1.什么是推薦系統
用戶沒有明確的需求,你需要的是一個自動化的工具,它可以分析你的歷史興趣,從龐大的電影庫中找到幾部符合你興趣的電影供你選擇。這個工具就是個性化推薦系統。
推薦系統的主要任務
推薦系統的任務就是聯系用戶和信息,一方面幫助用戶發現對自己有價值的信息,另一方面讓信息能夠展現在對它感興趣的用戶面前,從而實現信息消費者和信息生產者的雙贏
推薦系統與搜索引擎的區別
和搜索引擎一樣,推薦系統也是一種幫助用戶快速發現有用信息的工具。和搜索引擎不同的是,推薦系統不需要用戶提供明確的需求,而是通過分析用戶的歷史行為給用戶的興趣建模,從而主動給用戶推薦能夠滿足他們興趣和需求的信息。因此,從某種意義上說,推薦系統和搜索引擎對于用戶來說是兩個互補的工具。搜索引擎滿足了用戶有明確目的時的主動查找需求,而推薦系統能夠在用戶沒有明確目的的時候幫助他們發現感興趣的新內容。
從物品的角度出發,推薦系統可以更好地發掘物品的長尾( long tail)
需要推薦的兩個因素
1.信息過載
2.用戶沒有明確的需求
2.個性化推薦系統的應用
相信個性化推薦系統對每一個經常使用互聯網的人來說都不陌生,購物時有個性化商品推薦、聽歌/看電影時有猜你喜歡的歌曲/電影推薦、逛論壇時有你想看的個性化熱帖推薦……隨著信息技術的飛速發展,人們逐漸走進了信息過載的時代,從大量的信息中找出自己感興趣的東西成了一件困難的事情。一個好的推薦系統,可以在用戶面前展示他感興趣的東西,為商家推廣產品,為平臺(網站或手機應用)帶來流量……可以說是實現了三方的共贏。
那么問題來了,推薦系統向用戶推薦物品的依據有哪些呢?其中哪一種又是最優的?如何評價一個推薦系統是好是壞呢?
3.推薦系統評測
實驗方法
在推薦系統中,主要有三種評測推薦效果的實驗方法:離線實驗,用戶調查和在線實驗。
離線實驗
離線實驗通過日志系統獲得用戶行為數據,生成數據集,將數據集劃分成訓練集和測試集,在訓練集上訓練模型,測試集上進行預測,最后對預測結果進行評測。
離線實驗的優點是,不需要用戶的實時參與,可以快速地進行大量不同算法的測試;它的主要缺點是無法獲得點擊率、轉化率等很多商業上關注的指標,離線實驗的指標和商業指標還存在著差距,比如高預測準確率不等于高用戶滿意度。
用戶調查
用戶調查是推薦系統評測的一個重要工具,很多離線時沒有辦法評測的與用戶主觀感受有關的指標都可以通過用戶調查獲得。選擇測試用戶時,需要盡量保持測試用戶的分布與真實用戶的分布相同,同時要盡量保證是雙盲實驗(實驗人員和用戶事先不知道測試的目標),避免實驗結果受主觀成分的影響。
用戶調查的優點是可以獲得體現用戶主管感受的指標,彌補離線實驗的不足,同時相對在線實驗風險較低;它的主要缺點是招募測試用戶代價大,因此會使測試結果的統計意義不足,此外,在很多時候設計雙盲實驗非常困難,而且用戶在測試環境下的行為和真實環境下可能有所不同。
在線實驗
在完成離線實驗和必要的用戶調查后,可以將推薦系統上線做AB測試,AB測試是一種常用的在線評測算法的實驗方法,它通過一定的規則將用戶隨機分成幾組,并對不同組的用戶采用不同的算法,然后通過統計不同組用戶的各種不同的評測指標比較不同算法。
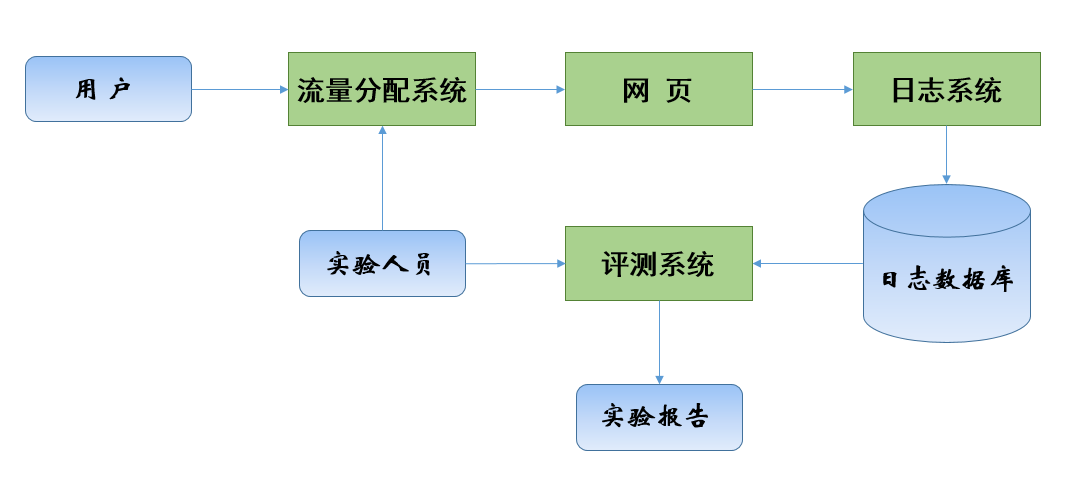
上圖是一個簡單的AB評測系統:用戶進入網站后,流量分配系統(由后臺實驗人員配置)決定用戶是否需要被進行AB測試,然后用戶瀏覽網頁,瀏覽網頁時的行為都會被通過日志系統發回后臺數據庫,實驗人員在后臺統計日志數據庫中的數據,通過評測系統生成不同分組用戶的實驗報告,并比較和評測實驗結果。
總結
一般來說,一個新的推薦算法最終上線前,需要完成3個實驗:
首先,需要通過離線實驗證明它在很多離線指標上優于現有的算法;然后,需要通過用戶調查確定它的用戶滿意度不低于現有算法;最后通過在線測試確定它在我們關心的指標上優于現有的算法。
評測指標
用戶滿意度
用戶滿意度是評測推薦系統的最重要指標,它可以通過用戶調查獲得,設計問卷時要注意考慮到用戶在各方面的感受。對于在線系統,用戶滿意度主要由對用戶行為的統計得到:設置用戶反饋按鈕,或者用點擊率、用戶停留時間和轉化率等指標度量用戶的滿意度。
預測準確度
預測準確度度量了一個推薦系統預測用戶行為的能力,是最重要的推薦系統離線評測指標。對于不同研究方向的離線推薦算法,預測準確度的指標也不相同,主要有兩種:
1、評分預測
評分預測的預測準確度一般通過均方根誤差(RMSE)和平均絕對誤差(MAE)計算,對于測試集中的一個用戶u和物品i,令rui是用戶u對物品i的實際評分,而r’ui是推薦算法給出的預測,那么RMSE和MAE的定義分別為:
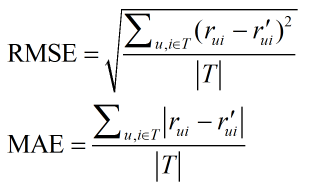
python代碼如下:
def RMSE(records):return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records])/float(len(records)))def MAE(records):return sum([abs(rui-pui) for u,i,rui,pui in records])/float(len(records))
2、個性化(TopN)推薦列表
TopN推薦列表的預測準確率一般通過準確率和召回率度量:
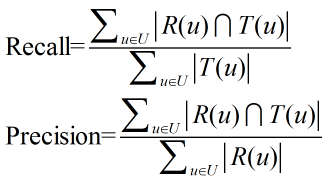
其中R(u)是推薦列表,T(u)是用戶在測試集上的行為列表。
通常來說,TopN推薦比評分預測更符合實際應用。
覆蓋率
覆蓋率描述一個推薦系統對物品長尾的發掘能力。覆蓋率有不同的定義方法,最簡單的定義為推薦系統能夠推薦出來的物品占總物品集合的比例:
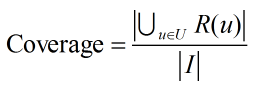
其中R(u)為用戶u的推薦列表。
個性化的推薦系統應當不僅僅能夠向用戶推薦那些熱門的物品,同時可以發掘適合用戶的非熱門物品,一個好的推薦系統不僅需要有比較高的用戶滿意度,也要有較高的覆蓋率。
但是上面的定義過于粗略,為了更細致地描述推薦系統發掘長尾的能力,需要統計推薦列表中不同物品出現次數的分布。如果所有物品都出現在推薦列表中,且出現次數相差不大,那么推薦系統發現長尾的能力就很好。信息熵和Gini系數也可以用來定義覆蓋率:
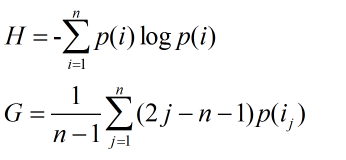
其中p(i)是物品i的流行度除以所有物品流行度之和,ij是按照物品i流行度p()從小到大排序的物品列表中第j個物品。
多樣性
多樣性描述了推薦列表中物品兩兩之間的不相似性,假設s(i,j)定義了物品i和j之間的相似度,那么用戶u的推薦列表R(u)的多樣性定義如下:
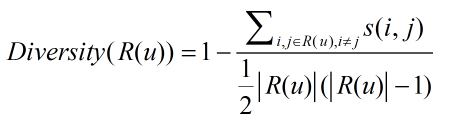
而推薦系統的整體多樣性可以定義為所有用戶推薦列表多樣性的平均值。
其它評測指標還有新穎性、驚喜度、信任度、實時性、健壯性等,在這里就不一一列舉。
用戶行為數據
用戶行為數據在網站上最簡單的存在形式就是日志,日志中記錄了用戶的各種行為,比如網頁瀏覽、點擊、購買、評論、評分等等。
用戶行為在個性化推薦系統中一般分為顯性反饋行為和隱性反饋行為。顯性反饋行為包括用戶明確表示對物品的喜好的行為,比如給物品評分,而隱性反饋行為是指那些不能明確反應用戶喜好的行為,比如頁面瀏覽行為。隱性反饋數據比顯性反饋不明確,但其數據量更龐大。
此外,用戶活躍度和物品流行度的分布都服從長尾分布,隨著用戶活躍度(物品流行度)的下降,用戶數量(物品數量)逐漸下降,但不會迅速墜落到零,而是極其緩慢地貼近于橫軸,粗看上去幾乎與橫軸平行延伸。
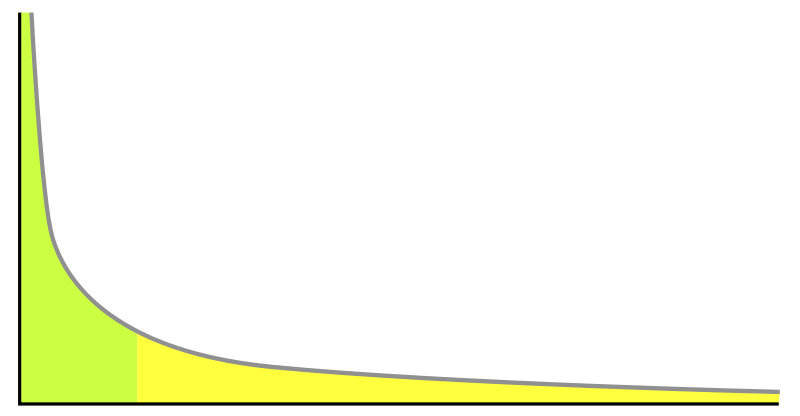
僅僅基于用戶行為數據設計的推薦算法一般稱為協同過濾算法,比如基于領域的算法、隱語義模型、基于圖的算法等等,下面對這幾種方法分別進行介紹。
基于鄰域的算法
基于鄰域的算法是推薦系統中最基本的算法,分為兩大類,一類是基于用戶的協同過濾算法,一類是基于內容的協同過濾算法。
基于用戶的協同過濾算法(UserCF)
計算用戶相似度
基于用戶的協同過濾算法通過找到和目標用戶興趣相似的用戶集合,找到這個集合中的用戶喜歡的,且目標用戶沒有聽說過的物品推薦給目標用戶。
通過余弦相似度計算兩個用戶的興趣相似度:
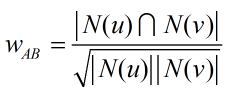
如果對兩兩用戶都利用余弦相似度計算,在用戶數很大時消耗的時間將會非常多,因此可以首先篩選出興趣物品集合交集不為零的用戶對,然后再對這些情況除以分母計算興趣相似度。
利用UserCF篩選用戶感興趣的物品
得到用戶之間的興趣相似度后,UserCF算法會給用戶推薦和他興趣最相似的K個用戶喜歡的物品,下面的公式度量了UserCF中用戶u對物品i的感興趣程度:
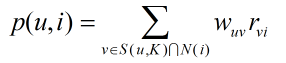
其中S(u,k)包含和用戶u興趣最接近的K個用戶,wuv是用戶u和用戶v的興趣相似度,N(i)是對物品i有過行為的用戶合集,rvi代表用戶v對物品i的興趣,使用單一行為的隱反饋數據時,所有的rvi=1。K值需要通過離線實驗,選擇在預測數據集上預測效果最好時所對應的值。
相似度計算改進
對一件冷門物品有過相同行為比對一件熱門物品有過相同行為更能說明兩個用戶興趣相似,比如,同時購買《數據挖掘導論》的用戶顯然比同時購買《新華字典》的用戶喜好更相近。因此,需要對相似度公式進行如下的改進:
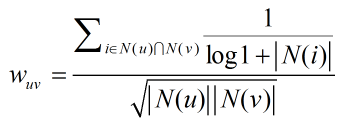
該公式通過1/log1+|N(i)|懲罰了用戶u和用戶v共同興趣列表中的熱門物品i,實驗表明,改進的UserCF算法的各預測指標都有所提升。
基于物品的協同過濾算法(ItemCF)
計算物品相似度
基于物品的協同過濾算法是向用戶推薦與他們過去喜歡過的物品相似的物品。那么首先需要計算物品之間的相似度,可以由下面的公式計算:
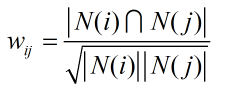
|N(i)|和|N(j)|分別是喜歡物品i和物品j的用戶數,分母之所以這樣設計,是為了減輕熱門物品會和很多物品相似的可能性。
和UserCF算法類似,ItemCF算法在計算物品相似度時為了避免兩兩物品之間都需要進行計算,首先建立用戶-物品倒排表,對于每個用戶,將他物品列表中的物品兩兩在共現矩陣中加1,最后將矩陣歸一化就可以得到物品之間的余弦相似度。
利用ItemCF篩選用戶感興趣的物品
得到物品之間的相似度之后,ItemCF通過以下公式計算用戶u對一個物品j的興趣:
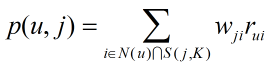
其中S(j,K)包含和物品i最接近的K個物品,wji是物品i和物品j的相似度,N(u)是用戶喜歡的物品合集,rui代表用戶u對物品i的興趣,使用單一行為的隱反饋數據時,所有的rui=1。
相似度計算改進
試想這樣一種情況:如果有一個用戶從網上購買了數十萬本書準備開書店,這數十萬本可能覆蓋眾多領域的書兩兩之間就產生了相似性,然而用戶購買這些書并非出于自己興趣,因此John S.Breese提出應當懲罰活躍用戶對物品相似度的貢獻,將計算公式改進為:
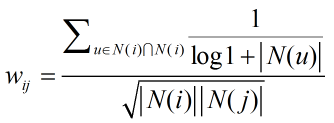
同時,對于某些過于活躍的用戶,為了避免相似度矩陣過于稠密,通常直接忽略他們的興趣列表,不納入相似度計算的數據集。
物品相似度的歸一化
如果將ItemCF的相似度矩陣按最大值歸一化,可以提高推薦的準確率、覆蓋率和多樣性。原因是,物品往往歸屬于不同的類,類物品之間的相似度往往比不同類物品之間的相似度要高,類物品之間的相似度都變成1,推薦時的多樣性和覆蓋率就更好了。歸一化公式如下:
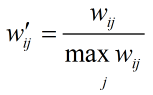
UserCF和ItemCF的綜合比較
- UserCF適用于用戶較少的場合,因為用戶很多時計算相似度矩陣的代價會很大,需要計算物品相似度矩陣的ItemCF則適用于物品數明顯小于用戶數的場合。
- UserCF的推薦更社會化,反映了用戶所在的小型興趣群體中物品的熱門程度,ItemCF的推薦更加個性化,反映了用戶自己的興趣傳承。
- 當用戶有新行為時,UserCF算法中推薦結果不一定立即變化,而ItemCF中一定會導致推薦結果的實時變化。
- UserCF適用于新聞推薦,主要是由于在新聞網站用戶的興趣比較粗粒度且偏向于熱門,同時,新聞的時效性很強,維護物品相似度矩陣代價太大。
- ItemCF適用于圖書、電影、音樂和電子商務中的推薦,因為在這些網站中用戶的興趣比較固定,個性化推薦的任務是幫助用戶發現和他研究鄰域相關的物品。
隱語義模型(LFM)
基于興趣分類方法的核心思想是通過隱含特征聯系用戶興趣和物品,判斷用戶對哪些類的物品感興趣,再將屬于這些類的物品推薦給用戶。那么,如何給物品分類,分類的粒度如何確定?如何確定用戶對哪些類的物品感興趣,以及感興趣的程度?又如何確定物品在一個類中的權重呢?
隱語義分析技術基于用戶行為統計進行自動聚類,較好地解決了以上幾個問題。
LFM是隱語義分析技術中的一種模型,通過以下公式計算用戶u對物品i的興趣:
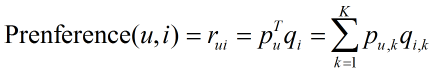
其中pu,k度量了用戶u的興趣和第k個隱類的關系,qi,k度量了第k個隱類和物品i之間的關系。計算這兩個參數,需要一個訓練集,對于每個用戶u,訓練集里都包含了用戶u喜歡和不感興趣的物品,通過學習這個數據集,就可以獲得模型參數。
訓練集采樣
在隱性反饋數據集中,只有正樣本,沒有負樣本。那么就需要在用戶沒有行為的物品中進行負樣本的采用,經過實驗,發現對負樣本的采樣應該遵循以下原則:對于每個用戶,要保證正負樣本的平衡,對每個用戶采樣負樣本時,選取熱門但用戶沒有行為的物品。
采樣完成后可以得到一個用戶-物品集K={(u,i)},如果(u,i)是正樣本,則rui=1,否則rui=0。
優化損失函數
對于采樣完成的訓練集,需要優化如下損失函數來找到最合適的參數p和q:
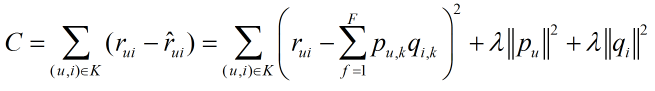
最小化損失函數采用的是隨機梯度下降法。
基于圖的模型
基于圖的模型首先需要將用戶行為表示成二分圖模型,令G(V,E)表示用戶物品二分圖,其中V由用戶頂點合集VU和物品頂點合集VI組成,E為連接用戶節點和物品節點的邊的集合,用戶節點和物品節點相連說明該用戶對相連的物品產生過行為。
度量頂點之間相關性的方法有很多,主要有:兩個頂點之間的路徑數,兩個頂點之間路徑的長度,兩個頂點之間的路徑經過的頂點。
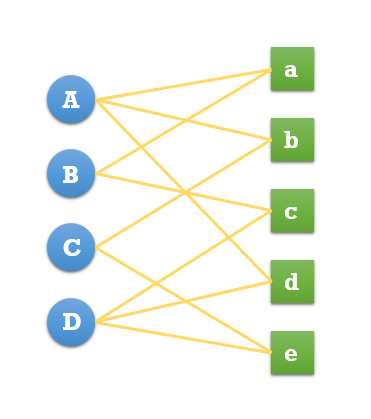
基于隨機游走的PersonalRank算法
了解了二分圖模型的基本概念,下面介紹一種計算圖中頂點之間相關性的方法。
假設要給用戶u進行個性化推薦,可以從用戶u對應的節點vu開始在用戶物品二分圖上進行隨機游走,游走到任何一個節點時,首先按照概率決定是繼續游走還是停止這次游走并從vu節點重新開始游走。如果決定繼續游走,那么就從當前節點指向的節點中按照均勻分布隨機選擇一個節點作為游走下次經過的節點。這樣,經過很多次隨機游走后,每個物品節點被訪問到的概率會收斂到一個數。最終的推薦列表中物品的權重就是物品節點的訪問概率。
這種方法可以表示成如下公式:
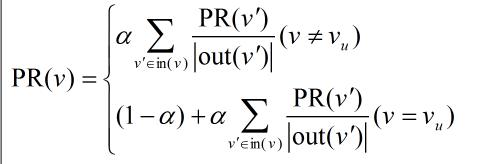
PersonalRank算法可以通過隨機游走進行比較好的理論解釋,但該算法在時間復雜度上有明顯的缺點,可以通過將PR轉化成矩陣的方法進行改進。


)
組合模式)
--Pycharm安裝、使用小技巧)
)

)
-注釋)


)
)

)

-算數運算符)
)

-程序執行的原理)