題目描述:
給定一個字符串數組,將字母異位詞組合在一起。字母異位詞指字母相同,但排列不同的字符串。
示例:
輸入: ["eat", "tea", "tan", "ate", "nat", "bat"],
輸出:
[["ate","eat","tea"],["nat","tan"],["bat"]
] 說明:
- 所有輸入均為小寫字母。
- 不考慮答案輸出的順序。
給定一個字符串數組,將字母異位詞組合在一起。字母異位詞指字母相同,但排列不同的字符串。
示例:
輸入:
["eat", "tea", "tan", "ate", "nat", "bat"], 輸出: [["ate","eat","tea"],["nat","tan"],["bat"] ]說明:
- 所有輸入均為小寫字母。
- 不考慮答案輸出的順序。
?
要完成的函數:
vector<vector<string>> groupAnagrams(vector<string>& strs)
?
說明:
1、給定一個vector,里面裝著多個string,要求把這些string進行分組。
兩個字符串擁有相同的字母,就是同一組。(題目說字母相同,順序不同,但測試樣例中出現了字母相同順序也相同的,也在同一組)
字符串只含有小寫字母。
每一組存在一維vector中,所有組存放在二維vector中,最終返回二維vector。
?
2、這道題筆者最開始想用一個雙重循環,外層循環對每個字符串進行迭代,內層循環判斷當前字符串跟前面的字符串,有沒有哪個是相同字母的。
關于內層循環的判斷,筆者最開始想用異或來處理,但后來發現it和ro這四個不同的字母,i^t^r^o的結果為0……
也就是我們不能用異或結果是不是0來判斷字母是不是相同。
異或應該只是適用于只有一個字母不同,而其他字母都相同的情況。
?
那不能用異或,那就用普通的“空間換時間”,我們建立長度為26的vector,在內層循環中判斷兩個字符串是否擁有相同字母。
在對長度為26的vector進行操作前,我們先判斷兩個字符串的長度是否相等,這可以省去很多時間。
代碼如下:(附詳解)
bool judge(string a,string b)//判斷兩個字符串是否擁有相同的字母{vector<int>table(26,0),t1(26,0);for(char i:a)table[i-'a']++;for(char i:b)table[i-'a']--;if(table!=t1)return false;//如果table不是全為0,返回falsereturn true;//否則返回true}vector<vector<string>> groupAnagrams(vector<string>& strs) {vector<vector<string>>res={{strs[0]}};//初始化最終要返回的二維vectorbool flag;for(int i=1;i<strs.size();i++)//循環迭代每個字符串{flag=0;for(int j=0;j<res.size();j++)//對當前的字符串,判斷是否跟前面出現過的字符串,擁有相同字母{if(strs[i].size()!=res[j][0].size())//長度的判斷continue;if(judge(strs[i],res[j][0]))//字母相同的兩個字符串{res[j].push_back(strs[i]);flag=1;break;}}if(flag==0)//前面所有字符串跟當前字符串的字母都不相同{res.push_back({strs[i]});}}return res;//最終返回res}
上述代碼也可以通過測試,但是實測1228ms,beats 2.20% of cpp submissions……太低了
那肯定還有更好的辦法==
?
我們分析一下上述代碼,發現耗費時間的地方在于:
①雙重循環,如果可以改成單重循環就最好了。
②二維vector的不斷申請空間、不斷插入
第二點似乎很難避免,我們要初始化res擁有多長的長度?跟給定的一維vector strs一樣長?那多出來那部分怎么處理……
不斷地pop_back()?這也是一個方法,但看了一下普遍的時間花費是36ms左右,我這樣改可能效果也不會很大……
那第一點要怎么改善?外層循環肯定不可少了,內層循環改成O(1)的時間復雜度?
?
我們想一下,如果是數字串而不是字母串,我們會怎樣判斷當前數字串有沒有出現過?
比如12,32,12,當前數字是第三個數字12,我們可以用vector,前面有了vector[12]=1,vector[32]=1,此時我們再查詢一下當前數字12的對應vector[12],是不是0。
如果是0,那么沒有出現過,如果不是0,那么出現過。
這個時候我們不用一個個地去循環,去遍歷,直接就訪問了。
那可不可以同樣利用這種方法來處理字母串呢?
答案是可以的,我們可以用哈希表。
?
哈希表其實就是數組+鏈表的結構,在c++中,筆者覺得map這種數據結構可能就是實現了哈希表的算法。
哈希表結合了數組的快速訪問、修改和鏈表的無限長度兩個特點,可以參考下面這張圖。
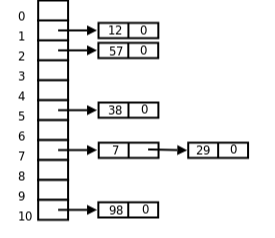
左邊是數組,快速訪問和修改,右邊的鏈表延伸出去,無限長度。
?我們以字母串作為鍵值,像用vector查看數字串一樣去判斷。
?
但有的同學可能有想法,比如“ate”和“eat”這兩個鍵值都不一樣,你怎么判斷?
“ate”和“eat”是不一樣,但它們有共性,那就是擁有的字母相同,我們可以對它們的字母排下序,就可以轉化為相同的鍵值了。
代碼如下:(附詳解)
vector<vector<string>> groupAnagrams(vector<string>& strs) {vector<vector<string>>res;//最終要返回的二維vectorunordered_map<string,int>m1;//定義一個map作為哈希表int index=0;vector<string> strs1=strs;//用于重新排序strs中的每個字符串,strs是原本for(int i=0;i<strs1.size();i++){sort(strs1[i].begin(),strs1[i].end());//對字符串中的字母進行排序if(!m1.count(strs1[i]))//如果之前沒有出現過{m1[strs1[i]]=index;//更新一下index++;//index作為res中的索引res.push_back({strs[i]});//插入一個一維的vector}else//如果有出現過了{res[m1[strs1[i]]].push_back(strs[i]);//res找到對應的索引,插入當前字符串}}return res;//最終返回res}
上述代碼實測28ms,beats 93.68% of cpp submissions。
哈希表其實就是我們平時常用的vector的升級版本,用map實現時,既可以實現快速訪問,又有好的哈希函數,使得空間充足。
神奇神奇~



![[Python] 程序結構與控制流](http://pic.xiahunao.cn/[Python] 程序結構與控制流)


:RecyclerView增刪item)




)

![[Swift]LeetCode916.單詞子集 | Word Subsets](http://pic.xiahunao.cn/[Swift]LeetCode916.單詞子集 | Word Subsets)





