
編者按:最近,研究者們發布了?nocaps?挑戰,用以測量在沒有對應的訓練數據的情況下,模型能否準確描述測試圖像中新出現的各種類別的物體。針對挑戰中的問題,微軟?Azure?認知服務團隊和微軟研究院的研究員提出了全新解決方案視覺詞表預訓練?(Visual Vocabulary Pre-training)。該方法在?nocaps?挑戰中取得了新的?SOTA,并首次超越人類表現。
圖像描述或看圖說話(Image Captioning)是計算機根據圖片自動生成一句話來描述其中的內容,由于其潛在的應用價值(例如人機交互和圖像語言理解)而受到了廣泛的關注。這項工作既需要視覺系統對圖片中的物體進行識別,也需要語言系統對識別的物體進行描述,因此存在很多復雜且極具挑戰的問題。其中,最具挑戰的一個問題就是新物體描述(Novel object captioning),即描述沒有出現在訓練數據中的新物體。
最近,研究者們發布了 nocaps 挑戰(https://nocaps.org/),以測量在即使沒有對應的訓練數據的情況下,模型能否準確描述測試圖像中新出現的各種類別的物體。在這個挑戰中,雖然沒有配對的圖像和文本描述(caption)進行模型訓練,但是可以借助計算機視覺的技術來識別各類物體。例如在一些之前的工作中,模型可以先生成一個句式模板,然后用識別的物體進行填空。然而,這類方法的表現并不盡如人意。由于只能利用單一模態的圖像或文本數據,所以模型無法充分利用圖像和文字之間的聯系。另一類方法則使用基于 Transformer 的模型進行圖像和文本交互的預訓練(Vision and Language Pre-training)。這類模型在多模態(cross-modal)的特征學習中取得了有效的進展,從而使得后續在圖像描述任務上的微調(fine-tuning)獲益于預訓練中學到的特征向量。但是,這類方法依賴于海量的訓練數據,在這個比賽中無法發揮作用。
針對這些問題,微軟 Azure 認知服務團隊和微軟研究院的研究員們提出了全新的解決方案? Visual Vocabulary Pre-training(視覺詞表預訓練,簡稱VIVO),該方法在沒有文本標注的情況下也能進行圖像和文本的多模態預訓練。這使得訓練不再依賴于配對的圖像和文本標注,而是可以利用大量的計算機視覺數據集
VIVO 方法取得成功的關鍵在于視覺詞表(visual vocabulary)的建立。如圖1所示,研究人員把視覺詞表定義為一個圖像和文字的聯合特征空間(joint embedding space),其中語義相近的詞匯,例如男人和人、手風琴和樂器,會被映射到距離更近的特征向量上。在預訓練學習建立了視覺詞表以后,模型還會在有對應的文本描述的小數據集上進行微調。微調時,訓練數據只需要涵蓋少量的共同物體,例如人、狗、沙發,模型就能學習如何根據圖片和識別到的物體來生成一個通用的句式模板,并且把物體填入模板中相應的位置,例如,“人抱著狗”。在測試階段,即使圖片中出現了微調時沒有見過的物體,例如手風琴,模型依然可以使用微調時學到的句式,加上預訓練建立的視覺詞表進行造句,從而得到了“人抱著手風琴”這句描述。
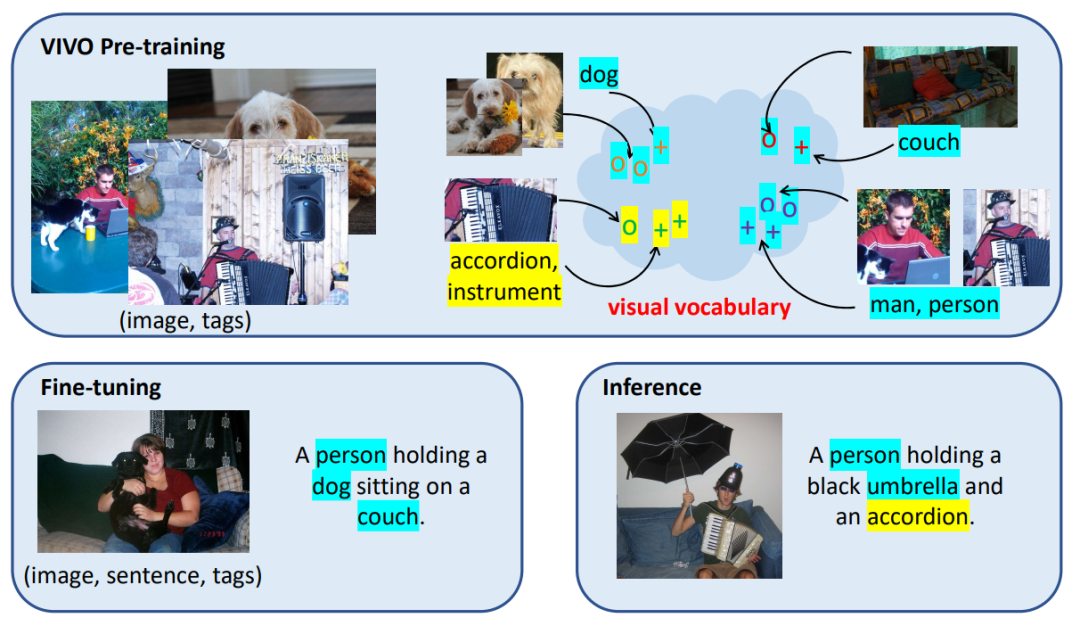
圖1:VIVO 預訓練使用大量的圖片標簽標注來建立視覺詞表,其中語義相近的詞匯與對應的圖像區域特征會被映射到距離相近的向量上。微調使用只涵蓋一部分物體(藍色背景)的少量文本描述標注進行訓練。在測試推理時,模型能夠推廣生成新物體(黃色背景)的語言描述,得益于預訓練時見過的豐富物體類型。
通過這樣的方法,研究員們結合了預訓練中識別圖片物體的能力,以及微調中用自然語言造句的能力,從而做到了在推理測試時舉一反三,使用更豐富的詞匯量來描述圖片中新出現的各種物體。
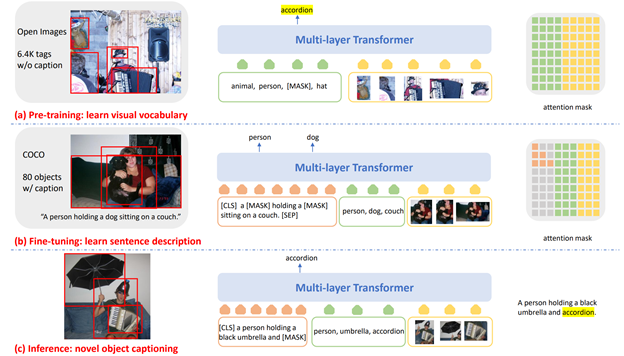
圖2:訓練和推理流程總覽(a)在VIVO 預訓練中,Transformer 模型在圖片標簽的訓練數據上做標簽預測,從而針對豐富的視覺概念進行多模態特征學習。(b)在微調中,模型在有文本描述標注的訓練數據上學習如何基于圖片和識別出來的物體生成一句話。(c)在推理時,對于給定的圖片和識別的物體,模型以自回歸的方式生成一系列字符,從而構成描述新物體的句子。
如圖2所示,VIVO 訓練流程采用了兩階段的訓練。第一階段為預訓練,使用多層的 Transformer 模型進行圖像分類的預測。具體來說,先給定圖片和對應的一些標簽(tag),然后隨機地抹去其中一部分標簽,讓模型來預測這些被抹去的標簽原本是什么。由于這些標簽之間的順序是可以互換的,因此需要使用匈牙利算法(Hungarian matching)來找到預測結果和目標標簽之間的一一對應,然后計算交叉熵損失(cross entropy loss)函數。
預訓練之后,第二階段為微調。Transformer 模型會在有文本描述標注的小數據集上訓練,例如 COCO。微調時使用的物體標簽可以來自數據集本身的標注,也可以由其他已經訓練好的圖像分類或物體識別模型自動生成。
在測試階段,對于給定圖片和識別出來的物體標簽,模型采用了自回歸(auto-regressive)的方式生成字符序列,從而獲得描述圖片的一句話。
研究員們將 VIVO 與 nocaps 挑戰中一些領先的方法,如 UpDown 、 OSCAR 等做了對比(這些方法使用的訓練數據也是 COCO)。另外,遵循之前的方法,添加了使用 SCST 和 Constrained Beam Search (CBS)之后的結果。在 nocaps 的校驗集(validation)和測試集(test)上的結果顯示在表1中。可以看到,相比于之前的方法,VIVO 的結果表現有了顯著的提高。僅僅使用 VIVO 預訓練就取得了遠超過 UpDown+ELMo+CBS 和 OSCAR 的結果。最終,VIVO 方法的結果達到了新的 SOTA,并且首次在 nocaps 挑戰中超過了人類表現的 CIDEr 得分。
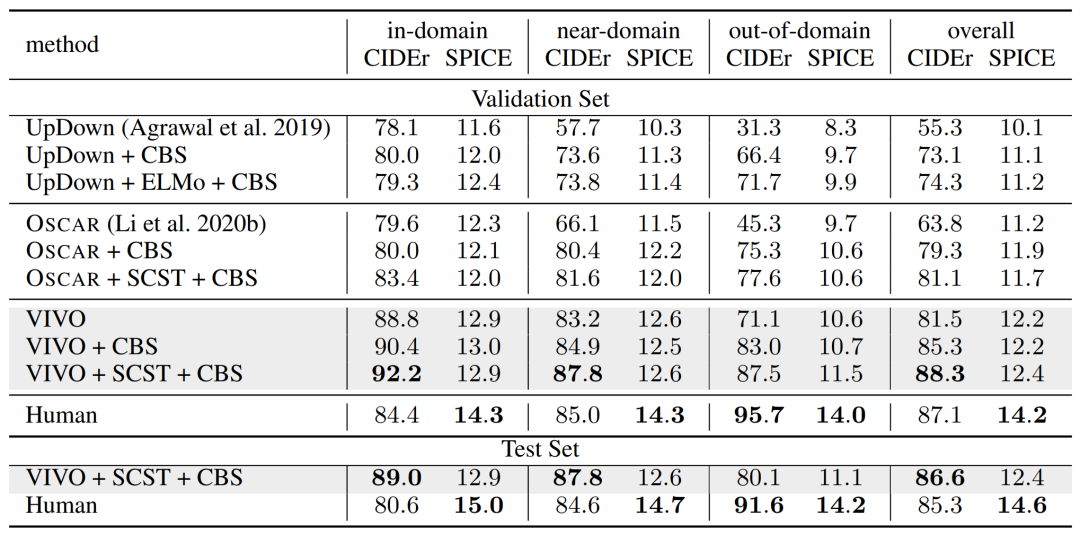
表1:各種方法在 nocaps 的校驗和測試數據集上的結果
為了進一步理解 VIVO 預訓練中學習視覺詞表所產生的作用,即在圖像和文字的共同特征空間中對準圖像與相應的語義標簽,研究員們展示了如何根據這些新物體的標簽找到它們在圖片中的位置(grounding to image regions)。對于每個圖片區域和每個物體標簽的兩兩配對,VIVO 都計算了它們對應特征向量之間的相似度(cosine similarity)。圖3高亮了其中得分高的配對。可以看出,VIVO 的模型能夠準確地在眾多區域中確定這些物體所在的位置。
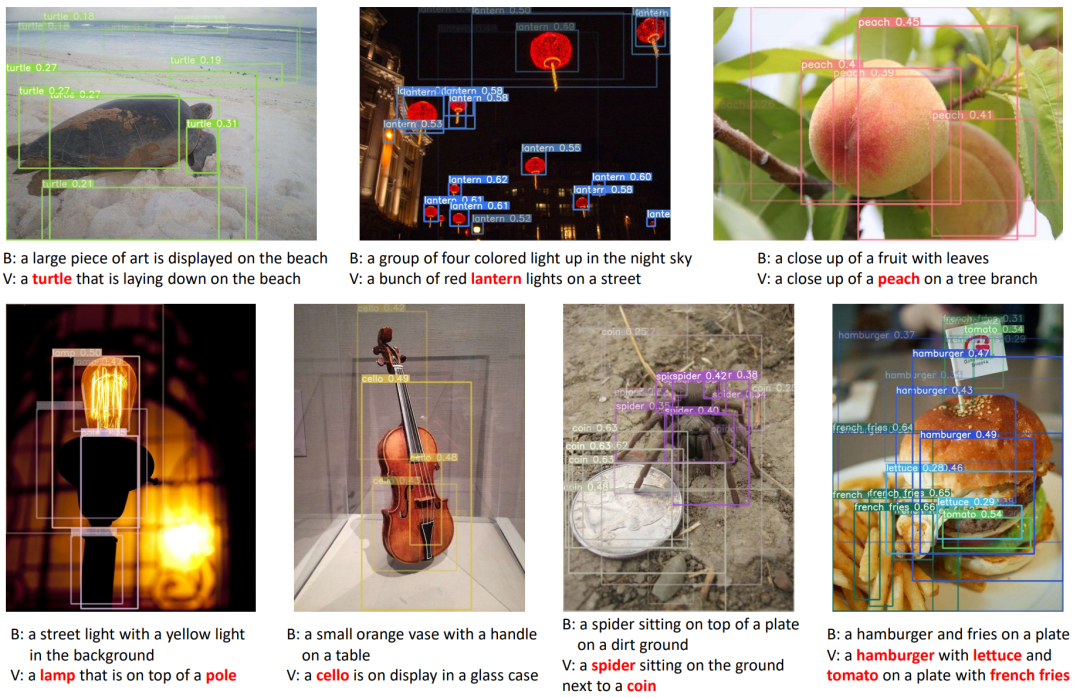
圖3:模型對 nocaps 圖片的描述結果。B:沒有做 VIVO 預訓練的模型。V:有 VIVO 預訓練的模型。紅色文字顯示了描述中出現的新物體。圖中還顯示了各個圖片區域和描述中出現的新物體對應特征向量之間的相似度,相似度越高的組合顏色亮度越高。
VIVO 展示了視覺詞表對描述圖片中新出現的物體的重要作用。作為第一個不依賴于圖片文本標注(paired image-sentence data)的圖像與文本交互的預訓練(Vision-Language Pre-training)方法,VIVO 成功運用了計算機視覺研究中已經標注的大規模圖片標簽數據(image tagging data)來進行全新模式的圖像與文本交互預訓練。值得注意的是,如果可以利用模型自動給圖片生成標簽,而不需要人工標注文本描述,那么可以在訓練時加入可能無限多的無標注圖片,從而進一步提高模型的表現,微軟的研究人員也將在未來的后續工作中對此進行更多探索。
你也許還想看:




)


)



)




)



)
為博客添加一個漂亮的分享按鈕)

![[Android] 年年有魚手機主題](http://pic.xiahunao.cn/[Android] 年年有魚手機主題)