣本進行,而被忽略的難區分的樣本才是訓練的重點。這時需要再引入一個調制因子,公式如下:
CE(pt)?=?(1?pt)γlog(pt)CE(p_t)?=-(1-p_t)^{γ} log(p_t)CE(pt?)?=?(1?pt?)γlog(pt?)
γγγ 也是一個參數,范圍在[0,5],觀察上式可以發現,當 ptp_tpt? 趨向于1時,說明該樣本比較容易區分,整個調制因子是趨向于0的,也就是loss的貢獻值會很小;如果某樣本被錯分,但是ptp_tpt? 很小,那么此時調制因子是趨向1的,對loss沒有大的影響(相對于基礎的交叉熵),參數 γγγ 能夠調整權重衰減的速率。還是上面這張圖,當 γ=0γ=0γ=0 的時候,FL就是原來的交叉熵CE,隨著 γγγ 的增大,調整速率也在變化,實驗表明,在 γ=2γ =2γ=2 時,效果最佳。
上述兩小節分別解決了正負樣本不平衡問題和易分,難分樣本不平衡問題,那么將這兩個損失函數組合起來,就是最終的Focal loss:
CE(pt)?=?αt(1?pt)γlog(pt)CE(p_t)?=-α_t(1-p_t)^{γ} log(p_t)CE(pt?)?=?αt?(1?pt?)γlog(pt?)
它的功能可以解釋為:通過 αtα_tαt? 可以抑制正負樣本的數量失衡,通過 γγγ 可以控制簡單/難區分樣本數量失衡。關于focal loss,有以下結論:
1、無論是前景類還是背景類,ptp_tpt?越大,權重 (1?pt)r(1-p_t)^r(1?pt?)r 就越小。也就是說easy example可以通過權重進行抑制。換言之,當某樣本類別比較明確些,它對整體loss的貢獻就比較少;而若某樣本類別不易區分,則對整體loss的貢獻就相對偏大。這樣得到的loss最終將集中精力去誘導模型去努力分辨那些難分的目標類別,于是就有效提升了整體的目標檢測準度
2、αtα_tαt? 用于調節positive和negative的比例,前景類別使用 ata_tat? 時,對應的背景類別使用 KaTeX parse error: Expected group after '_' at position 5: 1-at_?;
3、rrr和αtα_tαt?的最優值是相互影響的,所以在評估準確度時需要把兩者組合起來調節。作者在論文中給出 r=2、αt=0.25r=2、α_t=0.25r=2、αt?=0.25 時,ResNet-101+FPN作為backbone的結構有最優的性能。
此外作者還給了幾個實驗結果:
- 在計算 ptp_tpt? 時用sigmoid方法比softmax準確度更高;
- Focal Loss的公式并不是固定的,也可以有其它形式,性能差異不大,所以說Focal Loss的表達式并不crucial。
RetinaNet
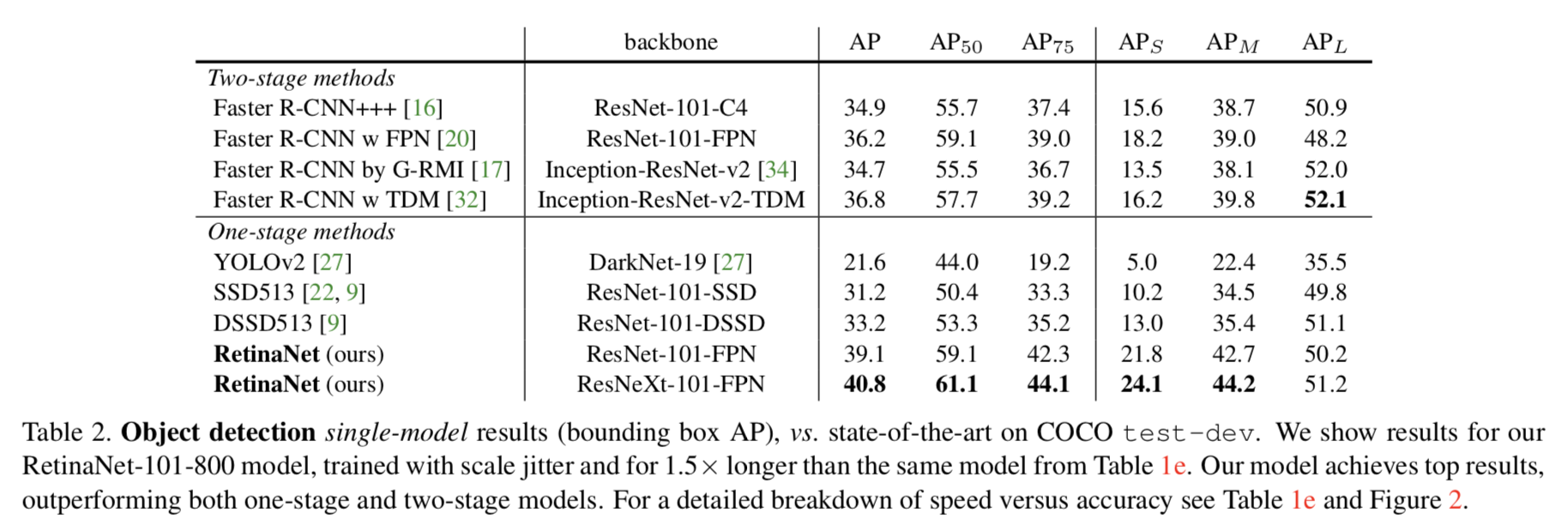
為了驗證focal loss的有效性設計了一種one-stage的目標檢測器RetinaNet,它的設計利用了高效的網絡特征金字塔以及采用了anchor boxes,表現最好的RetinaNet結構是以ResNet-101-FPN為bakcbone,在COCO測試集能達到39.1的AP,速度為5fps;
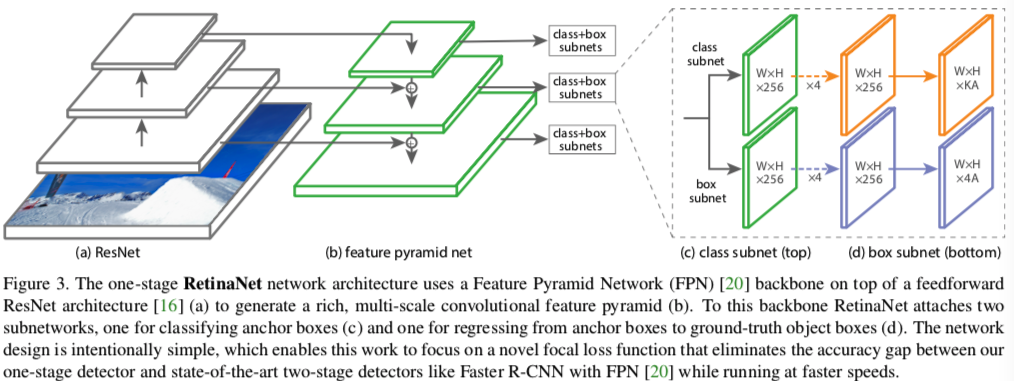
RetinaNet本質上是由 resnet+FPN+兩個FCN子網絡組成,設計思路是 backbone 選擇vgg、resnet等有效的特征提取網絡,主要嘗試了resnet50、resnet101,FPN是針對resnet 里面形成的多尺度特征進行強化利用獲得表達力更強包含多尺度目標區域信息的feature map,最后在 FPN 的feature map集合上分別使用兩個結構相同但是不share參數的 FCN子 網絡,從而完成目標框類別分類和bbox位置回歸任務;
Anchor信息:與RPN網絡類似,也使用anchors來產生proposals。特征金字塔的每層對應一個anchor面積。anchor的面積從 32232^2322 到 5122512^25122 在特征金字塔p3到p7等級上,在每一個level上都有三種不同的長寬比例{1:2,1:1,2:1},針對denser scale coverage,在每一個level的anchor集合上加入 20,21/3,22/3{2^0, 2^{1/3}, 2^{2/3}}20,21/3,22/3 三種不同的size;每一個anchor分配一個長度為K的vector作為分類信息,以及一個長度為4的bbox回歸信息;
inference:前向推理階段,即測試階段,作者對金字塔每層特征圖都使用0.05的置信度閾值進行篩選,然后取置信度前1000的候選框(不足1000更好) ,接下來收集所有層的候選框,進行NMS,閾值0.5
train:訓練時,與GT的IOU大于0.5為正樣本,小于0.4為負樣本,否則忽略
Classification Subnet:分類子網對A個anchor,每個anchor中的K個類別,都預測一個存在概率。如下圖所示,對于FPN的每一層輸出,對分類子網來說,加上四層3x3x256卷積的FCN網絡,最后一層的卷積稍有不同,用3x3xKA,最后一層維度變為KA表示,對于每個anchor,都是一個K維向量,表示每一類的概率,然后因為one-hot屬性,選取概率得分最高的設為1,其余k-1為歸0。傳統的RPN在分類子網用的是1x1x18,只有一層,而在RetinaNet中,用的是更深的卷積,總共有5層,實驗證明,這種卷積層的加深,對結果有幫助。
Box Regression Subnet:與分類子網并行,對每一層FPN輸出接上一個位置回歸子網,該子網本質也是FCN網絡,預測的是anchor和它對應的一個GT位置的偏移量。首先也是4層256維卷積,最后一層是4A維度,即對每一個anchor,回歸一個(x,y,w,h)四維向量。注意,此時的位置回歸是類別無關的。分類和回歸子網雖然是相似的結構,但是參數是不共享的。
模型的訓練和部署:使用訓練好的模型針對每個FPN level上目標存在概率最高的前1000bbox進行下一步的decoding處理,然后將所有level的bbox匯總,使用0.5threshold的nms過濾bbox最后得到目標最終的bbox位置;訓練的loss由bbox位置信息L1 loss和類別信息的focal loss組成,在模型初始化的時候考慮到正負樣本極度不平衡的情況對最后一個conv的bias參數做了有偏初始化;
注意幾點:
- 訓練時FPN每一級的所有example都被用于計算Focal Loss,loss值加到一起用來訓練;
- 測試時FPN每一級只選取score最大的1000個example來做nms;
- 整個結構不同層的head部分共享參數,但分類和回歸分支間的參數不共享
- 分類分支的最后一級卷積的bias初始化成 ?log((1?π)/π)-log((1-\pi)/\pi)?log((1?π)/π)
實驗部分
參考
-
Focal Loss for Dense Object Detection解讀
-
RetinaNet: Focal loss在目標檢測網絡中的應用
-
https://www.cnblogs.com/ziwh666/p/12494348.html









-可變形卷積)



)


)


