主要介紹MP(Matching Pursuits)算法和OMP(Orthogonal Matching Pursuit)算法[1],這兩個算法雖然在90年代初就提出來了,但作為經典的算法,國內文獻(可能有我沒有搜索到)都僅描述了算法步驟和簡單的應用,并未對其進行詳盡的分析,國外的文獻還是分析的很透徹,所以我結合自己的理解,來分析一下寫到博客里,算作筆記。
1. 信號的稀疏表示(sparse representation of signals)
給定一個過完備字典矩陣 ,其中它的每列表示一種原型信號的原子。給定一個信號y,它可以被表示成這些原子的稀疏線性組合。信號 y 可以被表達為 y = Dx ,或者
,其中它的每列表示一種原型信號的原子。給定一個信號y,它可以被表示成這些原子的稀疏線性組合。信號 y 可以被表達為 y = Dx ,或者![]() 。 字典矩陣中所謂過完備性,指的是原子的個數遠遠大于信號y的長度(其長度很顯然是n),即n<<k。
。 字典矩陣中所謂過完備性,指的是原子的個數遠遠大于信號y的長度(其長度很顯然是n),即n<<k。
2.MP算法(匹配追蹤算法)
2.1 算法描述
作為對信號進行稀疏分解的方法之一,將信號在完備字典庫上進行分解。
假定被表示的信號為y,其長度為n。假定H表示Hilbert空間,在這個空間H里,由一組向量 構成字典矩陣D,其中每個向量可以稱為原子(atom),其長度與被表示信號 y 的長度n相同,而且這些向量已作為歸一化處理,即|
構成字典矩陣D,其中每個向量可以稱為原子(atom),其長度與被表示信號 y 的長度n相同,而且這些向量已作為歸一化處理,即| ,也就是單位向量長度為1。MP算法的基本思想:從字典矩陣D(也稱為過完備原子庫中),選擇一個與信號 y 最匹配的原子(也就是某列),構建一個稀疏逼近,并求出信號殘差,然后繼續選擇與信號殘差最匹配的原子,反復迭代,信號y可以由這些原子來線性和,再加上最后的殘差值來表示。很顯然,如果殘差值在可以忽略的范圍內,則信號y就是這些原子的線性組合。如果選擇與信號y最匹配的原子?如何構建稀疏逼近并求殘差?如何進行迭代?我們來詳細介紹使用MP進行信號分解的步驟:[1] 計算信號 y 與字典矩陣中每列(原子)的內積,選擇絕對值最大的一個原子,它就是與信號 y 在本次迭代運算中最匹配的。用專業術語來描述:令信號
,也就是單位向量長度為1。MP算法的基本思想:從字典矩陣D(也稱為過完備原子庫中),選擇一個與信號 y 最匹配的原子(也就是某列),構建一個稀疏逼近,并求出信號殘差,然后繼續選擇與信號殘差最匹配的原子,反復迭代,信號y可以由這些原子來線性和,再加上最后的殘差值來表示。很顯然,如果殘差值在可以忽略的范圍內,則信號y就是這些原子的線性組合。如果選擇與信號y最匹配的原子?如何構建稀疏逼近并求殘差?如何進行迭代?我們來詳細介紹使用MP進行信號分解的步驟:[1] 計算信號 y 與字典矩陣中每列(原子)的內積,選擇絕對值最大的一個原子,它就是與信號 y 在本次迭代運算中最匹配的。用專業術語來描述:令信號 ,從字典矩陣中選擇一個最為匹配的原子,滿足
,從字典矩陣中選擇一個最為匹配的原子,滿足 ,r0 表示一個字典矩陣的列索引。這樣,信號 y 就被分解為在最匹配原子
,r0 表示一個字典矩陣的列索引。這樣,信號 y 就被分解為在最匹配原子 的垂直投影分量和殘值兩部分,即:
的垂直投影分量和殘值兩部分,即: 。[2]對殘值R1f進行步驟[1]同樣的分解,那么第K步可以得到:
。[2]對殘值R1f進行步驟[1]同樣的分解,那么第K步可以得到:
 ,?其中
,?其中 ?滿足
?滿足 。可見,經過K步分解后,信號 y 被分解為:
。可見,經過K步分解后,信號 y 被分解為: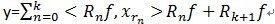 ,其中
,其中 。
。
2.2 繼續討論
(1)為什么要假定在Hilbert空間中?Hilbert空間就是定義了完備的內積空。很顯然,MP中的計算使用向量的內積運算,所以在在Hilbert空間中進行信號分解理所當然了。什么是完備的內積空間?篇幅有限就請自己搜索一下吧。
(2)為什么原子要事先被歸一化處理了,即上面的描述。內積常用于計算一個矢量在一個方向上的投影長度,這時方向的矢量必須是單位矢量。MP中選擇最匹配的原子是,是選擇內積最大的一個,也就是信號(或是殘值)在原子(單位的)垂直投影長度最長的一個,比如第一次分解過程中,投影長度就是 。,三個向量,構成一個三角形,且
。,三個向量,構成一個三角形,且 和
和 正交(不能說垂直,但是可以想象二維空間這兩個矢量是垂直的)。
正交(不能說垂直,但是可以想象二維空間這兩個矢量是垂直的)。
(3)MP算法是收斂的,因為, 和正交,由這兩個可以得出
和正交,由這兩個可以得出![]() ,得出每一個殘值比上一次的小,故而收斂。
,得出每一個殘值比上一次的小,故而收斂。
2.3 MP算法的缺點
如上所述,如果信號(殘值)在已選擇的原子進行垂直投影是非正交性的,這會使得每次迭代的結果并不少最優的而是次最優的,收斂需要很多次迭代。舉個例子說明一下:在二維空間上,有一個信號 y 被 D=[x1, x2]來表達,MP算法迭代會發現總是在x1和x2上反復迭代,即 ,這個就是信號(殘值)在已選擇的原子進行垂直投影的非正交性導致的。再用嚴謹的方式描述[1]可能容易理解:在Hilbert空間H中,,,定義
,這個就是信號(殘值)在已選擇的原子進行垂直投影的非正交性導致的。再用嚴謹的方式描述[1]可能容易理解:在Hilbert空間H中,,,定義 ,就是它是這些向量的張成中的一個,MP構造一種表達形式:
,就是它是這些向量的張成中的一個,MP構造一種表達形式:![]() ;這里的Pvf表示 f在V上的一個正交投影操作,那么MP算法的第 k 次迭代的結果可以表示如下(前面描述時信號為y,這里變成f了,請注意):
;這里的Pvf表示 f在V上的一個正交投影操作,那么MP算法的第 k 次迭代的結果可以表示如下(前面描述時信號為y,這里變成f了,請注意):![]()
如果  ?是最優的k項近似值,當且僅當
?是最優的k項近似值,當且僅當![]() 。由于MP僅能保證
。由于MP僅能保證![]() ,所以一般情況下是次優的。這是什么意思呢?是k個項的線性表示,這個組合的值作為近似值,只有在第k個殘差和正交,才是最優的。如果第k個殘值與正交,意味這個殘值與fk的任意一項都線性無關,那么第k個殘值在后面的分解過程中,不可能出現fk中已經出現的項,這才是最優的。而一般情況下,不能滿足這個條件,MP一般只能滿足第k個殘差和xk正交,這也就是前面為什么提到“信號(殘值)在已選擇的原子進行垂直投影是非正交性的”的原因。如果第k個殘差和fk不正交,那么后面的迭代還會出現fk中已經出現的項,很顯然fk就不是最優的,這也就是為什么說MP收斂就需要更多次迭代的原因。不是說MP一定得到不到最優解,而且其前面描述的特性導致一般得到不到最優解而是次優解。那么,有沒有辦法讓第k個殘差與正交,方法是有的,這就是下面要談到的OMP算法。
,所以一般情況下是次優的。這是什么意思呢?是k個項的線性表示,這個組合的值作為近似值,只有在第k個殘差和正交,才是最優的。如果第k個殘值與正交,意味這個殘值與fk的任意一項都線性無關,那么第k個殘值在后面的分解過程中,不可能出現fk中已經出現的項,這才是最優的。而一般情況下,不能滿足這個條件,MP一般只能滿足第k個殘差和xk正交,這也就是前面為什么提到“信號(殘值)在已選擇的原子進行垂直投影是非正交性的”的原因。如果第k個殘差和fk不正交,那么后面的迭代還會出現fk中已經出現的項,很顯然fk就不是最優的,這也就是為什么說MP收斂就需要更多次迭代的原因。不是說MP一定得到不到最優解,而且其前面描述的特性導致一般得到不到最優解而是次優解。那么,有沒有辦法讓第k個殘差與正交,方法是有的,這就是下面要談到的OMP算法。
3.OMP算法
3.1 算法描述
OMP算法的改進之處在于:在分解的每一步對所選擇的全部原子進行正交化處理,這使得在精度要求相同的情況下,OMP算法的收斂速度更快。
那么在每一步中如何對所選擇的全部原子進行正交化處理呢?在正式描述OMP算法前,先看一點基礎思想。
先看一個 k ?階模型,表示信號 f 經過 k 步分解后的情況,似乎很眼熟,但要注意它與MP算法不同之處,它的殘值與前面每個分量正交,這就是為什么這個算法多了一個正交的原因,MP中僅與最近選出的的那一項正交。
 (1)
(1)
?k + 1 階模型如下:
![]() (2)
(2)
應用 k + 1階模型減去k 階模型,得到如下:
![]() (3)
(3)
我們知道,字典矩陣D的原子是非正交的,引入一個輔助模型,它是表示 對前k個項
對前k個項![]() 的依賴,描述如下:
的依賴,描述如下:
 (4)
(4)
和前面描述類似,在span(x1, ...xk)之一上的正交投影操作,后面的項是殘值。這個關系用數學符號描述:![]()
請注意,這里的 a 和 b 的上標表示第 k 步時的取值。
將(4)帶入(3)中,有:
 (5)
(5)
如果一下兩個式子成立,(5)必然成立。
 (6)
(6)
 (7)
(7)
令![]() ,有
,有
![]()
其中![]() 。
。
ak的值是由求法很簡單,通過對(7)左右兩邊添加作內積消減得到:
![]()
后邊的第二項因為它們正交,所以為0,所以可以得出ak的第一部分。對于![]() ,在(4)左右兩邊中與
,在(4)左右兩邊中與 作內積,可以得到ak的第二部分。
作內積,可以得到ak的第二部分。
對于(4),可以求出 ,求的步驟請參見參考文件的計算細節部分。為什么這里不提,因為后面會介紹更簡單的方法來計算。
,求的步驟請參見參考文件的計算細節部分。為什么這里不提,因為后面會介紹更簡單的方法來計算。
3.2 收斂性證明
通過(7),由于與 正交,將兩個殘值移到右邊后求二范的平方,并將ak的值代入可以得到:
正交,將兩個殘值移到右邊后求二范的平方,并將ak的值代入可以得到:
![]()
可見每一次殘差比上一次殘差小,可見是收斂的。
3.3 算法步驟
整個OMP算法的步驟如下:

由于有了上面的來龍去脈,這個算法就相當好理解了。
到這里還不算完,后來OMP的迭代運算用另外一種方法可以計算得知,有位同學的論文[2]描述就非常好,我就直接引用進來:


對比中英文描述,本質都是一樣,只是有細微的差別。這里順便貼出網一哥們寫的OMP算法的代碼,源出處不得而知,共享給大家。

再貼另外一個洋牛paper[3]中關于OMP的描述,之所以引入,是因為它描述的非常嚴謹,但是也有點苦澀難懂,不過有了上面的基礎,就容易多了。

它的描述中的Sweep步驟就是尋找與當前殘差最大的內積時列在字典矩陣D中的索引,它的這個步驟描述說明為什么要選擇內積最大的以及如何選擇。見下圖,說的非常清晰。

它的算法步驟Update Provisional Solution中求![]() 很簡單,就是在 b = Ax 已知 A和b求x, 在x的最小二范就是A的偽逆與b相乘,即:
很簡單,就是在 b = Ax 已知 A和b求x, 在x的最小二范就是A的偽逆與b相乘,即:
![]()
看上去頭疼,其實用matlab非常簡單,看看上面的matlab的代碼就明白了。
我們可以看得出來,算法流程清晰明了,還是很好理解的。這正是OMP算法的魅力,作為工具使用簡單,背后卻隱藏著很有趣的思想。寫這篇博客的目的,是因為搜索了一下,MP和OMP沒有人很詳細的介紹。文獻[1]講的很清楚的,大家有興趣可以找來看看。不要被老板發現我居然在搜中文文獻還寫中文博客。
參考文獻:
[1]?Orthogonal Matching Pursuit:Recursive Function Approximat ion with Applications to Wavelet Decomposition
[2]http://wenku.baidu.com/view/22f3171614791711cc7917e4.html
[3]?From Sparse Solutions of Systems of Equations to Sparse Modeling of Signals and Images










二進制日志)

)
)



)

