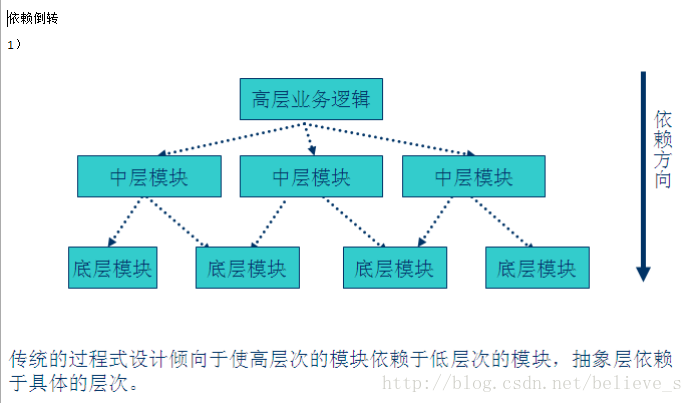
在傳統的過程式中,上層依賴于底層,當底層變化,上層也得跟著做出相應的變化。這就是面向過程的思想,弊端就是導致程序的復用性降低并且提高了開發的成本。
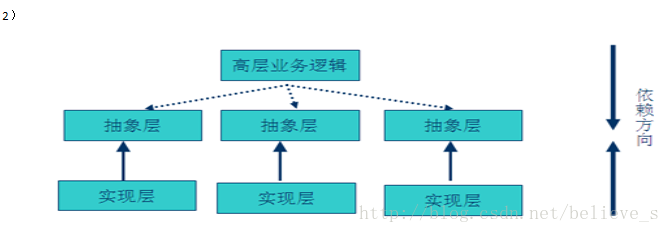
而面向對象的開發則很好的解決了這個問題,讓用戶程序依賴于抽象層,實現層也依賴于抽象層,而抽象層一般不會輕易變化。即使實現變化,只要抽象不變,客戶程序就不用變化,這大大降低了客戶程序與實現細節的耦合度。
就好比實例中電腦由硬盤、CPU、內存組成,而這些硬件又有很多種類和品牌,組裝電腦時,我們只管裝抽象的硬件如硬盤而不管具體是什么牌子的硬盤,這要即使你硬盤的品牌變化了,也不會影響將硬盤這種硬件裝進電腦中。這里硬盤就是一個抽象類,如果沒有這個抽象層,直接將電腦和具體的硬盤品牌或者類型進行連接,一旦你換成其他類型或者品牌的硬盤,你電腦的接口也得相應調整,增加了成本。
依賴倒置原則實例:
#include <iostream>// 硬盤的抽象類
class HardDisk
{
public:virtual void work() = 0;
};// 三星
class SanHardDisk : public HardDisk
{
public:void work(){printf ("三星硬盤正常工作....\n");}
};// CPU的抽象類
class CPU
{
public:virtual void work() = 0;
};//因特爾
class IntelCPU : public CPU
{
public:void work(){printf ("Intel CPU正常工作....\n");}
};// 內存的抽象類
class Memory
{
public:virtual void work() = 0;
};//金士頓
class JsdMemory : public Memory
{
public:void work(){printf ("金士頓 內存正常工作....\n");}
};class Computer
{
public:Computer(HardDisk *hd, CPU *cpu, Memory *my) // 組裝電腦{this->hd = hd; // 組裝硬盤this->cpu = cpu; // 組裝CPUthis->my = my; // 組裝內存}void work(){hd->work(); // 硬盤正常工作cpu->work(); // CPU正常工作my->work(); // 內存正常工作}
private:// 要有硬盤HardDisk *hd;// 要有CPUCPU *cpu;// 要有內存Memory *my;
};int main()
{HardDisk *hd = NULL;CPU *cpu = NULL;Memory *my = NULL; // 生產一個電腦,定義一個電腦的對象hd = new SanHardDisk;cpu = new IntelCPU;my = new JsdMemory;Computer cp(hd, cpu, my);// Computer cp(new SanHardDisk, new IntelCPU, new JsdMemory);cp.work();delete hd;delete cpu;delete my;return 0;
}class A
{
public:void func();// 增加新功能void func2();
};// 通過繼承增加新功能
class B: public A
{
public:void func2();
};// 通過組合的辦法
class C
{
public:void func(){a->func();// 增加新功能}
private:A *a;
};



![[轉載]基于Aaf的數據拆分](http://pic.xiahunao.cn/[轉載]基于Aaf的數據拆分)



)
)

)

)
![第一節 接口概述 [轉貼]](http://pic.xiahunao.cn/第一節 接口概述 [轉貼])




