Python常見面試200題及答案總結
/待完善/
1. 列出5個常用python標準庫?
os:提供了不少與操作系統相關聯的函數,提供了一種可移植的使用操作系統功能的方法。使用os模塊中提供的接口,可實現跨平臺訪問。但是,并不是所有的os模塊中的接口在全平臺都通用,有些接口的實現是依賴特定平臺的,比如linux相關的文件權限管理和進程管理。
os模塊的主要功能:系統相關、目錄及文件操作、執行命令和管理進程
>>> os.getcwd() # 返回當前的工作目錄
>>> os.chdir() # 修改當前的工作目錄
>>> os.system('mkdir today') # 執行系統命令 mkdirsys:通常用于命令行參數re:正則匹配math:數學運算datetime:處理日期時間
2. Python 內建數據類型有哪些?
數字(整型int、浮點數float、復數complex)布爾 boolBytes字符串 str列表 list元祖 tuple集合 set字典 dict
3. 簡述 with 方法打開處理文件幫我我們做了什么?
# 常規的打開文件寫法
f = open("./1.txt")
try:print(f.read())
excpet:pass
finally:f.colse()# with語句打開文件寫法
with open('1.txt') as f:print(f.read())
打開文件在進行讀寫的時候可能會出現一些異常狀況,如果按照常規的f.open寫法,需要try,except,finally,做異常判斷,并且文件最終不管遇到什么情況,都要執行finally f.close()關閉文件,with方法幫我們實現了finally中f.close。注意:with本身沒有異常捕獲的功能,如果發生了運行時異常,它照樣可以關閉文件釋放資源。
【格式】
with context [as var]:pass
其中:context是一個表達式,返回一個對象,var用來保存context表達式返回的對象,可以是單個或多個返回值。
with open('1.txt') as f:print(f.read())print(f.closed)
# 表達式open('1.txt')返回是一個_io.TextIOWrapper類型的變量對象,用f來保存。
# 在with語句塊中就可以使用這個變量操作文件。
# 執行with這個結構之后。f會自動關閉。相當于自帶了一個finally。輸出:
print # 1.txt文件的內容
True # 執行完with語句塊之后,f自動關閉
【with語句實質是上下文管理】
1、上下文管理協議。包含方法__enter__()和__exit__(),支持該協議對象要實現這兩個方法。
2、上下文管理器。定義執行with語句時要建立的運行時上下文,負責執行with語句快上下文中的進入與退出操作。
3、進入上下文的時候執行__enter__(),如果設置as var語句,var變量接受__enter__()方法返回值。
4、如果運行時發生了異常,就退出上下文管理器。調用管理器__exit__()方法。
【應用場景】
1、文件操作
2、進程線程之間互斥對象
3、支持上下文其他對象
4. 列出 Python 中可變數據類型和不可變數據類型,為什么?
詳解參考link
可變數據類型:在id(內存地址)不變的情況下,value(值)可以變,則稱為可變類型。即說明對一個變量進行操作時,其值是可變的,值的變化并不會引起新建對象,其地址是不會變的,只是地址中的內容變化了或者地址得到了擴充。
- 列表 list
- 字典 dict
# 以list為例
>>> a = [1, 2, 3]
>>> id(a)
41568816
>>> a = [1, 2, 3]
>>> id(a)
41575088
# 進行兩次a = [1, 2, 3]操作,兩次a引用的地址值是不同的,即說明其實創建了兩個不同的對象。
# 即在內存中保存了多個同樣值的對象,地址值不同。
>>> a.append(4)
>>> id(a)
41575088
>>> a += [2]
>>> id(a)
41575088
>>> a
[1, 2, 3, 4, 2]
# 對列表a進行操作,a引用的對象值改變了,但a的地址值沒有發生改變,只是在地址后面又擴充了新的地址。
不可變數據類型:value(值)一旦改變,id(內存地址)也改變,則稱為不可變類型(id變,意味著創建了新的內存空間)。
優點:內存中不管有多少個引用,相同的對象只占用了一塊內存。
缺點:當需要對變量進行運算從而改變變量引用的對象的值時,由于是不可變的數據類型,所以必須創建新的對象,這樣就會使得一次次的改變創建了一個個新的對象,不過不再使用的內存會被垃圾回收器回收。
- 數字(整型int、浮點數float、復數complex)
- 布爾 bool
- 字符串 str
- 元祖 tuple
- 集合 set
# int為例
>>> x = 1
>>> id(x)
31106520
>>> y = 1
>>> id(y)
31106520
# x、y引用對象都為1,id不變
>>> x = 2
>>> id(x)
31106508
>>> y = 2
>>> id(y)
31106508
>>> z = y
>>> id(z)
31106508
# 此時x、y、z引用對象變為2,id即改變了
5.Python 獲取當前日期?
import time
localtime = time.localtime(time.time())
print(localtime)# time.time()用于獲取當前時間時間戳。
# 每個時間戳都以自1970年1月1日午夜(歷元)經過了多長時間來表示。以秒為單位的浮點小數。
# 用localtime()函數將浮點數轉化為元祖struct_time結構
輸出:
time.struct_time(tm_year=2021, tm_mon=3, tm_mday=18, tm_hour=16, tm_min=18, tm_sec=48, tm_wday=3, tm_yday=77, tm_isdst=0)
6. 統計字符串每個單詞出現的次數
# collection模塊,實現了特定目標的容器,以提供Python標準內建容器 dict , list , set , 和 tuple 的替代選擇。
from collections import Counterstr1 = 'I can because i think i can'
# Counter -- 字典的子類,提供了可哈希對象的計數功能
counts = Counter(str1.split())
print(counts)
輸出:
Counter({'can': 2, 'i': 2, 'I': 1, 'because': 1, 'think': 1})
7. 用 python 刪除文件和用 linux 命令刪除文件方法
# python
import os
os.remove('111.py')
# linux
rm 111.py
8. 寫一段自定義異常代碼
# 本模塊的基類
class CalcErr(Exception):pass# 非整型引發異常
class NumErorr(CalcErr):"""輸入的非整型數據類型將引發此異常"""def __init__(self, numA, numB): # 異常類對象的初始化屬性"""用戶輸入的數據"""self.numA = numAself.numB = numBdef __str__(self): # 返回異常類對象說明信息"""返回異常描述"""return f"本計算機只接收整數!"# 計算函數,try子句引發異常
def calculator(a, b):"""a+b=c"""try:if type(a) != int or type(b) != int:raise NumErorr(a, b) # 拋出異常類對象,傳入初始化數據except Exception as e: # 捕獲異常,返回描述信息print(e)else: # 輸入正常的情況下,直接計算,不引發一場c = a + bprint(c)9. 舉例說明異常模塊中 try except else finally 的相關意義
try...except...else沒有捕獲到異常,執行else語句try...except...finally不管是否捕獲到異常,都執行finally語句
10. 遇到 bug 如何處理
1、細節上的錯誤,通過print()打印,能執行到print()說明一般上面的代碼沒有問題,分段檢測程序是否有問題,如果是js的話可以alert或console.log2、如果涉及一些第三方框架,會去查官方文檔或者一些技術博客。3、對于bug的管理與歸類總結,一般測試將測試出的bug用teambin等bug管理工具進行記錄,然后我們會一條一條進行修改,修改的過程也是理解業務邏輯和提高自己編程邏輯縝密性的方法,我也都會收藏做一些筆記記錄。4、導包問題、城市定位多音字造成的顯示錯誤問題
語言特性
1. 談談對 Python 和其他語言的區別
1、語言特點:簡潔,省略了各種大括號和分號,還有一些關鍵字,類型說明;縮緊表達邏輯
2、語言類型:解釋型語言,運行的時候是一行一行的解釋,并運行,所以調試代碼很方便,開發效率很高;但運行速度慢。
3、第三方庫:python是開源的
4、可移植性
2.簡述解釋型和編譯型編程語言

- 解釋型
使用專門的解釋器對源程序逐行解釋成特定平臺的機器碼并立即執行。解釋型語言不需要事先編譯,其直接將源代碼解釋成機器碼并立即執行,所以只要某一平臺提供了相應的解釋器即可運行該程序。解釋型語言每次運行都需要將源代碼解釋稱機器碼并執行,效率較低;只要平臺提供相應的解釋器,就可以運行源代碼,所以可以方便源程序移植;Python等屬于解釋型語言。
- 編譯型
使用專門的編譯器,針對特定的平臺,將高級語言源代碼一次性的編譯成可被該平臺硬件執行的機器碼,并包裝成該平臺所能識別的可執行性程序的格式。在編譯型語言寫的程序執行之前,需要一個專門的編譯過程,把源代碼編譯成機器語言的文件,如exe格式的文件,以后要再運行時,直接使用編譯結果即可,如直接運行exe文件。因為只需編譯一次,以后運行時不需要編譯,所以編譯型語言執行效率高。一次性的編譯成平臺相關的機器語言文件,運行時脫離開發環境,運行效率高;與特定平臺相關,一般無法移植到其他平臺;現有的C、C++、Objective等都屬于編譯型語言。
- 區別
主要區別在于,編譯源程序編譯后即可在該平臺運行,翻譯是在運行期間才編譯。所以編譯性語言運行速度快,翻譯性語言跨平臺性好。
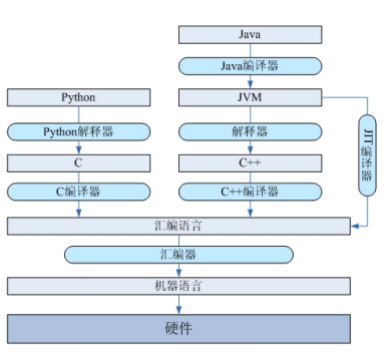

- 有關java是什么語言?
確切的說java就是解釋型語言,其所謂的編譯過程只是將.java文件編譯成平臺無關的字節碼.class文件,并不是向C一樣編譯成可執行的機器語言,請注意Java中所謂的“編譯”和傳統的“編譯”的區別)。作為編譯型語言,JAVA程序要被統一編譯成字節碼文件——文件后綴.class。此種文件在java中又稱為類文件。java類文件不能再計算機上直接執行,它需要被java虛擬機(JVM)翻譯成本地的機器碼后才能執行,而java虛擬機的翻譯過程則是解釋性的。java字節碼文件首先被加載到計算機內存中,然后讀出一條指令,翻譯一條指令,執行一條指令,該過程被稱為java語言的解釋執行,是由java虛擬機完成的。而在現實中,java開發工具JDK提供了兩個很重要的命令來完成上面的編譯和解釋(翻譯)過程。兩個命令分別是java.exe和javac.exe,前者加載java類文件,并逐步對字節碼文件進行編譯,而另一個命令則對應了java語言的解釋(javac.exe)過程。在次序上,java語言是要先進行編譯的過程,接著解釋執行。
3.Python 的解釋器種類以及相關特點?
當我們編寫完Python代碼時,我們會得到一個包含Python代碼的以.py為擴展名的文件,這個時候,我們要運行這個代碼,就需要Python解釋器去執行.py文件。
- CPython
用C語言實現的Python解釋器,也是官方的并且最廣泛使用的Python解釋器;CPython是使用字節碼的解釋器,任何程序源代碼在執行之前都先要編譯成字節碼,它還有和幾種其他語言交互的外部函數接口,特點就是使用最廣的解釋器
- IPython
基于CPython之上的一個交互式解釋器,也就是說,IPython只是在交互方式上有所增強,但是執行Python代碼的功能和CPython是完全一樣的,好比國產瀏覽器雖然外觀不同,但是內核其實都是調用了IDE,特點就是交互方式很強。
- PyPy
目標是執行速度,采用JIT技術(Just-In-Time,即時編譯器),對Python代碼進行動態編譯,所以可以顯著提高Python代碼的執行速度,所以它最大的特點就是可以提高執行效率。
- JPython
運行在Java平臺上的Python解釋器,可以直接把Python代碼編譯成Java字節碼執行。
- IronPython
和JPython類似,只不過IronPython是運行在微軟.net平臺上的Python解釋器,可以直接把Python代碼編譯成.net的字節碼,其優勢也是顯而易見的。
4. 說說你知道的Python3 和 Python2 之間的區別?
在 Python 2 中,print 是一條語句;在py2中,print語句后面接的是一個元組對象。而 Python3 中作為函數存在。而py3中,print函數可以接收多個未知參數。
# py2
>>> print("hello", "world")
('hello', 'world')# py3
>>> print("hello", "world")
hello word
- 編碼
Python2的默認編碼是ASCII碼;Python3默認采用UTF-8編碼,因此不需要在文件頂部寫# coding=utf-8了。
- 字符串
| py2 | py3 | 表現 | 轉換 | 作用 |
|---|---|---|---|---|
| str | byte | 字節 | encode | 存儲、傳輸 |
| unicode | str | 字符 | decode | 展示 |
- True和False
在Python2中,True和False是兩個全局變量(名字),數值上分別對應1和0,因為是變量,可以指向其他對象。
# py2
>>> True = False
>>> print(True)
False
>>> True is False
True
Python3中修正了這個缺陷,True和False變為兩個關鍵字,永遠指向兩個固定的對象,不允許被重新賦值。
# py3
>>> True = 1File "<stdin>", line 1
SyntaxError: cant't assign to keyword
- 迭代器
在python2中很多返回列表對象的內置函數和方法在python3中都改成了類似于「迭代器」的對象,因為迭代器的惰性加載特性使得操作大數據更有效率。Python2中的range和xragne函數合并成了range函數。
另外,字典對象的dict.keys()、dict.values()方法都不在返回列表,而是以一個類似迭代器的“view”對象返回。高階函數map、filter、zip返回的也不是列表對象。Python2的迭代器必須實現next方法,而python3改成了__next__
- nonlocal
Python2中可以在函數里面用關鍵字global聲明某個變量為全局變量,但是在嵌套函數中,想要給一個變量聲明為非局部變量是沒法實現的,在python3中,新增了關鍵字nonlocal,使得非局部變量成為可能。
def func():c = 1def foo():c = 12foo()print(c)func()輸出:
1
def func():c = 1def foo():nonlocal cc = 12foo()print(c)func()輸出:
12
5. Python3 和 Python2 中 int 和 long 區別?
Python2:long(長整型)數字末尾有一個L64位機器,范圍-2^63~2^63-1超出上述范圍,python 自動轉化為 long (長整型)python3:所有整型都是 int,沒有 long (長整型)
6. xrange 和 range 的區別?
python2:xrange:不會在內存中立即創建,而是在循環時,邊循環邊創建 range:在內存立即把所有的值創建 python3:只有 range,相當于 python2 中的 xrange range:不會在內存中立即創建,而是在循環時,邊循環邊創建
編碼規范
7.什么是 PEP8?
8.了解 Python 之禪么?
9.了解 docstring 么?
10.了解類型注解么?
11.例舉你知道 Python 對象的命名規范,例如方法或者類等
12.Python 中的注釋有幾種?
13.如何優雅的給一個函數加注釋?
14.如何給變量加注釋?
15.Python 代碼縮進中是否支持 Tab 鍵和空格混用。
16.是否可以在一句 import 中導入多個庫?
17.在給 Py 文件命名的時候需要注意什么?
18.例舉幾個規范 Python 代碼風格的工具
數據類型
字符串
19.列舉 Python 中的基本數據類型?
20.如何區別可變數據類型和不可變數據類型
21.將"hello world"轉換為首字母大寫"Hello World"
22.如何檢測字符串中只含有數字?
23.將字符串"ilovechina"進行反轉
24.Python 中的字符串格式化方式你知道哪些?
25.有一個字符串開頭和末尾都有空格,比如“ adabdw ”,要求寫一個函數把這個字符串的前后空格都去掉。
26. 獲取字符串”123456“最后的兩個字符。
s = "123456"
tmp = s[4:6:1]
print(tmp)輸入:
56
27. 一個編碼為 GBK 的字符串 S,要將其轉成 UTF-8 編碼的字符串,應如何操作?
demo_str = "demo".encode("gbk")
demo = demo_str.decode('gbk').encode('utf-8')
28. (1)s=“info:xiaoZhang 33 shandong”,用正則切分字符串輸出[‘info’, ‘xiaoZhang’, ‘33’, ‘shandong’]a = "你好 中國 ",去除多余空格只留一個空格。
29. 怎樣將字符串轉換為小寫?
print(s.lower())
# 注意s.lower()不會改變原來字符串s里的大小寫
- 單引號、雙引號、三引號的區別?
1、在Python中,單引號和雙引號都可以用來表示一個字符串,在沒有遇到轉義字符的情況下,是完全一樣的;有轉義字符的話,分情況。2、用單引號或者雙引號定義一個字符串的時候只能把字符串連在一起寫成一行,如果非要寫成多行,就得在每一行后面加一個\表示連字符,或者用轉義字符\n;此時就可以用三引號了,單雙一樣;三引號還有注釋的作用。
列表
30. 已知 AList = [1,2,3,1,2],對 AList 列表元素去重,寫出具體過程。
tmp = set(AList)
AList = list(tmp)
print(AList)輸出:
[1, 2, 3]
31. 如何實現 “1,2,3” 變成 [“1”,“2”,“3”]
s = "1,2,3"
lst = list(map(str, s.split(',')))
print(lst)輸出:
['1', '2', '3']
32. 給定兩個 list,A 和 B,找出相同元素和不同元素
A=[1,2,3,4,5,6,7,8,9]
B=[1,3,5,7,9]
print('A、B中相同元素:')
print(set(A)&set(B))
print('A、B中不同元素:')
print(set(A)^set(B))
33.[[1,2],[3,4],[5,6]]一行代碼展開該列表,得出[1,2,3,4,5,6]
34.合并列表[1,5,7,9]和[2,2,6,8]
35. 如何打亂一個列表的元素?
from random import shufflelst = [1, 3, 4]
shuffle(lst)
print(lst)輸出:
[4, 3, 1]
字典
36.字典操作中 del 和 pop 有什么區別
37.按照字典的內的年齡排序
38.請合并下面兩個字典 a = {“A”:1,“B”:2},b = {“C”:3,“D”:4}
39.如何使用生成式的方式生成一個字典,寫一段功能代碼。
40.如何把元組(“a”,“b”)和元組(1,2),變為字典{“a”:1,“b”:2}
綜合
41. Python 常用的數據結構的類型及其特性?
42. 如何交換字典 {“A”:1,“B”:2}的鍵和值?
new_dic = {v: k for k, v in dic.items()}
43. Python 里面如何實現 tuple 和 list 的轉換?
lst = [1,2,3]
tup = tuple(lst)
print(tup)輸出:
(1, 3, 4)
44.我們知道對于列表可以使用切片操作進行部分元素的選擇,那么如何對生成器類型的對象實現相同的功能呢?
45. 請將[i for i in range(3)]改成生成器
在 Python 中,使用了 yield 的函數被稱為生成器(generator)。
跟普通函數不同的是,生成器是一個返回迭代器的函數,只能用于迭代操作,更簡單點理解生成器就是一個迭代器。
在調用生成器運行的過程中,每次遇到 yield 時函數會暫停并保存當前所有的運行信息,返回 yield 的值, 并在下一次執行 next() 方法時從當前位置繼續運行。
調用一個生成器函數,返回的是一個迭代器對象。
(i for i in range(3))
46. a="hello"和 b="你好"編碼成 bytes 類型
a = b"hello"
b = bytes("你好", 'utf-8')
c = "hello".encode(encoding='utf-8')
d = "你好".encode(encoding='utf-8')
print(a, end='\n')
print(b, end='\n')
print(c, end='\n')
print(d, end='\n'輸出:
b'hello'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
b'hello'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
操作類題目
49.Python 交換兩個變量的值
50.在讀文件操作的時候會使用 read、readline 或者 readlines,簡述它們各自的作用
51.json 序列化時,可以處理的數據類型有哪些?如何定制支持 datetime 類型?
52.json 序列化時,默認遇到中文會轉換成 unicode,如果想要保留中文怎么辦?
53.有兩個磁盤文件 A 和 B,各存放一行字母,要求把這兩個文件中的信息合并(按字母順序排列),輸出到一個新文件 C 中。
54.如果當前的日期為 20190530,要求寫一個函數輸出 N 天后的日期,(比如 N 為 2,則輸出 20190601)。
55.寫一個函數,接收整數參數 n,返回一個函數,函數的功能是把函數的參數和 n 相乘并把結果返回。
56.下面代碼會存在什么問題,如何改進?
57.一行代碼輸出 1-100 之間的所有偶數。
-
with 語句的作用,寫一段代碼?
-
python 字典和 json 字符串相互轉化方法
-
請寫一個 Python 邏輯,計算一個文件中的大寫字母數量
-
請寫一段 Python連接 Mongo 數據庫,然后的查詢代碼。
-
說一說 Redis 的基本類型。
-
請寫一段 Python連接 Redis 數據庫的代碼。
-
請寫一段 Python 連接 MySQL 數據庫的代碼。
-
了解 Redis 的事務么?
-
了解數據庫的三范式么?
-
了解分布式鎖么?
-
用 Python 實現一個 Reids 的分布式鎖的功能。
-
寫一段 Python 使用 Mongo 數據庫創建索引的代碼。
高級特性
70.函數裝飾器有什么作用?請列舉說明?
71.Python 垃圾回收機制?
72.魔法函數 __call__怎么使用?
73.如何判斷一個對象是函數還是方法?
74.@classmethod 和@staticmethod 用法和區別
75.Python 中的接口如何實現?
76.Python 中的反射了解么?
77.metaclass 作用?以及應用場景?
78.hasattr() getattr() setattr()的用法
79.請列舉你知道的 Python 的魔法方法及用途。
80.如何知道一個 Python 對象的類型?
81.Python 的傳參是傳值還是傳址?
82.Python 中的元類(metaclass)使用舉例
83.簡述 any()和 all()方法
84.filter 方法求出列表所有奇數并構造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
85.什么是猴子補丁?
86.在 Python 中是如何管理內存的?
87.當退出 Python 時是否釋放所有內存分配?
正則表達式
88.使用正則表達式匹配出
百度一下,你就知道
中的地址 a=“張明 98 分”,用 re.sub,將 98 替換為 10089. 正則表達式匹配中(.*)和(.*?)匹配區別?
(.*)是貪婪匹配,會把滿足正則的盡可能多的往后匹配(.*?)是非貪婪匹配,會把滿足正則的盡可能少匹配
import re
s= str("<a>哈哈</a><a>啦啦</a>")
res1 = re.findall("<a>(.*)</a>",s)
print(res1)
res2 = re.findall("<a>(.*?)</a>",s)
print(res2)
90. 寫一段匹配郵箱的正則表達式
合法郵箱的例子:
1234@qq.com(純數字)
wang@126.com(純字母)
wang123@126.com(數字、字母混合)
wang123@vip.163.com(多級域名)
wang_email@outlook.com(含下劃線 _)
wang.email@gmail.com(含英語句號 .)
根據對以上郵箱的觀察,可將郵箱分為兩部分(“@”左邊和右邊部分)來進行分析:1 左邊部分可以有數字、字母、下劃線(_)和英語句號(.),因此可以表示成:[A-Za-z0-9]+([_\.][A-Za-z0-9]+)*。
2 右邊部分是域名,按照域名的規則,可以有數字、字母、短橫線(-)和英語句號(.),另外頂級域名一般為 2 ~ 6 個英文字母(比如“cn”、“com”、“site”、“group”、“online”),故可表示為:([A-Za-z0-9\-]+\.)+[A-Za-z]{2,6}。
要注意兩點:
1 考慮到匹配郵箱時字符串的一頭一尾不能有其它字符,故要加上開始標志元字符 ^ 和結束標志元字符 $。
2 英語句號(.)是正則表達式的元字符,因此要進行轉義(\.)。
email = /^[A-Za-z0-9]+([_\.][A-Za-z0-9]+)*@([A-Za-z0-9\-]+\.)+[A-Za-z]{2,6}$/
其他內容
91.解釋一下 python 中 pass 語句的作用?
92.簡述你對 input()函數的理解
93.python 中的 is 和==
94. Python 中的命名空間和作用域
命名空間(Namespace)是從名稱到對象的映射,大部分的命名空間都是通過Python字典來實現的。命名空間提供了在項目中避免名字沖突的一種方法。各個命名空間是獨立的,沒有任何關系的,所以一個命名空間中不能有重名,但不同的命名空間是可以重名而沒有任何影響。一般有三種命名空間:
1、內置名稱(built-in names),Python語言內置的名稱,比如函數名 abs、char 和異常名稱BaseException、Exception 等等。
2、全局名稱(global names),模塊中定義的名稱,記錄了模塊的變量,包括函數、類、其它導入的模塊、模塊級的變量和常量。
3、局部名稱(local names),函數中定義的名稱,記錄了函數的變量,包括函數的參數和局部定義的變量。(類中定義的也是)命名空間查找順序:
假設我們要使用變量runoob,則 Python 的查找順序為:局部的命名空間去 -> 全局命名空間 -> 內置命名空間。
如果找不到變量 runoob,它將放棄查找并引發一個 NameError 異常:
NameError: name 'runoob' is not defined。命名空間的生命周期:
命名空間的生命周期取決于對象的作用域,如果對象執行完成,則該命名空間的生命周期就結束。
因此,我們無法從外部命名空間訪問內部命名空間的對象。
作用域就是一個Python程序可以直接訪問命名空間的正文區域。在一個python程序中,直接訪問一個變量,會從內到外依次訪問所有的作用域直到找到,否則會報未定義的錯誤。Python中,程序的變量并不是在哪個位置都可以訪問的,訪問權限決定于這個變量是在哪里賦值的。變量的作用域決定了在哪一部分程序可以訪問哪個特定的變量名稱。Python的作用域一共有4種,分別是:
L(Local):最內層,包含局部變量,比如一個函數/方法內部。
E(Enclosing):包含了非局部(non-local)也非全局(non-global)的變量。
比如兩個嵌套函數,一個函數(或類) A 里面又包含了一個函數 B ,那么對于 B 中的名稱來說 A 中的作用域就為 nonlocal。
G(Global):當前腳本的最外層,比如當前模塊的全局變量。
B(Built-in): 包含了內建的變量/關鍵字等。,最后被搜索
規則順序: L –> E –> G –>gt; B。
在局部找不到,便會去局部外的局部找(例如閉包),再找不到就會去全局找,再者去內置中找。注意:Python 中只有模塊(module),類(class)以及函數(def、lambda)才會引入新的作用域,其它的代碼塊(如 if/elif/else/、try/except、for/while等)是不會引入新的作用域的,也就是說這些語句內定義的變量,外部也可以訪問,
95.三元運算寫法和應用場景?
96.了解 enumerate 么?
97.列舉 5 個 Python 中的標準模塊
98.如何在函數中設置一個全局變量
99.pathlib 的用法舉例
100.Python 中的異常處理,寫一個簡單的應用場景
101.Python 中遞歸的最大次數,那如何突破呢?
102.什么是面向對象的 mro
103.isinstance 作用以及應用場景?
104.什么是斷言?應用場景?
105.lambda 表達式格式以及應用場景?
106.新式類和舊式類的區別
107.dir()是干什么用的?
108.一個包里有三個模塊,demo1.py, demo2.py, demo3.py,但使用 from tools import *導入模塊時,如何保證只有 demo1、demo3 被導入了。
109.列舉 5 個 Python 中的異常類型以及其含義
110.copy 和 deepcopy 的區別是什么?
111.代碼中經常遇到的*args, **kwargs 含義及用法。
112.Python 中會有函數或成員變量包含單下劃線前綴和結尾,和雙下劃線前綴結尾,區別是什么?
113.w、a+、wb 文件寫入模式的區別
114.舉例 sort 和 sorted 的區別
115.什么是負索引?
116.pprint 模塊是干什么的?
117.解釋一下 Python 中的賦值運算符
118.解釋一下 Python 中的邏輯運算符
119.講講 Python 中的位運算符
120.在 Python 中如何使用多進制數字?
121.怎樣聲明多個變量并賦值?
算法和數據結構
122.已知:
(1) 從 AList 和 BSet 中 查找 4,最壞時間復雜度那個大?
(2) 從 AList 和 BSet 中 插入 4,最壞時間復雜度那個大?
123.用 Python 實現一個二分查找的函數
124.python 單例模式的實現方法
125.使用 Python 實現一個斐波那契數列
126.找出列表中的重復數字
127.找出列表中的單個數字
128.寫一個冒泡排序
129.寫一個快速排序
130.寫一個拓撲排序
131.python 實現一個二進制計算
132.有一組“+”和“-”符號,要求將“+”排到左邊,“-”排到右邊,寫出具體的實現方法。
133.單鏈表反轉
134.交叉鏈表求交點
135.用隊列實現棧
136.找出數據流的中位數
137.二叉搜索樹中第 K 小的元素
爬蟲相關
138.在 requests 模塊中,requests.content 和 requests.text 什么區別
139.簡要寫一下 lxml 模塊的使用方法框架
140.說一說 scrapy 的工作流程
141.scrapy 的去重原理
142.scrapy 中間件有幾種類,你用過哪些中間件
143.你寫爬蟲的時候都遇到過什么?反爬蟲措施,你是怎么解決的?
144.為什么會用到代理?
145.代理失效了怎么處理?
146.列出你知道 header 的內容以及信息
147.說一說打開瀏覽器訪問 百度一下,你就知道 獲取到結果,整個流程。
148.爬取速度過快出現了驗證碼怎么處理
149.scrapy 和 scrapy-redis 有什么區別?為什么選擇 redis 數據庫?
150.分布式爬蟲主要解決什么問題
151.寫爬蟲是用多進程好?還是多線程好? 為什么?
152.解析網頁的解析器使用最多的是哪幾個
153.需要登錄的網頁,如何解決同時限制 ip,cookie,session(其中有一些是動態生成的)在不使用動態爬取的情況下?
154.驗證碼的解決(簡單的:對圖像做處理后可以得到的,困難的:驗證碼是點擊,拖動等動態進行的?)
155.使用最多的數據庫(mysql,mongodb,redis 等),對他的理解?
網絡編程
156.TCP 和 UDP 的區別?
157.簡要介紹三次握手和四次揮手
158.什么是粘包? socket 中造成粘包的原因是什么? 哪些情況會發生粘包現象?
并發
159.舉例說明 conccurent.future 的中線程池的用法
160. 說一說多線程,多進程和協程的區別。
1、進程是操作系統分配的最小單位,線程是CPU調度的最小單位,協程既不是進程也不是線程,協程僅僅是一個特殊的函數,協程和進程、線程不是一個維度的。2、一個進程由一個或者多個線程組成,線程是一個進程中代碼的不同執行路線,協程是屬于一種操作,是由用戶自己去操作線程的切換(在用戶態進行切換),這樣的話,就可以大大降低線程切換(在內核態切換)的花銷。3、切換進程需要的花銷(時間、資源等)比切換線程要大,切換線程也是需要花銷的,協程與進程一樣,切換是存在上下文切換問題的。4、一個進程可以包含多個線程,一個線程可以包含多個協程。5、一個線程內的多個協程雖然可以切換,但是多個協程是串行執行的,只能在一個線程內運行,沒法利用CPU多核能力。# 多進程執行多任務
import os
import time
from multiprocessing import Pool# multiprocessing模塊提供了一個Pool進程池的方式批量創建子進程。def long_time_task(name):print('Run task %s (%s)...' % (name, os.getpid()))start = time.time()time.sleep(1) # 線程推遲執行的時間end = time.time()print('Task %s runs %0.2f seconds.' % (name, (end - start)))if __name__ == '__main__':print('Parent process %s.' % os.getpid())p = Pool(5) # Pool對象,參數5表示調用多少個并行進程進行程序運行,pool的默認容量為CPU的計算核數量for i in range(10):p.apply_async(long_time_task, args=(i,)) # p.apply_async()函數給進程池添加進程任務,它的參數包括待運行程序和程序的傳入參數。print('Waiting for all subprocess done ...')p.close() # 對Pool對象調用join()方法會等待所有子進程執行完畢,調用join()之前必須先調用close(),調用close()之后就不能繼續添加新的Process了。p.join() # join()方法可以等待子進程結束后再繼續往下運行,通常用于進程間的同步。print('All subprocesses done.')# 多線程執行多任務
import time
import threading
# threading模塊# 新線程執行的代碼:def loop():print('thread %s is running...' % threading.current_thread().name)# threading.current_thread()永遠返回當前線程的實例n = 0while n < 5:n = n + 1print('thread %s >>> %s' % (threading.current_thread().name, n))time.sleep(1)print('thread %s ended.' % threading.current_thread().name)print('thread %s is running...' % threading.current_thread().name)t = threading.Thread(target=loop, name='LoopThread') # 用LoopThread命名子線程t.start()t.join()print('thread %s ended.' % threading.current_thread().name)
161. 簡述 GIL
- 預備知識
并行與并發的理解:并發:交替處理多個任務的能力;
并行:同時處理多個任務的能力; 并發的關鍵是你有處理多個任務的能力,不一定要同時。
并行的關鍵是你有同時處理多個任務的能力,強調的是同時.最大的區別:是否是『同時』處理任務。
- GIL(全局解釋器鎖)
通過代碼可以發現多進程可以充分使用cpu的兩個內核而多線程卻不能充分使用cpu的兩個內核 問題:通過驗證我們發現多線程并不能真正的讓多核cpu實現并行。 原因:
cpython解釋器中存在一個GIL(全局解釋器鎖),其作用就是保證同一時刻只有一個線程可以執行代碼,
這造成使用多線程的時候無法實現并行。結論:
1.在處理像科學計算這類需要持續使用cpu的任務的時候單線程會比多線程快,可以使用多進程利用多核的CPU資源。
2.在處理像IO操作等可能引起阻塞的這類任務的時候多線程會比單線程,因為遇到IO阻塞會自動釋放GIL鎖 解決方案法:
1:更換解釋器比如使用jpython(java實現的python解釋器)
2:使用多進程完成多任務的處理
162. 進程之間如何通信
Process之間肯定是需要通信的,操作系統提供了很多機制來實現進程間的通信。Python的multiprocessing模塊包裝了底層的機制,提供了Queue、Pipes等多種方式來交換數據。
from multiprocessing import Process, Queueimport os, time, random# 寫數據進程執行的代碼:def write(q):print('Process to write: %s' % os.getpid())for value in ['A', 'B', 'C']:print('Put %s to queue...' % value)q.put(value)time.sleep(random.random())# 讀數據進程執行的代碼:def read(q):print('Process to read: %s' % os.getpid())while True:value = q.get(True)print('Get %s from queue.' % value)if __name__=='__main__':# 父進程創建Queue,并傳給各個子進程:q = Queue()pw = Process(target=write, args=(q,))pr = Process(target=read, args=(q,))# 啟動子進程pw,寫入:pw.start()# 啟動子進程pr,讀取:pr.start()# 等待pw結束:pw.join()# pr進程里是死循環,無法等待其結束,只能強行終止:pr.terminate()
163.IO 多路復用的作用?
164.select、poll、epoll 模型的區別?
165.什么是并發和并行?
166.一個線程 1 讓線程 2 去調用一個函數怎么實現?
167.解釋什么是異步非阻塞?
168. threading.local 的作用?
內部自動為每個線程維護一個空間(字典),用于當前存取屬于自己的值。保證線程之間的數據隔離。{
線程ID: {...}
線程ID: {...}
線程ID: {...}
線程ID: {...}
}
Git 面試題
169.說說你知道的 git 命令
170.git 如何查看某次提交修改的內容
)
)



)




整合)
)




 小例)

)
