問題的提出
我們有一個不安全網頁的黑名單,包含了100億個黑名單網頁的URL,每個網頁URL最多占用64B.。
現在我們要設計一個網頁過濾系統,這個系統要判斷該網頁是否在黑名單里,但是我們的空間有限,只有30GB.
允許有萬分之一的判斷失誤
布隆過濾器
我們可以把所有的URL保存起來,比如放到hashmap里,但是64B*100億=640GB,不符合要求。
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。布隆過濾器可以用于檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的算法,缺點是有一定的誤識別率和刪除困難。?
如果遇到網頁黑名單系統、垃圾郵件過濾、爬蟲網址判重等問題,如果可以容忍一定程度的失誤率,那么我們就可以用布隆過濾器來解決。
哈希函數
我們先來認識一下哈希函數(或者說是復習)
1)
哈希函數的輸入可以認為是無窮大或者是非常大的范圍,比如任意一個整數(字符串),而輸出域是有范圍的
(這就意味著不同的輸入可能是相同的輸出)
2)
當輸入相同的值時,返回值也相同(確定性)
3)
所有不同的輸入值得到的輸出,均勻地分布在輸出域內,并且與輸入值出現的規律無關。(這也是評價一個哈希函數是否優秀的兩個重要標準)比如:1和2相差很近,但是經過優秀的哈希函數計算后,他們應該差距較大。
4)
速度快:可以認為哈希函數的計算時間是O(1)的。
布隆過濾器輸入
下面就開始介紹布隆過濾器啦。
1)
我們準備k個哈希函數,并且他們之間沒有什么關系,彼此獨立。
那么對于同一個輸入對象(你想的沒錯就是一個URL),經過計算出來的結果也是完全獨立的沒有規律的。
2)
我們準備一個數組,長度為m,只有兩種狀態,所以我們選用bit數組名為bitmap。
3)
我們輸入一個黑名單里的URL時:把URL用每一個哈希函數計算出來,結果%數組長度(目的是能存下呀。。。。。),把對應位置的bit變為1,記錄下來。
處理完所有URL,我們的布隆過濾器就準備好啦。
布隆過濾器檢查
我們如何用布隆過濾器檢查某個URL是否是黑名單中的呢?
同樣的方法,把這個值用k個哈希函數算出結果,每一個結果都去bitmap里找有沒有存在過,只要有一個結果不存在,那這個URL就肯定不是黑名單了。(因為之前用同樣的方法,bitmap變為1的那些位置和現在應該是一樣的)
接下來就是比較佛性的事了,既然有一個答案不存在,這個URL就不是黑名單里的,那。。。所有答案都存在,就能確定它在黑名單里嗎?
不是的。
因為可能是其它URL算出的答案恰好把本URL的答案全都算出來過。
想到這就不禁要問了:那這個數據結構有啥用?不是坑爹呢?
其實是有用的,他的失誤率是很低很低的。
他的原則就是:“寧可錯殺三千,不可放過一個”
如何設計空間和哈希函數
?
首先我們應該想到:數組太小的話肯定是不準確的,比如:

就這么小個數組,存了幾個URL,十個地方全算出來過,全成1了。
那后面判斷的時候就比較坑了,隨便來什么URL,隨便什么哈希函數,算出的答案全都出現過,這顯然不是我們想要的。
所以,我們應該知道,數組過小會影響準確性。
那么我們如何根據數據量來設計數組大小和哈希函數個數呢?
以本題為例:
樣本數:100億
失誤率:不超過0.01%,記為p
每個樣本大小:64B(這個其實不影響布隆過濾器大小,因為這是和哈希函數有關的,一般的哈希函數都能接受64B的數據,并且輸出,bitmap只需記錄答案是否出現過即可)
布隆過濾器大小m由以下公式決定:

根據公式算出m=19.19n,向上取整20,所以需要2000億bit=25GB
哈希函數的個數由以下公式決定:
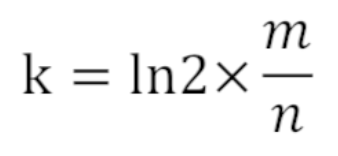
k=14
布隆過濾器的失誤率為:

計算出為0.006%,符合要求,此題可解。
公式分析





?
白名單
過濾器會用錯誤,對已經發現的錯誤樣本可以建立白名單防止錯誤。
其他使用場景
- 網頁爬蟲對URL的去重,避免爬去相同的URL地址
- 垃圾郵件過濾,從數十億個垃圾郵件列表中判斷某郵箱是否是殺垃圾郵箱
- 解決數據庫緩存擊穿,黑客攻擊服務器時,會構建大量不存在于緩存中的key向服務器發起請求,在數據量足夠大的時候,頻繁的數據庫查詢會導致掛機。
)
組合模式)
--Pycharm安裝、使用小技巧)
)

)
-注釋)


)
)

)

-算數運算符)
)

-程序執行的原理)
)
