文章目錄
- 目錄
- 1.分布式文件系統
- 1.1 計算機集群概念
- 1.2 分布式文件系統結構
- 2.HDFS簡介
- 2.1 HDFS設計的目標
- 2.2HDFS的局限性
- 2.3 塊的概念
- 2.4 HDFS主要組件及其功能
- 2.4.1 名稱節點
- 2.4.2 第二名稱節點
- 2.4.3 數據節點
- 3.HDFS體系結構
- 3.1 HDFS體系結構介紹
- 3.2 HDFS體系結構的局限性
- 4.HDFS存儲原理
- 4.1 冗余數據保存
- 4.2 數據存取策略
- 4.3 數據錯誤和恢復
- 4.3.1 名稱節點出錯
- 4.3.2 數據節點出錯
- 4.3.3 數據出錯
- 5.HDFS數據讀寫過程
- 5.1 數據讀取過程
- 5.2 數據存儲過程
- 5.3 讀寫介紹
- 5.3.1 讀數據過程
- 5.3.2 寫數據過程
- 6.HDFS編程實踐
- 6.1 HDFS常用命令
- 6.2 HDFS的web界面
目錄
1.分布式文件系統
1.1 計算機集群概念
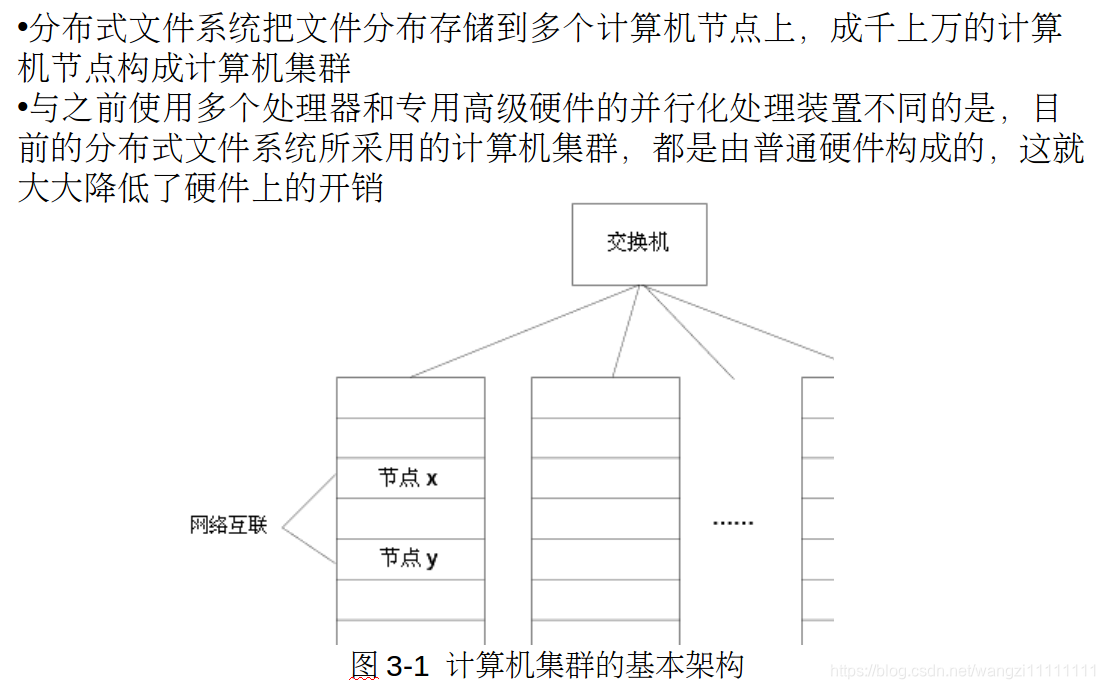
Hadoop的分布式文件存儲,使得文件的存儲不在依賴于計算機性能,普通的計算機也可以組件集群。
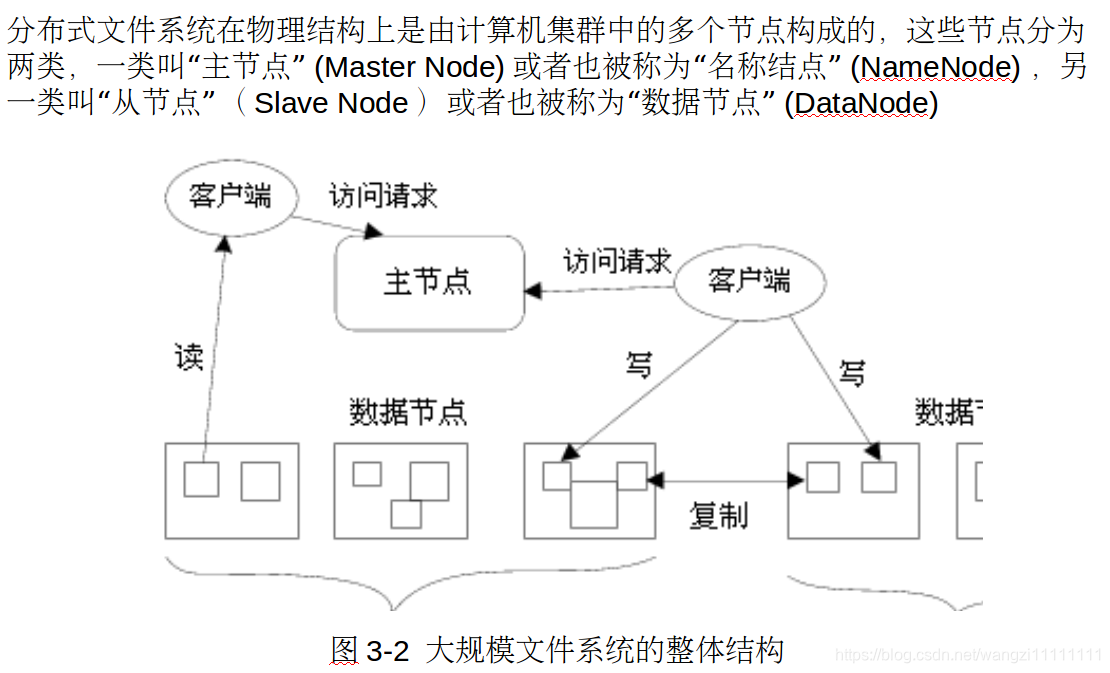
1.2 分布式文件系統結構
2.HDFS簡介
2.1 HDFS設計的目標
- 兼容廉價的硬件設備
- 流數據的讀寫
- 大數據集的存儲于管理
- 簡單的文件模型
- 強大的跨平臺性能
2.2HDFS的局限性
- 不適合低延遲的數據訪問(HBASE支持實時訪問)
- 無法高效的存儲大量的小文件(nameNode節點的存儲有限,如果小文件過多,元數據就多)
- 不支持多用戶寫入及任意修改
2.3 塊的概念

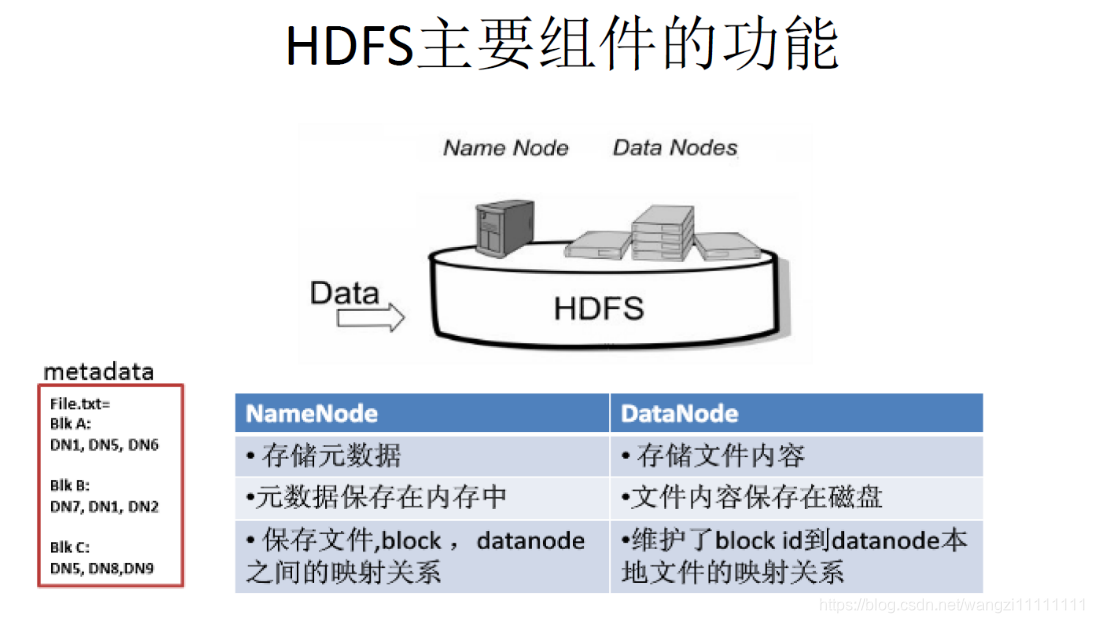
2.4 HDFS主要組件及其功能
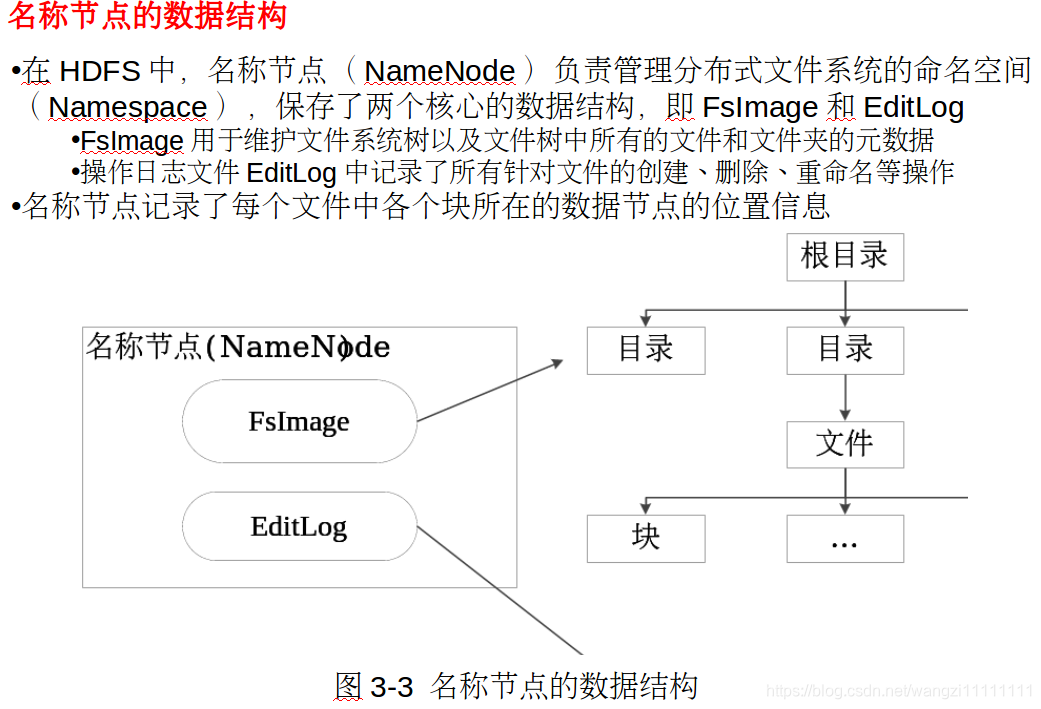
2.4.1 名稱節點



2.4.2 第二名稱節點
2.4.3 數據節點
- 數據節點是分布式文件系統HDFS的工作節點,負責數據的存儲和讀取,會根據客戶端或者是名稱節點的調度來進行數據的存儲和檢索,并且向名稱節點定期發送自己所存儲的塊的列表
- 每個數據節點中的數據會被保存在各自節點的本地Linux文件系統中
3.HDFS體系結構
3.1 HDFS體系結構介紹
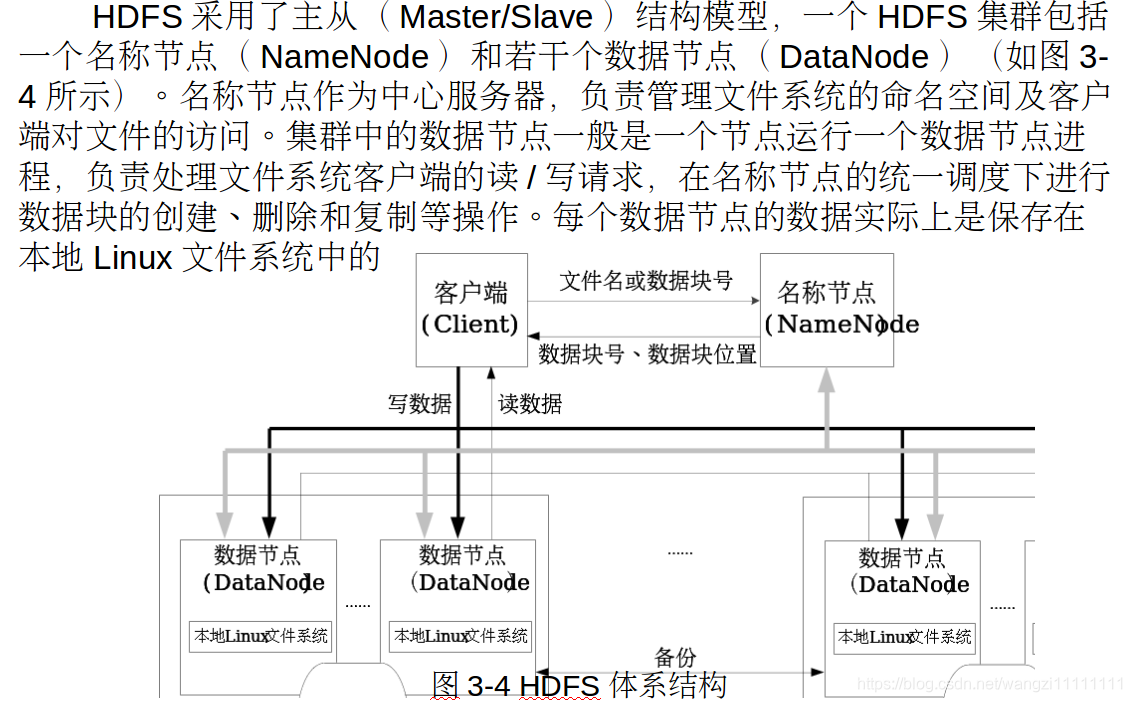
- HDFS的命名空間包含目錄、文件和塊
- 在HDFS1.0體系結構中,在整個HDFS集群中只有一個命名空間,并且只有唯一一個名稱節點,該節點負責對這個命名空間進行管理
- HDFS使用的是傳統的分級文件體系,因此,用戶可以像使用普通文件系統一樣,創建、刪除目錄和文件,在目錄間轉移文件,重命名文件等


3.2 HDFS體系結構的局限性

4.HDFS存儲原理
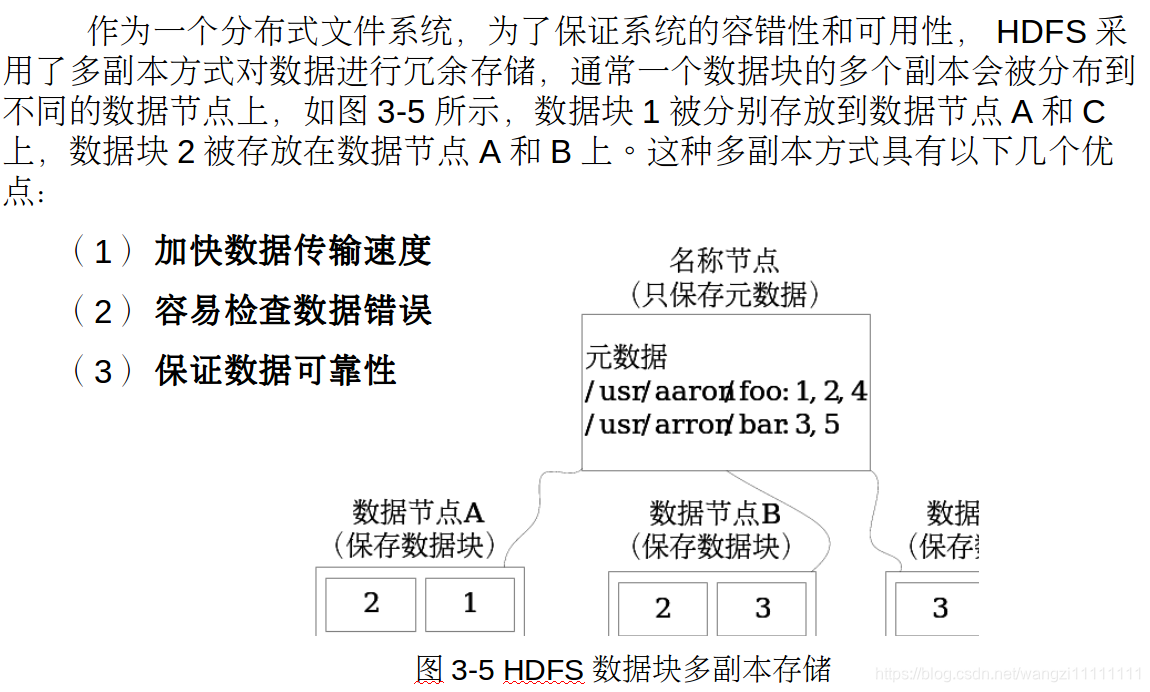
4.1 冗余數據保存
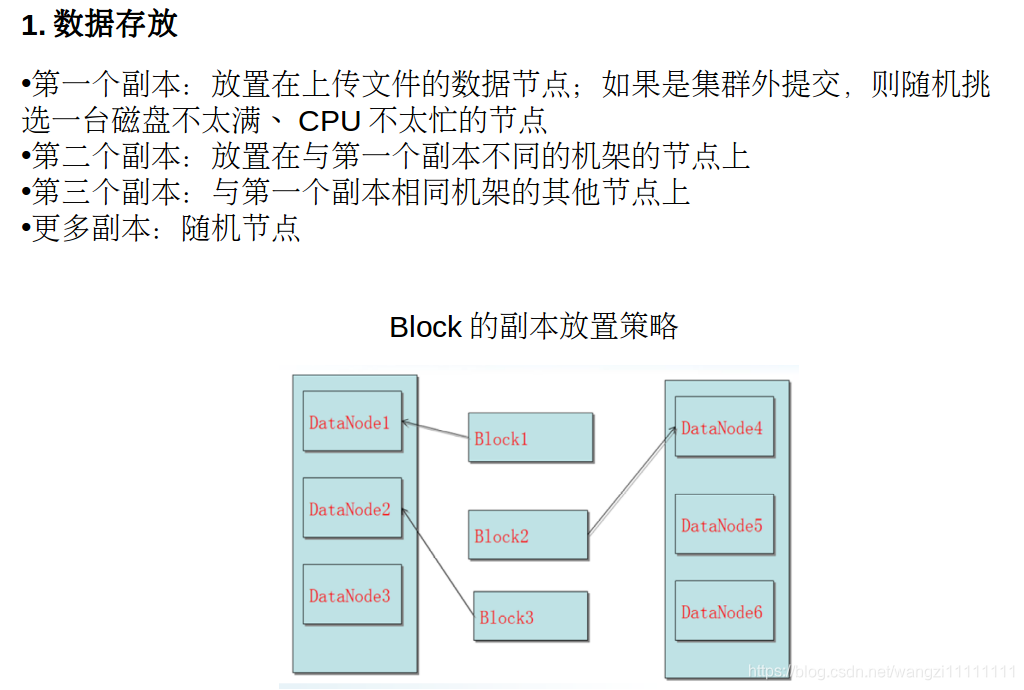
4.2 數據存取策略

4.3 數據錯誤和恢復
HDFS具有較高的容錯性,可以兼容廉價的硬件,它把硬件出錯看作一種常態,而不是異常,并設計了相應的機制檢測數據錯誤和進行自動恢復,主要包括以下幾種情形:名稱節點出錯、數據節點出錯和數據出錯。
4.3.1 名稱節點出錯
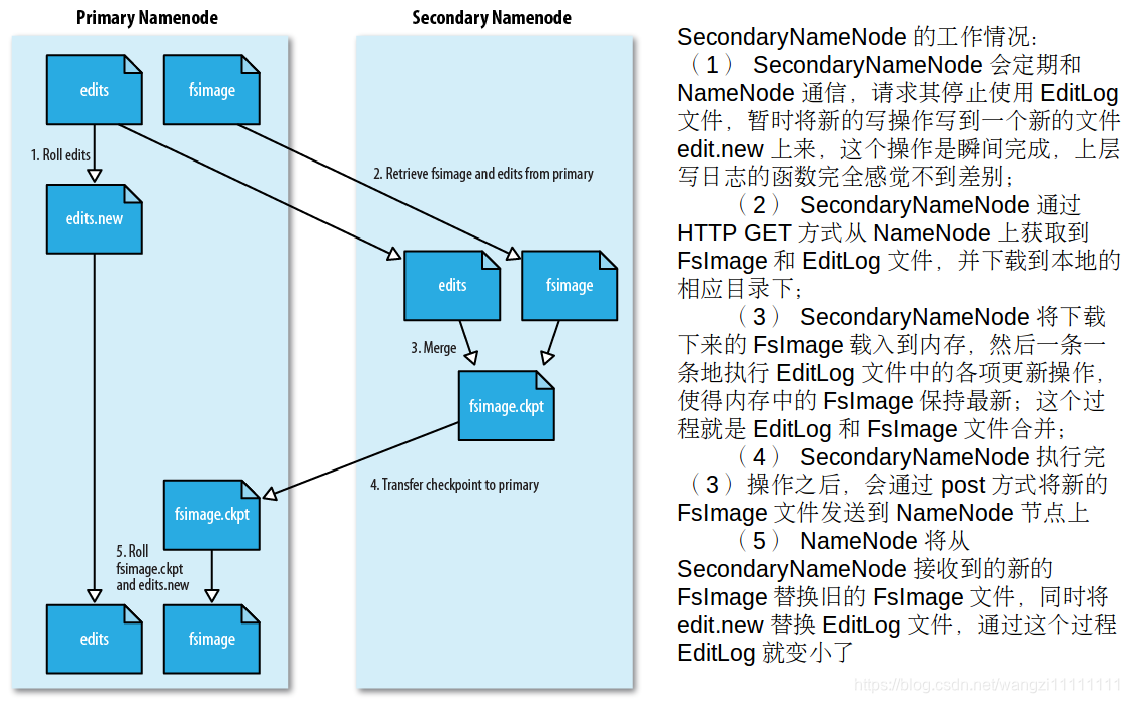
- 名稱節點保存了所有的元數據信息,其中,最核心的兩大數據結構是FsImage和Editlog,如果這兩個文件發生損壞,那么整個HDFS實例將失效。因此,HDFS設置了備份機制,把這些核心文件同步復制到備份服務器SecondaryNameNode上。當名稱節點出錯時,就可以根據備份服務器SecondaryNameNode中的FsImage和Editlog數據進行恢復。
4.3.2 數據節點出錯

4.3.3 數據出錯
- 網絡傳輸和磁盤錯誤等因素,都會造成數據錯誤
- 如何判斷數據出錯:HDFS在創建每個文件的時候,都默認給出了一個校驗碼,在讀取文件的時候,會比對校驗碼,如果校驗碼沒有錯,則數據沒有出錯。
- 在文件被創建時,客戶端就會對每一個文件塊進行信息摘錄,并把這些信息寫入到同一個路徑的隱藏文件里面
- 當客戶端讀取文件的時候,會先讀取該信息文件,然后,利用該信息文件對每個讀取的數據塊進行校驗,如果校驗出錯,客戶端就會請求到另外一個數據節點讀取該文件塊,并且向名稱節點報告這個文件塊有錯誤,名稱節點會定期檢查并且重新復制這個塊
5.HDFS數據讀寫過程
HDFS支持兩種方式的交互,我們可以自由的選擇shell和java的方式。
5.1 數據讀取過程
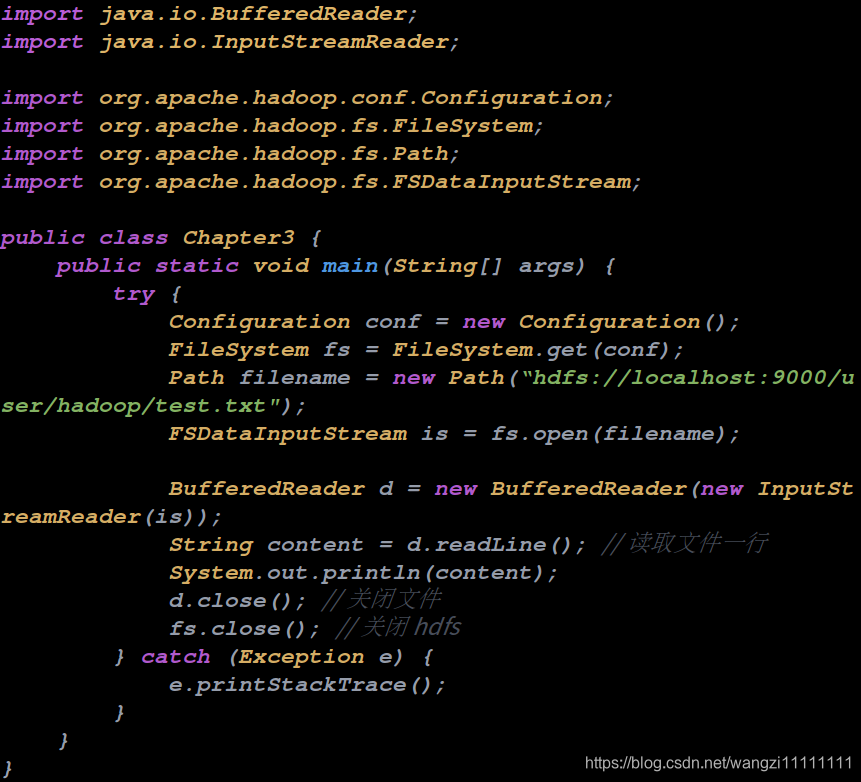
5.2 數據存儲過程
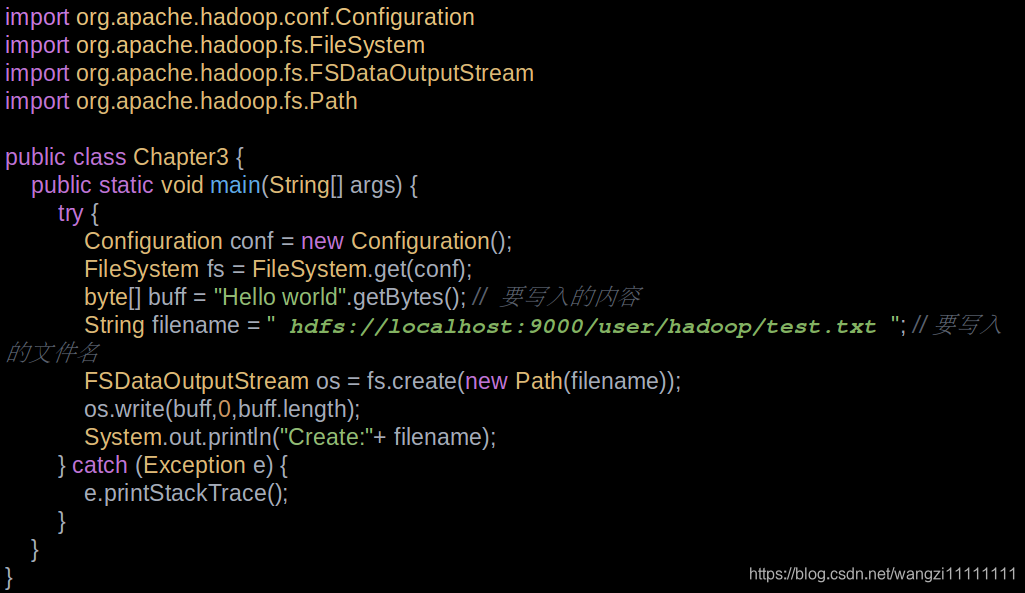
5.3 讀寫介紹
5.3.1 讀數據過程
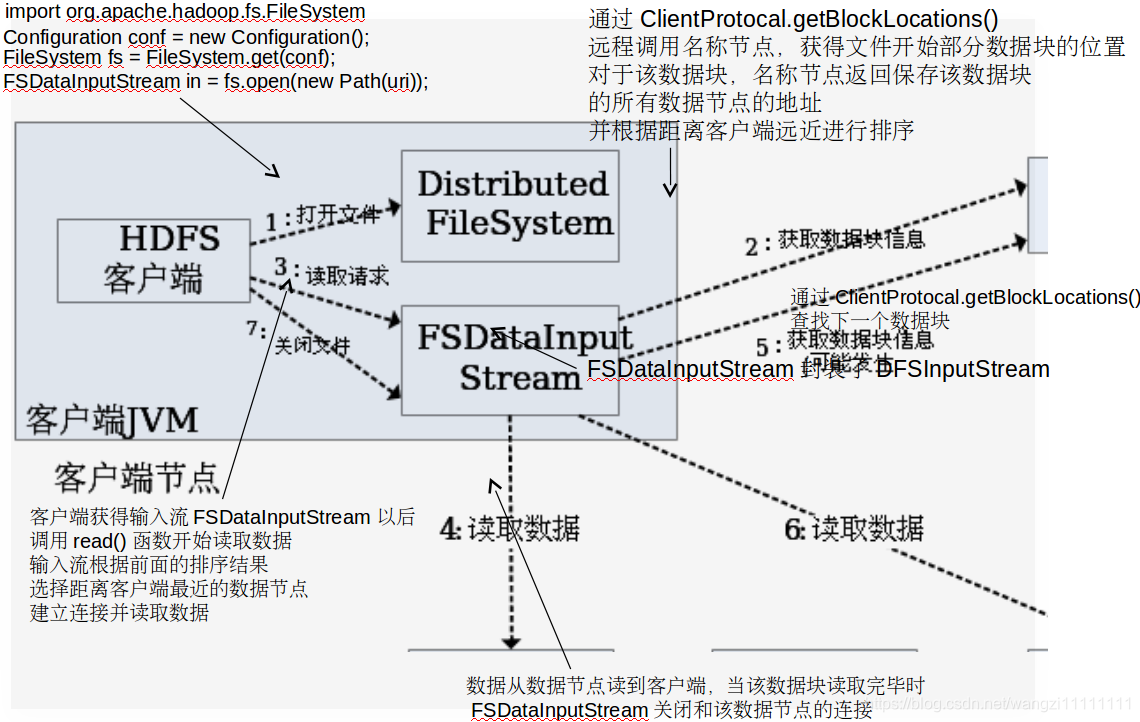
5.3.2 寫數據過程
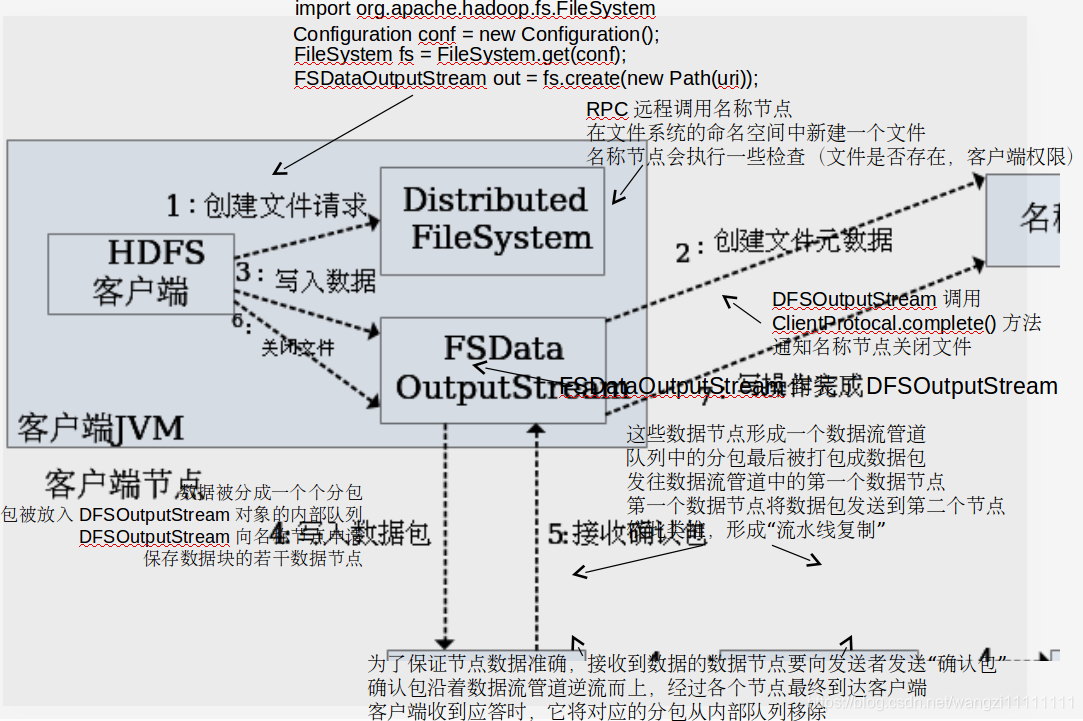
6.HDFS編程實踐
參考鏈接:http://dblab.xmu.edu.cn/blog/290-2/
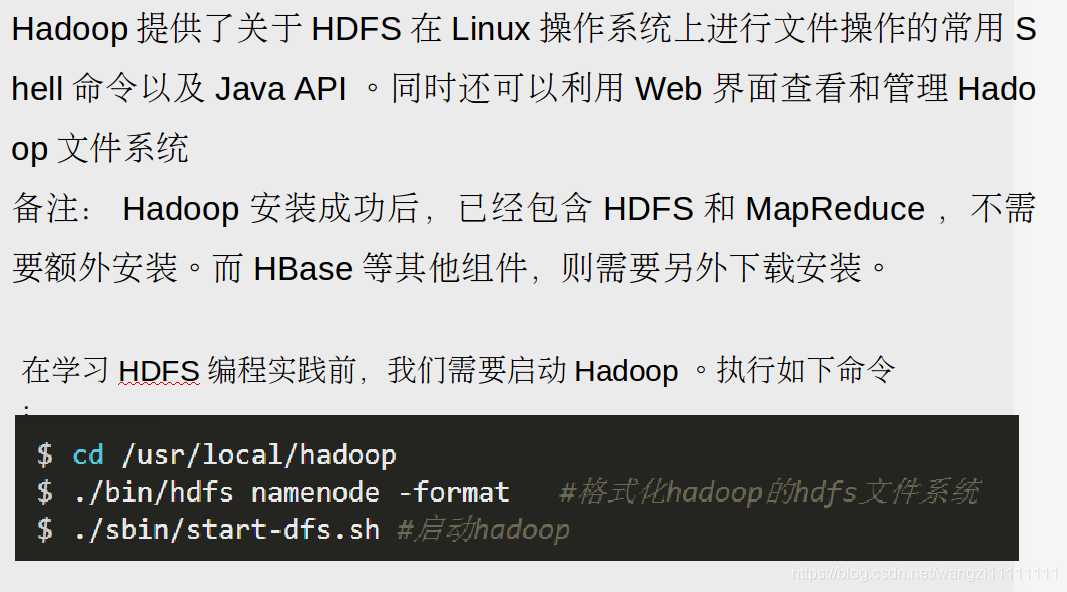

6.1 HDFS常用命令
- hadoop fs -ls
:顯示 指定的文件的詳細信息 - hadoop fs -mkdir
:創建 指定的文件夾 - hadoop fs -cat
:將 指定的文件的內容輸出到標準輸出(stdout) - hadoop fs -copyFromLocal :將本地源文件復制到路徑指定的文件或文件夾中
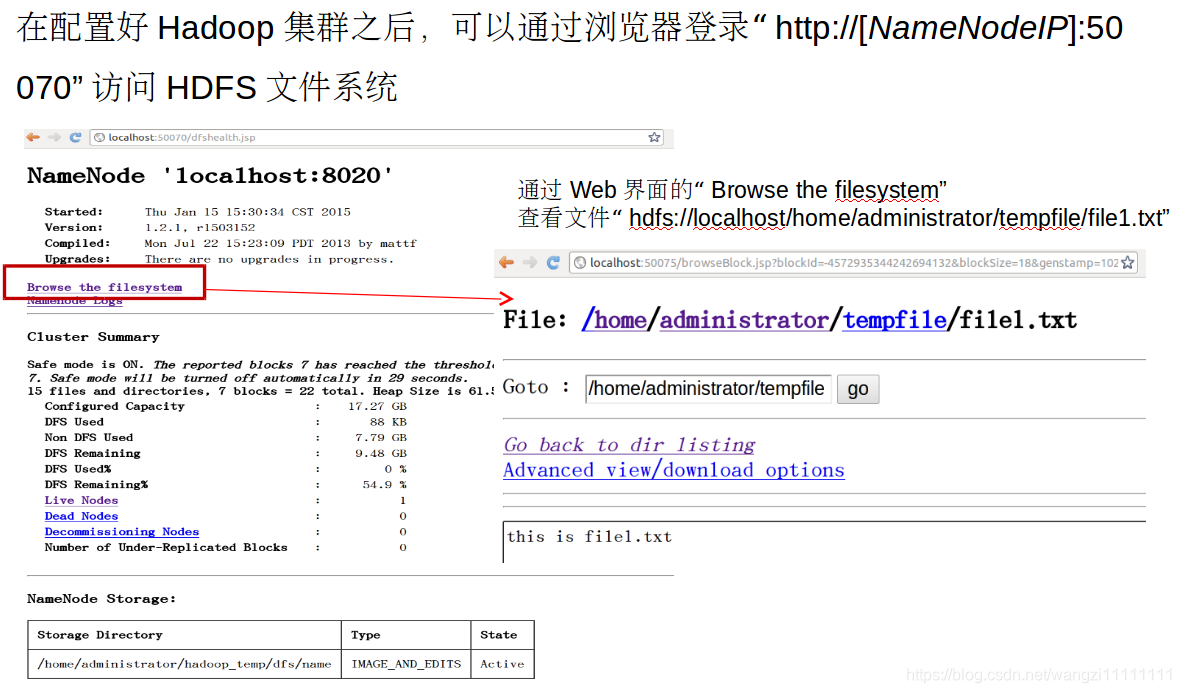
6.2 HDFS的web界面


--分布式數據庫HBase)

-tar,find,grep,xargs)
---代碼)


-源起、設計目標、設計哲學、特點)
---Event Recommendation Engine Challenge(基礎版))

-第一個python程序、執行python程序三種方式)


-Pycharm基本使用技巧)
)


)
組合模式)