文章目錄
- 一、背景知識
- 1、什么是Map?
- 2、什么是Hash?
- 3、什么是哈希表?
- 4、什么是HashMap?
- 5、如何使用HashMap?
- 6、HashMap有哪些核心參數?
- 7、HashMap與HashTable的對比?
- 8、HashMap和HashSet的區別?
- 9、什么是LinkedHashMap和TreeMap?
- 二、HashMap的實現原理
- 10、HashMap的數據結構?
- 11、HashMap put元素的原理?
- 12、HashMap get元素的原理?
- 三、紅黑樹
- 13、為什么要將鏈表轉化為紅黑樹?
- 14、鏈表元素超過8轉化為紅黑樹,那為什么不是紅黑樹元素小于等于8轉化為鏈表,而是小于等于6?
- 15、鏈表元素超過8是否一定轉化為紅黑樹?
- 三、hash計算和index計算
- 16、HashMap如何計算K的hash值?
- 17、為什么不用K的hashCode值直接作為hash值,而是將hashCode值進行無符號右移16位,再異或的復雜操作?
- 18、HashMap如何計算K的數組下標?
- 四、HashMap的擴容
- 19、HashMap什么時候擴容?
- 20、為什么HashMap的容量必須是2的冪?
- 21、JDK7如何實現HashMap的擴容?
- 22、1.7為什么采用頭插法?
- 23、頭插法為什么會造成HashMap的死循環?
- 24、JDK8做了哪些改進,避免死循環?
- 25、JDK8擴容的優化點?
- 26、HashMap線程安全嗎?
- 27、什么是ConcurrentHashMap?
- 28、ConcurrentHashMap JDK7的實現原理?
- 29、ConcurrentHashMap JDK8的實現原理?
- 30、JDK8對HashMap做了哪些優化?
一、背景知識
面試過程中面試官的死亡連:你說你看過很多源碼是嗎?那你說說hashmap的底層實現?什么條件下會自動擴容的?為什么要有 紅黑樹?什么條件下會有?擴容因子為什么是0.75有研究過嗎? 下來就來徹底了解一下HashMap吧!
1、什么是Map?
Map是一種集合接口,提供了一系列操作K-V的方法,HashMap、HashTable都是Map接口的實現類。
2、什么是Hash?
Hash 音譯為 “哈希” ,也叫 “散列” 。
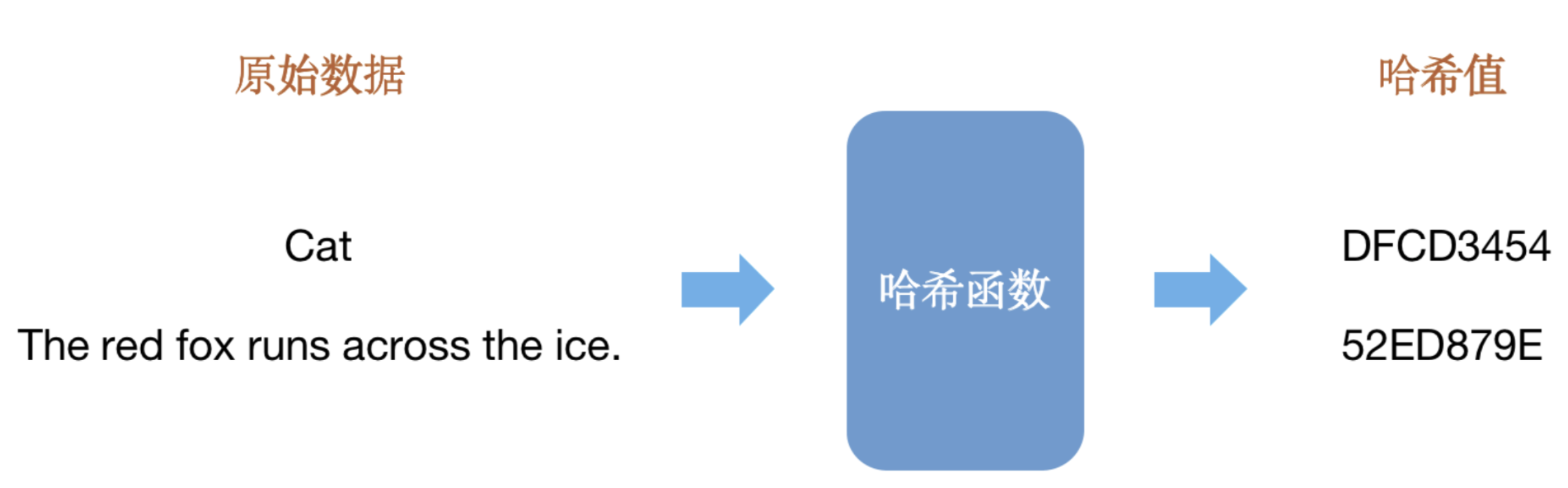
哈希的本質是通過哈希函數對原始數據進行有損壓縮,得到固定長度的輸出,即哈希值,通過哈希值唯一標識原始數據。
若不同的原始數據被有損壓縮后產生了相同的結果,該現象稱為哈希碰撞。
3、什么是哈希表?
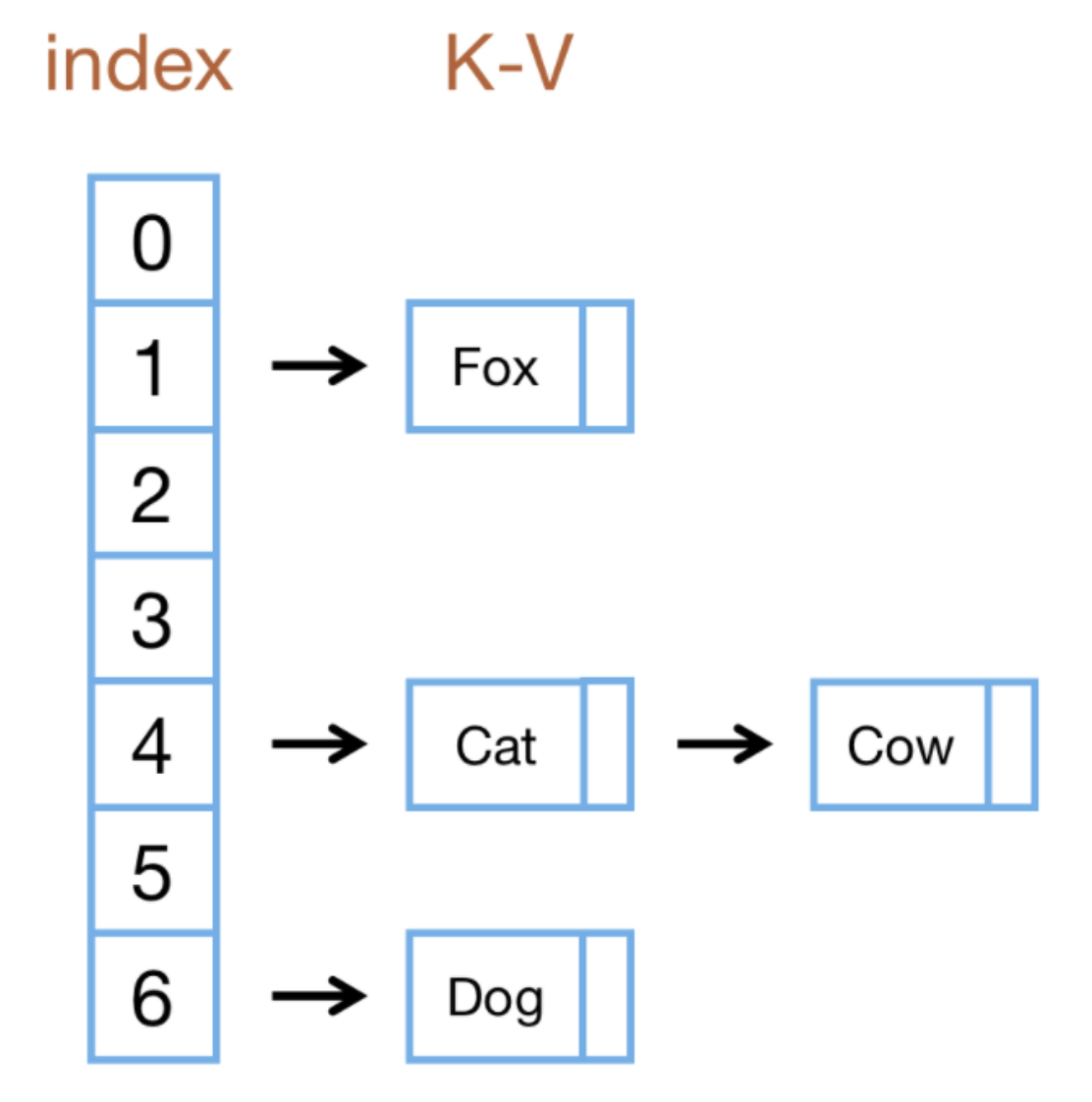
哈希表是一種數據結構,它可以提供較高的存取效率。
【原理】
1、向哈希表插入元素時,會先根據哈希函數計算K對應的存儲位置,再put元素;
2、查詢時,根據哈希函數計算K對應的存儲位置,直接訪存儲位置獲取元素,查詢效率高。
【基本概念】
4、什么是HashMap?
HashMap繼承了AbstractMap類,是Map接口的一種實現,用于存儲K-V數據結構的元素,底層通過哈希表實現了較快的存取效率。
5、如何使用HashMap?
Map map = new HashMap(); // 創建HashMap對象
map.put("數學", 91 ); // 存放元素
map.put("語文", 92 ); // 存放元素
map.put("物理", 94 ); // 存放元素
int score = map.get("語文"); // 獲取元素值
for(Object key : map.keySet()) { // 遍歷元素System.out.println("科目"key + "的成績是" + map.get(key));
}
map.remove("物理"); // 刪除元素
6、HashMap有哪些核心參數?
1、默認初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16
2、最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
3、默認負載因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4、樹形化閾值
static final int TREEIFY_THRESHOLD = 8;
5、解樹形化閾值
static final int UNTREEIFY_THRESHOLD = 6;
7、HashMap與HashTable的對比?
【相同點】
都用于存儲K-V元素
【不同點】
- HashMap可接受null鍵值和值,Hashtable則不能;
- HashMap線程不安全,HashTable線程安全,方法都加了synchronized;
- HashMap繼承AbstractMap類,HashTable繼承Dictionary類;
- HashMap的迭代器(Iterator)是fail-fast迭代器,HashTable的enumerator迭代器不是fail-fast,所以遍歷時如果有線程改變了HashMap(增加或者移除元素),將會拋出
ConcurrentModificationException。- HashMap默認容量16,擴容為old2;HashTable默認容量11,擴容為old2+1。
8、HashMap和HashSet的區別?
HashSet實現Set接口,不允許集合中有重復值;HashMap實現Map接口,存儲鍵值對,K不允許重復。
9、什么是LinkedHashMap和TreeMap?
LinkedHashMap內部維護一個鏈表,存儲了K的插入順序,迭代時按照插入順序迭代。
TreeMap底層是一顆紅黑樹,containsKey、get、put、remove方法的時間復雜度都是
log(n),按K的自然順序排列(如整數的從小到大),也可指定Comparator比較函數。
二、HashMap的實現原理
10、HashMap的數據結構?
JDK1.7及之前,HashMap的內部數據結構是數組+鏈表。
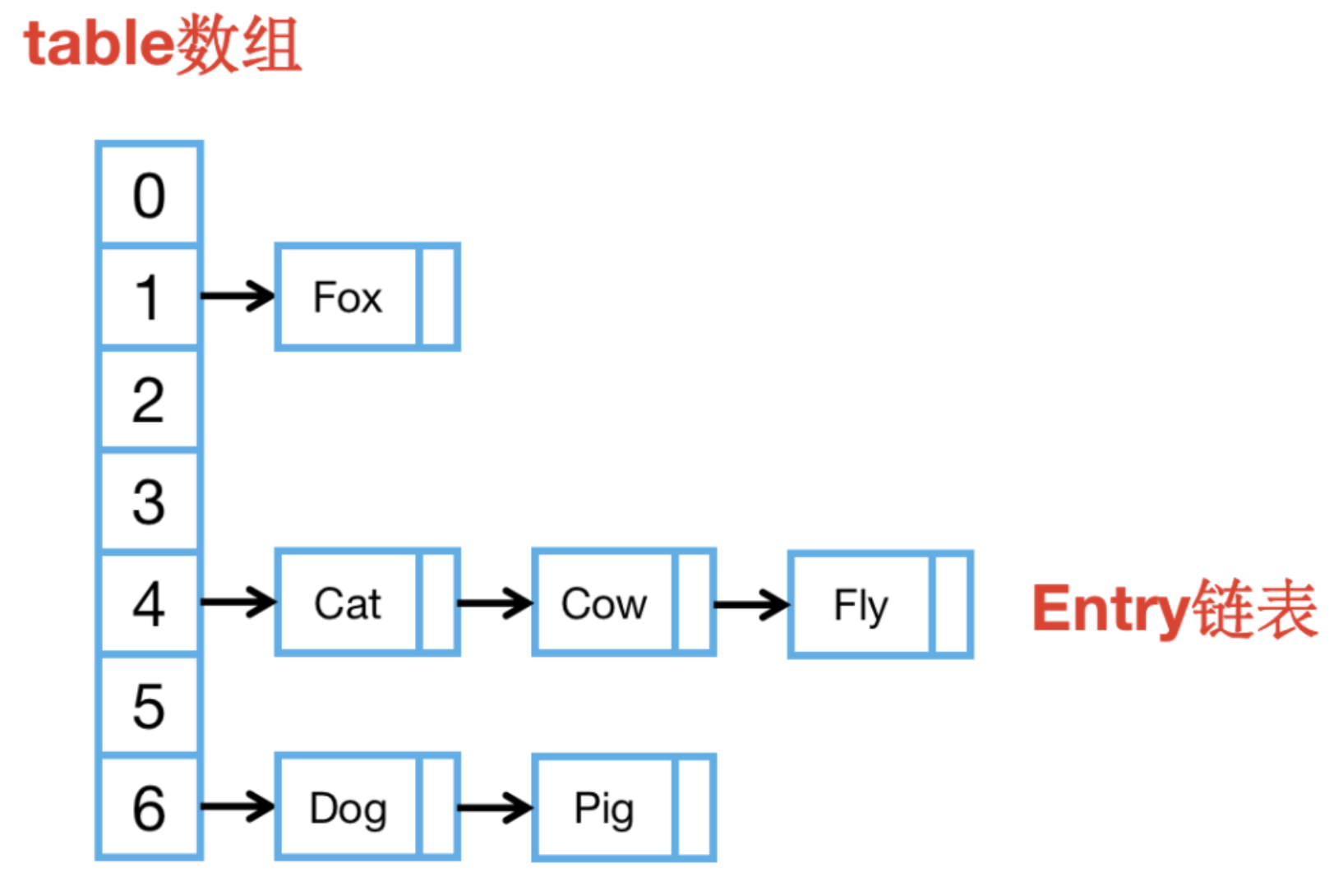
JDK1.8開始,當鏈表長度 > 8時會轉化為紅黑樹,當紅黑樹元素個數 ≤ 6時會轉化為鏈表。
11、HashMap put元素的原理?

12、HashMap get元素的原理?

三、紅黑樹
13、為什么要將鏈表轉化為紅黑樹?
鏈表長度太長時,紅黑樹的存取效率比鏈表高。
14、鏈表元素超過8轉化為紅黑樹,那為什么不是紅黑樹元素小于等于8轉化為鏈表,而是小于等于6?
如果鏈表和紅黑樹互相轉換的閾值固定是8,當HashMap元素個數在8左右變更時,
會導致樹和鏈表數據結構的頻繁變更,降低性能,所以中間預留buffer。
15、鏈表元素超過8是否一定轉化為紅黑樹?
鏈表長度大于8 && 數組長度大于64,才會樹形化,否則只是resize擴容。
為什么呢?因為數組小而鏈表長的場景,將鏈表轉換為樹治標不治本,應優先擴容數組。
三、hash計算和index計算
16、HashMap如何計算K的hash值?
hash值 = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
17、為什么不用K的hashCode值直接作為hash值,而是將hashCode值進行無符號右移16位,再異或的復雜操作?
Object的hashCode()函數返回的值是int型,值范圍從-2147483648到2147483648,轉化為2進制有32位,如、1011000110101110011111010011011。
使用右移、異或的操作,可以充分利用K的hashCode值高低位不同的特性,以減少hash碰撞的可能,提升查詢效率。
18、HashMap如何計算K的數組下標?
index = h & (length-1)
四、HashMap的擴容
19、HashMap什么時候擴容?
- 當元素數量超過閾值時擴容,閾值 = 數組容量 * 加載因子。
- 數組容量默認16,加載因子默認0.75,所以默認閾值12。
- 容量上限為1 << 30
20、為什么HashMap的容量必須是2的冪?
index = h & (length-1),2的冪次方-1都是1,可以充分利用高低位特點,減少hash沖突。
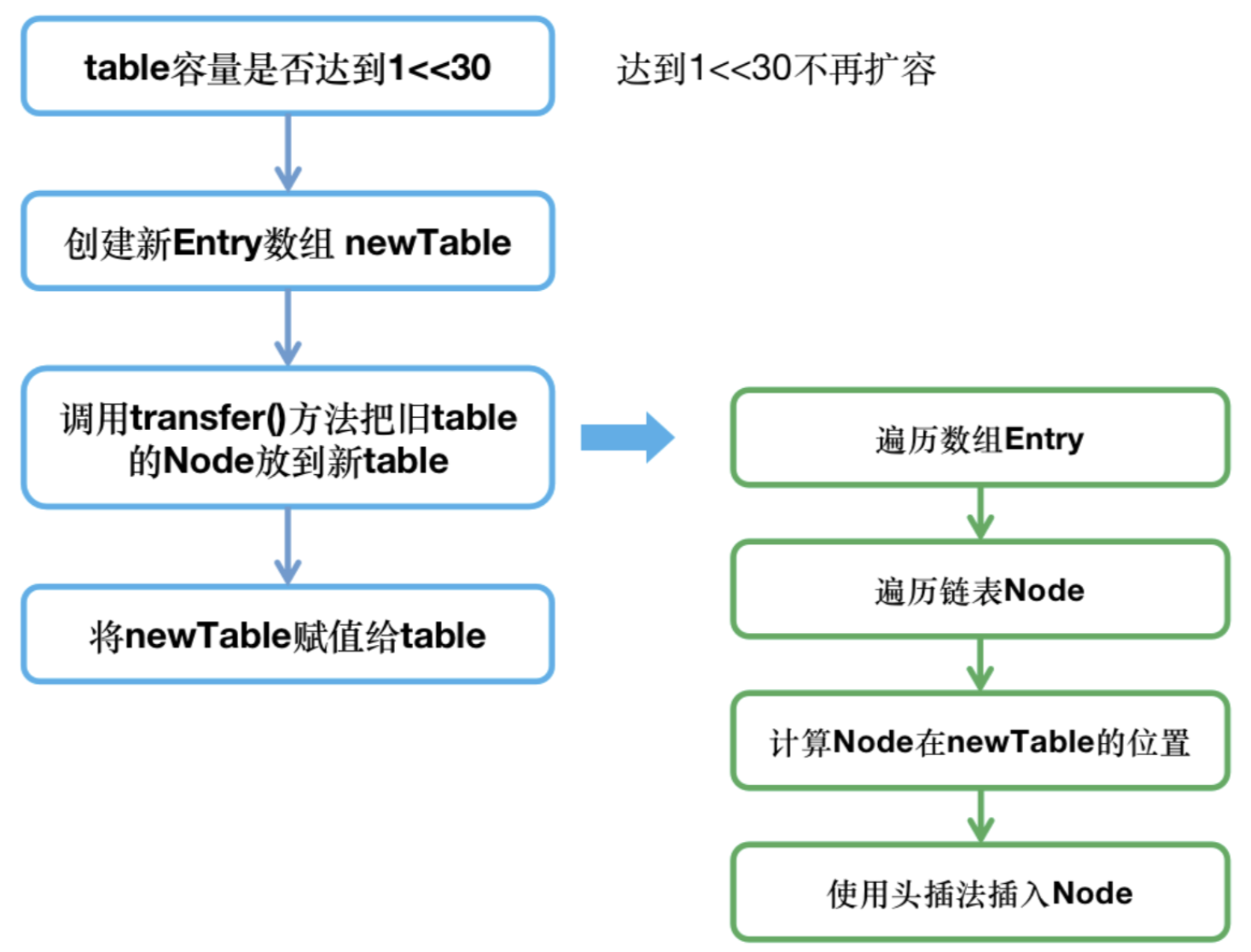
21、JDK7如何實現HashMap的擴容?
源碼、
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];transfer(newTable, initHashSeedAsNeeded(newCapacity));table = newTable;threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}
}
不想看源碼 ?直接看我整理的簡單流程圖
22、1.7為什么采用頭插法?
剛添加的元素,被訪的概率大。
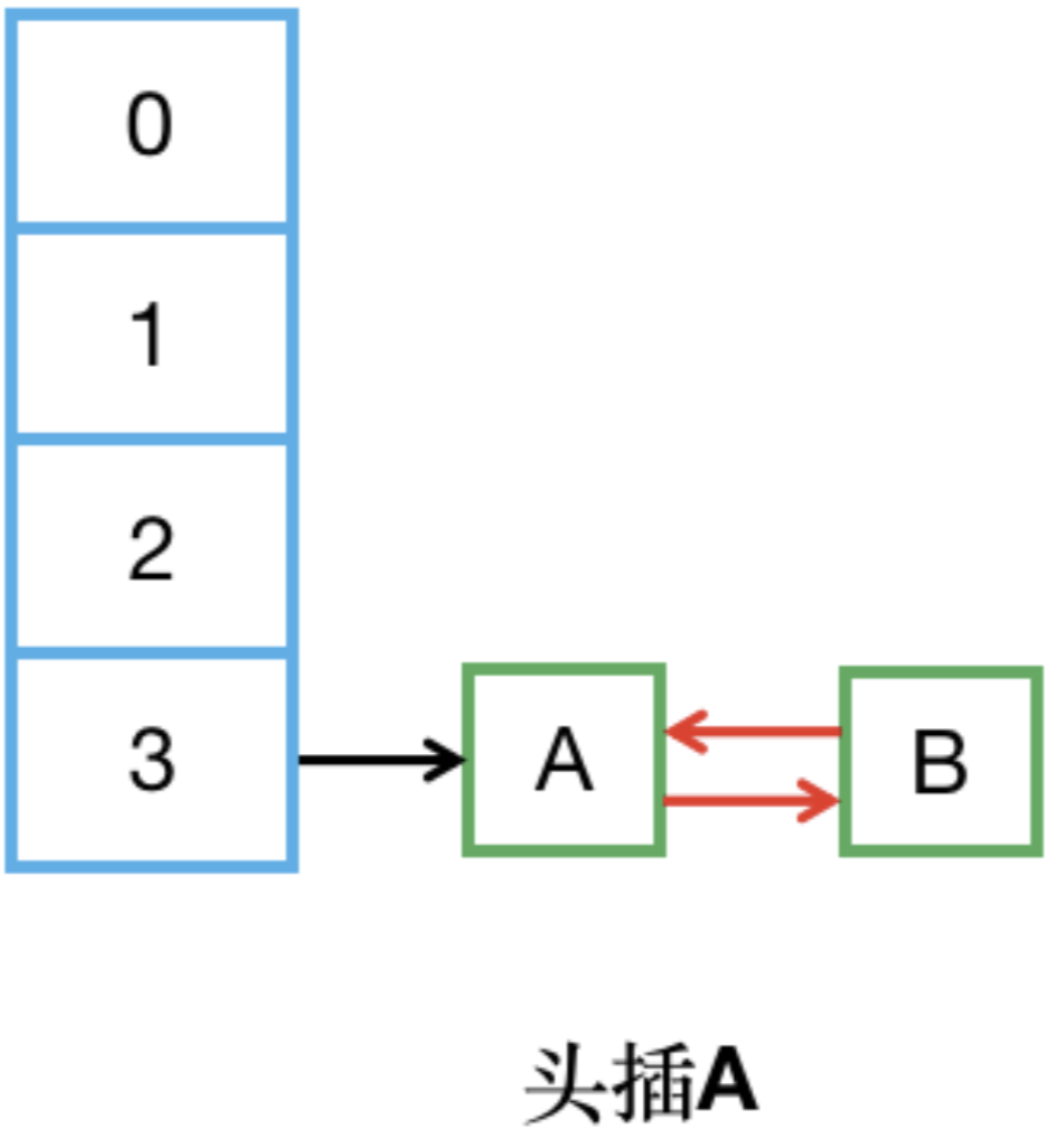
23、頭插法為什么會造成HashMap的死循環?
【step1】現有HashMap,table大小為2,里面有3個元素在index1處。
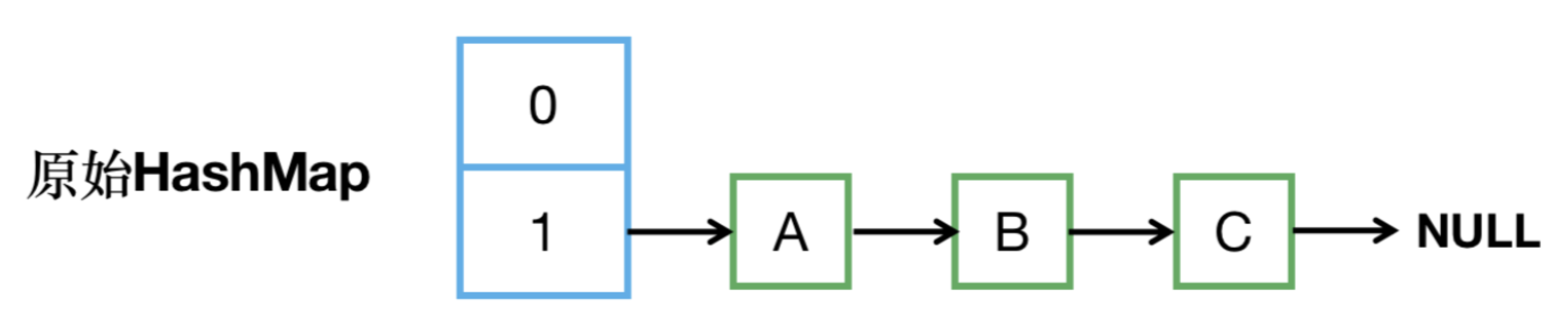
【step2】有2個線程同時觸發了擴容,但線程2剛啟動擴容就被掛起,此時線程2內e指向了key(A),其next指向了key(B),而線程1完成了擴容。
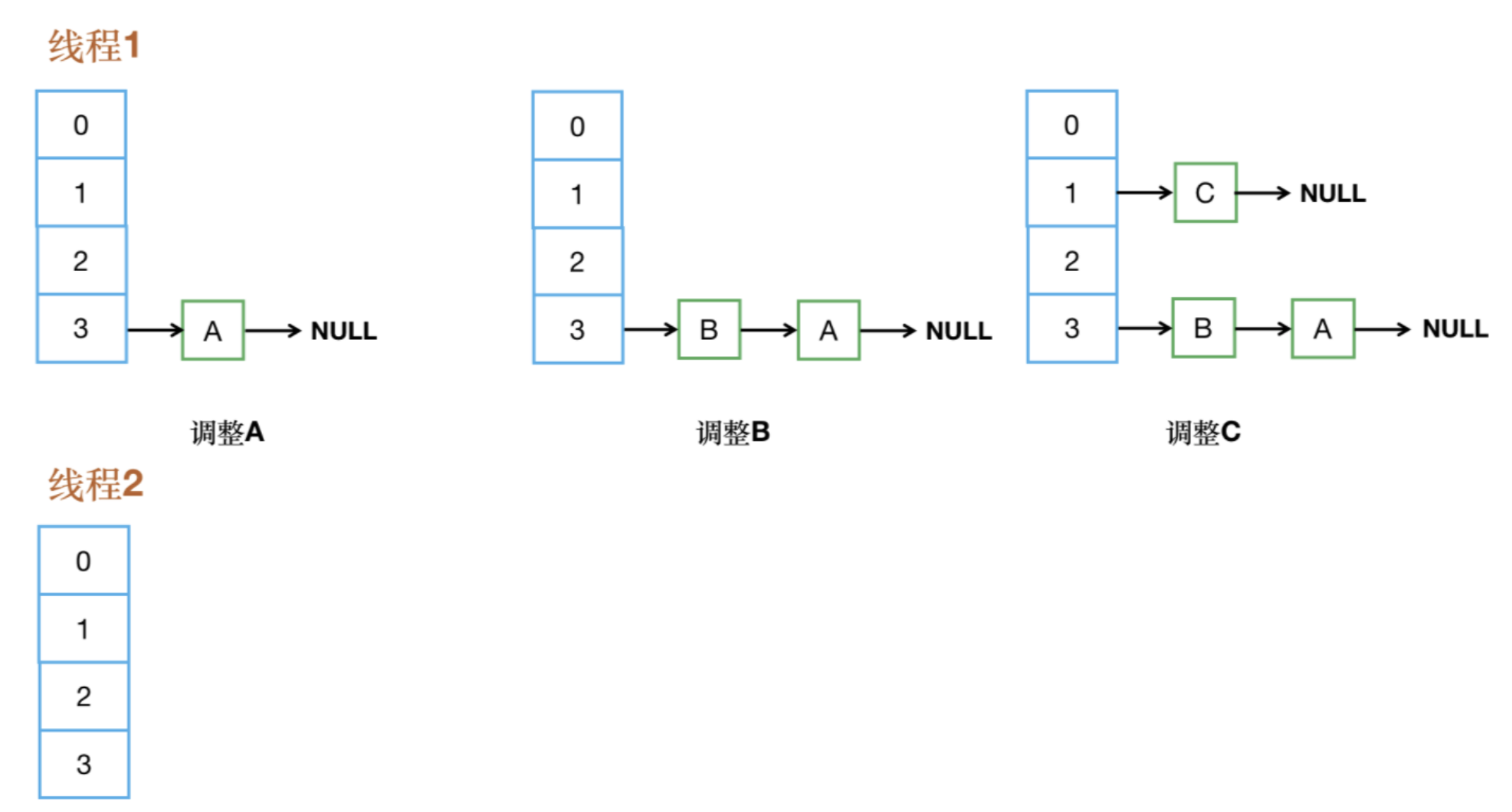
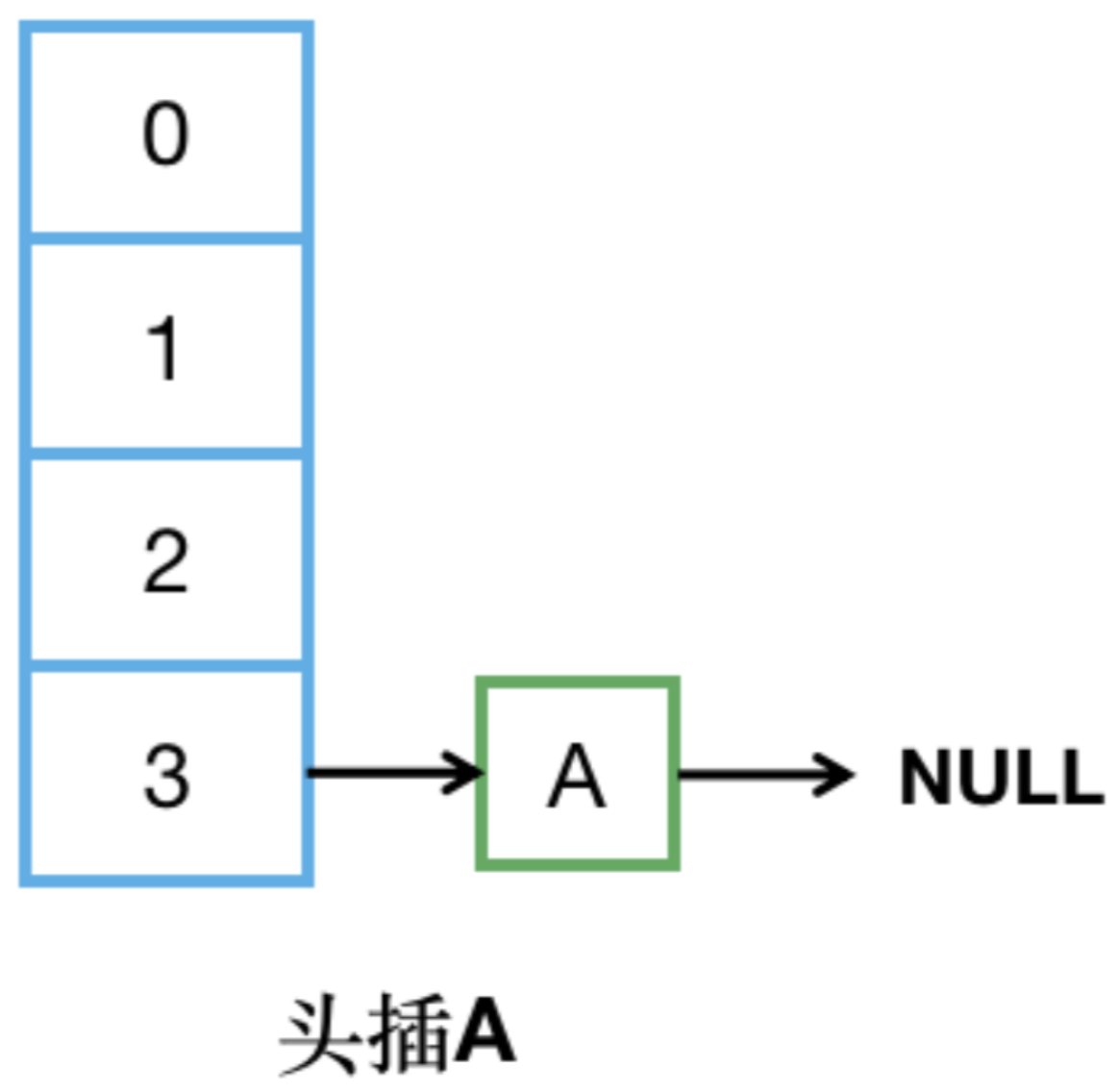
【step3】線程2被調度回來,線程2內當前待調整元素e指向A,所以頭插A。此時e.next=B,待調整B。
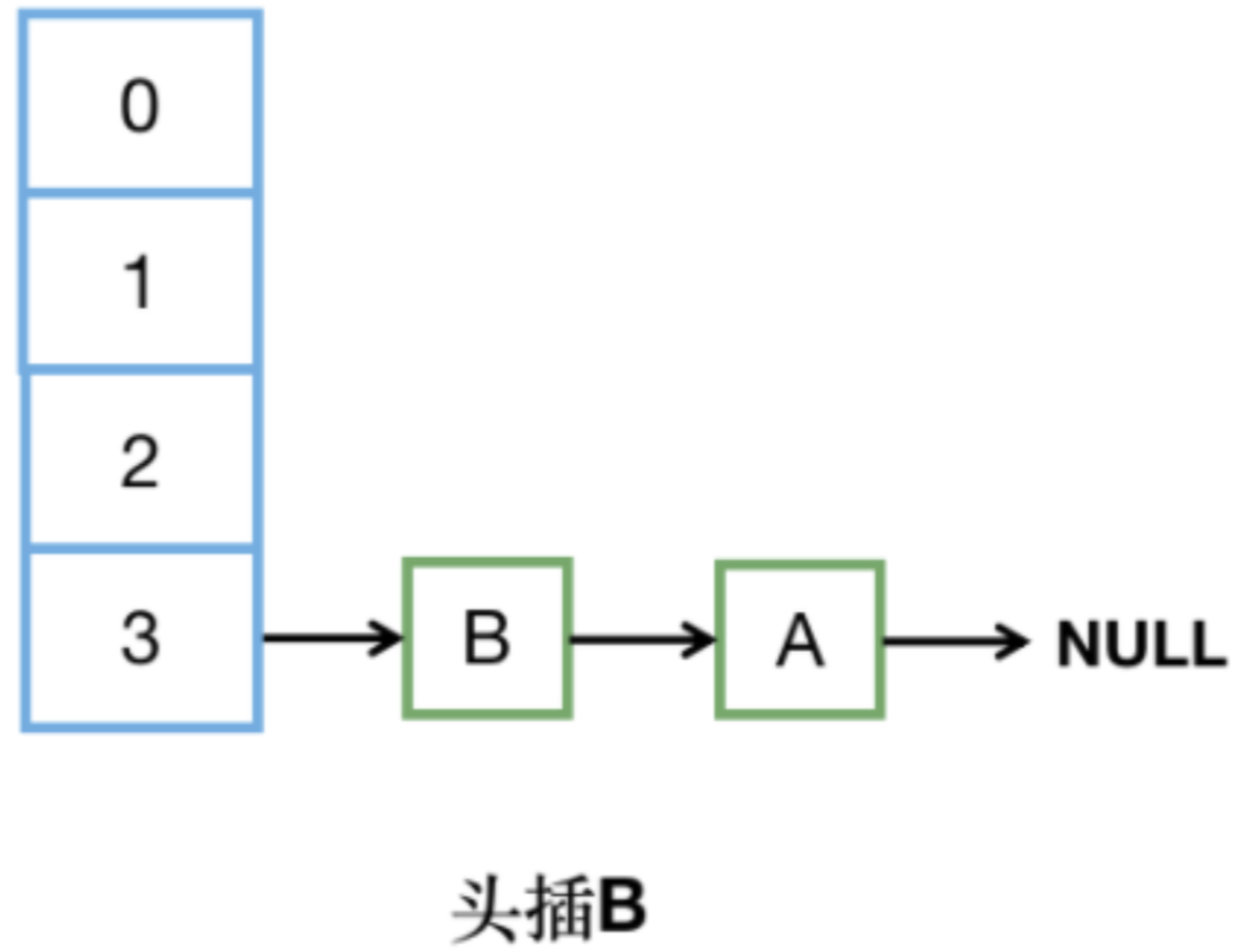
【step4】e = next指向B,所以頭插B,此時e.next = table[i] ,本來應該指向C,但由于線程1已經完成了擴容,所以又指向了A。
【step5】頭插A,形成環。
24、JDK8做了哪些改進,避免死循環?
1、鏈表太長轉換為紅黑樹,減少死循環發生的可能;
2、1.8使用尾插法,在擴容時會保持鏈表元素原來的順序,解決了死循環題,但解決不了線程不安全題。
25、JDK8擴容的優化點?
1、頭插法改為尾插法,解決鏈表死循環題。
2、擴容的效率更高
擴容前index = hash&(oldTable.length-1),
擴容后index = hash&(oldTable.length*2-1)唯一的區別是 length -1,多了一個高位1參與運算,如果hash對應的位置是0,則Node的index沒變,如果hash對應位置是1,則newIndex =oldIndex + oldLength。
即得出結論、擴容后,Node的位置要么不變,要么移動odLength。
因此,在擴容時,不需要重新計算元素的hash了,只需要通過 if ((e.hash & oldCap) == 0)
判斷最高位是1還是0就可以確定index,效率更高。
【線程安全】
26、HashMap線程安全嗎?
HashMap非線程安全,線程安全的Map可以使用ConcurrentHashmap。
27、什么是ConcurrentHashMap?
HashMap線程不安全,多線程環境可以使用Collections.synchronizedMap、HashTable實現線程安全,但性能不佳。
ConurrentHashMap比較適合高并發場景使用。
28、ConcurrentHashMap JDK7的實現原理?
1、數據結構、Segment數組+HashEntry鏈表數組
ConcurrentHashMap由一個Segment數組構成(默認長度16),Segment繼承自ReentrantLock,所以加鎖時Segment數組元素之間相互不影響,所以可實現分段加鎖,性能高。
Segment本身是一個HashEntry鏈表數組,所以每個Segment相當于是一個HashMap
。
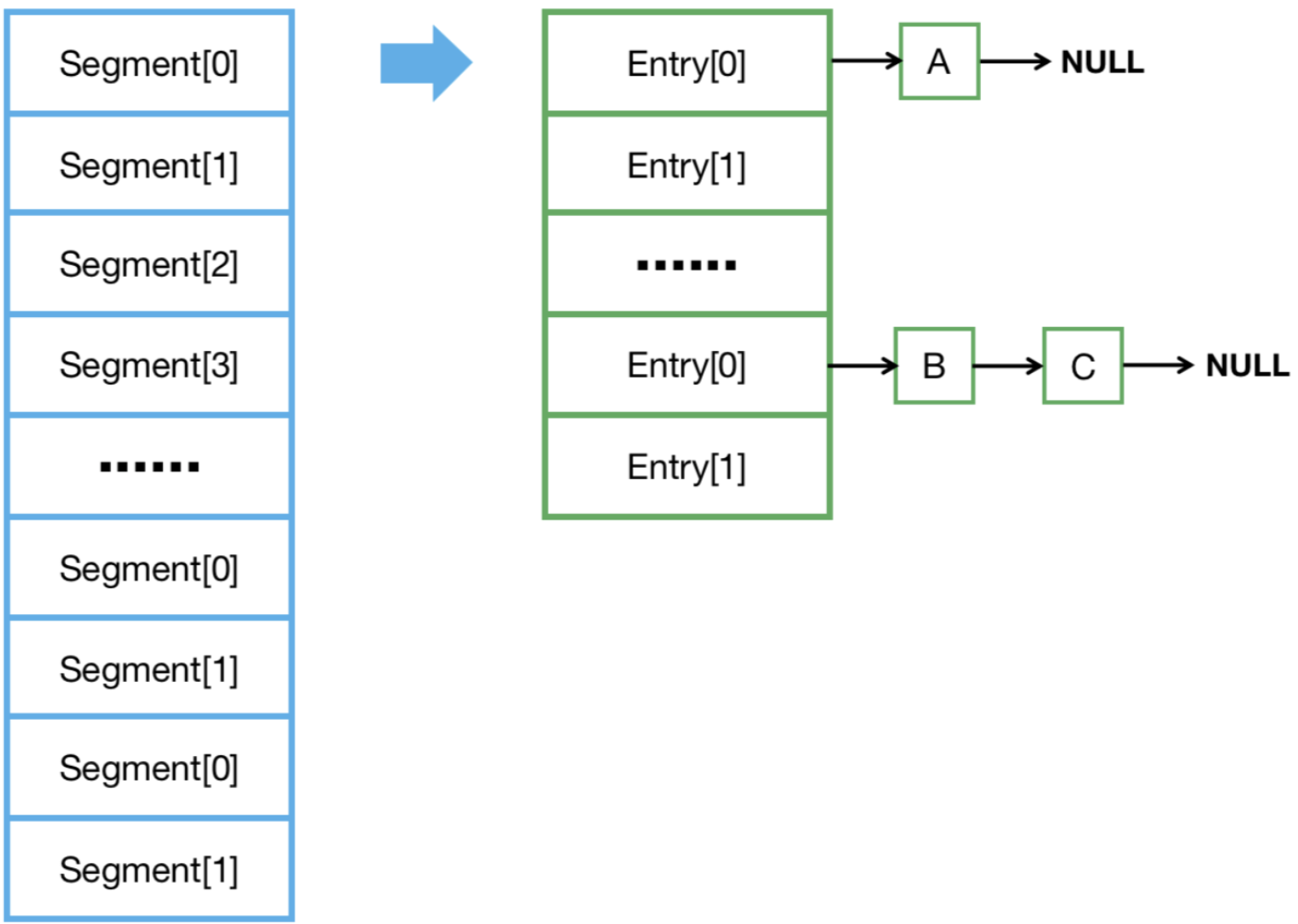
2、put元素原理

3、get元素原理
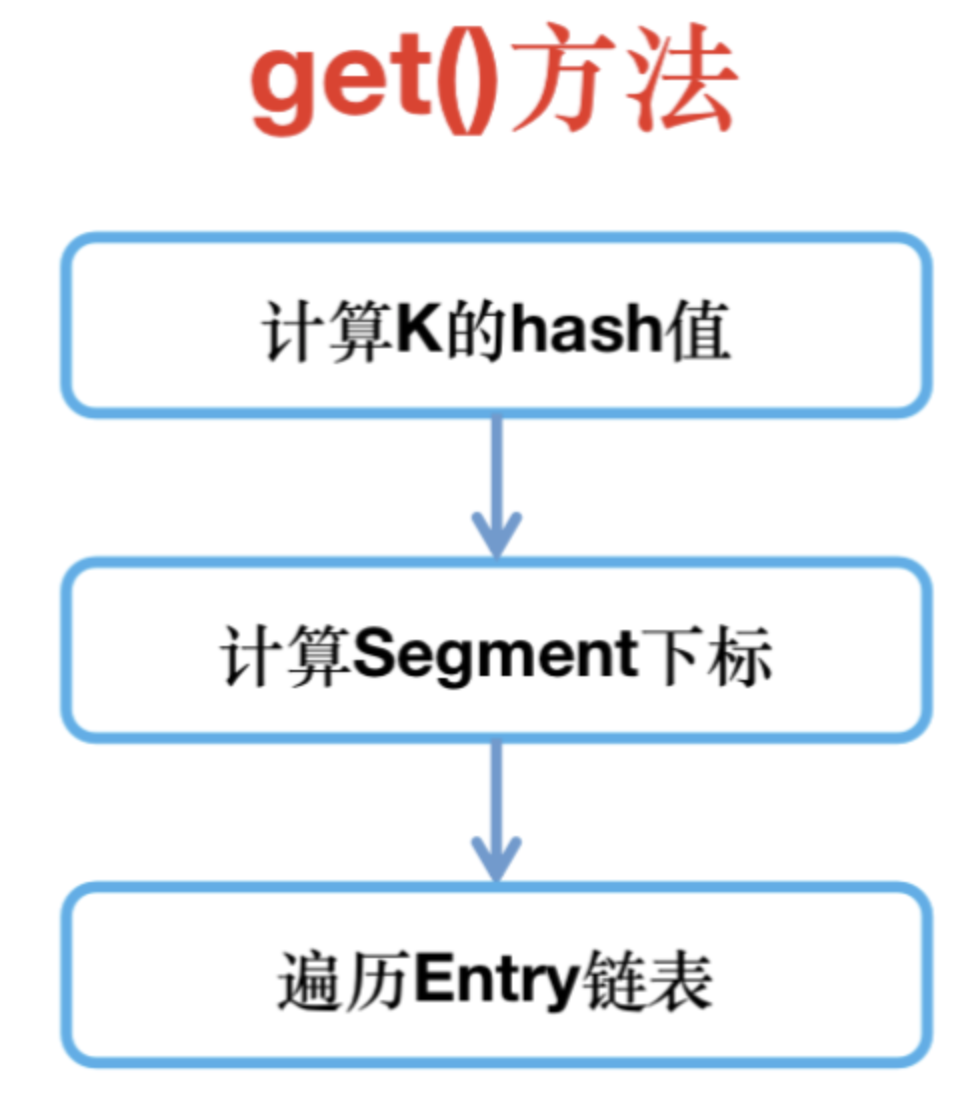
get()操作不需要加鎖,是因為HashEntry的元素val和指針next都使用volatile修飾,在多線程環境下,線程A修改Node的val或新增節點時,對線程B都是可見的。
29、ConcurrentHashMap JDK8的實現原理?
1、數據結構、Node數組+鏈表/紅黑樹,類似1.8的HashMap。
摒棄Segment,使用Node數組+鏈表+紅黑樹的數據結構。
桶中的結構可能是鏈表,也可能是紅黑樹,紅黑樹是為了提高查找效率。
并發控制使用Synchronized和CAS來操作,整體看起來像是線程安全的JDK8 HashMap。
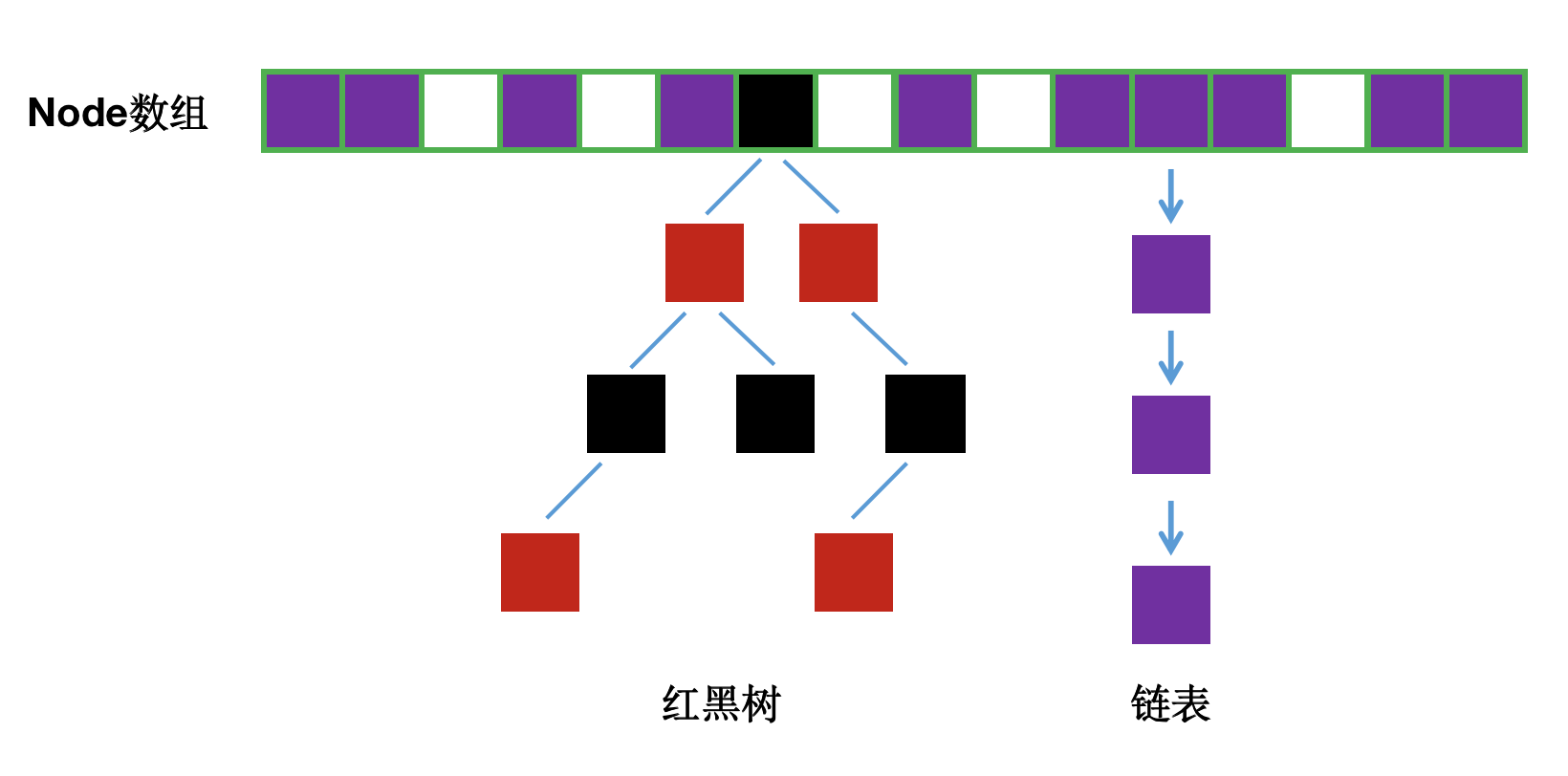
2、存放元素原理
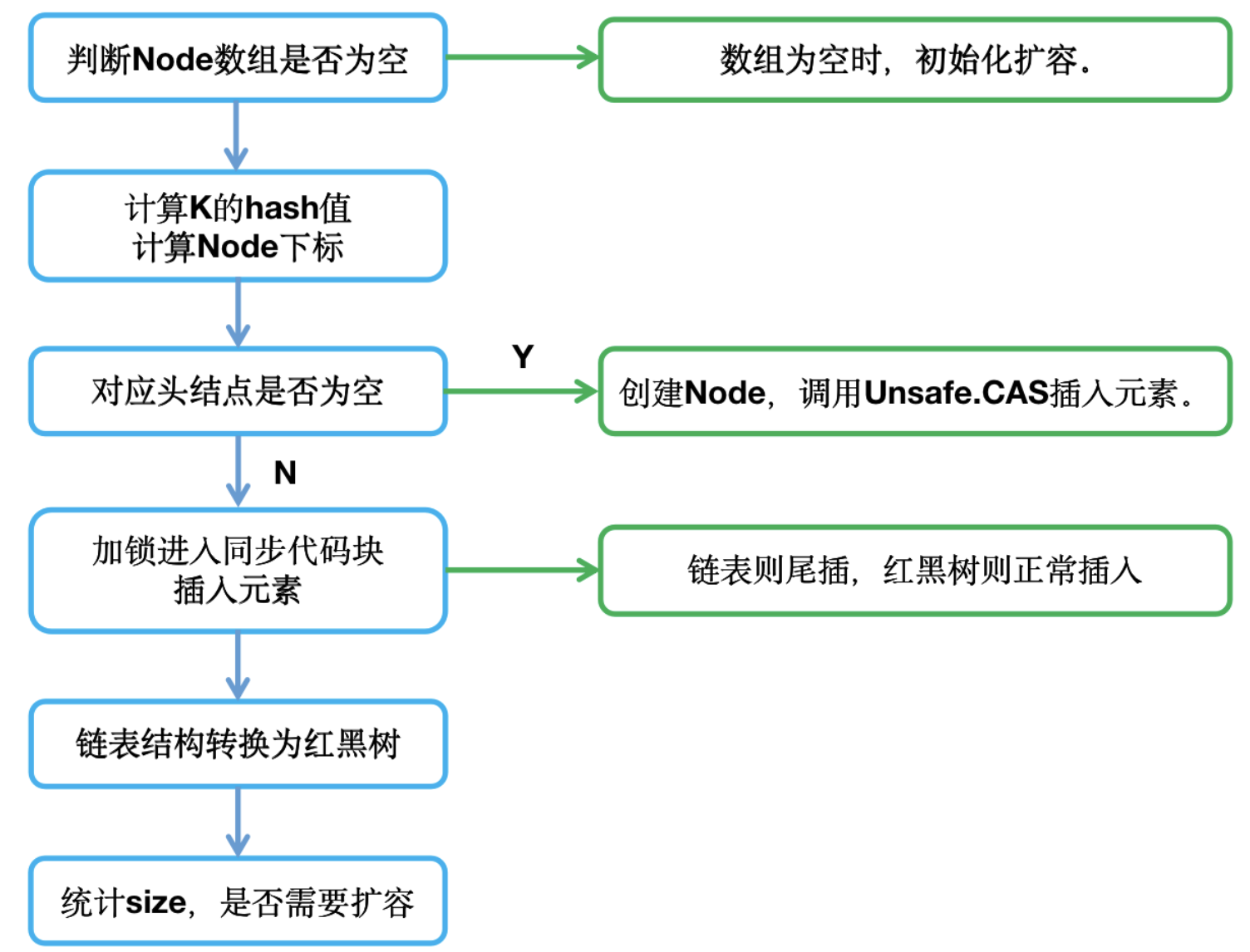
3、獲取元素原理
計算hash - 計算數組下標 - 遍歷節點
30、JDK8對HashMap做了哪些優化?
1、引入紅黑樹 ,提升元素獲取速度。
2、頭插法改為尾插法,解決鏈表死循環題。
3、擴容的效率更高













![P3193 [HNOI2008]GT考試](http://pic.xiahunao.cn/P3193 [HNOI2008]GT考試)



)
)
![[算法]不使用*、/、+、-、%操作符求一個數的1/3](http://pic.xiahunao.cn/[算法]不使用*、/、+、-、%操作符求一個數的1/3)