?
?What is machine learning?
并沒有廣泛認可的定義來準確定義機器學習。以下定義均為譯文,若以后有時間,將補充原英文......
定義1、來自Arthur Samuel(上世紀50年代、西洋棋程序)
在進行特定編程的情況下給予計算機學習能力的領域。
定義2、來自Tom Mitchell(卡內基梅隆大學)
一個好的學習問題定義如下:一個程序被認為能從經驗E中學習,解決任務T,達到性能度量值P,
當且僅當,有了經驗E后,經過P評判,程序在處理T時的性能有所提升。
?
機器學習分類
- 監督學習(Supervised Learning)
- 常見算法:邏輯回歸(Logistic Regression)和反向傳遞神經網絡(Back Propagation Neural Network)
- 無監督學習(Unsupervised Learning)
- 常見算法:Apriori算法以及k-Means算法。
- 強化學習(Reinforcement Learning)
- 常見算法包括Q-Learning以及時間差學習(Temporal difference learning)
- 半監督學習(Semi-supervised Learning)
- 圖論推理算法(Graph Inference)或者拉普拉斯支持向量機(Laplacian SVM.)
- 深度學習(Deep Learning)
?
監督學習(Supervised Learning)
在監督學習中,給定一組數據,我們知道正確的輸出結果應該是什么樣子,并且知道在輸入和輸出之間有著一個特定的關系。
監督學習的分類:
- 回歸(Regression)
- 分類(Classification)
在回歸問題中,我們會預測一個連續值。也就是說我們試圖將輸入變量和輸出用一個連續函數對應起來;而在分類問題中,我們會預測一個離散值,我們試圖將輸入變量與離散的類別對應起來。
?
監督學習舉例:
回歸問題:
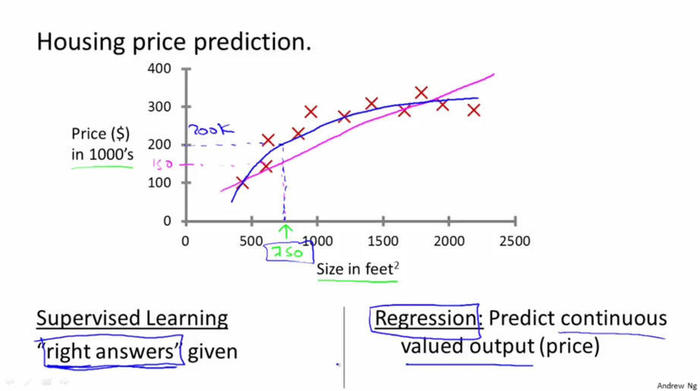
?
分類問題:
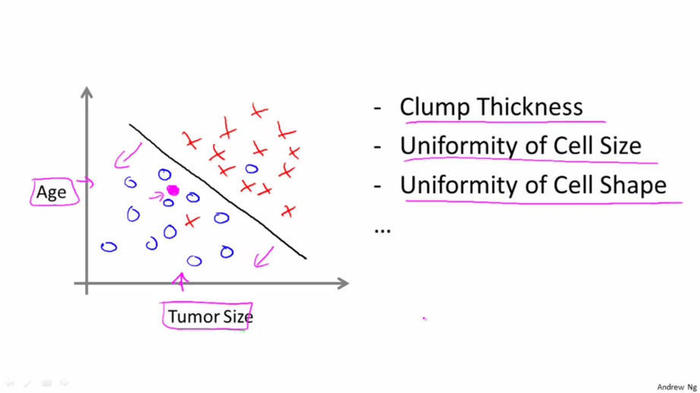
給定醫學數據,通過腫瘤的大小來預測該腫瘤是惡性瘤還是良性瘤(課程中給的是乳腺癌的例子),這就是一個分類問題,它的輸出是0或者1兩個離散的值。(0代表良性,1代表惡性)。
分類問題的輸出可以多于兩個,比如在該例子中可以有{0,1,2,3}四種輸出,分別對應{良性, 第一類腫瘤, 第二類腫瘤, 第三類腫瘤}。
下圖中上下兩個圖只是兩種畫法。第一個是有兩個軸,Y軸表示是否是惡性瘤,X軸表示瘤的大小; 第二個是只用一個軸,但是用了不同的標記,用O表示良性瘤,X表示惡性瘤。

在這個例子中特征只有一個,那就是瘤的大小。 有時候也有兩個或者多個特征, 例如下圖, 有“年齡”和“腫瘤大小”兩個特征。(還可以有其他許多特征,如下圖右側所示)
?無監督學習(Unsupervised Learning)
?在無監督學習中,我們基本上不知道結果會是什么樣子,但我們可以通過聚類的方式從數據中提取一個特殊的結構。在無監督學習中給定的數據是和監督學習中給定的數據是不一樣的。在無監督學習中給定的數據沒有任何標簽或者說只有同一種標簽。如下圖所示:
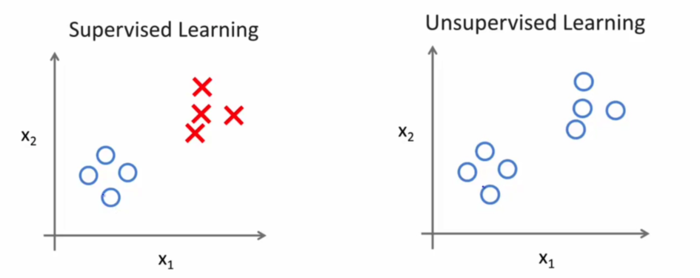
如下圖所示,在無監督學習中,我們只是給定了一組數據,我們的目標是發現這組數據中的特殊結構。例如我們使用無監督學習算法會將這組數據分成兩個不同的簇,,這樣的算法就叫聚類算法。
?
?無監督學習舉例:
例1、新聞分類
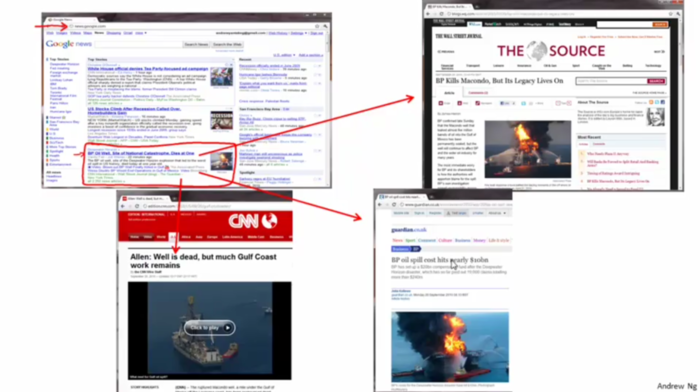
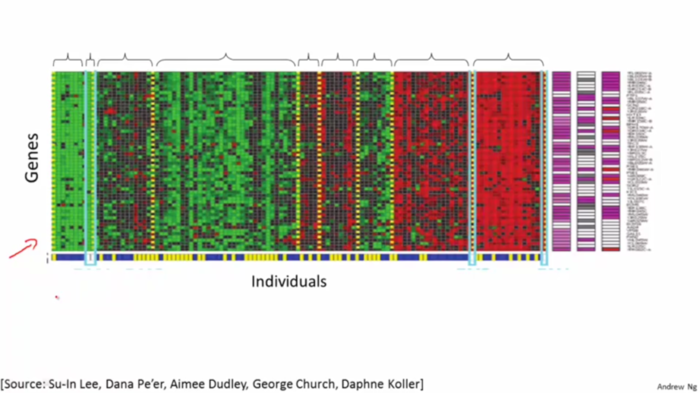
例2、根據給定基因將人群分類
如圖是DNA數據,對于一組不同的人我們測量他們DNA中對于一個特定基因的表達程度。然后根據測量結果可以用聚類算法將他們分成不同的類型。這就是一種無監督學習, 因為我們只是給定了一些數據,而并不知道哪些是第一種類型的人,哪些是第二種類型的人等等。
?
?半監督學習(Semi-supervised Learning):
在此學習方式下,輸入數據部分被標識,部分沒有被標識,這種學習模型可以用來進行預測,但是模型首先需要學習數據的內在結構以便合理的組織數據來進行預測。應用場景包括分類和回歸,算法包括一些對常用監督式學習算法的延伸,這些算法首先試圖對未標識數據進行建模,在此基礎上再對標識的數據進行預測。如圖論推理算法(Graph Inference)或者拉普拉斯支持向量機(Laplacian SVM.)等。
強化學習(Reinforcement Learning)
?
在這種學習模式下,輸入數據作為對模型的反饋,不像監督模型那樣,輸入數據僅僅是作為一個檢查模型對錯的方式,在強化學習下,輸入數據直接反饋到模型,模型必須對此立刻作出調整。常見的應用場景包括動態系統以及機器人控制等。常見算法包括Q-Learning以及時間差學習(Temporal difference learning)
?
遺傳算法(GENETIC ALGORITHIM):
和強化學期類似,? ? ? 淘汰弱者、試著生存的原則,通過這種淘汰機制去選擇最優的設計或模型
?
深度學習(Deep Learning):
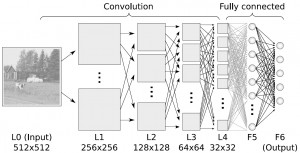
深度學習算法是對人工神經網絡的發展。 在近期贏得了很多關注, 特別是百度也開始發力深度學習后, 更是在國內引起了很多關注。?? 在計算能力變得日益廉價的今天,深度學習試圖建立大得多也復雜得多的神經網絡。很多深度學習的算法是半監督式學習算法,用來處理存在少量未標識數據的大數據集。常見的深度學習算法包括:受限波爾茲曼機(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷積網絡(Convolutional Network), 堆棧式自動編碼器(Stacked Auto-encoders)。
?
?總結:
有數據和標簽的監督學習、只有數據沒有標簽的非監督學習、結合了監督學習和非監督學習的半監督學習(少量有標簽、大量無標簽)、從經驗中總結提升的強化學習(機器人投籃)、有著適者生存不適者被淘汰準則的遺傳算法、對人工神經網絡的發展的深度學習。
?
在企業數據應用的場景下, 人們最常用的可能就是監督式學習和非監督式學習的模型。 在圖像識別等領域,由于存在大量的非標識的數據和少量的可標識數據, 目前半監督式學習是一個很熱的話題。 而強化學習更多的應用在機器人控制及其他需要進行系統控制的領域。
?
?
參考課程地址:Supervised Learning & Unsupervised Learning
https://www.bilibili.com/video/av9912938/index_8.html#page=1
參考文章鏈接:https://www.jianshu.com/p/7bae1ead174e
https://www.ctocio.com/hotnews/15919.html
?
















![【BZOJ 3326】[Scoi2013]數數 數位dp+矩陣乘法優化](http://pic.xiahunao.cn/【BZOJ 3326】[Scoi2013]數數 數位dp+矩陣乘法優化)
)

